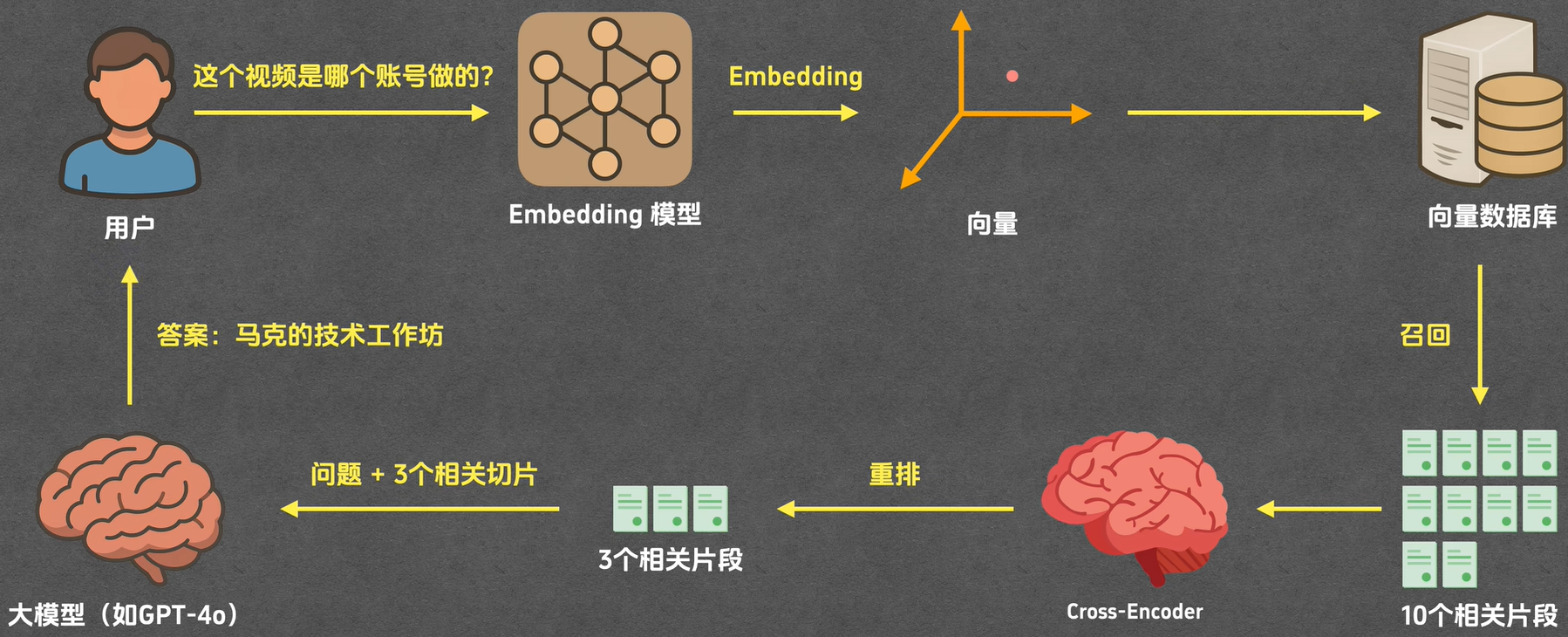
RAG(检索增强生成):
它是 AI 回答问题的一种 "聪明办法"------ 不是让 AI 只靠自己脑子里存的旧知识瞎编,而是先去 "翻资料"(从提前准备好的文档、数据库里搜相关信息),把搜到的靠谱内容当 "参考资料",再结合这些资料生成回答。
简单说就是:AI 回答前先 "查资料",避免瞎掰或说过时的内容。
为什么RAG在多轮对话中可能表现不佳?
在多轮对话场景中,RAG(检索增强生成)的核心矛盾是"静态的检索逻辑"难以匹配"动态的对话演进",最终导致回答偏离、矛盾或缺乏针对性。
简单来说,在多轮聊天(比如你和 AI 聊好几轮那种)里,RAG 这东西(就是先搜资料再生成回答的 AI)最头疼的问题是:它查资料的规矩是死的,但聊天的内容是一直在变的 ------ 聊着聊着话题、需求都不一样了,它还按老办法搜资料,结果要么答跑偏了,要么前后说的不一样,要么根本没说到你真正想要的点上。下面我把为啥会这样、咋改,用更明白的话给你讲清楚。
一、RAG在多轮对话中表现不佳的核心原因
1. 检索与对话历史脱节,相关性下降
传统RAG的检索环节是"单轮独立"的------仅用当前轮用户输入的query生成检索向量,完全忽略对话中积累的上下文关联,相当于"每轮对话都在'失忆'的状态下搜索"。
- 场景1:指代缺失
用户第一轮 :"我想了解华为Mate 60的摄像头配置"
用户第二轮 :"它的电池容量是多少?"
若检索仅基于"电池容量",可能匹配到其他品牌手机的电池信息,而非华为Mate 60的,导致回答跑偏。 - 场景2:隐含约束丢失
用户第一轮 :"帮我找2000元以内的无线耳机"
用户第二轮 :"这款降噪效果怎么样?"
若检索没携带"2000元以内"的约束,可能返回高端耳机的降噪数据,不符合用户预算前提。
2. 上下文窗口限制导致历史信息丢失
大语言模型(LLM)的"上下文窗口"是有限的(比如GPT-4是128k tokens),多轮对话积累的历史内容(用户偏好、之前讨论的细节)会被**"截断丢弃"**,相当于"对话越长,模型越'健忘'"。
- 对生成的影响:前后矛盾
前3轮对话中,用户明确说"我是学生,预算有限",但第5轮时历史信息被截断,模型可能推荐高端产品,与之前的需求冲突。 - 对检索的影响:向量失真
检索需要"当前query + 对话历史"共同生成向量,但如果历史被截断,向量就会"缺斤少两"------比如用户问"这个功能怎么用",但截断了"这个功能"对应的是"某款打印机的扫描功能",检索向量就会变成模糊的"功能使用方法",匹配到无关文档。
3. 知识冲突与一致性难以维护
RAG的检索结果是**"多来源文档的拼接"**,但不同轮次检索到的文档可能存在信息矛盾,而传统RAG没有"一致性校验"的环节,相当于"捡到什么信息就直接说什么"。
- 具体案例:
第1轮检索 :"iPhone 15的屏幕刷新率是60Hz"(来源:旧款机型介绍页)
第3轮检索 :"iPhone 15的屏幕刷新率是120Hz"(来源:新款机型更新公告)
模型会直接复述第3轮的"120Hz",但不会解释"为什么和之前说的不一样",甚至完全忘记之前的结论,让用户觉得"模型不靠谱"。
4. 动态语境适配不足
对话的主题是"流动的"(比如从"手机参数"→"购买渠道"→"售后政策"),但传统RAG的检索策略是"固定的"------向量库是提前构建的、检索的关键词权重是预设的,无法跟着对话主题调整。
- 场景:
对话前2轮在聊"笔记本电脑的性能"(检索关键词:CPU、显卡),第3轮转向"便携性"(需要检索:重量、尺寸),但传统RAG仍会优先匹配"CPU、显卡"相关文档,导致返回的信息和当前主题不相关。
5. 用户意图的"隐性演进"未被捕捉
多轮对话中,用户的需求会从"浅层次事实查询"逐渐升级为"深层次决策支持",但传统RAG的检索库以"事实性文档"为主,缺乏"分析类、对比类"内容,无法跟上意图的变化。
- 意图演进路径:
① 事实查询:"某款投影仪的亮度是多少?"
② 场景适配:"这个亮度适合在客厅用吗?"
③ 对比决策:"和另一款投影仪比,哪个更适合我家客厅?"
传统RAG能满足①,但②需要"亮度与场景的对应关系"文档、③需要"产品对比分析"文档,而这些内容往往不在初始检索库中,导致回答无法满足需求。
二、改进多轮对话中RAG表现的关键策略
针对上述问题,改进的核心是"让RAG具备'对话感知能力'"------从"单轮检索"升级为"多轮动态检索",同时增强生成环节的一致性。
1. 解决"检索与历史脱节":引入"对话记忆模块"
在检索前,先构建一个"对话记忆摘要",将历史上下文压缩成关键信息(比如指代对象、约束条件),再和当前query结合生成检索向量。
- 具体做法:
- 用LLM将每轮对话的关键信息(如"对象:华为Mate 60;约束:2000元以内")提取为"记忆标签";
- 检索时,将"当前query + 记忆标签"拼接后生成向量,确保检索能关联历史信息。
- 效果:
用户问"它的电池容量是多少?"时,检索向量是"华为Mate 60 的电池容量",而非单纯的"电池容量",匹配结果更精准。
2. 解决"上下文窗口限制":优化历史信息的"压缩与调用"
通过"摘要压缩"和"选择性召回",让有限的上下文窗口承载更有效的历史信息。
- 做法1:对话历史摘要
用LLM定期将长对话压缩为"关键信息摘要"(比如每3轮压缩一次),替代原始的长对话文本,减少token占用。 - 做法2:检索式历史召回
不把所有历史都塞进上下文,而是将历史信息存入一个"小型向量库",当需要时,用当前query检索相关的历史片段,只把相关的内容加入上下文。
3. 解决"知识冲突与一致性":增加"检索结果校验环节"
在生成回答前,先对多轮检索到的信息做"一致性检查",识别冲突并处理。
- 具体流程:
- 检索后,用LLM对比当前检索结果与历史回答/检索信息,标记冲突点(如"之前说续航606km,现在是556km");
- 对冲突点,补充检索"冲突原因"(比如"Model 3不同版本续航不同");
- 生成回答时,解释冲突原因,保持逻辑一致。
4. 解决"动态语境适配":采用"主题感知的检索策略"
让RAG能实时识别对话主题,并调整检索的范围和权重。
- 做法:
- 用LLM实时识别当前对话的"主题标签"(比如"性能""便携性""售后");
- 针对不同主题,调用对应的"细分向量库"(比如"性能库"存CPU/显卡数据,"便携性库"存重量/尺寸数据);
- 调整检索关键词的权重(比如主题是"便携性"时,增加"重量""轻薄"的权重)。
5. 解决"隐性意图演进":构建"分层检索库"
将检索库分为"事实层""分析层""决策层",匹配不同阶段的用户意图。
- 分层示例:
- 事实层:产品参数、基础功能说明;
- 分析层:场景适配建议(如"亮度3000流明适合客厅");
- 决策层:产品对比、个性化推荐(如"投影仪A更适合小客厅,投影仪B更适合大空间");
- 效果:用户意图从"事实"升级为"决策"时,RAG能调用对应层级的文档,回答更有针对性。