目录
[一、 不懂就问,才是好助理](#一、 不懂就问,才是好助理)
[二、 能抄近道,绝不瞎点屏幕](#二、 能抄近道,绝不瞎点屏幕)
[三、 大脑在云端,小脑在手机](#三、 大脑在云端,小脑在手机)
[四、 在混乱中学会生存](#四、 在混乱中学会生存)
[五、 开源与未来](#五、 开源与未来)

🎬 攻城狮7号 :个人主页
🔥 个人专栏 :《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 通用 GUI 智能体基座 MAI-UI 开源
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
过去两年,我们看过太多令人眼花缭乱的AI Agent演示视频。 视频里,AI帮人点外卖、发邮件、订机票,行云流水。但当你真正上手这些所谓的"AI手机"或"自动操作助手"时,现实往往很骨感:
要么是APP稍微改了个版,AI就找不到按钮了;要么是遇到一个弹窗广告,AI就卡死在那里发呆;最可怕的是,当你指令稍微模糊一点,AI可能就自作主张帮你下单了不想要的东西。
**为什么实验实里的Demo到现实中就成了"人工智障"?**核心原因在于真实世界的手机界面(GUI)太复杂、太动态,且容错率极低。
最近,阿里通义实验室开源了一个名为 MAI-UI 的项目,并在多个权威榜单上拿到了第一。它不只是一个模型,更是一套试图解决上述"落地难"问题的完整方法论。今天我们就来扒一扒,它到底做对了什么?


一、 不懂就问,才是好助理
现在的很多AI Agent都有个坏毛病:盲目自信。
比如你跟AI说:"帮我买点水果。" 传统的GUI智能体可能会直接打开生鲜APP,随便加购一箱苹果然后下单。等你发现时,快递可能都发出了。这种"一根筋"执行任务的方式,在容错率极高的聊天场景里没问题,但在涉及花钱、发消息等严肃操作的GUI场景里,简直是灾难。
MAI-UI引入了一个非常像人类助理的特性:主动交互(Agent-User Interaction)。
它被训练成在遇到模糊指令或关键信息缺失时,先"停下来",问清楚再动手。
举个例子,你说:"查一下日历,看看我老婆交代的购物清单,帮我买一下。"
MAI-UI读取日历后发现写着"车厘子、洗衣液"。
此时它不会直接下单,而是会弹窗问你:"老板,日历里写了车厘子和洗衣液,这两样都要买吗?还是只买水果?"
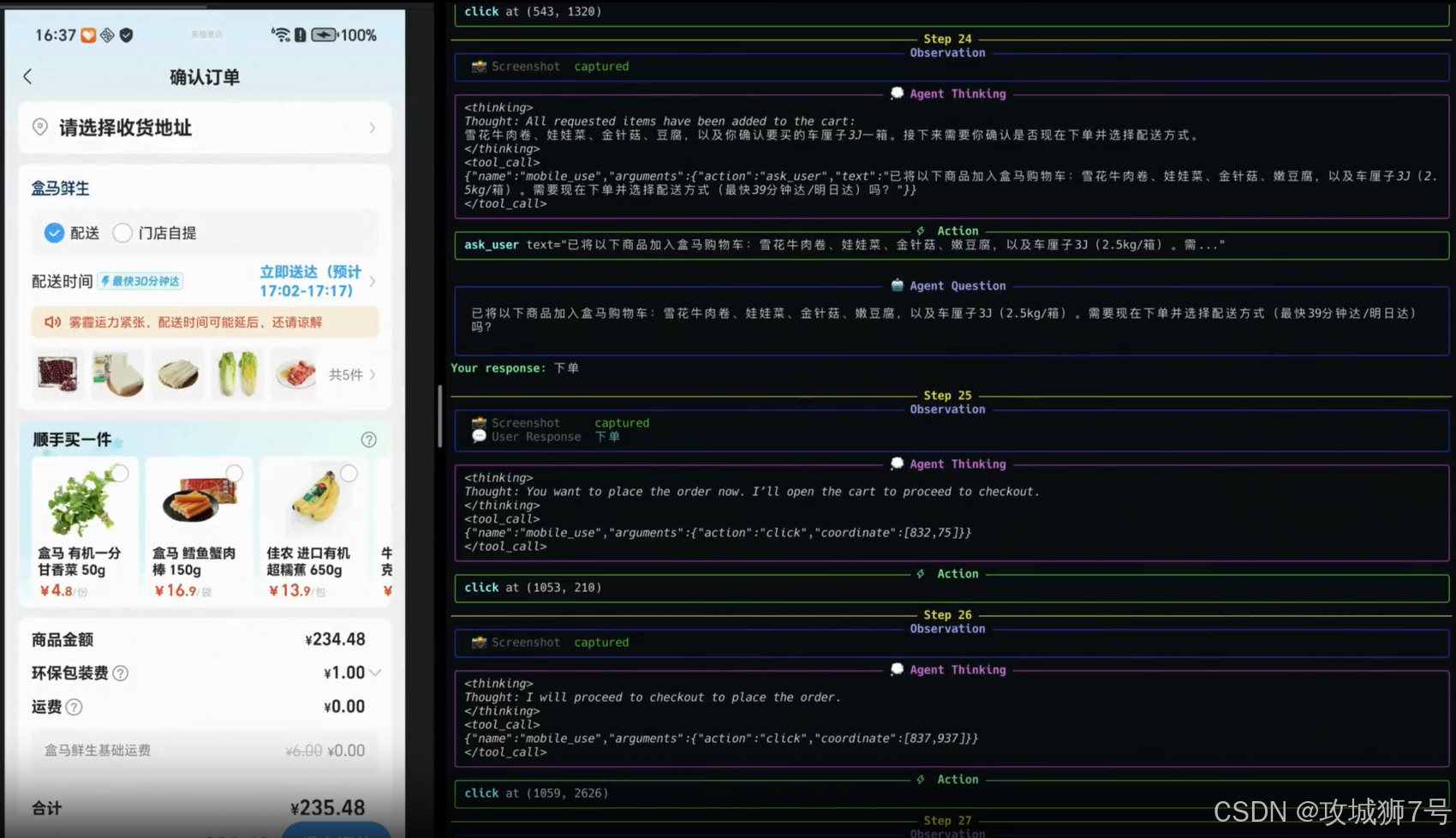
这种能力听起来很简单,但在模型训练层面其实很难。因为大部分训练数据都是"指令-动作"的单向执行流。MAI-UI团队专门构建了一套数据管线,强行让模型学会输出 `ask_user`(询问用户)这个动作。
只有当用户确认后,它才会继续执行。这不仅减少了"瞎操作"的风险,更重要的是,它让AI看起来更靠谱、更懂事了。
二、 能抄近道,绝不瞎点屏幕
操作图形界面(GUI)其实是一件效率很低且极不稳定的事。
想象一下,你要规划一个从公司去客户那里的行程,并记录到备忘录里。
如果是纯模仿人类操作的AI,它需要:
(1)打开地图APP,等启动广告过去。
(2)点击搜索框,输入地址。
(3)在列表里找到正确的地点,点击路线。
(4)截图识别时间。
(5)切后台到备忘录,新建笔记,打字输入。
这中间任何一个环节------比如地图APP突然弹出一个"领打车券"的弹窗,或者网速慢加载不出来------整个任务链条就断了。
MAI-UI 的聪明之处在于,它是个"混血儿"。它既能像人一样点屏幕,也能像程序员一样调接口(MCP, Model Context Protocol)。
当它发现任务太复杂,或者有现成的工具可以用时,它会优先选择"抄近道"。
在上面的例子中,MAI-UI可能会直接在后台调用高德地图的API接口拿到路线数据,然后直接调用系统的笔记API写入内容。几十步的屏幕点击操作,被压缩成了两次API调用。
这种"工具优先"的策略,极大地提升了任务的成功率。毕竟,API接口比那千变万化的UI界面要稳定得多。在阿里发布的MobileWorld评测中,这种混合模式让成功率直接翻倍。
三、 大脑在云端,小脑在手机
把几十亿参数的大模型塞进手机,一直是个行业难题。模型太小,智商不够,处理不了复杂任务;模型太大,手机发烫耗电,而且反应慢。
更关键的是隐私问题。如果我让AI帮我转账,或者处理相册里的私密照片,我绝对不想这些数据被上传到云端服务器。
MAI-UI 提出了一套原生的**"端云协同"** 架构,简单来说就是:小鬼当家,大佬兜底。
平时: 一个轻量级的 **2B(20亿参数)**模型常驻在手机端。它反应快、功耗低,负责处理像"定闹钟"、"查天气"、"打开APP"这种日常琐事。同时,它还扮演"监工"的角色,实时监控操作有没有跑偏。
遇到难题: 当任务变得复杂(比如跨三个APP做旅行规划),或者端侧小模型尝试了几次都失败了,系统会判断:当前数据敏感吗?
如果不敏感(比如查公开的火车票),它会把任务无缝"甩锅"给云端的 32B 大模型。云端大模型"智商"高,能处理复杂逻辑。
如果涉及隐私(比如输入支付密码、查看身份证照片),系统会强制在本地死磕,绝不上传。
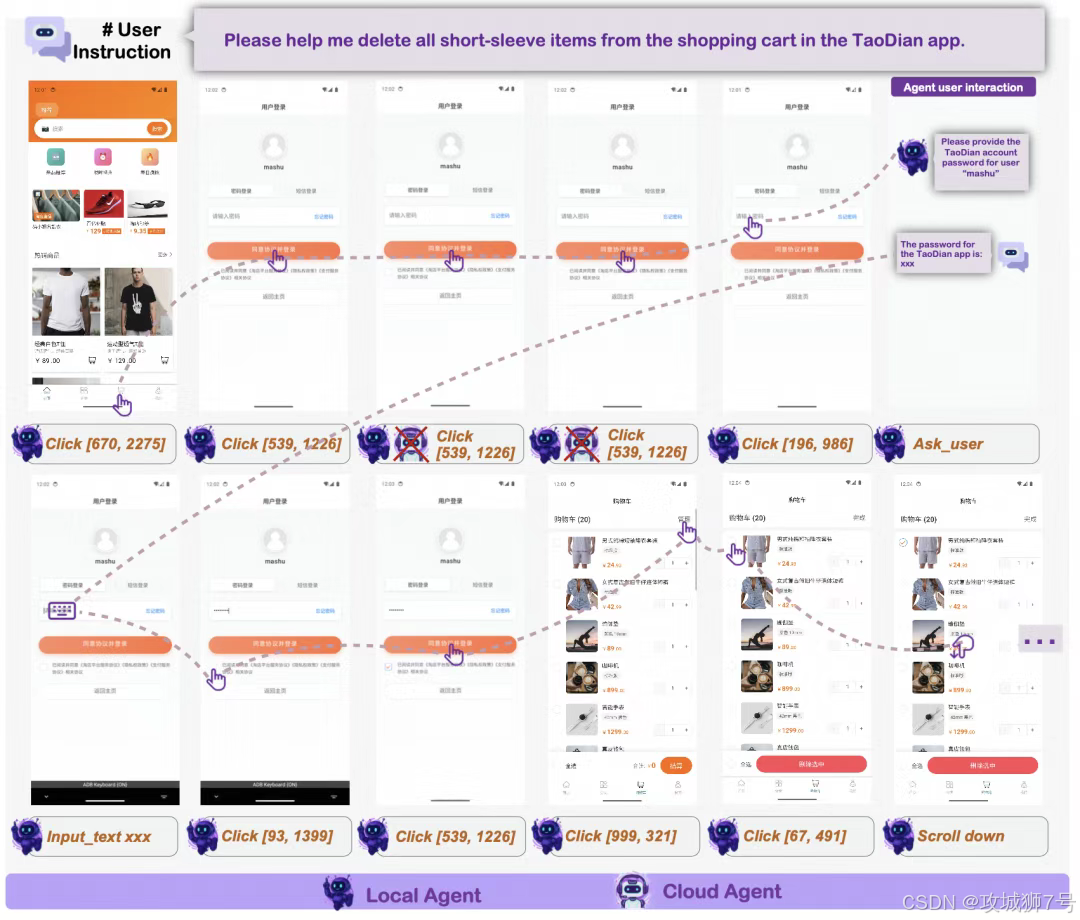
最妙的是,在从手机切换到云端时,小模型会自动生成一份"错误摘要",告诉云端大模型:"大哥,我刚才在第3步卡住了,原因是找不到按钮,你接着来。"这种接力机制,既保证了隐私和体验,又兼顾了能力上限。
四、 在混乱中学会生存
真实环境下的手机操作,充满了不可预测的动态干扰。
你正操作着,突然跳出来一个微信视频通话;或者你想点的按钮因为页面没加载完,突然"瞬移"到了别的地方。
传统的AI是在静态数据上训练的,遇到这种情况通常会当场"死机"。
而MAI-UI引入了在线强化学习(Online RL)。通义团队搭建了一个包含数百个并行环境的训练场,专门给AI"上强度"。他们会在训练中故意制造麻烦:突然弹窗、让按钮偏移、让APP响应变慢。
模型被迫在这些混乱中通过试错来学习。它学会了:
(1)点了没反应?那就多点几次,或者等等。
(2)突然有弹窗?先把它关掉,再继续原来的任务。
(3)进错页面了?点返回键退出来,重新找入口。
这种像人类一样的"鲁棒性",是以前那些只能在实验室温室里跑通Demo的AI所不具备的。在AndroidWorld榜单上,MAI-UI的成功率大幅领先,靠的就是这种在泥坑里摸爬滚打出来的生存能力。
五、 开源与未来
这次通义实验室不仅开源了从2B到32B的全系列模型,还开源了一个名为 MobileWorld 的评测基准。
这个基准非常有意思,它不再是简单的"点这个按钮",而是包含了大量跨APP的长链路任务,甚至包含了需要和用户多轮对话才能搞定的任务。这其实是在倒逼整个行业:别再刷那些简单的榜单了,来点真实的。
MAI-UI 的出现,标志着GUI智能体从"玩具"向"工具"迈出了一大步。它不再追求在完美的实验环境下拿高分,而是开始正视真实世界的脏乱差------弹窗、隐私、网络延迟、模糊指令。
未来的AI手机,可能不会再是一个简单的语音助手,而是一个真正能像你一样,看着屏幕,理解你的犹豫,帮你搞定繁琐操作的"数字分身"。MAI-UI,让我们看到了这个未来的一角。
相关链接 :
🔗GitHub(MAI-UI):https://github.com/Tongyi-MAI/MAI-UI
🔗Arxiv(MAI-UI):http://arxiv.org/abs/2512.22047
🔗GitHub(MobileWorld):https://github.com/Tongyi-MAI/MobileWorld
🔗Arxiv(MobileWorld):https://arxiv.org/abs/2512.19432
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!