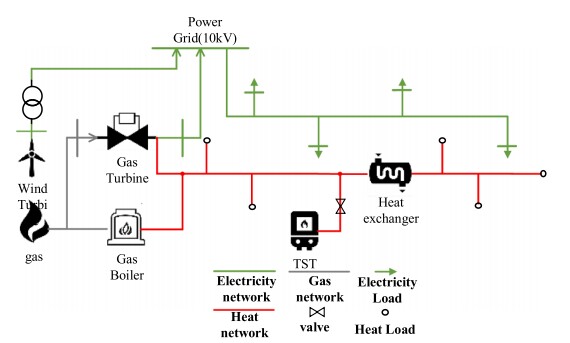
热电联产系统智能经济调度:一种深度强化学习方法 关键词:热电联产,经济调度,深度强化学习,近端优化 一种热电组合(CHP)系统经济调度的深度强化学习(DRL)方法,该方法具有对不同操作场景的适应性,显著地在不影响精度的情况下降低了计算复杂度。 在问题描述方面,大量的热与功率组合(CHP)经济调度问题被建模为一个高维和非光滑的目标函数,具有大量的非线性约束,需要强大的优化算法和相当长的时间来解决它。 为了减少解决方案的时间,大多数工程应用程序选择线性化优化目标和设备模型。 为了避免复杂的线性化过程,本文将CHP经济调度问题建模为马尔可夫决策过程(MDP),使模型被高度封装,以保存各种设备的输入和输出特性。 此外改进了一种先进的深度强化学习算法:分布式近端策略优化(DPPO),使其适用于CHP经济调度问题。 此外,我们还改进了一种先进的深度强化学习算法:分布式近端策略优化(DPPO),使其适用于CHP经济调度问题。 在此算法的基础上,将对代理进行训练,以探索不同操作场景的最优调度策略,并有效地响应系统紧急情况。 在实用阶段,经过训练的代理将根据当前系统状态实时生成最优控制策略。
嘿,各位技术爱好者们!今天咱来聊聊热电联产系统智能经济调度里深度强化学习这一超酷的玩法。
热电联产,也就是 CHP,这系统的经济调度一直是个有趣又复杂的问题。大量的 CHP 经济调度问题就像一个个难啃的硬骨头,被建模成高维和非光滑的目标函数,周围还环绕着一堆非线性约束。想象一下,要解决它,就像在错综复杂的迷宫里找出口,得依靠强大的优化算法,还得花上老长的时间。
不少工程应用为了减少解决问题的时间,选择把优化目标和设备模型进行线性化处理。但这就好比为了走捷径而绕开了美丽的风景,线性化过程其实挺复杂的。而今天要讲的方法就厉害了,它把 CHP 经济调度问题建模成马尔可夫决策过程(MDP),就像是给各种设备的输入输出特性搭建了一个高度封装的小房子,模型变得简洁又高效。
改进算法:分布式近端策略优化(DPPO)
这里不得不提咱们改进的分布式近端策略优化(DPPO)算法,它原本就很先进,经过咱们改造,就像给赛车换上了更强劲的引擎,完美适配 CHP 经济调度问题。
咱来看段简单的伪代码,感受下 DPPO 的大致思路(这里只是示意,实际应用会复杂得多):
python
# 初始化策略网络和价值网络
policy_network = PolicyNetwork()
value_network = ValueNetwork()
# 初始化优化器
policy_optimizer = Optimizer(policy_network.parameters())
value_optimizer = Optimizer(value_network.parameters())
# 训练循环
for episode in range(num_episodes):
state = get_initial_state()
done = False
while not done:
# 根据策略网络选择动作
action = policy_network(state)
# 执行动作,获取下一个状态、奖励和是否结束的信息
next_state, reward, done = take_action(action)
# 计算优势估计
advantage = calculate_advantage(value_network, state, reward, next_state, done)
# 更新策略网络
policy_loss = calculate_policy_loss(policy_network, state, action, advantage)
policy_optimizer.zero_grad()
policy_loss.backward()
policy_optimizer.step()
# 更新价值网络
value_loss = calculate_value_loss(value_network, state, reward, next_state, done)
value_optimizer.zero_grad()
value_loss.backward()
value_optimizer.step()
state = next_state在这段代码里,一开始初始化了策略网络和价值网络,这俩网络就像是两个聪明的小助手,策略网络负责决定采取什么行动,价值网络评估当前状态的好坏。然后进入训练循环,每次循环都根据当前状态通过策略网络选择一个动作,接着执行这个动作,看看得到什么新状态、奖励,以及是否结束了这一轮。之后计算优势估计,这一步就像是给策略网络的决策打分,看看这个决策到底好不好。根据这个打分来更新策略网络和价值网络,让它们变得越来越聪明。
代理训练与策略生成
基于这个改进的 DPPO 算法,我们就要训练代理啦。这个代理就像一个聪明的小管家,它会在不同的操作场景里探索,找到最优的调度策略,而且面对系统紧急情况也能有效响应。
等训练完成,这个"小管家"就可以上岗啦!在实际应用阶段,经过训练的代理会根据当前系统的实时状态,迅速生成最优控制策略,让热电联产系统能够经济又高效地运行。
深度强化学习在热电联产系统经济调度里的应用,不仅展现了技术的创新,更有可能为能源领域带来新的变革。说不定以后我们的能源利用会因为这些技术变得更加智能、环保又高效呢!
今天就跟大家分享到这儿,欢迎一起探讨这个有趣的话题呀!
