引言
仓湖一体架构是大数据架构演进中未来的架构趋势,它融合了数据仓库和数据湖的优点,是目前大厂(如腾讯、阿里、华为等)青睐和推广的大数据架构。
下文我就大家解释一下,仓湖一体架构到底是怎么回事,为什么大厂如此青睐。
仓湖一体架构
想象你是一个老板,需要建一个超级仓储中心,以前的做法就像有两个仓库:
- 老仓库(数据湖):什么货都能放,成本低,但是找东西特别慢,像个大杂货铺
- 精品仓库(数据仓库):货品整理得井井有条,找东西快,但是成本高,只能放特定规格的货
而现在的湖仓一体就像造了一个智能仓储中心,把两个仓库的优点结合起来了!这个智能仓储中心的架构呢,如下所示:
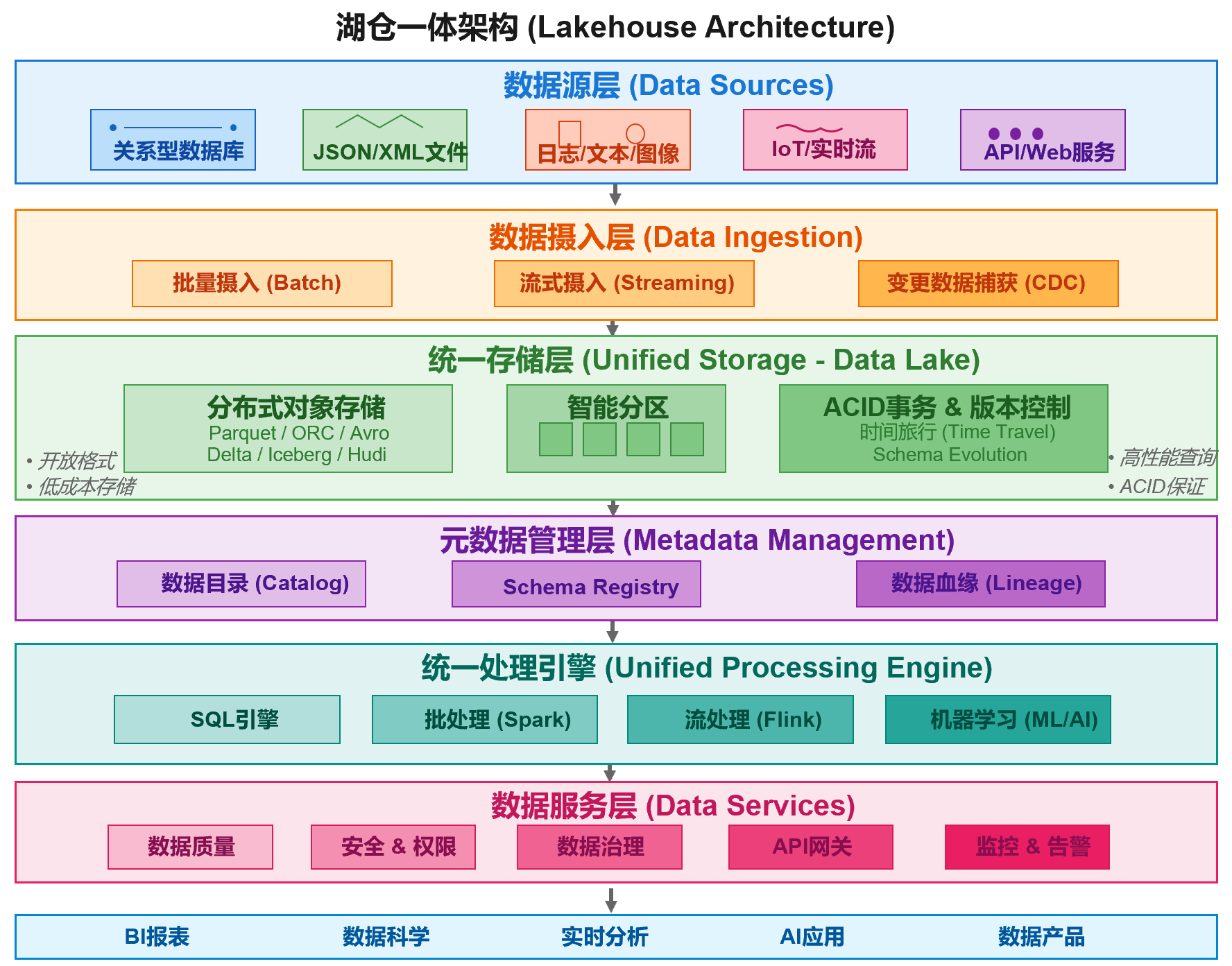
看这张图,从上到下就是货物的全流程:
1. 最上层 - 收货区(数据源层)
就像您的仓库要收各种货:
- 整箱的标准货(结构化数据)= 财务报表、销售订单
- 散装货(半结构化数据)= 客户邮件、合同文档
- 各种形状的特殊货(非结构化数据)= 产品图片、客服录音
- 不断送来的快递(流数据)= 实时交易、设备监控
- 网购订单(API数据)= 电商平台数据、社交媒体反馈
2. 橙色区域 - 智能收货系统(数据摄入层)
- 有的货一车车地来(批量)
- 有的货随时在送(实时)
- 还能实时监控货物变化(CDC)
3. 绿色核心区 - 超级智能货架(统一存储层)
这是整个系统的精华!
- 成本低:像普通仓库一样,不挑货,什么都能放
- 找货快:像精品仓库一样,有智能索引系统
- 智能标签:每件货都有详细标签,还能追溯来源
- 时光机功能:能看到货物的历史状态(比如上个月的库存)
4. 紫色区域 - 仓库管理系统(元数据层)
- 货物目录:知道每件货在哪
- 规格登记:记录货物规格
- 追踪系统:知道货从哪来到哪去
5. 青色区域 - 智能处理中心(统一处理引擎)
- 快速查询:老板要看销售数据,秒出结果
- 批量分析:月底算总账,高效处理
- 实时监控:随时知道哪个产品卖得好
- 智能预测:用AI预测下个季度的销售趋势
6. 粉色区域 - 品质保障系统(数据服务层)
- 质检:确保数据准确,不会因为错误数据做错决策
- 安保:不同部门只能看自己的数据
- 合规:满足监管要求
- 统一接口:各部门用统一方式取数据
- 监控告警:系统有问题立即通知
7. 最下层 - 价值变现(应用层)
- 看报表:销售业绩、财务状况一目了然
- 做分析:哪个产品赚钱,哪个市场有潜力
- 实时决策:库存预警、价格调整及时响应
- 智能应用:个性化推荐、智能客服
- 数据产品:把数据变成新的收入来源
元数据模型
看到这里,大家一定有个困惑,这么多数据类型是如何实现元数据的统一的?比如表和图像完全不一样啊,数据目录怎么设计呢?怎么实现统一查询的?
实际上,仓湖一体使用分层的元数据模型来统一不同类型的数据,如下所示:
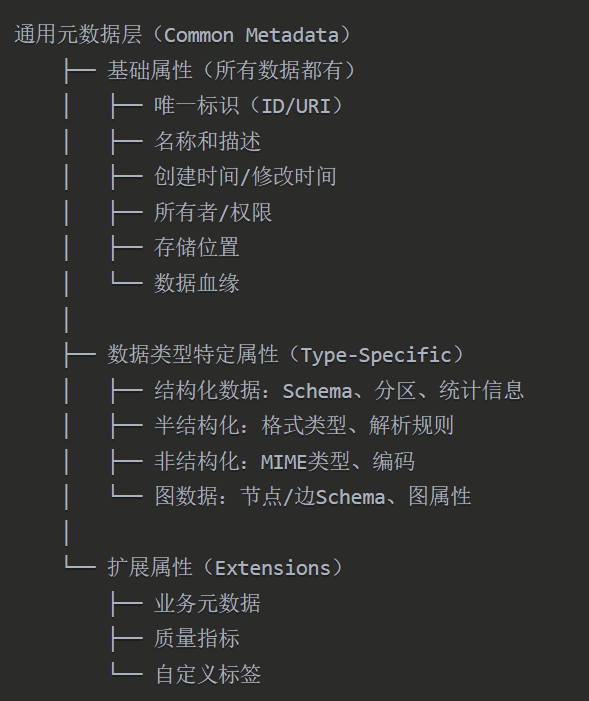
下图示例了湖仓一体统一元数据模型:
元数据统一意味着湖仓一体能够对数据仓库和数据湖中存储的各种类型的数据进行统一管理,这是进行统一查询处理的基础。
以前数据湖和数据仓库两者信息是不互通的,比如要对数据湖的文件和数据仓库的表进行Join,前提就是把数据湖的文件ETL到数据仓库后才能join,有了统一元数据后就不需要这个搬迁动作了。
大家是否还记得,当我们需要从数据湖中对文件进行查询处理时,往往先需要通过ETL把文件加载到数据仓库的表中才可以的哦,这也就意味着一个文件其实在两个系统都存储了一份,现在统一了元数据后,文件在哪里都可以直接处理,就这个特性,就可以让存储成本降低50%以上,而不搬迁数据,意味着运维成本也大幅下降了,数据一致性也得到了保证,大家都懂得,搬迁数据可能出现各种意外。
仓湖一体实时读写架构
湖仓一体的价值显然不仅仅在于各种类型数据的元数据统一,相对于数据湖或者数据仓库,性能也进行了大幅提升。
大家都知道,无论是MPP数据仓库还是hadoop这类数据湖,本身不具备实时读和写的能力,下面是一张比对表,一看就知道与湖仓一体的差距了:

现在企业的数据湖为了支持实时流处理,往往是新建一套流处理引擎,比如通过CDC+kafka+flink的组合来实现,通过kafka这种消息中间件来存储实时的数据,其与hadoop的批处理实际是两套系统,这种架构意味着企业需要构建两套处理引擎,维护成本翻倍上升,同时存在流批数据处理不一致等系列问题。
那么,湖仓一体到底是怎么解决传统数据湖的实时读写难题呢?
奥妙就在事务日志的精妙处理上,即将"改文件"变成"写日志",其不会修改原始文件,而只是用日志元数据记录了什么时候修改了啥,下图显示了湖仓一体实时读写的架构图,我在下面附上了对此图的解读,大家一看就懂了:
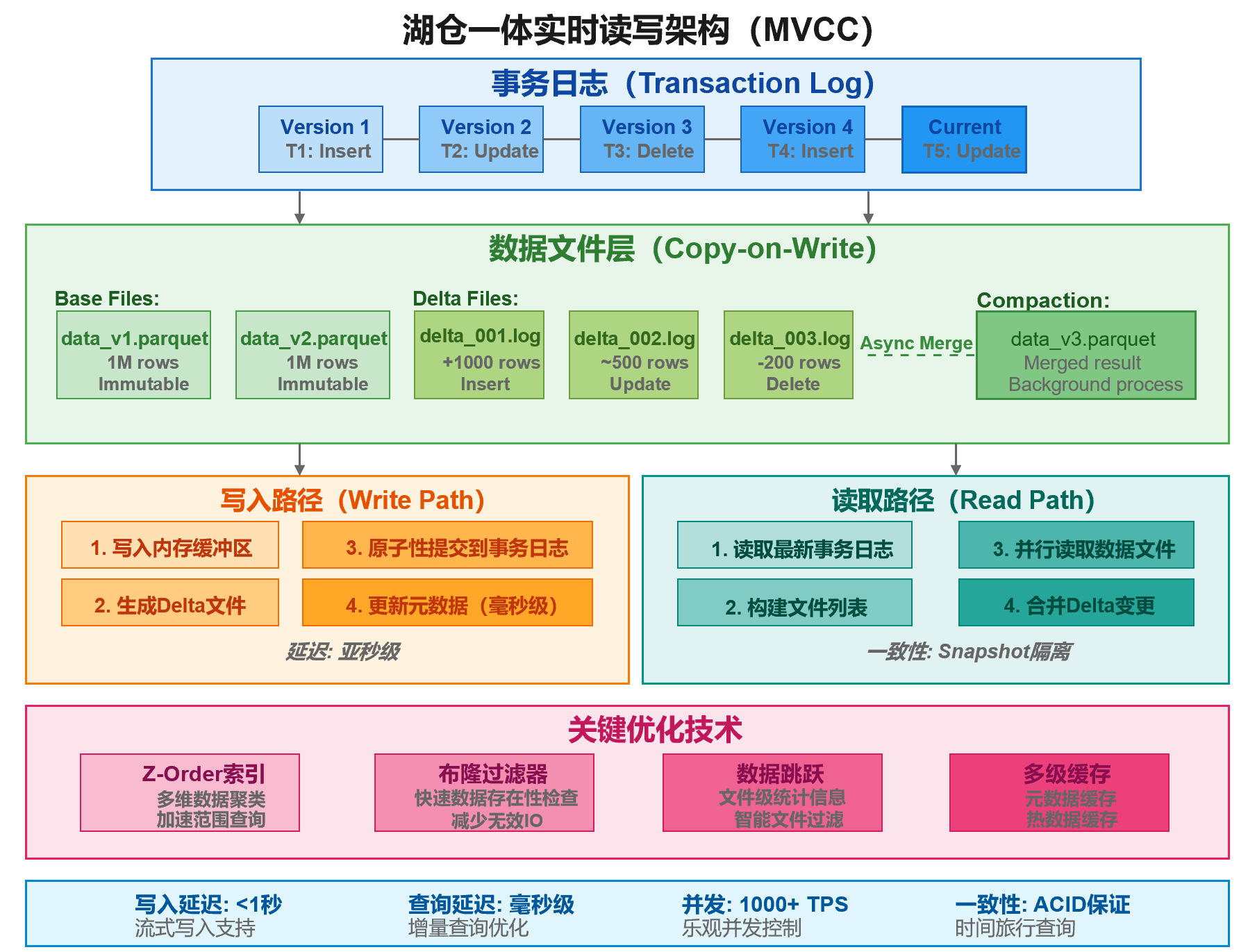
1. 事务日志层 - 实时写入的"大脑"
传统Hadoop的致命问题:

湖仓一体的解决方案:
图中展示的Version 1→2→3→4→Current就像Git的提交历史:
- Version 1: "插入了1000条订单记录"
- Version 2: "更新了订单#123的状态"
- Version 3: "删除了取消的订单"
- Version 4: "插入了新的订单"
- Current: "正在进行的更新"
关键优势:
- 原子性提交:要么全部成功,要么全部失败
- 并发控制:多个写入者可以同时工作
- 时间旅行:可以查询任意历史版本的数据
2. 数据文件层 - 巧妙的"双轨制"
大家都知道为了实时,hadoop每次写入文件要尽量小,但小文件太多又会导致元数据太大导致读取速度很慢,因此,传统hadoop在写文件的时候,一般要确保写入的文件达到一定的大小,这导致了其实时性的不足。
Base Files + Delta Files的双轨存储,这是湖仓一体最巧妙的设计,解决了Hadoop的小文件问题。
1.Base Files(基础文件)
特点:
- 大文件(如1GB的Parquet)
- 不可变(Immutable)
- 高度优化的列式存储
- 批量数据的主题
2. Delta Files(增量文件)
特点:
- 小文件(KB到MB级别)
- 记录增量变更
- 快速写入
- 定期合并到 Base Files
工作原理示例:

后台压缩(Compaction)- 自动优化图中右侧的"Async Merge"展示了后台压缩过程:

读写分离设计 - 互不干扰的"双车道"
写入路径(橙色区域)- 为速度优化
四步快速写入流程:
1. 写入内存缓冲区
优势:
- 内存操作(纳秒级)
- 可以做预聚合
- 批量处理提高效率
2. 生成Delta文件
技术细节:
- 使用高效的序列化技术
- 压缩算法减少IO
- 顺序写入,避免随机IO
3. 原子性提交到事务日志
关键技术:
- 利用文件系统的原子rename操作
- 或使用分布式锁服务
- 确保要么全部可见,要么全部不可见
4. 更新元数据
包括:
- 文件列表
- 统计信息
- 索引更新
- 缓存失效
读取路径(青色区域)- 一致性保证
四步一致性读取:
1. 读取最新事务日志
获取:
- 当前版本号
- 有效文件列表
- 删除标记
2. 构建文件列表
逻辑:
- Base Files + Delta Files
- 减去已删除的文件
- 应用时间旅行(如果需要)
3. 并行读取数据文件
优化:
- 多线程/多进程并行
- 列裁剪(只读需要的列)
- 谓词下推(在存储层过滤)
4. 合并 Delta 变更
实时合并:
- 将 Delta 中的插入添加到结果
- 应用更新操作
- 过滤删除的记录
关键优化技术 - 性能加速器
这些优化技术让实时读写真正可用于生产环境:
1. Z-Order索引 - 多维数据的"导航仪"
传统索引只能优化一个维度的查询:
WHERE date = '2025-01-01'
Z-Order 可以同时优化多个维度:
WHERE date = '2025-01-01' AND city = 'chengdu' AND product = 'iPhone'
2. 布隆过滤器 - 快速"排除法"
查询:WHERE customer_id = 'C12345'
- 不用布隆过滤器:需要打开 100 个文件查找
3. 数据跳跃 - 智能"快进"
由于每个文件都有统计信息,查询时就可以直接过滤掉部分文件,加快查询速度。
4. 多级缓存 - 热数据的"快速通道"
缓存层次:
- L1:元数据缓存(哪些文件包含什么数据)
- L2:索引缓存(布隆过滤器、统计信息)
- L3:热数据缓存(频繁访问的数据块)
效果:热查询可以完全从内存返回
总结
把湖仓一体的实时读写架构比作一个现代化的物流中心:
- 事务日志 = 订单系统(记录所有变更)
- Base Files = 主仓库(存放大批量货物)
- Delta Files = 快递暂存区(临时存放小件)
- Compaction = 夜间整理(把暂存区货物整理到主仓库)
- 读写分离 = 进货出货双通道(互不干扰)
- 优化技术 = 智能货架 + 快速定位系统
这样,既能处理大批量货物(批处理),又能快速处理零散订单(实时写入),还能让客户即时查询(毫秒级响应)。
读到这里,相信你已经能理解了湖仓一体的强大之处,从技术角度看,这种架构就是把hadoop改造成了大数据时代的ORACLE。
如果企业从0到1建设大数据平台,湖仓一体绝对有竞争力,现实中,是否引入湖仓一体则取决于企业自身的实际业务需要。
互联网公司是当前国内这种架构的主要推动者,因为其业务非常依赖这种大数据的实时架构。
但如果企业数据分析还是以批处理为主,实时业务还未成规模,那么,传统的hadoop叠加流处理引擎也就够了。