在物联网 / 工控场景的主流设计中,一个设备(比如一台诱导屏、一个车位锁)的所有命令、心跳、ACK 确实共用同一个 TCP 长连接,这个连接默认会一直保持(长连接),直到设备主动关闭、网络中断,或服务端主动断开为止。
一、核心结论:设备级单长连接是主流设计
对单个设备而言,"所有命令 / ACK 共用一个 TCP 长连接" 是物联网场景的标准最优实践,而非 Netty 强制要求,但几乎所有工业级设备(诱导屏、车位锁、充电桩等)都会这么设计,原因很简单:
| 设计方案 | 优点 | 缺点 |
|---|---|---|
| 单设备单长连接(主流) | 1. 服务端 / 设备端资源消耗极低(少连接)2. 通信延迟低(无需重复建连)3. 易于绑定设备身份(连接 = 设备) | 需处理连接保活、重连逻辑 |
| 单设备多连接(极少用) | 业务隔离性稍好 | 1. 服务端端口 / 内存资源耗尽(设备量大会崩)2. 设备侧功耗 / 资源消耗高3. 难以追踪设备状态 |
| 单设备短连接(几乎不用) | 无需维护连接 | 1. 每次发命令都要建连(3 次握手),延迟高2. 服务端无法主动下发命令3. ACK 难以匹配请求 |
二、"长连接" 的实际落地:不是绝对 "永不中断",但逻辑上 "直到设备关闭"
你问的 "直到设备关闭为止" 是逻辑层面的设计目标,实际落地中这个长连接会有这些特性:
-
默认保持连接:设备上电后主动和服务端建立 TCP 连接,建立后不会主动断开,除非:
- 设备断电 / 关机(物理关闭);
- 网络中断(比如设备移动物联网卡信号丢失);
- 服务端检测到设备异常(比如长时间无心跳)主动断开;
- 设备主动发起断开(比如固件升级重启)。
-
心跳保活 :为了让连接 "活" 着,设备会定期(比如 10 秒 / 30 秒)通过这个连接发送心跳包(就是你提到的 "车位锁心跳上报"),服务端回复 ACK------ 这个心跳的核心作用不是 "业务数据",而是检测连接是否可用,如果服务端长时间收不到心跳,就判定连接失效,会断开连接;设备如果发心跳没收到 ACK,也会主动重连。
-
重连机制:连接意外断开后,设备会自动重试建立连接(比如每隔 5 秒试一次),直到重新连上服务端,恢复单长连接的状态。
Crystal
graph LR
A[车位锁设备] -->|上电建连| B[Netty服务端]
B -->|创建专属Channel| C[Channel-车位锁001]
C -->|绑定Pipeline| D[通用编解码器]
D -->|处理所有业务| E[心跳上报+ACK]
D -->|处理所有业务| F[开锁命令+ACK]
D -->|处理所有业务| G[状态查询+ACK]
C -->|连接保持| H[直到设备断电/网络断]
H -->|设备重连| B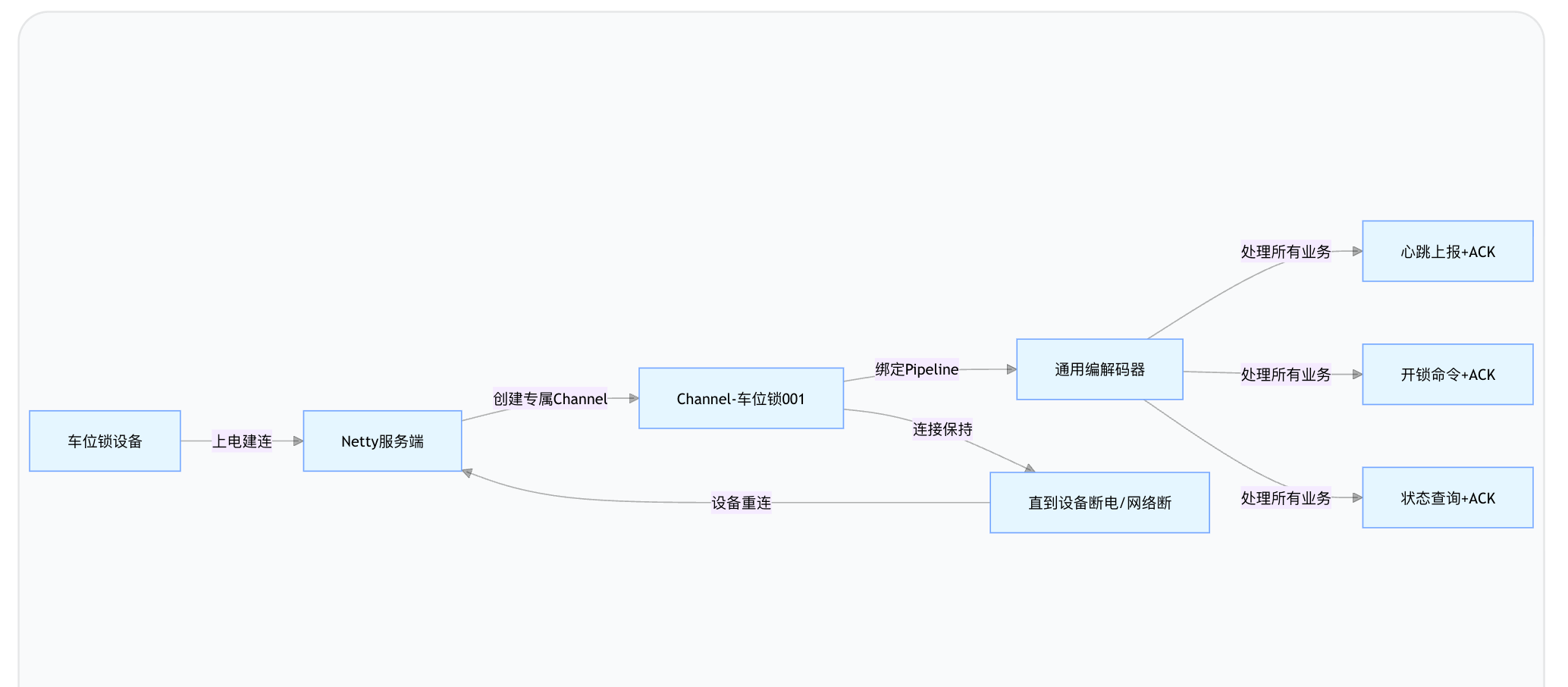
一个设备只有一个 DeviceClient 实例,对应一个 Channel(一个 TCP 长连接)
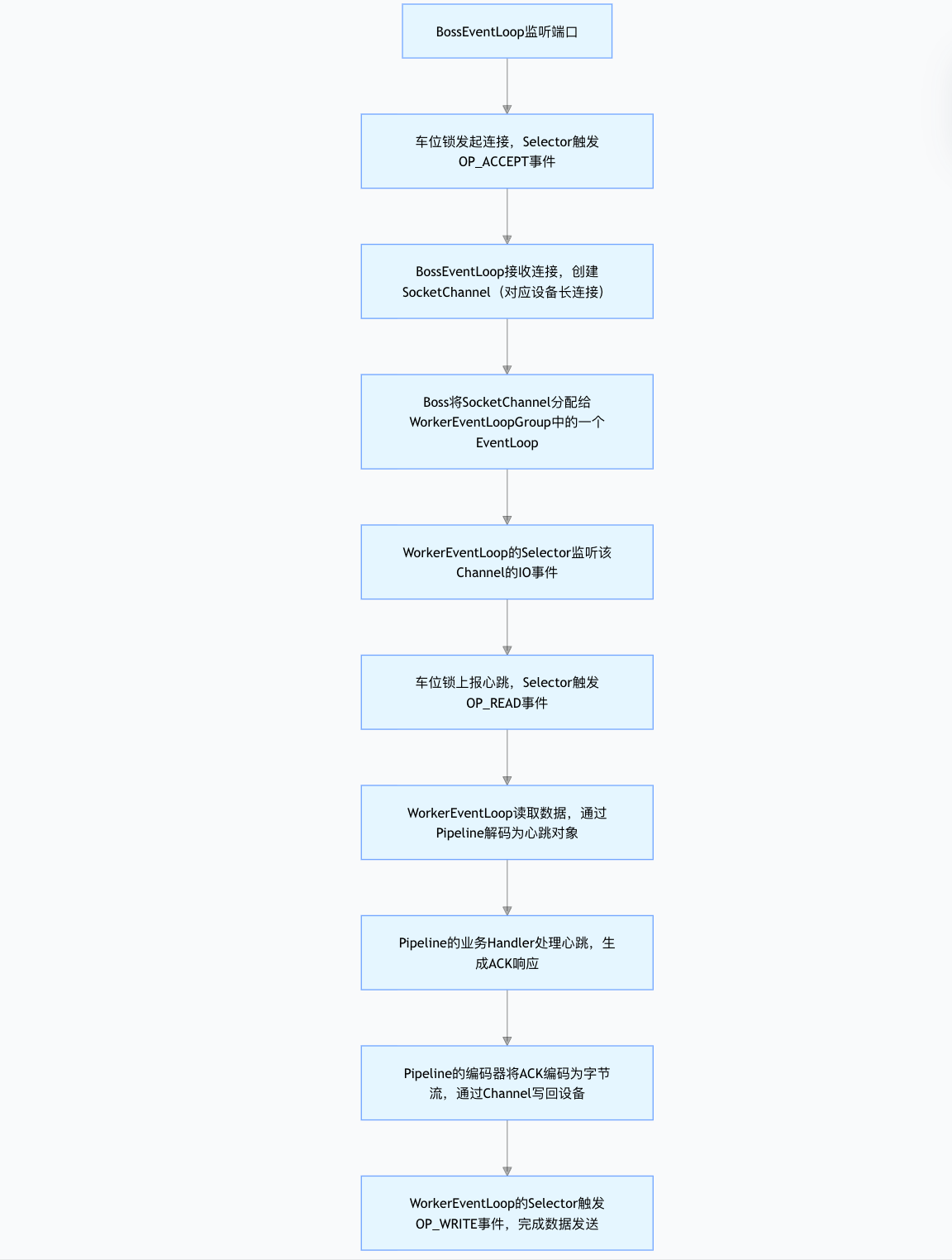
Netty的架构模型