随机种子
定义一个 seed_everything() 函数,统一设置多个库的随机种子,用于设置各种随机种子以确保实验的可重复性。
在需要对比不同模型或参数时,确保随机性不会影响实验结果。
def seed_everything(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
random.seed(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
# 调用函数,设置随机种子为0
seed_everything(0)
# 后续的随机操作将是确定性的数据增广
对原始数据进行一系列有目的的变换 来人工扩展数据集的技术。
核心目的:
-
增加数据量和多样性 :尤其在数据稀缺时,避免模型因训练数据不足而过拟合(即模型过度记忆训练数据,无法泛化到新数据)。
-
提升模型泛化能力:通过让模型看到更多样的数据变体,使其对噪声、变换等更具鲁棒性,从而提高在真实场景中的表现。


Softmax 函数
Softmax 是一个数学函数,它将一组任意实数转换为概率分布。简单说,它能把模型的"原始得分"变成"概率"。

迁移学习------数据量少时的最佳选择
大佬们的模型:花了百万美元,在千万上亿的数据集上训练,提取的特征特别好。
我的模型:5000元电脑,在千张照片上训练,提取的特征:二分类准确率有百分之五十吧(基本瞎猜)
迁移学习可以理解为你把大佬的模型拿过来,用在自己的数据集训练上
有预训练模型的时候,尽量使用预训练模型。
我们使用他人模型架构的原因,最大的原因不是因为他们架构好,而是因为可以迁移。
迁移学习是一类机器学习方法,通过在源领域(source domain)或任务(source task)中学得的知识来帮助目标领域(target domain)或任务(target task)的学习。
核心思想是利用已有的模型或知识,减少在目标任务中对大规模标注数据的依赖,提高学习效率和模型性能。
优势分析
预训练模型已学习通用特征
避免从零开始学习
迁移学习的三种主要策略
特征提取(Feature Extraction)
微调(Fine-tuning)
预训练+新头(Pretrain + New Head)
保留预训练的特征提取器,替换最后的全连接层
完全相信大佬的模型,线性探测(一般不用);否则微调
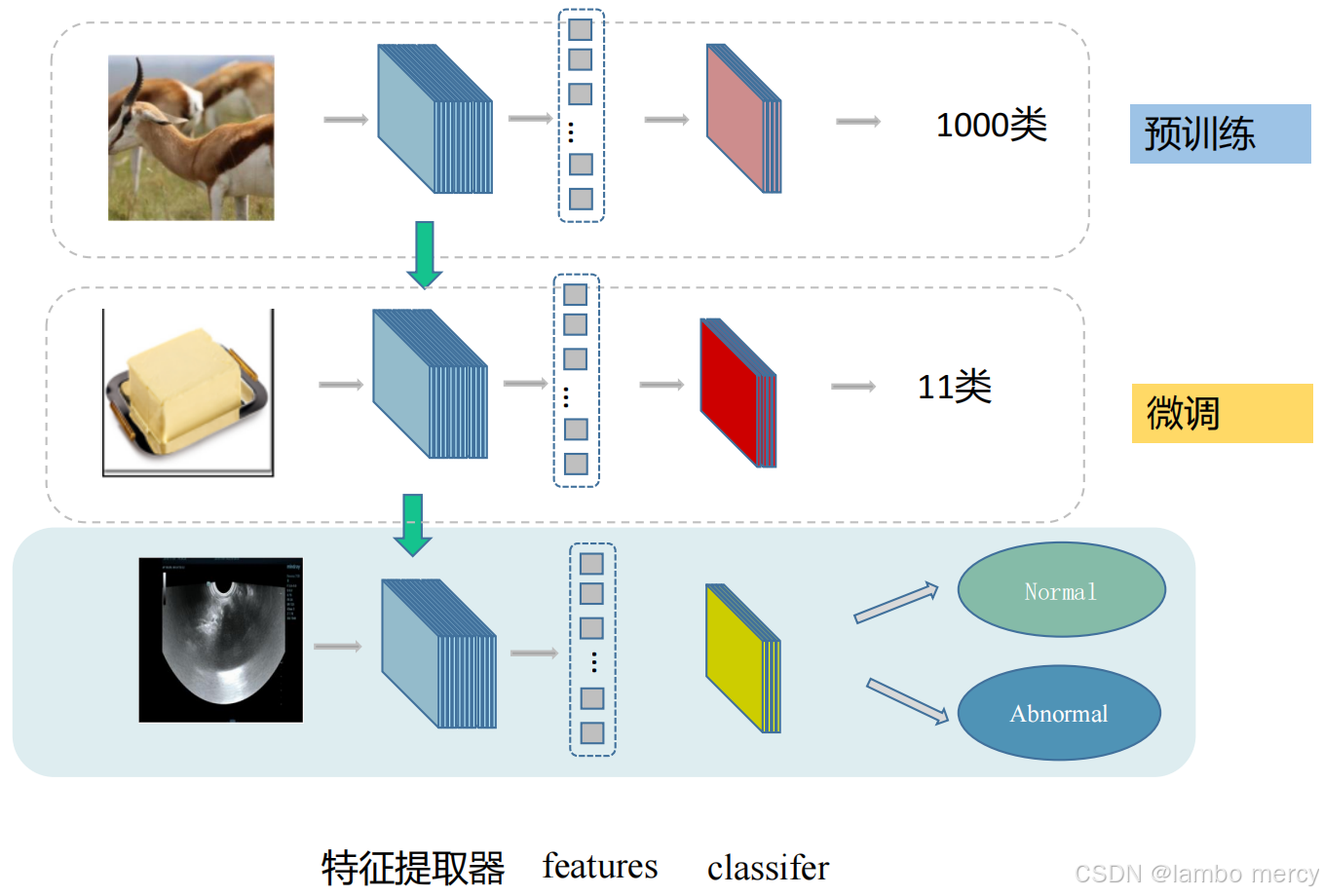
把大佬的特征提取器拿过来用,但是分类头需要用自己的。大佬分1000类,你只有11类。所以必须改分类头
归一化
归一化 是一种数据预处理技术,将数据缩放 到一个特定的范围 (通常是0,1或-1,1),或者使其具有零均值和单位方差。
# 假设一个数据集有两个特征:
特征1: 年龄 [20, 50, 80] # 范围 20-80
特征2: 收入 [30000, 80000, 150000] # 范围 30000-150000
# 如果不归一化:
# 收入的变化会完全主导年龄的影响
# 因为收入的数值比年龄大得多Adam和AdamW 优化器
SGD简单有效,但有两个主要缺点:
所有参数使用相同的学习率:对于稀疏特征或不常更新的参数,这可能不是最优的。
梯度可能不稳定:遇到陡峭或平缓的峡谷地形时,容易震荡或收敛缓慢。
为了解决这些问题,自适应优化器 应运而生。它们的核心思想是:为每个参数计算并维护其自身的、随时间变化的学习率。
Adam 结合了 动量法 和 RMSProp 的优点:
-
自适应学习率:每个参数有自己的步长。
-
包含动量:加速收敛并减少震荡。
Adam 的三大特性:
-
动量(Momentum):加速收敛,减少振荡
-
自适应学习率:每个参数有自己的学习率
-
偏差修正:解决初始估计偏差问题
基本使用
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
完整参数
optimizer = torch.optim.Adam(
model.parameters(),
lr=0.001, # 学习率
betas=(0.9, 0.999), # β1(一阶矩衰减率),β2(二阶矩衰减率)
eps=1e-8, # 数值稳定性常数
weight_decay=0, # L2正则化(权重衰减)
amsgrad=False # 是否使用AMSGrad变体
)
Dataset 和 DataLoader 的关系
Dataset 类(数据提供者)
class Dataset:
#Dataset提供给DataLoader的标准数据格式
def __getitem__(self, index):
"""返回单个样本:数据 + 标签"""
return data, label
def __len__(self):
"""返回数据集大小"""
return dataset_sizeDataLoader 类(数据组织者)
DataLoader 不需要自己定义,直接使用就可以 (PyTorch 内置了完整的 DataLoader 实现)
class DataLoader:
def __init__(self, dataset, batch_size, shuffle):
self.dataset = dataset # 持有Dataset实例
self.batch_size = batch_size
self.shuffle = shuffle
def __iter__(self):
"""返回一个迭代器,每次迭代返回一个batch"""
# 1. 生成索引序列
# 2. 分批调用 dataset.__getitem__()
# 3. 整理成batch返回PyTorch 的哲学是:
你需要自己定义
Dataset(数据如何存储和获取)PyTorch 提供
DataLoader(数据如何组织和迭代)就像餐厅的比喻:
Dataset:你是厨师,定义菜怎么做(数据格式)
DataLoader:服务员,负责把菜端给客人(数据提供给模型)你不需要自己当服务员,PyTorch 已经提供了专业的"服务员"
food_Dataset(train_path, "train") 返回的是什么?
-
返回的是对象,不是数据
train_set = food_Dataset(train_path, "train")
train_set 是一个 Dataset 对象,不是数据本身!
-
什么时候才真正获取数据?
情况1:通过索引直接访问
x, y = train_set[0] # 这里才调用 getitem(0)
情况2:通过 DataLoader 批量访问
train_loader = DataLoader(train_set, batch_size=16)
for batch_data, batch_labels in train_loader: # DataLoader内部调用 getitem
# 这里才真正加载数据
pass
train_loader = DataLoader(train_set, batch_size=16, shuffle=True)
16个样本的数据批次(不是16个Dataset对象)
每个批次包含:
batch_x: 16个图像数据(形状 16, 3, 224, 224)
batch_y: 16个对应的标签(形状 16)x和y是严格对应的
shuffle=True体现在

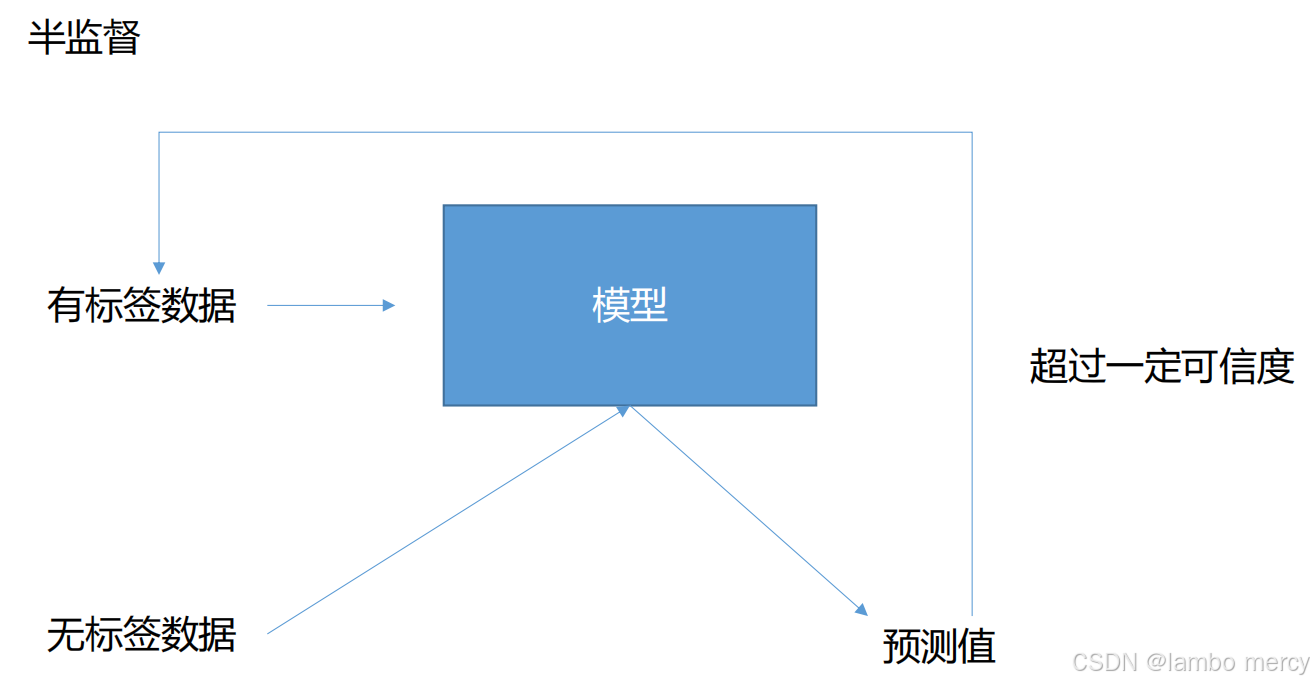
半监督学习
同时利用少量有标签数据和大量无标签数据来训练模型,以获得比仅使用有标签数据(监督学习)或仅使用无标签数据(无监督学习)更好的性能。
当模型在有标签数据上达到一定准确度后,用它对无标签数据进行预测,筛选出预测置信度高于阈值(如99%)的样本,将这些样本及其预测标签作为伪标签数据,加入到模型的训练中,从而提升模型性能。
代码
class food_Dataset(Dataset)
class food_Dataset(Dataset):
def __init__(self, path, mode="train"):
self.mode = mode
if mode == "semi":
self.X = self.read_file(path)
else:
self.X, self.Y = self.read_file(path)
self.Y = torch.LongTensor(self.Y) #标签转为长整形\
if mode == "train":
self.transform = train_transform
else:
self.transform = val_transform
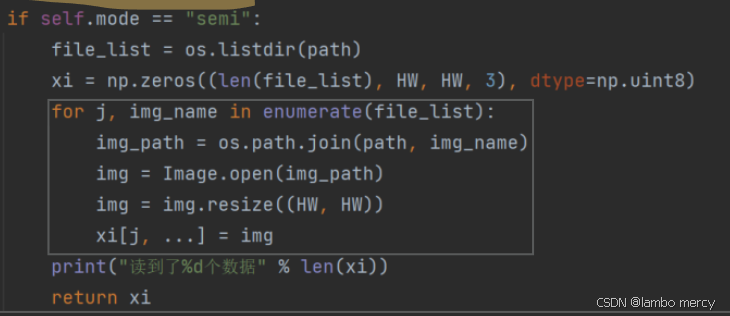
def read_file(self, path):
if self.mode == "semi":
file_list = os.listdir(path)
X = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8)
for j, img_name in enumerate(file_list):
img_path = os.path.join(path, img_name)
img = Image.open(img_path)
img = img.resize((HW, HW))
X[j, ...] = img
print("读到了%d个数据" % len(X))
return X
else:
for i in tqdm(range(11)):
file_dir = path + "/%02d" % i
file_list = os.listdir(file_dir)
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8)
yi = np.zeros(len(file_list), dtype=np.uint8)
# 列出文件夹下所有文件名字
for j, img_name in enumerate(file_list):
img_path = os.path.join(file_dir, img_name)
img = Image.open(img_path)
img = img.resize((HW, HW))
xi[j, ...] = img
yi[j] = i
if i == 0:
X = xi
Y = yi
else:
X = np.concatenate((X, xi), axis=0)
Y = np.concatenate((Y, yi), axis=0)
print("读到了%d个数据" % len(Y))
return X, Y
def __getitem__(self, item):
if self.mode == "semi":
return self.transform(self.X[item]), self.X[item]
else:
return self.transform(self.X[item]), self.Y[item]
def __len__(self):
return len(self.X)def read_file
首先我们肯定要读出这个照片数据,这里分为有标签的数据和无标签的数据:
1、有标签的数据,调用read_file 函数,获取他的图片和标签
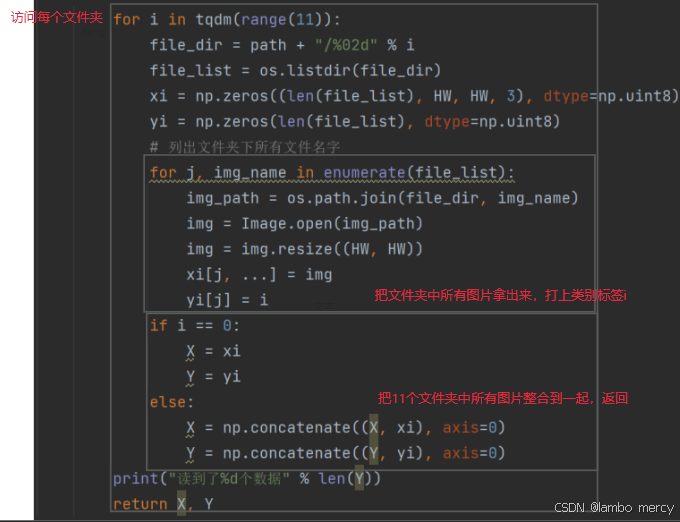
根据文件我们知道一共有11个类别,每个文件夹中有若干照片。首先遍历这11个文件夹,拿到文件夹中每一张照片,放到xi数组中,对应的yi数组存放类别。
一个文件夹遍历一遍,每次遍历结束后都把收集到的xi和yi合并到大的X和Y数组中,等11个文件夹全部遍历结束,我们就能拿到完整的X和Y数组
2、无标签的数据,调用read_file 函数,只能获取到他的图片
def init
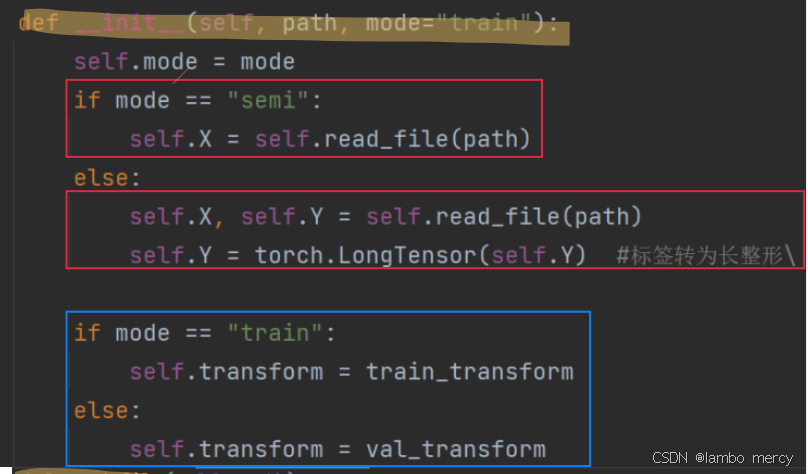
init中我们拿到了初始的数据,根据模式mode我们分配不同的transform,当**Dataset获取数据的时候自动进行图片变换**
def getitem
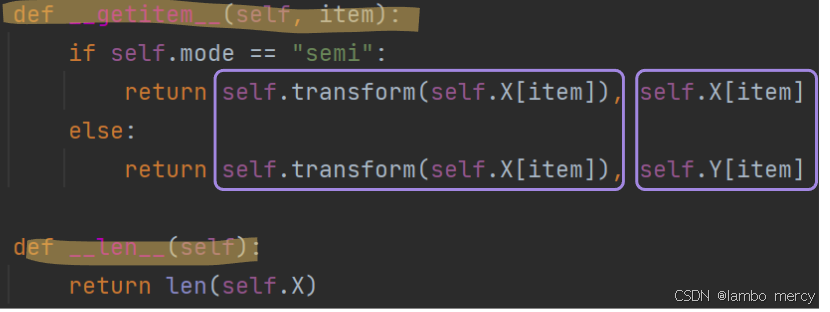
当 food_Dataset(train_path, "train") 调用时,如果是semi返回的就是预处理后的数据和原始数据;如果不是semi,返回的就是变换后的数据和原始标签
transform
train_transform = transforms.Compose([
transforms.ToPILImage(), #224, 224, 3模型 :3, 224, 224
transforms.RandomResizedCrop(224),
transforms.RandomRotation(50),
transforms.ToTensor()
])
val_transform = transforms.Compose([
transforms.ToPILImage(), #224, 224, 3模型 :3, 224, 224
transforms.ToTensor()
])如果是训练数据,我们不仅需要预处理,还要数据增强
- 将输入数据转换为 PIL Image 格式
2. 随机调整图像大小并裁剪到 224x224
3. 随机旋转图像
- 将 PIL Image 转换为 PyTorch Tensor
如果是semi或者val数据,我们只需要基本的预处理
-
将输入数据转换为 PIL Image 格式
-
将 PIL Image 转换为 PyTorch Tensor
class myModel(nn.Module)
class myModel(nn.Module):
def __init__(self, num_class):
super(myModel, self).__init__()
#3 *224 *224 -> 512*7*7 -> 拉直 -》全连接分类
self.conv1 = nn.Conv2d(3, 64, 3, 1, 1) # 64*224*224
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU()
self.pool1 = nn.MaxPool2d(2) #64*112*112
self.layer1 = nn.Sequential(
nn.Conv2d(64, 128, 3, 1, 1), # 128*112*112
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2) #128*56*56
)
self.layer2 = nn.Sequential(
nn.Conv2d(128, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2) #256*28*28
)
self.layer3 = nn.Sequential(
nn.Conv2d(256, 512, 3, 1, 1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2) #512*14*14
)
self.pool2 = nn.MaxPool2d(2) #512*7*7
self.fc1 = nn.Linear(25088, 1000) #25088->1000
self.relu2 = nn.ReLU()
self.fc2 = nn.Linear(1000, num_class) #1000-11
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.pool1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.pool2(x)
x = x.view(x.size()[0], -1)
x = self.fc1(x)
x = self.relu2(x)
x = self.fc2(x)
return x卷积
nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
3:输入通道数(RGB图像的3个通道)
64:输出通道数
3:卷积核大小3×3
1:步长(每次移动1像素)
1:填充(在图像四周填充1圈0值像素)
self.conv1 = nn.Conv2d(3, 64, 3, 1, 1) #输出:64×224×224(保持了原始图像尺寸)
批量归一化
self.bn1 = nn.BatchNorm2d(64) # 对64个通道的特征图进行批量归一化
激活函数
self.relu = nn.ReLU()池化
self.pool1 = nn.MaxPool2d(2)展开
卷积网络连接到全连接层的必要操作
x = x.flatten(1) # 从第1维开始展平全连接层
self.fc1 = nn.Linear(25088, 1000) class semiDataset(Dataset)
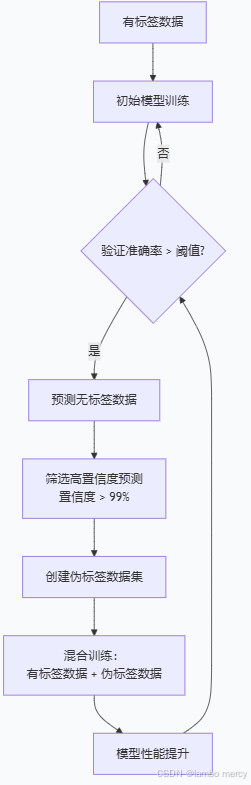
伪标签数据集
class semiDataset(Dataset):
def __init__(self, no_label_loder, model, device, thres=0.99):
x, y = self.get_label(no_label_loder, model, device, thres)
if x == []:
self.flag = False
else:
self.flag = True
self.X = np.array(x)
self.Y = torch.LongTensor(y)
self.transform = train_transform
def get_label(self, no_label_loder, model, device, thres):
model = model.to(device)
pred_prob = []
labels = []
x = []
y = []
soft = nn.Softmax()
with torch.no_grad():
for bat_x, _ in no_label_loder:
bat_x = bat_x.to(device)
pred = model(bat_x)
pred_soft = soft(pred)
pred_max, pred_value = pred_soft.max(1)
pred_prob.extend(pred_max.cpu().numpy().tolist())
labels.extend(pred_value.cpu().numpy().tolist())
for index, prob in enumerate(pred_prob):
if prob > thres:
x.append(no_label_loder.dataset[index][1]) #调用到原始的getitem
y.append(labels[index])
return x, y
def __getitem__(self, item):
return self.transform(self.X[item]), self.Y[item]
def __len__(self):
return len(self.X)def get_label 获取伪标签
什么样的伪标签是可以用的?
置信度超过阈值的伪标签,可以用作正式训练的标签
第一步:使用训练好的模型批量预测无标签数据,获取每个样本的预测置信度和预测类别,并收集起来用于后续的伪标签生成。
with torch.no_grad():
for batch_x , _ in no_label_loader:
batch_x = batch_x .to(device)
predict = model(batch_x)
predict_soft = Softmax(predict)
pred_max, pred_index = predict_soft.max(1)
predict_proba.extend(pred_max.cpu().numpy().tolist())
predict_labels.extend(pred_index.cpu().numpy().tolist())第二步:筛选出预测置信度高于阈值的高质量预测,将对应的原始数据和预测类别作为伪标签数据返回。
for index, prob in enumerate(predict_proba):
if prob > thres:
x.append(no_label_loader.dataset[index][1]) #调用到原始的x
y.append(predict_labels[index])
return x, ydef init
初始化semiDataset对象,通过生成伪标签创建新的带标签数据集,并根据是否成功生成有效伪标签设置标志位和数据属性。
def __init__(self, no_label_loder, model, device, thres=0.99):
x, y = self.get_label(no_label_loder, model, device, thres)
if x == []:
self.flag = False
else:
self.flag = True
self.X = np.array(x)
self.Y = torch.LongTensor(y)
self.transform = train_transformdef getitem
Dataset提供给DataLoader的标准数据格式
def __getitem__(self, item):
return self.transform(self.X[item]), self.Y[item]def get_semi_loader
def get_semi_loader(no_label_loder, model, device, thres):
semiset = semiDataset(no_label_loder, model, device, thres)
if semiset.flag == False:
return None
else:
semi_loader = DataLoader(semiset, batch_size=16, shuffle=False)
return semi_loader创建一个包含伪标签数据的DataLoader,如果成功生成了有效的伪标签数据集,则返回该DataLoader用于训练,否则返回None。
def train_val
-
初始化
def train_val(model, train_loader, val_loader, no_label_loader, device, epochs, optimizer, loss, thres, save_path):
model = model.to(device) # 模型移动到指定设备
semi_loader = None # 半监督数据加载器初始为空# 记录训练历史的列表 plt_train_loss = [] # 训练损失 plt_val_loss = [] # 验证损失 plt_train_acc = [] # 训练准确率 plt_val_acc = [] # 验证准确率 max_acc = 0.0 # 记录最佳验证准确率
设置训练环境,初始化跟踪变量,为训练循环做准备。
-
训练主循环
for epoch in range(epochs):
# 重置每个epoch的计数器
train_loss = 0.0
val_loss = 0.0
train_acc = 0.0
val_acc = 0.0
semi_loss = 0.0
semi_acc = 0.0start_time = time.time() # 计时开始 model.train() # 切换到训练模式
控制训练轮次,每轮重置指标,设置训练模式。
3. 有标签数据训练
for batch_x, batch_y in train_loader:
# 数据移动到设备
x, target = batch_x.to(device), batch_y.to(device)
# 前向传播
pred = model(x)
# 计算损失
train_bat_loss = loss(pred, target)
# 反向传播
train_bat_loss.backward() # 计算梯度
optimizer.step() # 更新参数
optimizer.zero_grad() # 清空梯度
# 累加损失
train_loss += train_bat_loss.cpu().item()
# 计算准确率
train_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())-
半监督数据训练
if semi_loader != None:
for batch_x, batch_y in semi_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
semi_bat_loss = loss(pred, target)
semi_bat_loss.backward()
optimizer.step()
optimizer.zero_grad()semi_loss += train_bat_loss.cpu().item() semi_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy()) print("半监督数据集的训练准确率为", semi_acc/train_loader.dataset.__len__())
关键点:
-
只有在生成伪标签数据后才执行
-
训练逻辑与有标签数据完全相同
-
但使用的是伪标签而不是真实标签
-
打印的是伪标签训练准确率(模型对伪标签的拟合程度)
-
验证eval
model.eval() # 切换到评估模式
with torch.no_grad(): # 禁用梯度计算
for batch_x, batch_y in val_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
val_bat_loss = loss(pred, target)
val_loss += val_bat_loss.cpu().item()
val_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy()) -
伪标签更新
if epoch % 3 == 0 and plt_val_acc[-1] > 0.6:
semi_loader = get_semi_loader(no_label_loader, model, device, thres)
-
周期性更新:每3个epoch更新一次伪标签
-
条件触发:只在验证准确率>60%时才生成伪标签
-
为什么需要条件:
-
初期模型不准 → 伪标签质量差 → 影响训练
-
中期模型较准 → 高质量伪标签 → 提升性能
-
-
动态调整:每次用最新模型重新生成伪标签
-
模型保存
if val_acc > max_acc:
torch.save(model, save_path)
max_acc = val_acc
-
保存验证集上表现最好的模型
-
避免过拟合后模型性能下降
-
torch.save(model, save_path):保存整个模型结构和参数
-
日志输出
print('[%03d/%03d] %2.2f 秒 TrainLoss : %.6f | valLoss: %.6f Trainacc : %.6f | valacc: %.6f' %
(epoch, epochs, time.time() - start_time,
plt_train_loss[-1], plt_val_loss[-1],
plt_train_acc[-1], plt_val_acc[-1]))
训练流程
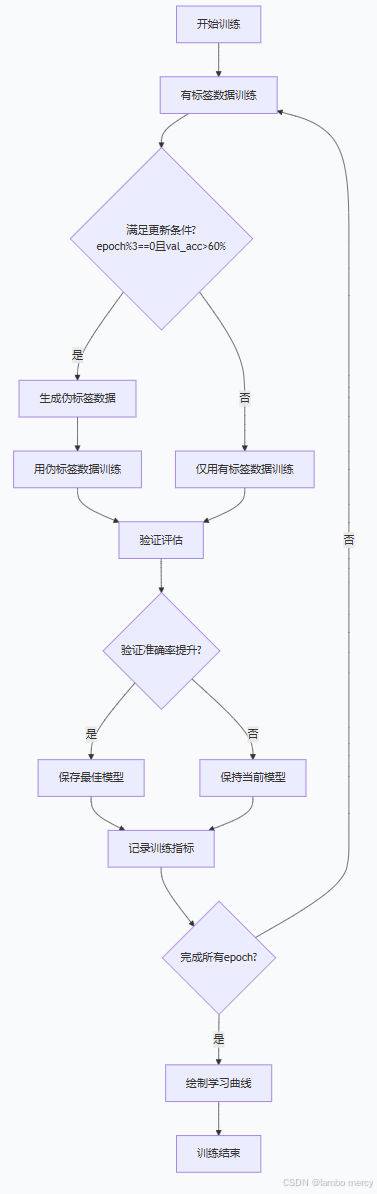
- 渐进式学习
先学简单的(有标签数据)
再学困难的(伪标签数据)
- 质量控制
只使用高置信度伪标签 , 加入训练
if prob > thres: # thres=0.99
- 动态调整
定期更新伪标签
随着模型变好,伪标签质量提高
形成良性循环
- 防止误差传播
条件触发机制
if plt_val_acc-1 > 0.6:
只有模型够好时才生成伪标签
这个训练函数实现了完整的自训练半监督学习框架,通过有标签数据和伪标签数据的混合训练,有效利用无标签数据提升模型性能。