web自动化
1.有没有做过Web UI自动化,你们web自动化是怎么做的?
【技术选型 + 架构设计 + 分层思想】
前一个项目是有参与过web自动化测试工作的,
框架:Pytest + selenium
UI 自动化:基于POM模型搭建的,分为3层,base表现层、page页面操作层以及testcase测试用例层,
2.自动化测试流程是什么,举个例子
先根据自己
先挑选测试用例
根据自动化测试用例编写脚本
创建export出库订单:
login -> 检查UI的数据和excel里面的数据是否一致
3.你们自动化覆盖率是多少,怎么统计自动化覆盖率
根据目前的模块覆盖率来算的话,
按照已经实现的占总自动化用例来说,百分之50的样子
4.元素定位的方式有哪些,你常用的元素定位方式有哪些?
id
name
classname
tag
Link_text
partial_link_text
xpath
css_selector
常用的主要是:xpath
//input@id='kw'/parent::span
//input@id='kw'/following-sibling::i2
//spantext()='换一换'
//buttonstarts-with(text(), 'Buy s')
//*@name='wd'
5.定位不到元素,你碰到过哪些,怎么解决
1.去重现这个操作,看是否能正常找到这个元素(一定要完全重复操作)
2.如果可以找到的话,看一下这个元素是否可见(is_disabled)
3.如果可见的话,去看一下这个元素是否有什么特殊的,比如说在另外一个内嵌网页里面
4.如果不在的话
send_keys()的时候报错不可交互:
1.先看这个元素是不是可输入类的元素,input, textarea这种
2.不是的话就尽量定位到input这种元素上
3.如果是的话,就看一下这个元素的属性是不是可交互,js 获取到这个元素然后is_enabled()
6.xpath定位的方法?xpath怎么写
//div@name = '123'/parent::span
7.如何去定位内嵌页面
driver.switch_to.frame(名字)
8.如何在不同的网页之间切换,如何处理定位问题
switch_to.window(名字)
9.如何去定位滚动条,滚动条怎么处理
9.1 定位日期控件以及js调试方法
9.2 页面弹出框的处理
2.浏览器自带弹出框

10.如何去模拟键盘和鼠标的操作
键盘的话:
from selenium.webdriver.common.keys import Keys
send_keys(Keys.BACKSPACE)
鼠标的话
from selenium.webdriver.common.action_chains import ActionChains
actions = ActionChains(driver)
actions.move_to_element(driver.find_element(By.CSS_SELECTOR, "span#s-usersetting-top"))
actions.perform()
11.元素定位,有时候定位的到,有时候定位不到,可能是什么原因,怎么解决
经常会出现这个问题
1.大部分有可能是这个网络比较慢,导致这个元素加载延迟,可以用显示等待
2.动态id
12.对于不可见的元素,你如何定位,如何处理
可以用js的方法,将这个元素的属性设置为可见
13.你们自动化用例是怎么管理的
test_case包下面,一个模块一个py文件
14.自动化测试用例如何设计
一定是要可复用的,不能说这次执行了下次执行就会失败
覆盖模块的主功能点
export
15.自动化用例在什么环境下运行,如何批量运行
pytest 参数可以指定运行
pycharm一个一个运行
16.有没有独立的搭建过自动化测试框架
有自己尝试过,基于POM的设计模式
pom
UI自动化测试中的设计思想
Page Object Model: 页面对象模型
将页面元素的定位和测试用例代码进行分离
为什么要使用POM
页面元素对于测试用例来说,很多都是公用的
将页面元素的定位写在测试用例当中,会导致测试用例难以维护
POM 模式的封装思路
POM将页面划分三层
表现层: 页面中可见的元素,都属于表现层。(元素定位器的编写)
操作层: 对页面可见元素的操作,比如:输入文本内容,点击,拖拽......
业务层: 对页面当中若干元素操作后所实现的功能
POM的核心要素
在POM模式当中,将一些公共的方法封装到一个BasePage类中,该类是对Selenium的常用操作的二次封装
每个页面对应一个page类,page类需要继承自BasePage
测试用例基于page对象的方法
17.数据驱动怎么做的
没有数据驱动,接口自动化有
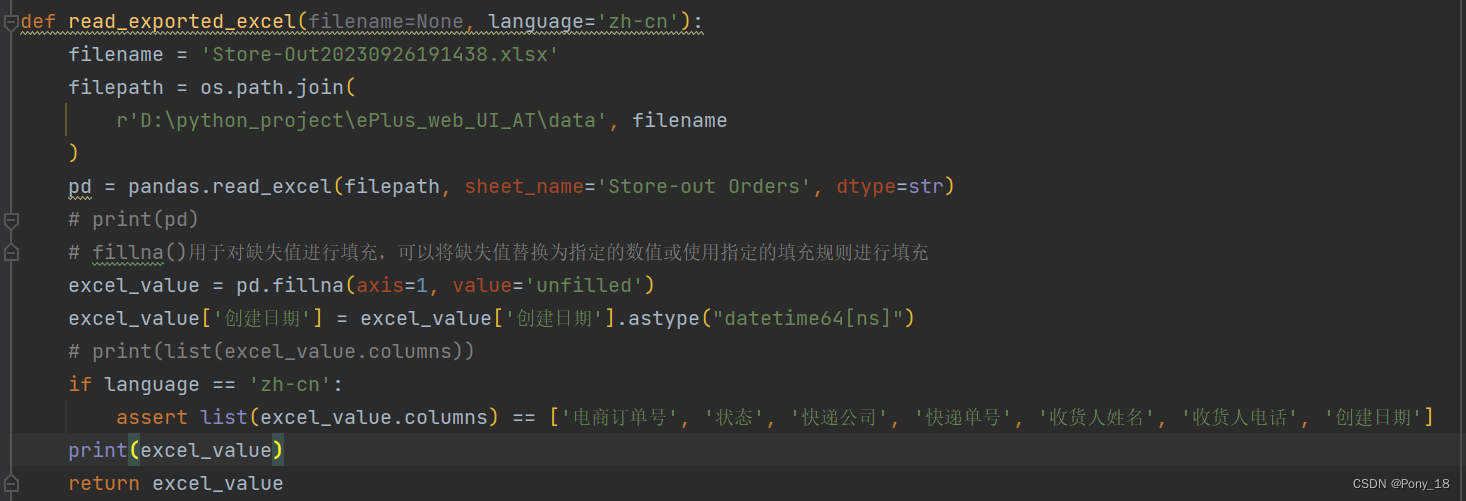
18.自动化中如何去操作excel表格
pandas读取excel
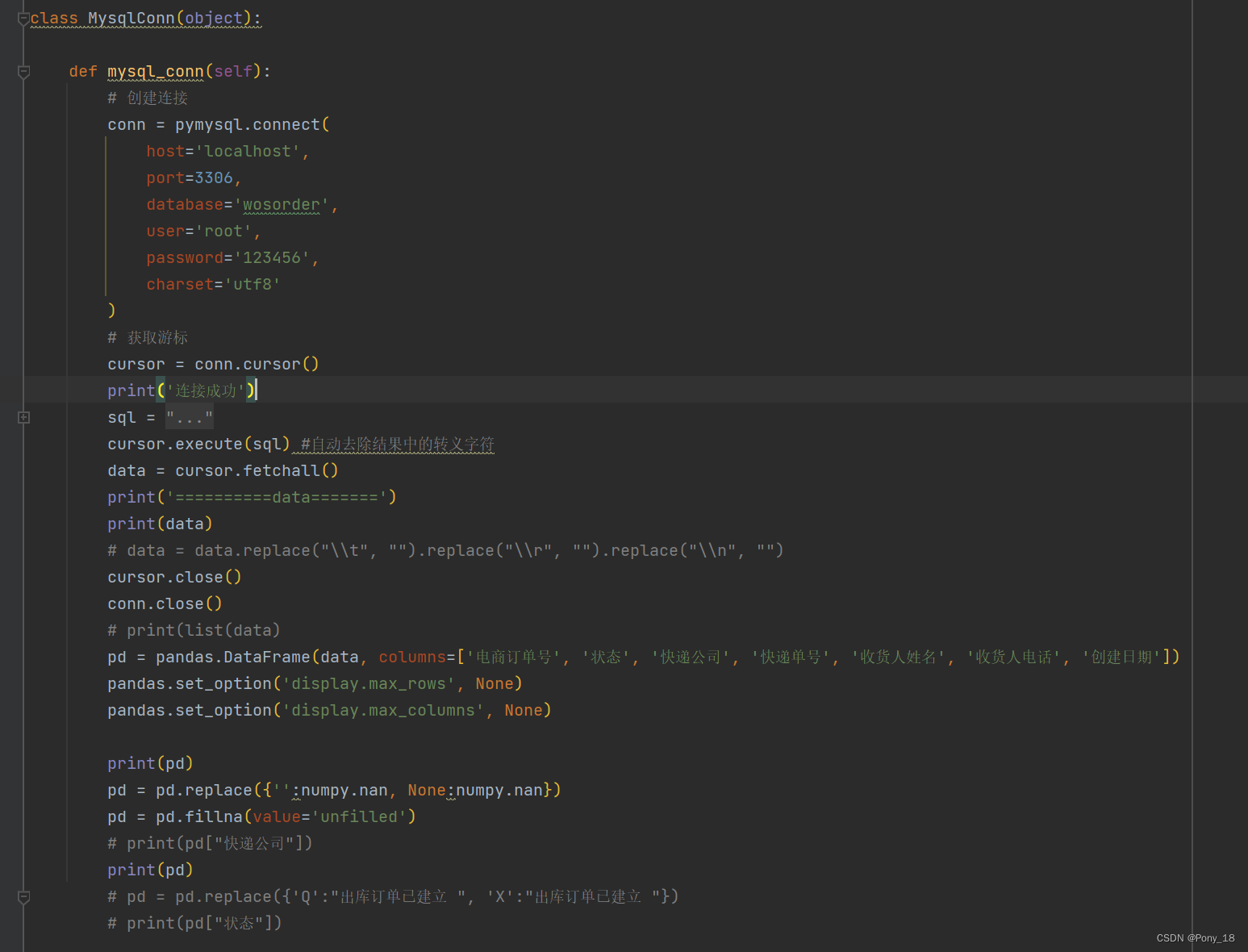
19.自动化中如何去操作数据库
pymysql
20.有没有自己封装过一些函数,封装过哪些函数
pymysql函数
log函数
config函数
21. web UI 自动化你怎么做断言
1.断言UI 上显示是否有该提示
2.断言UI显示的数据是否和db显示的一致
21.如何生成自动化测试报告
allure
- allure : 解压,将bin目录加入环境变量的path当中
- allure-pytest : pip install allure-pytest
22.对于生成的自动化测试报告如何分析
23.selenium库中用过哪些函数
driver.get()
driver.clear()
driver.find_elemant_by
24.se原理、playwright原理,两者区别,
请具体说一下,在你的实际体验中,Playwright 相比 Selenium 最大的优势是什么?或者是:你在使用 Selenium 时遇到过什么无法解决的痛点,是 Playwright 能轻松搞定的?
25.3种等待的区别和场景应用
显式等待:轮询

隐式等待:

强制等待:time.sleep() #用于调试
26.遇到过哪些难定位的元素,你是如何定位的
27.你的自动化框架是如何设计的
28. web自动化落地过程以及难点剖析

29.如何保证元素定位的成功率
====== 封装 - 考察代码能力 =====
关于 Base 层的封装(考察代码能力) 请问你的 BasePage 类中,除了简单的"查找元素"和"点击"之外,还封装了哪些通用的核心逻辑?
你提到了 Base 层。很多初级测试只是在 Base 层里写个 driver.find_element 就完了。
(提示:比如显式等待怎么处理?异常捕获怎么做?失败截图怎么实现?日志怎么打?)
关于稳定性(Web UI 的核心痛点)除了加 time.sleep(强制等待)这种不推荐的方式外,你在框架层面是如何设计"等待机制"来保证脚本稳定性的?
UI 自动化最怕的就是"不稳",比如元素偶尔加载慢了、页面有动态弹窗干扰等。
====== 业务结合能力 =====
在你的过往项目中,有没有遇到过很难定位的元素 ,或者是非标准的控件(比如滑动验证码、时间选择器、复杂的树状菜单)? 你是怎么解决的?(如果没遇到过,就说一个你觉得最复杂的场景)
===== 用例设计能力 =====
"假设现在的 Web 页面上有一个文件上传的功能。
-
如果那个上传按钮是
<input type='file'>标签,你会怎么做自动化? -
如果那个按钮不是 input 标签(是非标准的上传组件,点开会弹出一个 Windows 的文件选择框),这时候 Selenium/Playwright 控制不了操作系统弹窗,你会怎么处理?"
1.如果type是file的话,
eplus 有文件上传的功能
==== 持续集成 ====
框架的持续集成怎么实现
这个问题问得很好,考察的是你自动化测试落地 的能力,以及你对DevOps流程的理解。
结合你之前的**"AI模型压缩"**模块,回答的核心逻辑应该是:
"工具链 + 流程控制 + 策略分层"。
因为模型压缩涉及大量运算,跑一次很慢,所以不能傻傻地每次代码提交都跑全量测试,这里要体现出策略。
以下是满分回答模板:
🎙️ 面试回答话术
"我们框架的持续集成(CI)主要是基于 Jenkins + GitLab + Docker 来实现的。
主要是为了解决**'代码提交后的快速回归'和'夜间全量监控'**。
具体流程我分为 4 个阶段 来讲:"
1. 触发机制(什么时候跑?)
"我们配置了两种触发方式:
- 代码提交触发(Webhook): 当开发提交代码(Push)或者发起合并请求(MR)时,自动触发 Jenkins 构建。
- 定时触发(Nightly Build): 每天凌晨 2 点,系统空闲时,自动跑全量回归测试。"
2. 环境构建(在哪里跑?)
"因为模型压缩对环境依赖很重(Python版本、TensorFlow/PyTorch版本),为了避免环境污染,我们使用 Docker 容器化执行。
- Jenkins 收到任务后,会拉取最新的测试代码。
- 启动一个干净的 Docker 容器(里面预装好了测试框架依赖)。
- 在容器内执行测试脚本,保证每次测试环境都是一致的。"
3. 执行策略(跑什么?------这里是亮点)
"针对模型压缩比较耗时的特点,我们做了分层测试策略:
- 提交阶段(Smoke Test): 只跑冒烟测试。选几个典型的、体积小的模型(比如 <10MB 的 Demo 模型)跑通压缩流程,确保核心功能没挂,耗时控制在 5-10 分钟内。
- 夜间阶段(Regression Test): 跑全量回归。覆盖各种框架、各种参数组合、大体积模型。这部分比较慢,放在晚上跑。"
4. 报告与通知(结果给谁看?)
"测试执行完后,会利用 Allure 生成可视化的 HTML 报告,包含成功率、耗时趋势、失败截图等。
- 通知机制: 我们打通了钉钉/企业微信机器人 。
- 如果测试通过,仅在群里发一条简报。
- 如果测试失败,会直接 @对应的开发人员,并附上 Jenkins 的日志链接,要求尽快修复。"
💡 追问准备(技术细节)
面试官可能会问:"如果CI报错了,怎么排查是环境问题还是代码问题?"
你的回答:
"这正是我们用 Docker 的原因。
如果本地跑得通,CI 跑不通,通常是环境差异。但因为我们 CI 是在 Docker 里跑的,我可以在本地拉取同一个 Docker 镜像 来复现问题。
另外,我会去查看 Jenkins 的 Console Output(控制台日志),看是报错在环境安装阶段,还是测试断言阶段。"
📝 简单总结(记不住就背这个短版)
"我们的 CI 是用 Jenkins 搭建的。
流程是:代码提交到 GitLab 后,自动触发 Jenkins 任务。
任务会在 Docker 容器里运行 Pytest 自动化脚本。
为了效率,白天提交代码只跑冒烟测试 (快速验证),晚上跑全量回归 。
最后生成 Allure 报告,并通过钉钉群通知大家测试结果。"
框架的数据是怎么分层的