LlamaIndex介绍
LlamaIndex 是一个强大的框架,专门用于构建基于LLM的数据应用。它的主要目标是帮助开发者创建能够与私有数据交互的LLM应用。
1、官网(文档)
https://docs.llamaindex.ai/en/stable/
2、github地址
https://github.com/run-llama/llama\_index
3、中文文档(非官方,版本有点旧)
https://llama-index.readthedocs.io/zh/latest/index.html
为什么选择 LlamaIndex?
- 简单易用:仅需几行代码即可实现基本功能
- 灵活性强:支持多种数据源和格式
- 可扩展性:提供从基础到高级的完整工具链
- 生产就绪:支持企业级应用部署
有了 LlamaIndex,就可以:
-
把本地文档、数据库、网页等变成可查询的知识源
-
和大模型配合使用,实现 "基于你自己的数据" 来问答(也叫 RAG:Retrieval-Augmented Generation)
适用人群
- 初学者:可以使用高级API,仅需5行代码即可实现基本功能
- 进阶用户:可以自定义和扩展任何模块
- 企业用户:提供完整的生产级解决方案
基本概念
1. 上下文增强
LlamaIndex 的核心理念是"上下文增强"(Context Augmentation),主要包括:
- 数据摄入:从各种源导入数据
- 数据索引:结构化存储便于LLM使用
- 数据检索:智能查询和响应
2. 主要组件
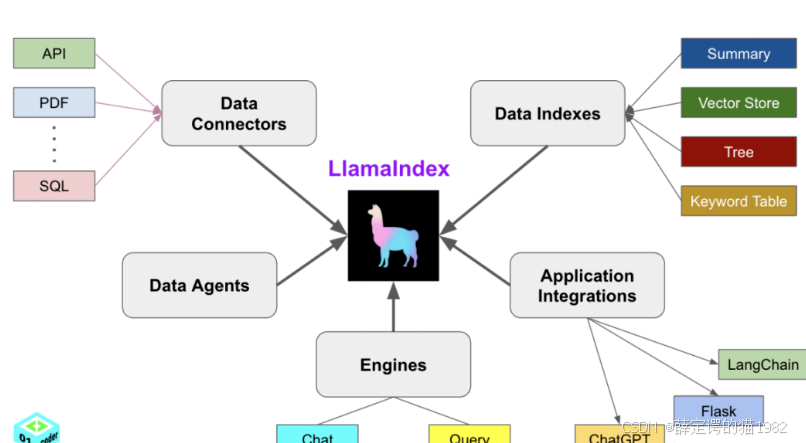
1、Data Connectors 数据连接器
连接各种类型的数据,提取数据给到LlamaIndex,LlamaIndex再给到大模型。这些数据源可以是 API、PDF、SQL、MarkDown、CSV、Txt 等等。
2、Data Indexes 数据索引
DataConnectors将文本数据给LlamaIndex后,LlamaIndex再将数据给大模型之前,需要将文本转向量,一般使用Embeding模型将文本转成向量。这个过程是由Data Indexes来负责。
Data Indexes将文本存储为向量后,LlamaIndex需要使用这些向量数据,所以需要创建索引来查找和使用向量,并且以Tree树状存放,检索使用Keyword Table 关键词表格。
因此Data Indexes的核心是将文本向量化,并且拿到其索引进行检索。
3、Engines 引擎
通过引擎Engines来加载大模型进行检索和处理数据。Query是单轮的,Chat是多轮的有历史对话的,两大功能本质是一样的。 因此 Engines是用来连接大模型的
4、Data Agents 数据智能体
处理一些复杂的逻辑。
5、Application Integrations 应用整合
LlamaIndex可以将RAG整合到其他AI应用中,作为辅助插件。
安装和快速开始
安装
pip install llama-index环境设置
.env中配置api_key
关键组件关系详解
1.1 加载层(Loading) 解决"数据从哪来"(Source)
-
- 入口:通过数据连接器获取原始数据
- 核心工具 :
SimpleDirectoryReader:本地文件加载- LlamaParse:PDF专业解析(含表格/公式处理)
- LlamaHub:300+ 外部数据源适配器(API/数据库等)
- 输出 :生成统一格式的
Document文档对象
1.2 转换层(Transformations)解决"数据怎么切"(Structure)
-
- 核心操作:文本结构化处理
- 核心工具 :
- Node Parsers:语义分割器(按句子/Token/HTML/JSON等规则切分)
- Text Splitters:滑动窗口分块(保留上下文的关键技术)
- 输出 :将
Document拆解为语义节点Nodes(携带元数据的基础单元)
1.3 组织层(Abstractions) 解决"数据如何存"(Store)
- 核心对象 :
*Document:原始文档抽象(保留来源/格式等元信息)Nodes:文档分块后的语义单元(带位置/关键词标记)- 关键机制 :
- 自定义元数据扩展(适配医疗/金融等垂直领域)
- 节点关联关系建模(用于知识图谱场景)
1.4 应用层(Applications) 解决"数据怎么用"(Use)
-
- 核心管道 :
- Ingestion Pipeline:标准化数据流(集成加载+转换+缓存优化)
- 上层应用 :
→Indexing(索引构建)
→Querying(智能查询)
→Agents(任务自动化)
→Workflows(多步骤业务流程)
- 核心管道 :