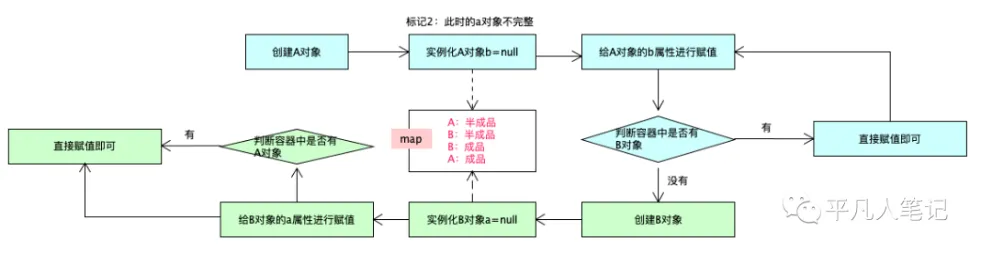
循环依赖
-
一级缓存(singletonObjects):存放完全初始化好的Bean,可直接使用。
-
二级缓存(earlySingletonObjects):存放提前暴露的Bean(已实例化但未完成属性填充和初始化)。
-
三级缓存(singletonFactories):存放Bean工厂对象(ObjectFactory),用于生成未完成初始化的Bean。
过程:
- 创建Bean A: 实例化A:调用构造函数创建A对象(此时属性未填充)。将A的ObjectFactory存入三级缓存。发现A依赖B:尝试从一级缓存获取B,若不存在则开始创建B。
- 创建Bean B: 调用构造函数创建B对象。将B的ObjectFactory存入三级缓存。发现B依赖A:尝试从一级缓存获取A,未找到。从三级缓存获取A的ObjectFactory并生成A的早期引用(未完成初始化的A对象,也就是二级缓存内的bean)。将A的早期引用注入B:B完成属性填充和初始化,并移入一级缓存。
- 完成Bean A的初始化,从一级缓存获取B,A完成属性填充和初始化,移入一级缓存。
注意事项:
- Spring 只能解决 单例模式(singleton scope)下的、通过 setter / 字段注入的循环依赖。
如果使用的是:
-
构造器注入(Constructor injection) → Spring 无法解决,抛出异常;
-
原型模式(prototype scope) → Spring 不做缓存,也无法处理循环依赖。
什么场景不支持循环依赖
https://blog.csdn.net/weixin_44772566/article/details/137157048
如果使用的是:
-
构造器注入(Constructor injection) → Spring 无法解决,抛出异常;这是因为在创建 Bean 的过程中,构造函数的调用是在对象实例化之前发生的,此时无法确定构造函数所需的依赖对象是否已经创建,从而导致循环依赖无法被解决。BeanA 的构造函数依赖于 BeanB,而 BeanB 的构造函数又依赖于 BeanA,构成了构造器循环依赖。
@Controller
public class StudentController {
//3.构造方法注入
private final StudentService studentService;
@Autowired
public StudentController(StudentService studentService) {
this.studentService = studentService;
}
}如果当前的类中只有一个构造方法,那么 @Autowired 也可以省略,所以以上代码还可以这样写:@Controller
public class StudentController { //3.构造方法注入
private final StudentService studentService;
public StudentController(StudentService studentService) {
this.studentService = studentService;
}
} -
原型模式(prototype scope) → Spring 不做缓存,也无法处理循环依赖。对于原型(prototype)作用域的 Bean,Spring 容器在创建时不会缓存对象实例 ,而是在每次请求时都会创建一个新的实例。因此,如果原型 Bean A 的某个属性依赖于原型 Bean B,而 Bean B 的某个属性又依赖于 Bean A,这种循环依赖无法通过 Spring 的循环依赖处理机制解决。这是因为 Spring 容器无法在创建原型 Bean 时提前暴露半初始化的对象,也无法缓存原型 Bean 的实例。PrototypeBeanA 的属性 beanB 依赖于 PrototypeBeanB,而 PrototypeBeanB 的属性 beanA 又依赖于 PrototypeBeanA,构成了原型 Bean 属性注入循环依赖。
// PrototypeBeanA.java
@Scope("prototype")
public class PrototypeBeanA {
private PrototypeBeanB beanB;public void setBeanB(PrototypeBeanB beanB) { this.beanB = beanB; }}
// PrototypeBeanB.java
@Scope("prototype")
public class PrototypeBeanB {
private PrototypeBeanA beanA;public void setBeanA(PrototypeBeanA beanA) { this.beanA = beanA; }}
如何处理的循环依赖
Spring 的循环依赖解决方案主要依赖于两个技术:BeanPostProcessor 和三级缓存。
- BeanPostProcessor
BeanPostProcessor 是 Spring 中的一个接口,它提供了两个方法:postProcessBeforeInitialization 和 postProcessAfterInitialization。这两个方法分别在 Bean 的初始化前后被调用,可以用来对 Bean 进行定制化处理。
在解决循环依赖问题时,Spring 使用 BeanPostProcessor 在 Bean 初始化之前对 Bean 进行处理,从而实现提前暴露半成品对象的目的。
- 三级缓存
Spring 中的 BeanFactory 是一个三级缓存结构,其中包含了singletonObjects、earlySingletonObjects 和 singletonFactories 三个缓存。
当 Spring 创建一个 Bean 的时候,它会先检查 singletonObjects 缓存中是否存在该 Bean 的实例。如果存在,直接返回该实例;否则继续创建该 Bean 的实例。
如果在创建该 Bean 的过程中出现了循环依赖,Spring 会将该 Bean 的半成品对象存储在 earlySingletonObjects 缓存中,并将其标记为"当前正在创建的 Bean",然后继续创建该 Bean 所依赖的其他 Bean。当所有的 Bean 都被创建完成后,Spring 会调用 BeanPostProcessor 的 postProcessAfterInitialization 方法,将所有标记为"当前正在创建的 Bean"的半成品对象转化为完整的 Bean 对象,并存储在 singletonObjects 缓存中。
如果在创建该 Bean 的过程中需要调用其他 Bean 的工厂方法,则 Spring会将该 Bean 的工厂方法存储在 singletonFactories 缓存中,以便在创建其他 Bean 时使用。当所有的 Bean 都被创建完成后,Spring 会遍历 singletonFactories 缓存中的所有工厂方法,调用它们的 getObject() 方法,将其转换为完整的 Bean 对象,并存储在 singletonObjects 缓存中。
通过使用三级缓存和 BeanPostProcessor,Spring 能够在 Bean 的创建过程中解决循环依赖问题,并保证所有的 Bean 都被正确地创建和初始化。