写在前面
最近 AI Coding 实在太火了,Cursor、Claude Code 这些工具让写代码变得越来越轻松。你可能也注意到了,这些工具都有一个共同点:在你写代码的时候,它们会实时给你补全建议,按 Tab 就能接受。这种体验太爽了,以至于我想在自己的博客编辑器里也搞一个类似的功能。
与此同时,「全栈开发」和「大模型应用开发」也成了很多人想要学习的方向。
我自己折腾了一个 Next.js 全栈 AI 博客项目,把 Prompt 工程、RAG 知识库、流式输出、AI Copilot 这些东西都实践了一遍。今天想通过这篇文章,把我在这个项目里学到的东西分享出来,希望能帮到想入门这个领域的朋友。
GitHub 地址 :github.com/flawlessv/S...
🔗 线上地址 :powder.icu/
本文主要讲述如何实现博客的AI相关功能,想了解基础功能如何实现的同学可以看下Next.js全栈开发从入门到部署实战
先看看这个博客长什么样:
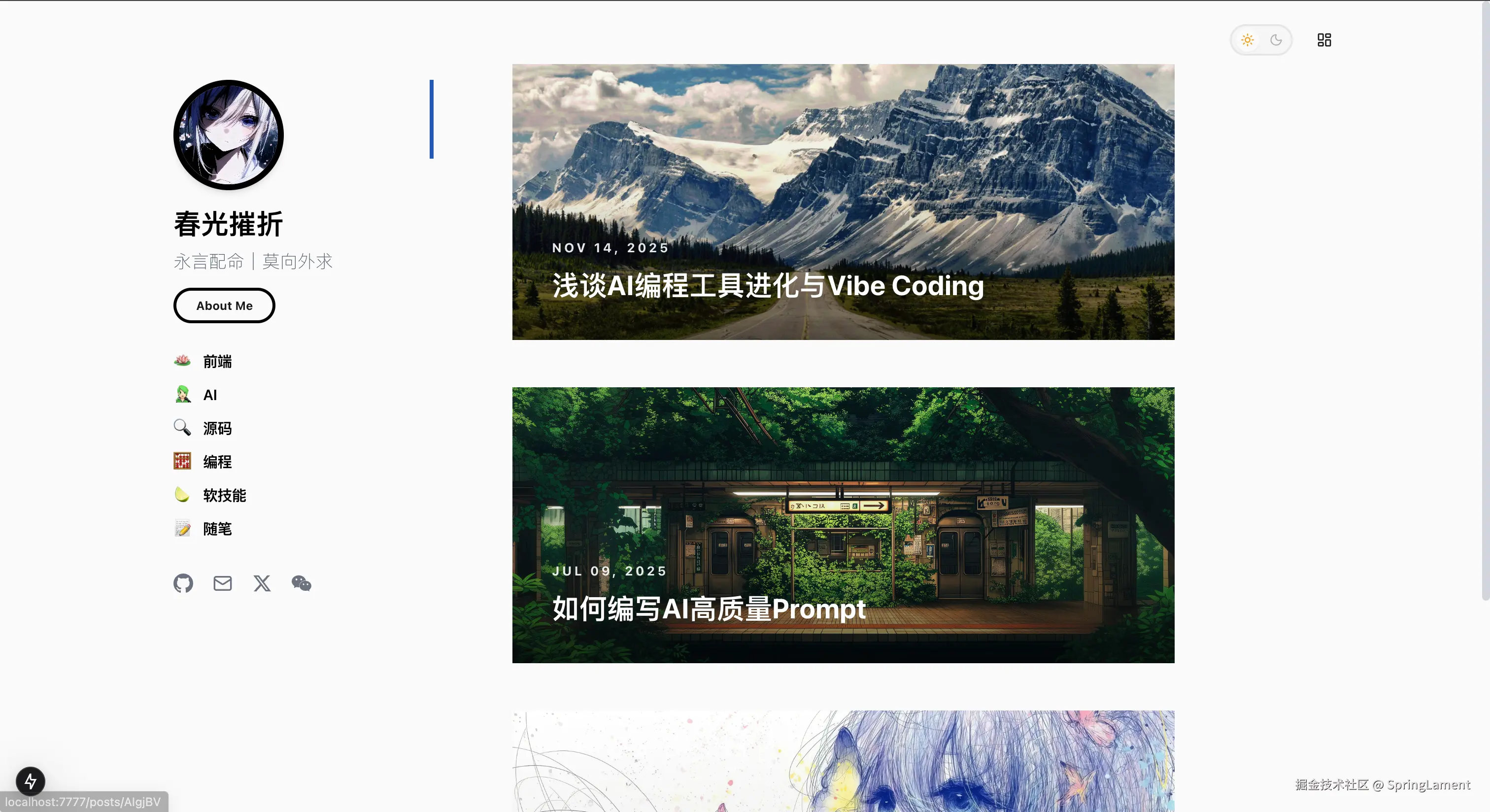
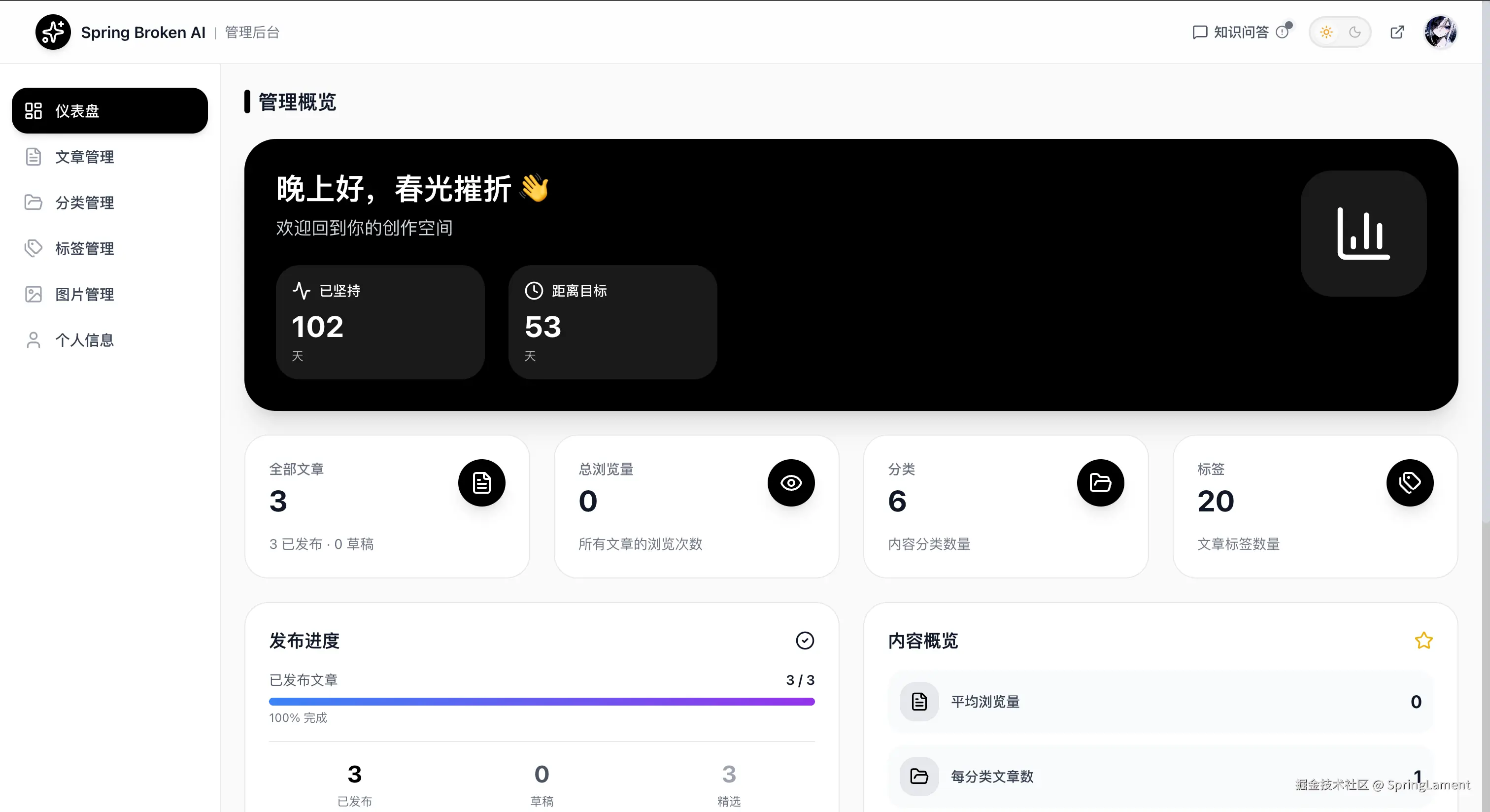 项目用的技术栈:
项目用的技术栈:
- 前端:Next.js 15 + TypeScript + shadcn/ui + Tailwind CSS
- 后端:Next.js API Routes + Prisma ORM
- AI:Kimi API + Ollama + ChromaDB
接下来我会从 Prompt 讲起,然后聊聊 AI Copilot、RAG、流式输出这些功能是怎么实现的。
一切的起点:Prompt
说到大模型应用开发,绑不开的就是 Prompt。
Prompt 是什么? 说白了就是你跟大模型说的话。你怎么问,它就怎么答。问得好,答案就靠谱;问得烂,答案就离谱。
我在做这个项目的时候发现,很多 AI 功能的本质都是一样的:构造一个 Prompt,然后调 LLM API。
比如:
- AI 生成文章标题?Prompt + LLM
- AI 生成摘要?Prompt + LLM
- AI 推荐标签?还是 Prompt + LLM
所以想玩好大模型应用,Prompt 工程是必须要会的。
结构化 Prompt
写 Prompt 其实跟写文章差不多,有结构会比乱写好很多。我在项目里用的是一种叫「结构化 Prompt」的写法,大概长这样:
markdown
# Role: 你的角色
## Profile
- Author: xxx
- Version: 1.0
- Language: 中文
- Description: 角色描述
## Skills
- 技能1
- 技能2
## Rules
1. 规则1
2. 规则2
## Workflow
1. 第一步做什么
2. 第二步做什么
## OutputFormat
- 输出格式要求
## Initialization
作为 <Role>,严格遵守 <Rules>,按照 <Workflow> 执行任务。这种写法的好处是逻辑清晰,大模型更容易理解你想要什么。
举个实际的例子,这是我项目里用来生成文章摘要的 Prompt:
typescript
export function buildExcerptPrompt(content: string): string {
return `# Role: 内容摘要撰写专家
## Profile
- Author: Spring Broken AI Blog
- Version: 2.0
- Language: 中文
- Description: 你是一位专业的内容编辑,擅长从长文中提取核心信息,撰写简洁有力的摘要。
## Rules
1. 摘要长度必须严格控制在 100-200 个汉字之间
2. 必须包含文章的核心观点和主要结论
3. 使用简洁、专业的语言,避免冗余表达
4. 只返回摘要文本,不要包含任何其他内容
## Workflow
1. 仔细阅读并理解完整的文章内容
2. 识别文章的核心主题和主要论点
3. 用简洁的语言组织摘要
4. 输出纯文本摘要
## Input
文章内容:
${content.slice(0, 3000)}
## Initialization
作为 <Role>,严格遵守 <Rules>,按照 <Workflow> 撰写摘要。`;
}你看,其实就是告诉大模型:你是谁、要遵守什么规则、按什么流程做事、输出什么格式。把这些说清楚了,大模型的输出质量会好很多。
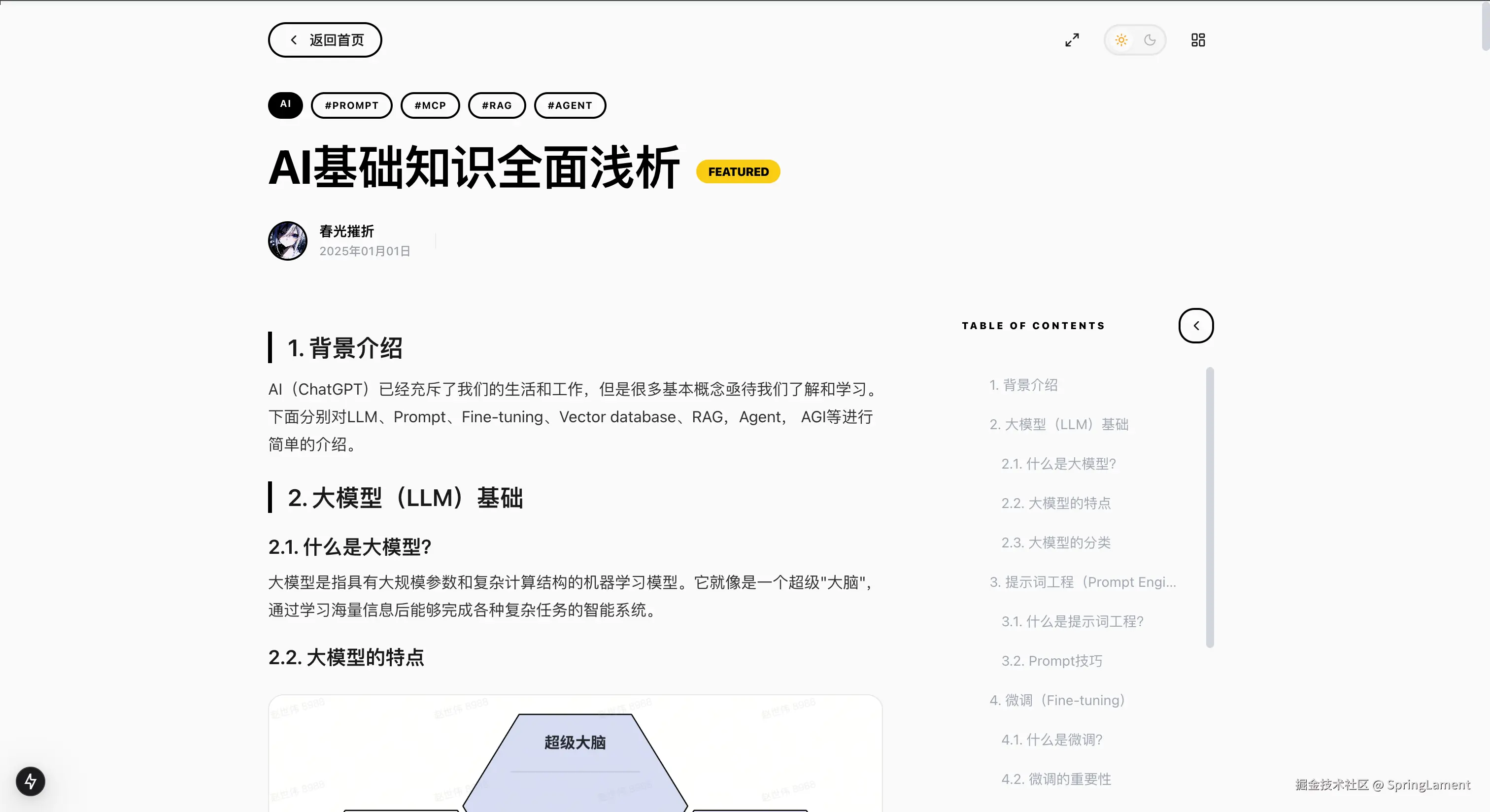
AI Copilot:编辑器里的智能补全
这个功能是我觉得最有意思的一个,效果类似 GitHub Copilot 或者 Cursor,在你写文章的时候实时给你补全建议。

实现思路
说穿了也不复杂:把文章上下文 + Prompt 丢给 LLM,让它帮你续写。
具体流程是这样的:
- 用户在编辑器里打字
- 我提取光标前 500 个字符作为上下文
- 构造一个 Prompt,大意是「根据上下文,续写 5-30 个字」
- 调 Kimi API 拿到补全建议
- 把建议以灰色斜体显示在光标后面
- 用户按 Tab 接受,按 Esc 取消
技术难点
这个功能看起来简单,但实际做起来有几个坑:
1. 非侵入式显示
补全建议不能直接写入文档,只能在视图层显示。
我一开始想的就是用样式来实现------在光标位置叠加一个灰色斜体的文本,看起来像是补全建议,但实际上不是文档的一部分。这个思路是对的,关键是怎么实现。
参考了 VSCode 的做法。VSCode 的 AI 补全(GitHub Copilot)用的是「虚拟文本」机制:补全建议只在视图层显示,不写入文档模型。只有用户按 Tab 确认后,才真正写入。
我用的编辑器是 Tiptap(基于 ProseMirror),刚好有类似的机制叫 Decoration。它可以在视图层叠加显示内容,不影响文档结构,正好符合我的需求。
2. 防抖
用户打字很快的时候,不能每敲一个字就调一次 API,那样太浪费了。我设了 500ms 的防抖,用户停下来半秒钟才触发补全请求。
3. 异步竞态
用户可能在 API 返回之前又继续打字了,这时候光标位置已经变了。如果直接把补全建议显示出来,位置就对不上了。
我的做法是双重位置校验:发请求前记录光标位置,API 返回后再校验一次,位置变了就不显示。
typescript
// 第一次校验:防抖回调执行时
const currentState = extension.editor.state;
if (currentSelection.from !== currentFrom) {
return; // 位置已改变,丢弃请求
}
// 调用 AI API...
// 第二次校验:API 返回后
const latestState = extension.editor.state;
if (latestState.selection.from === currentFrom) {
// 位置仍然一致,才更新状态
}4. ProseMirror 插件
编辑器用的是 Tiptap(基于 ProseMirror),补全建议的显示用的是 Decoration,不会影响文档结构,只是视觉上的装饰。
核心代码大概长这样:
typescript
// 创建补全建议的视觉装饰
const widget = document.createElement("span");
widget.className = "ai-completion-suggestion";
widget.style.cssText =
"color: #9ca3af; " + // 灰色
"font-style: italic; " + // 斜体
"pointer-events: none; " + // 不拦截鼠标
"user-select: none;"; // 不可选中
widget.textContent = suggestion;
// 在光标位置显示
const decoration = Decoration.widget(position, widget, {
side: 1, // 光标后
ignoreSelection: true,
});RAG:让 AI 基于你的内容回答问题
RAG 是这个项目里我花时间最多的功能。
先聊聊向量数据库
在讲 RAG 之前,得先说说向量数据库是什么。
我们平时用的数据库,比如 MySQL、MongoDB,存的都是结构化数据或文档。查询的时候用的是精确匹配或者关键词搜索。
但 AI 领域有个问题:怎么找到「语义相似」的内容?比如「如何写好 Prompt」和「Prompt 工程技巧」,这两句话关键词不一样,但意思很接近。传统数据库搞不定这个。
向量数据库就是为了解决这个问题。它的思路是:
- 把文本转成一串数字(向量),这个过程叫 Embedding
- 语义相似的文本,转出来的向量也相似
- 查询的时候,把问题也转成向量,然后找最相似的几个
常见的向量数据库有 Pinecone、Milvus、Chroma 等。我用的是 Chroma,开源免费,轻量好用。
为什么需要 RAG?
大模型虽然很聪明,但它不知道你博客里写了什么。你问它「我之前写的那篇关于 Prompt 的文章讲了什么」,它只能瞎猜。
这是因为大模型的知识有两个问题:
- 知识不新:训练数据有截止日期,不知道最新的事
- 知识不全:不知道你的私有内容
RAG(Retrieval-Augmented Generation,检索增强生成)就是为了解决这个问题。简单说就是给大模型「开卷考试」:先从你的内容里检索相关信息,再让大模型基于这些信息回答。

我的实现思路
整个流程分两部分:
离线索引(把文章存起来)
- 把文章切成小块(语义分块)
- 用 Ollama 把每个块转成向量(Embedding)
- 把向量存到 ChromaDB
在线检索(用户提问时)
- 把用户的问题也转成向量
- 在 ChromaDB 里找最相似的几个块
- 把这些块作为上下文,构造 Prompt
- 调 Kimi API 生成回答
分块的坑
分块这一步踩了不少坑。
一开始我想简单点,按固定字符数切,比如每 500 字一块。结果发现很多问题:句子被截断、段落被分割、检索时匹配到不完整的片段。
后来改成了语义分块,按优先级:
- 先按段落分(
\n\n) - 段落太长就按句子分(
。!?) - 实在不行才硬切
还有一个坑是 Ollama 的 nomic-embed-text 模型有 800 字符的限制。超过这个长度就报错。
我的处理方式是:如果一个块超过 800 字符,就把它切成多个子块,每个子块单独生成向量,单独存储。这样虽然麻烦点,但不会丢信息。
typescript
// 语义分块的核心逻辑
export function chunkPost(content: string, options = {}) {
const maxChars = options.maxChars || 800; // Ollama 硬限制
const chunks = [];
// 按段落分割
const paragraphs = content.split(/\n\n+/).filter((p) => p.trim());
for (const para of paragraphs) {
if (para.length > maxChars) {
// 段落太长,按句子分割
splitBySentence(para, chunks);
} else {
chunks.push(para);
}
}
return chunks;
}流式输出:打字机效果
如果你用过 ChatGPT,应该对那个打字机效果有印象。AI 的回答不是一下子全出来,而是一个字一个字蹦出来的。
这个效果不只是好看,更重要的是用户体验。如果等 AI 生成完再返回,用户可能要干等好几秒,体验很差。流式输出让用户立刻看到反馈,感觉响应更快。
实现思路
流式输出的核心是 SSE(Server-Sent Events)。
传统的 HTTP 请求是:发请求 → 等待 → 收到完整响应。
SSE 是:发请求 → 保持连接 → 服务器持续推送数据 → 最后关闭连接。
一个请求,多次推送。
后端代码大概是这样:
typescript
// 创建 SSE 流
const stream = new ReadableStream({
async start(controller) {
const sendEvent = (type, data) => {
const message = `event: ${type}\ndata: ${JSON.stringify(data)}\n\n`;
controller.enqueue(encoder.encode(message));
};
// 调用 Kimi API,流式返回
await aiClient.chatStream(messages, {}, (chunk) => {
// 每收到一个文本块,就推送给前端
sendEvent("chunk", { chunk });
});
// 完成后关闭连接
sendEvent("complete", { done: true });
controller.close();
},
});
return new Response(stream, {
headers: {
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache",
Connection: "keep-alive",
},
});前端用 fetch + ReadableStream 读取:
typescript
const response = await fetch("/api/ai/rag/stream", {
method: "POST",
body: JSON.stringify({ question }),
});
const reader = response.body.getReader();
const decoder = new TextDecoder();
while (true) {
const { done, value } = await reader.read();
if (done) break;
const text = decoder.decode(value);
// 解析 SSE 格式,更新 UI
parseSSE(text, (chunk) => {
setContent((prev) => prev + chunk); // 追加文本,实现打字机效果
});
}其他功能
除了上面说的 AI 功能,项目里还有一些基础功能:
AI 生成标题、摘要、标签
这些都是「Prompt + LLM」的套路。给大模型文章内容,让它生成标题/摘要/标签。
相关文章推荐
用当前文章的标题和摘要生成向量,在 ChromaDB 里找最相似的几篇文章。比传统的「按标签匹配」更智能。
降级机制
RAG 依赖 Ollama 和 ChromaDB,这两个服务挂了怎么办?
我做了降级处理:如果 RAG 不可用,就退化成纯 LLM 模式。虽然回答质量会差一些,但至少功能还能用。
如何获取 LLM API Key
这个项目用的是 Kimi(Moonshot AI)的 API,申请地址:
注册后会有免费额度,个人学习完全够用。
其他可选的 LLM 服务:
- DeepSeek :platform.deepseek.com/
- 通义千问 :dashscope.aliyun.com/
- 智谱 AI :open.bigmodel.cn/
快速上手
项目开源在 GitHub,感兴趣的话可以 clone 下来跑一跑:
GitHub 地址 :github.com/flawlessv/S...
如果觉得有帮助,欢迎给个 ⭐️ Star!
详细的安装步骤在 README 里都有,这里就不展开了。简单说就是:
- 安装 Node.js、Ollama、ChromaDB
- 配置 Kimi API Key
npm install+npm run dev
总结
做完这个项目,我最大的感受是:大模型应用开发没有想象中那么难。
很多功能的本质都是「Prompt + 调 API」,关键是把 Prompt 写好,把流程理清楚。
通过这个项目,你可以学到:
- Next.js 全栈开发(前端 + 后端 + 数据库)
- Prompt 工程(结构化 Prompt、角色设定、规则约束)
- RAG 实现(向量化、语义分块、相似度检索)
- 流式输出(SSE、ReadableStream)
如果想继续深入,可以看看这些方向:
- Agent:让 AI 自己规划任务、调用工具
- MCP:模型上下文协议,统一 AI 与外部系统的交互
- 微调:用自己的数据训练模型
希望这篇文章对你有帮助。有问题欢迎交流!
附录:参考资料
本项目在开发过程中参考了以下优秀内容:
- 样式生成 :如何用 Claude Code 生成顶级 UI - 通过 STYLE_GUIDE.md 减少样式信息丢失,让 AI 生成更精准的 UI
- Prompt 设计 :结构化 Prompt 设计指南 - 结构化 Prompt 的写法和最佳实践
- 博客样式 :Ursb's Blog - 博客整体风格参考