1.背景与动机:我们为何需要虚拟线程?
在很多现代编程语言中,比如 Go 的 Goroutine、C# 的 async/await、Erlang 的进程、Lua 的协程,都存在一种"轻量级线程"或"协程"技术。它们的核心目标是用更低的成本来处理并发,尤其是 I/O 阻塞型操作。
曾几何时,我们 Java 开发者面对这些高效的并发模型,只能羡慕地看着。传统的 Java 平台线程(Platform Thread)与操作系统(OS)线程是 1:1 的映射,这使得它成为一种"重型"资源:
- 创建成本高:每创建一个平台线程,操作系统都需要为其分配一个独立的、通常大小为 1MB 或更多的栈空间。
- 数量有限:受限于内存和操作系统内核参数,一个 JVM 进程通常只能创建几千个平台线程。
- 上下文切换昂贵:线程调度由 OS 内核完成,涉及用户态到内核态的切换,开销较大。
这些限制迫使我们在高并发 I/O 场景下,不得不转向复杂的异步编程范式,比如 CompletableFuture 和响应式编程框架(Reactive Frameworks如 WebFlux)。虽然这些方案能解决问题,但它们带来了新的挑战:"回调地狱"、陡峭的学习曲线、以及与命令式、顺序化代码风格的割裂,使得代码的编写、调试和维护都变得更加困难。
现在,随着 Java 21 中虚拟线程(Virtual Threads)的正式发布(GA),我们终于可以告别这种两难处境。虚拟线程让我们能够用最直观、最简单的同步阻塞式代码,去实现千万级别的海量并发,让 Java Boy 也能挺起腰杆说:"协程,我们也有,而且更好用!"
2.为什么引入虚拟线程?
让我们通过一个故事来理解虚拟线程的价值。
阶段一:同步阻塞
同事接到一个任务:根据前端传来的 fileId,从文件服务器下载文件,解析内容,然后处理。他很快写出了同步代码:
java
public void doSomething(String fileId) {
String filePath = downloadFile(fileId); // I/O 阻塞
List<XuxianDTO> list = readFile(filePath); // I/O 阻塞
doSomething(list);
}这在请求量小的时候工作得很好。
阶段二:天真的并发
随着业务增长,接口变慢。同事学习了多线程,试图为每个请求创建一个新线程来"提速":
java
public void doSomething(String fileId) {
new Thread(() -> {
String filePath = downloadFile(fileId);
List<XxxDTO> list = readFile(filePath);
doSomething(list);
}).start();
}压测时发现,系统很快就因为创建了过多线程而内存溢出(OutOfMemoryError: unable to create new native thread),并且由于频繁的上下文切换,性能不升反降。
阶段三:线程池优化
在大佬指点下,同事学会了使用线程池来复用和管理线程,避免了资源的无限创建:
java
public void doSomething(String fileId) {
executor.submit(() -> {
String filePath = downloadFile(fileId);
List<XxxDTO> list = readFile(filePath);
doSomething(list);
});
}这套方案在很长一段时间内都表现良好。但线程池并非银弹,它有其固有的问题:
- 吞吐量受限:池中线程数量是有限的。当所有线程都在执行 I/O 阻塞操作时(比如等待慢速的网络响应),新的任务只能在队列中等待,导致吞吐量瓶颈和响应延迟增加。
- 调优复杂:如何设置核心线程数、最大线程数、队列长度,是一个棘手的"猜谜游戏",需要根据负载反复调整。
阶段四:虚拟线程的革命
当请求量达到新的量级,即便是线程池也捉襟见肘。这时,虚拟线程登场了。它完美地解决了上述问题:当一个虚拟线程执行 I/O 阻塞操作时,它不会占用宝贵的平台线程。JVM 会自动将其"挂起"(unmount),并让其底层的"载体线程"(Carrier Thread)去执行其他就绪的虚拟线程。
这意味着,我们可以回归到最简单、最经典的**"一个请求一个线程"**模型,而无需担心资源耗尽。我们可以创建数百万个虚拟线程,轻松应对海量并发连接。
3.什么是虚拟线程?
- 轻量级:由 JVM 在用户空间管理,而非 OS 内核。它的创建和销毁成本极低,内存占用也非常小(几百字节起步)。
- M:N 调度:M 个虚拟线程被调度在 N 个平台线程上运行(M >> N)。默认情况下,JVM 使用一个与 CPU 核心数相当的 ForkJoinPool 作为载体线程池。
- 延续性(Continuations)实现:这是虚拟线程的魔法核心。当虚拟线程阻塞时,它的执行堆栈被保存为一个 Continuation 对象。当阻塞操作完成后,JVM 会找到一个可用的载体线程,恢复这个 Continuation 继续执行。
- 目标:简化高并发 I/O 密集型应用的编程模型,而不是取代平台线程。对于 CPU 密集型任务,平台线程仍然是最佳选择。
工作原理:
- 虚拟线程(Virtual Threads)也被称为纤程(Fibers),其基本的工作原理是将线程的调度从操作系统级别转移到用户级别,即由JVM控制。
- 在传统的线程模型中,每个线程都对应一个操作系统级别的线程,这种线程的创建、切换和销毁等操作都需要系统调用,消耗较大。而且,每个线程都需要一个完整的线程栈,这限制了同时运行的线程数量。
- 相比之下,虚拟线程并不直接对应一个操作系统级别的线程,而是由JVM管理和调度。多个虚拟线程可能共享一个操作系统级别的线程。这样,当一个虚拟线程阻塞时,JVM可以立即切换到另一个虚拟线程,而无需等待操作系统的调度。而且,虚拟线程不需要一个完整的线程栈,所以可以创建大量的虚拟线程。
- JDK 的虚拟线程调度器是一个以
FIFO模式运行的ForkJoinPool,调度器可以通过设置启动参数调整,代码如下:
java
VirtualThread类下面
private static ForkJoinPool createDefaultScheduler() {
ForkJoinWorkerThreadFactory factory = pool -> {
PrivilegedAction<ForkJoinWorkerThread> pa = () -> new CarrierThread(pool);
return AccessController.doPrivileged(pa);
};
PrivilegedAction<ForkJoinPool> pa = () -> {
int parallelism, maxPoolSize, minRunnable;
String parallelismValue = System.getProperty("jdk.virtualThreadScheduler.parallelism");
String maxPoolSizeValue = System.getProperty("jdk.virtualThreadScheduler.maxPoolSize");
String minRunnableValue = System.getProperty("jdk.virtualThreadScheduler.minRunnable");
... //省略赋值操作
Thread.UncaughtExceptionHandler handler = (t, e) -> { };
boolean asyncMode = true; // FIFO
return new ForkJoinPool(parallelism, factory, handler, asyncMode,
0, maxPoolSize, minRunnable, pool -> true, 30, SECONDS);
};
return AccessController.doPrivileged(pa);
}- 调度器分配给虚拟线程的平台线程称为虚拟线程的载体线程(carrier)。虚拟线程可以在其生命周期内会被安排在不同的载体线程上。
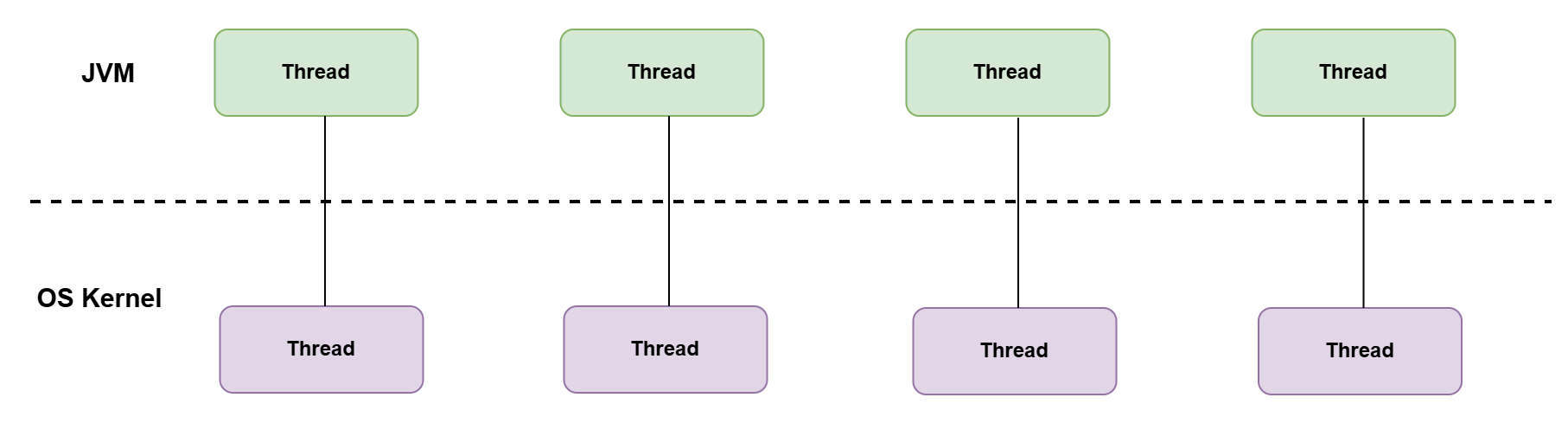
传统线程于OS Thread关系图:
虚拟线程与平台线程的关系图:
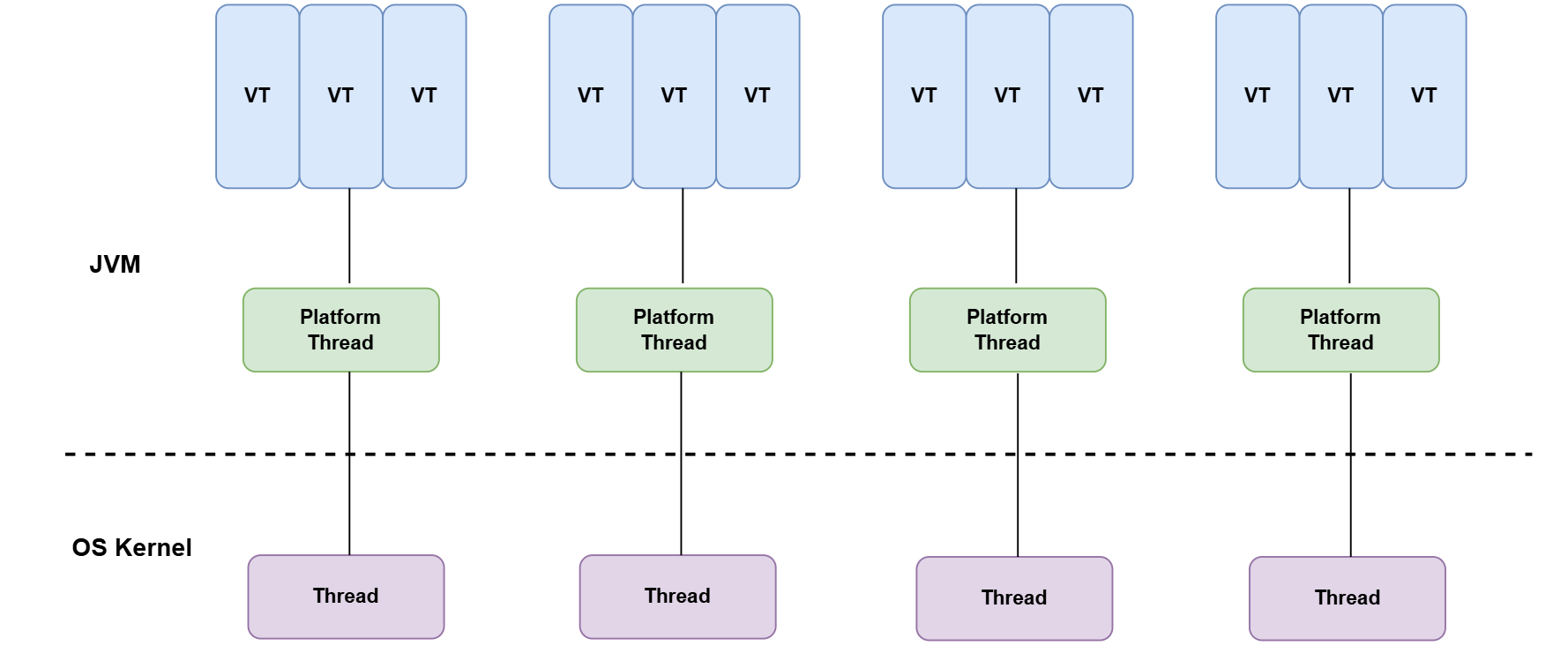
JVM 通过平台线程来管理虚拟线程,一个平台线程可以在不同的时间执行不同的虚拟线程,当虚拟线程被阻塞或等待时,平台线程可以切换到执行另一个虚拟线程,一个平台线程同时只会执行一个虚拟线程。
每个请求对应一个线程的应用代码可以在请求的整个持续时间内在虚拟线程中运行,但虚拟线程仅在 CPU 上执行计算时才消耗操作系统线程。这样可以获得异步编程相同的并发性,并且是以透明方式实现的。当虚拟线程中运行的代码调用 java.* API 中的阻塞 I/O 操作时,运行时执行非阻塞操作系统调用,并自动挂起虚拟线程直到它可以恢复的时候。
对于 Java 开发来说,虚拟线程只是创建成本低廉且数量几乎无限的线程。硬件利用率接近最佳,允许高水平的并发性,从而实现高吞吐量,同时代码实现与 Java 及其工具的多线程设计保持风格一致。
4.与其他语言协程模型的对比
虽然目标相似,但实现和使用体验上各有千秋。
| 特性 | Java虚拟线程 | Go Goroutine | C# async/await | Erlang 进程 | Lua协程 |
|---|---|---|---|---|---|
| 调度方式 | JVM 调度器;工作窃取 | Go 运行时;M:N 调度 | 编译器生成状态机,通过 await 关键字协作式调度 | 抢占式轻量级进程调度 | 手动调用 yield/resume 进行协作式调度 |
| 内存占用 | 动态增长,初始极小 | 几 KB | 每个异步方法一个状态机对象 | 几 KB 堆/栈 | 共享栈切片 |
| 调试模型 | 与平台线程几乎一致,支持标准 Thread API | Goroutine 专属的内省工具 | 通过 Task 对象追踪调用链 | 基于进程邮箱和消息 | 手动追踪 |
| 阻塞 I/O | 直接使用阻塞式 API,JVM 自动处理 | 直接使用阻塞式 API,运行时处理 | 必须使用 await 配合 Async 后缀的 API | 基于消息传递,天然非阻塞 | 手动处理阻塞 |
| 代码风格 | 同步、顺序化 | 同步、顺序化 | 结构化异步(async/await 语法糖) | Actor 模型 | 生成器风格 |
核心优势总结:Java 虚拟线程最大的优势在于对现有生态的无缝兼容和对开发者的透明性。你不需要学习新的 async/await 语法,也不需要改造海量的第三方库。你只需要将任务提交给虚拟线程执行器,就可以用最熟悉的方式编写代码,享受协程带来的高并发能力。
5.核心内部概念
- 挂载/卸载 (Mount / Unmount):虚拟线程运行时,会"挂载"到一个载体线程上。当遇到受支持的阻塞操作(如 Socket.read(), Thread.sleep(), BlockingQueue.take())时,它会自动"卸载",释放载体线程。
- 钉住 (Pinning):这是使用虚拟线程时需要特别注意的陷阱。某些情况下,虚拟线程无法被卸载,会一直"钉"在载体线程上,即使它发生了阻塞。这会严重影响可伸缩性。常见原因包括:
- 执行 synchronized 同步块或方法。
- 执行 JNI(Java Native Interface)本地方法。
- 执行某些特定的 JVM 内部操作。 解决方案:使用 java.util.concurrent.locks.ReentrantLock 替代 synchronized。
- 结构化并发 (Structured Concurrency - 预览特性):这是一个强大的编程模型,通过 StructuredTaskScope 来管理一组并发任务的生命周期。它能确保:
任务归属:子任务的生命周期被限定在父任务的作用域内。
错误处理:一个子任务失败,可以立即取消其他所有子任务。
结果聚合:简化了等待所有子任务完成并收集结果的逻辑。 这极大地简化了并发代码的健壮性和可维护性,类似于 Go 的 Context 和 errgroup。
6.何时使用虚拟线程?
黄金法则:虚拟线程适用于 I/O 密集型或"等待密集型"任务,而非 CPU 密集型任务。
理想场景 (I/O Bound):
- 处理大量并发的 Web 请求、API 调用。
- 微服务之间的 RPC 通信。
- 数据库访问(JDBC)。
- 消息队列的消费和生产。
- 任何涉及网络和文件系统读写的操作。
避免场景 (CPU Bound):
- 复杂的数学计算、科学模拟。
- 视频编码、图像处理。
- 大规模数据排序、加密解密。
- 在这些场景下,继续使用传统的平台线程池或 Parallel Streams。
7.局限性与注意事项
- 不要池化虚拟线程:虚拟线程本身就是轻量级的,创建成本极低。池化它们毫无意义,反而会增加复杂性。应该为每个任务创建一个新的虚拟线程。
- 警惕 ThreadLocal:由于可能创建数百万个虚拟线程,如果大量使用 ThreadLocal,每个虚拟线程都会持有一份副本,可能导致巨大的内存消耗。
替代方案:优先使用方法传参。对于需要在调用链中传递的数据,使用 Java 21 引入的作用域值 (Scoped Values - 预览特性),它更高效且不可变。
3.注意"钉住" (Pinning):使用诊断工具(如 JFR)来检测和分析线程钉住的情况。
4.第三方库兼容性:检查你使用的 I/O 相关库(如数据库驱动、HTTP客户端)是否已经针对虚拟线程进行 了优化,避免它们内部的线程池成为瓶颈。
5.监控与诊断:传统的线程 Dump 会变得非常庞大。需要学习使用新的工具和方法:
- jcmd Thread.print -virtual:只打印虚拟线程信息。
- Java Flight Recorder (JFR):提供了丰富的虚拟线程事件,如启动、结束、钉住等。
8.迁移策略
将现有应用迁移到虚拟线程通常很简单:
- 升级 JDK:确保项目使用 Java 21 或更高版本。
- 识别 I/O 密集型代码:找到那些使用 ExecutorService 处理网络请求、数据库查询等任务的地方。
- 替换执行器:将 Executors.newFixedThreadPool() 或 newCachedThreadPool() 替换为 Executors.newVirtualThreadPerTaskExecutor()。
- 审计同步块:检查 I/O 操作是否被包裹在 synchronized 块中,如果是,则替换为 ReentrantLock。
- 保留 CPU 密集型线程池:不要改动用于处理计算密集型任务的线程池。
- 测试与监控:进行充分的性能测试,并使用 JFR 等工具监控虚拟线程的行为和载体线程的利用率。
9.最佳实践
- 保持同步阻塞风格:拥抱虚拟线程带来的简单性,不要画蛇添足地混合 CompletableFuture。
- 任务生命周期要短:遵循"一个任务一个虚拟线程"的模式,任务执行完后线程就销毁。
- 使用 try-with-resources:对于 ExecutorService,使用 try-with-resources 语句可以确保线程池被正确关闭。
- 善用结构化并发:当一个任务需要派生多个并发子任务时,优先使用 StructuredTaskScope。
- 批量处理依然有效:虽然虚拟线程可以处理大量并发,但在数据库操作等场景,适当的批量处理仍然是提升性能的好方法。
10.代码示例
示例 1:简单的虚拟线程创建
java
import java.util.concurrent.*;
public class VirtualThreadExamples {
// 方式一:最简单的方式
public void simpleStart() {
Thread.startVirtualThread(() -> System.out.println("虚拟线程已启动 - " + Thread.currentThread()));
}
// 方式二:使用构建器,可进行更多配置
public void builderStart() {
Thread.ofVirtual()
.name("my-virtual-thread")
.uncaughtExceptionHandler((t, e) -> System.err.println("线程 " + t.getName() + " 异常: " + e.getMessage()))
.start(() -> System.out.println("构建的虚拟线程已启动 - " + Thread.currentThread()));
}
// 方式三:创建但不立即启动
public void unstartedThenRun() throws InterruptedException {
Thread vt = Thread.ofVirtual().unstarted(() -> System.out.println("延迟启动的虚拟线程 - " + Thread.currentThread()));
vt.start();
vt.join(); // 等待其完成
}
// 方式四:使用专用的 ExecutorService
public void perTaskExecutor() throws Exception {
try (ExecutorService exec = Executors.newVirtualThreadPerTaskExecutor()) {
Future<String> future = exec.submit(() -> {
Thread.sleep(100);
return "任务在虚拟线程中完成";
});
System.out.println(future.get());
}
}
}示例 2:重构阻塞工作流
这个例子展示了如何将一个包含下载、解析和聚合的复杂 I/O 密集型任务,用虚拟线程和结构化并发进行重构。
java
import java.io.IOException;
import java.nio.file.*;
import java.util.*;
import java.util.concurrent.*;
import java.util.stream.Collectors;
import jdk.incubator.concurrent.StructuredTaskScope; // 使用预览特性
public class VirtualThreadFileProcessor {
// 用于 I/O 密集型任务的虚拟线程执行器
private final ExecutorService vExecutor = Executors.newVirtualThreadPerTaskExecutor();
// 用于 CPU 密集型任务的平台线程池
private final ExecutorService cpuExecutor = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
public CompletableFuture<ProcessingResult> processFile(String fileId) {
// 整个流程提交给虚拟线程执行
return CompletableFuture.supplyAsync(() -> {
String path = downloadFile(fileId); // 阻塞 I/O
List<String> lines = readLines(path); // 阻塞文件 I/O
return parseAndAggregate(lines);
}, vExecutor);
}
private String downloadFile(String fileId) {
System.out.println("下载文件 " + fileId + " on " + Thread.currentThread());
try {
Thread.sleep(Duration.ofMillis(50)); // 模拟网络 I/O
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
return "/tmp/" + fileId + ".dat";
}
private List<String> readLines(String path) {
try {
// 假设文件已创建
// Files.createFile(Path.of(path));
return Files.readAllLines(Path.of(path));
} catch (IOException e) {
return List.of();
}
}
private ProcessingResult parseAndAggregate(List<String> lines) {
// 使用结构化并发来并行解析文件的各个部分
List<ParsedChunk> parsedChunks;
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
List<Future<ParsedChunk>> futures = new ArrayList<>();
for (List<String> chunk : splitIntoChunks(lines, 4)) {
futures.add(scope.fork(() -> parseChunk(chunk)));
}
scope.join(); // 等待所有子任务完成
scope.throwIfFailed(); // 如果有任何子任务失败,则抛出异常
parsedChunks = futures.stream().map(Future::resultNow).collect(Collectors.toList());
} catch (InterruptedException | ExecutionException e) {
Thread.currentThread().interrupt();
return new ProcessingResult(0, Map.of());
}
// 最后的聚合是 CPU 密集型任务,提交给平台线程池
try {
return cpuExecutor.submit(() -> summarize(parsedChunks)).get();
} catch (InterruptedException | ExecutionException e) {
Thread.currentThread().interrupt();
return new ProcessingResult(0, Map.of());
}
}
}11.性能压测
11.1 前置准备
Spring Boot: 3.5.5
JDK: zulu-21 21.0.9
压测工具:k6
运行配置:win11 12C 36G11.2 压测代码
模拟io请求
-
未开启虚拟线程
java@GetMapping("/test/{timeMillis}") public Object test(@PathVariable long timeMillis) throws InterruptedException { Map<String, Object> map = new HashMap<>(); map.put("time", System.currentTimeMillis()); map.put("msg", "test"); map.put("thread", Thread.currentThread().toString()); Thread.sleep(timeMillis); return map; } -
开启虚拟线程
请求同上,增加如下配置
java@EnableAsync @Configuration @ConditionalOnProperty(value = "spring.executor", havingValue = "virtual") public class ThreadConfig { @Bean public AsyncTaskExecutor applicationTaskExecutor() { return new TaskExecutorAdapter(Executors.newVirtualThreadPerTaskExecutor()); } @Bean public TomcatProtocolHandlerCustomizer<?> protocolHandlerVirtualThreadExecutorCustomizer() { return protocolHandler -> { protocolHandler.setExecutor(Executors.newVirtualThreadPerTaskExecutor()); }; } }application.yml
yamlspring: #配置virtual表示启用虚拟线程,非virtual表示不启用 executor: virtual threads: virtual: enabled: true -
压测脚本
simple-test.js
javascriptimport http from 'k6/http'; import { check } from 'k6'; export default function () { const res = http.get(`${__ENV.url}`); check(res, { 'is status 200': (r) => r.status === 200 }); }
11.3 压测结果
依次调整-u 参数(200,400,600,800,1000)并执行如下命令
bash
k6 run -u 200 --duration 60s -e url=http://127.0.0.1:8080/test/100 simple-test.js-
压测结果
tex未开启虚拟线程 1.200并发,逐步递增结果 HTTP http_req_duration..............: avg=108.84ms min=100.09ms med=108.58ms max=186.45ms p(90)=110.68ms p(95)=111.62ms { expected_response:true }...: avg=108.84ms min=100.09ms med=108.58ms max=186.45ms p(90)=110.68ms p(95)=111.62ms http_req_failed................: 0.00% 0 out of 110184 http_reqs......................: 110184 1833.622197/s EXECUTION iteration_duration.............: avg=108.99ms min=100.36ms med=108.73ms max=186.45ms p(90)=110.82ms p(95)=111.77ms iterations.....................: 110184 1833.622197/s vus............................: 200 min=200 max=200 vus_max........................: 200 min=200 max=200 NETWORK data_received..................: 25 MB 409 kB/s data_sent......................: 8.7 MB 145 kB/s 2.400并发,逐步递增结果 HTTP http_req_duration..............: avg=215.23ms min=100.44ms med=216.83ms max=263.05ms p(90)=219.37ms p(95)=220.42ms { expected_response:true }...: avg=215.23ms min=100.44ms med=216.83ms max=263.05ms p(90)=219.37ms p(95)=220.42ms http_req_failed................: 0.00% 0 out of 111634 http_reqs......................: 111634 1854.160819/s EXECUTION iteration_duration.............: avg=215.34ms min=100.44ms med=216.93ms max=263.05ms p(90)=219.49ms p(95)=220.53ms iterations.....................: 111634 1854.160819/s vus............................: 400 min=400 max=400 vus_max........................: 400 min=400 max=400 NETWORK data_received..................: 25 MB 414 kB/s data_sent......................: 8.8 MB 147 kB/s 3.600并发,逐步递增结果 HTTP http_req_duration..............: avg=322.04ms min=0s med=325.31ms max=389.61ms p(90)=328.76ms p(95)=330.02ms { expected_response:true }...: avg=322.79ms min=101.37ms med=325.32ms max=389.61ms p(90)=328.77ms p(95)=330.02ms http_req_failed................: 0.23% 259 out of 111969 http_reqs......................: 111969 1856.220501/s EXECUTION iteration_duration.............: avg=322.24ms min=2.16ms med=325.43ms max=390.61ms p(90)=328.84ms p(95)=330.09ms iterations.....................: 111969 1856.220501/s vus............................: 600 min=600 max=600 vus_max........................: 600 min=600 max=600 NETWORK data_received..................: 25 MB 413 kB/s data_sent......................: 8.8 MB 146 kB/s 4.800并发,逐步递增结果 HTTP http_req_duration..............: avg=430.68ms min=100.61ms med=433.68ms max=540.35ms p(90)=437.1ms p(95)=438.25ms { expected_response:true }...: avg=430.68ms min=100.61ms med=433.68ms max=540.35ms p(90)=437.1ms p(95)=438.25ms http_req_failed................: 0.38% 421 out of 111765 http_reqs......................: 111765 1849.543354/s EXECUTION iteration_duration.............: avg=430.8ms min=100.6ms med=433.79ms max=540.34ms p(90)=437.2ms p(95)=438.33ms iterations.....................: 111765 1849.543354/s vus............................: 800 min=800 max=800 vus_max........................: 800 min=800 max=800 NETWORK data_received..................: 25 MB 413 kB/s data_sent......................: 8.8 MB 146 kB/s 5.1000并发,逐步递增结果 HTTP http_req_duration..............: avg=529.78ms min=0s med=542.67ms max=609.58ms p(90)=546.22ms p(95)=547.36ms { expected_response:true }...: avg=532.93ms min=100.4ms med=542.71ms max=609.58ms p(90)=546.22ms p(95)=547.37ms http_req_failed................: 0.58% 664 out of 112577 http_reqs......................: 112577 1859.599297/s EXECUTION iteration_duration.............: avg=535.02ms min=26.48ms med=542.82ms max=1.82s p(90)=546.35ms p(95)=547.61ms iterations.....................: 112577 1859.599297/s vus............................: 1000 min=1000 max=1000 vus_max........................: 1000 min=1000 max=1000 NETWORK data_received..................: 25 MB 413 kB/s data_sent......................: 8.8 MB 146 kB/s 开启虚拟线程 1.200并发,逐步递增结果 HTTP http_req_duration..............: avg=108.66ms min=100.25ms med=108.51ms max=176.59ms p(90)=110.48ms p(95)=111.32ms { expected_response:true }...: avg=108.66ms min=100.25ms med=108.51ms max=176.59ms p(90)=110.48ms p(95)=111.32ms http_req_failed................: 0.00% 0 out of 110299 http_reqs......................: 110299 1835.872398/s EXECUTION iteration_duration.............: avg=108.8ms min=100.25ms med=108.64ms max=177.59ms p(90)=110.64ms p(95)=111.48ms iterations.....................: 110299 1835.872398/s vus............................: 200 min=200 max=200 vus_max........................: 200 min=200 max=200 NETWORK data_received..................: 28 MB 472 kB/s data_sent......................: 8.7 MB 145 kB/s 2.400并发,逐步递增结果 HTTP http_req_duration..............: avg=107.99ms min=0s med=108.28ms max=164.37ms p(90)=110.43ms p(95)=111.35ms { expected_response:true }...: avg=108.07ms min=99.72ms med=108.28ms max=164.37ms p(90)=110.43ms p(95)=111.35ms http_req_failed................: 0.07% 170 out of 221398 http_reqs......................: 221398 3684.402592/s EXECUTION iteration_duration.............: avg=108.43ms min=52.76ms med=108.42ms max=730.24ms p(90)=110.61ms p(95)=111.58ms iterations.....................: 221398 3684.402592/s vus............................: 400 min=400 max=400 vus_max........................: 400 min=400 max=400 NETWORK data_received..................: 57 MB 952 kB/s data_sent......................: 18 MB 291 kB/s 3.600并发,逐步递增结果 HTTP http_req_duration..............: avg=110.42ms min=0s med=108.79ms max=423.9ms p(90)=118.33ms p(95)=121.75ms { expected_response:true }...: avg=110.66ms min=99.83ms med=108.79ms max=423.9ms p(90)=118.34ms p(95)=121.76ms http_req_failed................: 0.21% 676 out of 321730 http_reqs......................: 321730 5351.582218/s EXECUTION iteration_duration.............: avg=111.88ms min=1.76ms med=108.95ms max=1.6s p(90)=118.67ms p(95)=122.18ms iterations.....................: 321730 5351.582218/s vus............................: 600 min=600 max=600 vus_max........................: 600 min=600 max=600 NETWORK data_received..................: 83 MB 1.4 MB/s data_sent......................: 25 MB 422 kB/s 4.800并发,逐步递增结果 HTTP http_req_duration..............: avg=128.88ms min=0s med=120.97ms max=774.13ms p(90)=152.35ms p(95)=184.17ms { expected_response:true }...: avg=129.15ms min=100.51ms med=120.99ms max=774.13ms p(90)=152.4ms p(95)=184.34ms http_req_failed................: 0.20% 752 out of 361920 http_reqs......................: 361920 6021.494579/s EXECUTION iteration_duration.............: avg=132.49ms min=32.43ms med=121.36ms max=2.95s p(90)=156.14ms p(95)=192.7ms iterations.....................: 361920 6021.494579/s vus............................: 800 min=800 max=800 vus_max........................: 800 min=800 max=800 NETWORK data_received..................: 94 MB 1.6 MB/s data_sent......................: 29 MB 475 kB/s 5.1000并发,逐步递增结果 HTTP http_req_duration..............: avg=128.56ms min=0s med=121.77ms max=652.69ms p(90)=149.55ms p(95)=175.48ms { expected_response:true }...: avg=128.8ms min=100.27ms med=121.79ms max=652.69ms p(90)=149.58ms p(95)=175.55ms http_req_failed................: 0.18% 837 out of 450901 http_reqs......................: 450901 7489.132676/s EXECUTION iteration_duration.............: avg=132.99ms min=10.83ms med=122.25ms max=4.98s p(90)=153.34ms p(95)=183.58ms iterations.....................: 450901 7489.132676/s vus............................: 1000 min=1000 max=1000 vus_max........................: 1000 min=1000 max=1000 NETWORK data_received..................: 117 MB 1.9 MB/s data_sent......................: 36 MB 591 kB/s
11.4 压测结果分析
- 未开启虚拟线程 vs 开启虚拟线程对比表
| Case | 类型 | QPS | 平均延迟 | p95延迟 | 失败率 |
|---|---|---|---|---|---|
| -u 200 | 传统线程 | 1833.62 | 108.84ms | 111.62ms | 0.00% |
| -u 200 | 虚拟线程 | 1835.87 | 108.66ms | 111.32ms | 0.00% |
| -u 400 | 传统线程 | 1854.16 | 215.23ms | 220.42ms | 0.00% |
| -u 400 | 虚拟线程 | 3684.40 | 107.99ms | 111.35ms | 0.07% |
| -u 600 | 传统线程 | 1856.22 | 322.04ms | 330.02ms | 0.23% |
| -u 600 | 虚拟线程 | 5351.58 | 110.42ms | 121.75ms | 0.21% |
| -u 800 | 传统线程 | 1849.54 | 430.68ms | 438.25ms | 0.38% |
| -u 800 | 虚拟线程 | 6021.49 | 128.88ms | 184.17ms | 0.20% |
| -u 1000 | 传统线程 | 1859.60 | 529.78ms | 547.36ms | 0.58% |
| -u 1000 | 虚拟线程 | 7489.13 | 128.56ms | 175.48ms | 0.18% |
2.QPS对比
未开启虚拟线程: ≈1850 req/s (各并发级别基本持平)
开启虚拟线程: 从≈1835增长至≈7489 req/s (+306%)3.平均延迟对比
未开启虚拟线程: 从108.84ms增至529.78ms (+387%)
开启虚拟线程: 维持在107.99ms-128.88ms之间 (相对稳定)4.平均延迟对比
未开启虚拟线程: 从111.62ms增至547.36ms (+390%)
开启虚拟线程: 从111.32ms增至175.48ms (+57.6%)结论
- 吞吐量显著提升
在1000并发下,开启虚拟线程的QPS是未开启时的4倍以上
随着并发数增加,传统线程模式性能趋于饱和,而虚拟线程模式仍能线性增长 - 延迟表现优异
未开启虚拟线程时,平均延迟随并发数线性增长(108ms→529ms)
开启虚拟线程后,平均延迟保持稳定(107ms-128ms)
P95延迟增长幅度明显减缓,虚拟线程优势明显 - 系统稳定性更好
传统线程模式失败率随并发数递增(0%→0.58%)
虚拟线程模式失败率维持在较低水平(0.07%→0.18%) - 资源利用效率更高
相同硬件条件下,虚拟线程能处理4倍以上的并发请求
网络传输速度也有相应提升,说明整体系统效率更高
12.总结
虚拟线程是 Java 并发编程的一次重大飞跃。它让我们能够:
- 以简单的同步代码风格,编写出具备极高吞吐量的 I/O 密集型应用。
- 显著降低资源消耗,轻松支持百万级并发连接。
- 摆脱复杂的异步和响应式编程范式,提高开发效率和代码可维护性。
对于我们团队而言,这意味着在未来的项目中,面对高并发 I/O 场景,我们可以优先考虑使用虚拟线程来构建更简单、更健壮、更易于维护的系统。