目录
- 前言
- 一、deque的结构剖析
-
- [1.1 deque的优缺点](#1.1 deque的优缺点)
- 二、priority_queue(优先级队列)
-
- [2.1 核心定义](#2.1 核心定义)
- [2.2 底层结构与核心依赖](#2.2 底层结构与核心依赖)
- [2.3 核心特性](#2.3 核心特性)
- [2.4 关键用法:自定义优先级(小顶堆 / 自定义规则)](#2.4 关键用法:自定义优先级(小顶堆 / 自定义规则))
- 三、priority_queue的模拟实现
-
- [3.1 向上调整建大堆](#3.1 向上调整建大堆)
-
- [3.1.1 ADL(参数依赖查找)](#3.1.1 ADL(参数依赖查找))
- [3.2 pop() + 向下调整建大堆](#3.2 pop() + 向下调整建大堆)
- [3.3 迭代器区间初始化 + 向下调整建大堆](#3.3 迭代器区间初始化 + 向下调整建大堆)
- [3.4 size](#3.4 size)
- 四、完整源码
- 结语


🎬 云泽Q :个人主页
🔥 专栏传送入口 : 《C语言》《数据结构》《C++》《Linux》《蓝桥杯系列》
⛺️遇见安然遇见你,不负代码不负卿~
前言
大家好啊,我是云泽Q ,欢迎阅读我的文章,一名热爱计算机技术的在校大学生,喜欢在课余时间做一些计算机技术的总结性文章,希望我的文章能为你解答困惑~
本文是上一篇文章的续写,结合上一篇文章来看体验更佳STL容器性能探秘:stack、queue、deque的实现与CPU缓存命中率优化
一、deque的结构剖析
deque就是一个被设计出来用来尝试兼容二者优点的数据结构,但是最终从结论来看deque是一个半成品
链表一个小空间就存一个数据优点浪费,deque的结构就是由一个个的小数组buffer构成,这个小数组的大小由开发者自己定义,存10个或8个数据都可以,当第一个buffer存满了之后不进行扩容,再开一个buffer,以此类推,buffer之间是用一个中控数组(指针数组)来管理,中控数组中存有一些指针指向这些buffer
这样vector的缺点:扩容的性能消耗就没有了,空间浪费还有,但是不多,就算一个buffer可以存一个数据,只存1个数据的话也最多浪费9个,CPU高速缓存访问命中率也不错,一个buffer一次存几十个字节,访问第一个数据后面的数据也会加载进去,且支持下标的随机访问。

相比list,deque的底层是连续空间,访问数据的时候计算出上图的x,和y也可以直接访问数据,不用像lis是单向的,需要从前往后遍历找
deuqe其实也是存在扩容的,比如说中控数组满了也是需要扩容的,但是该扩容代价就很低(只需要拷贝指针),vector扩容若存的数据类型是string,就需要拷贝string,代价很高
下面再继续分析他的结构
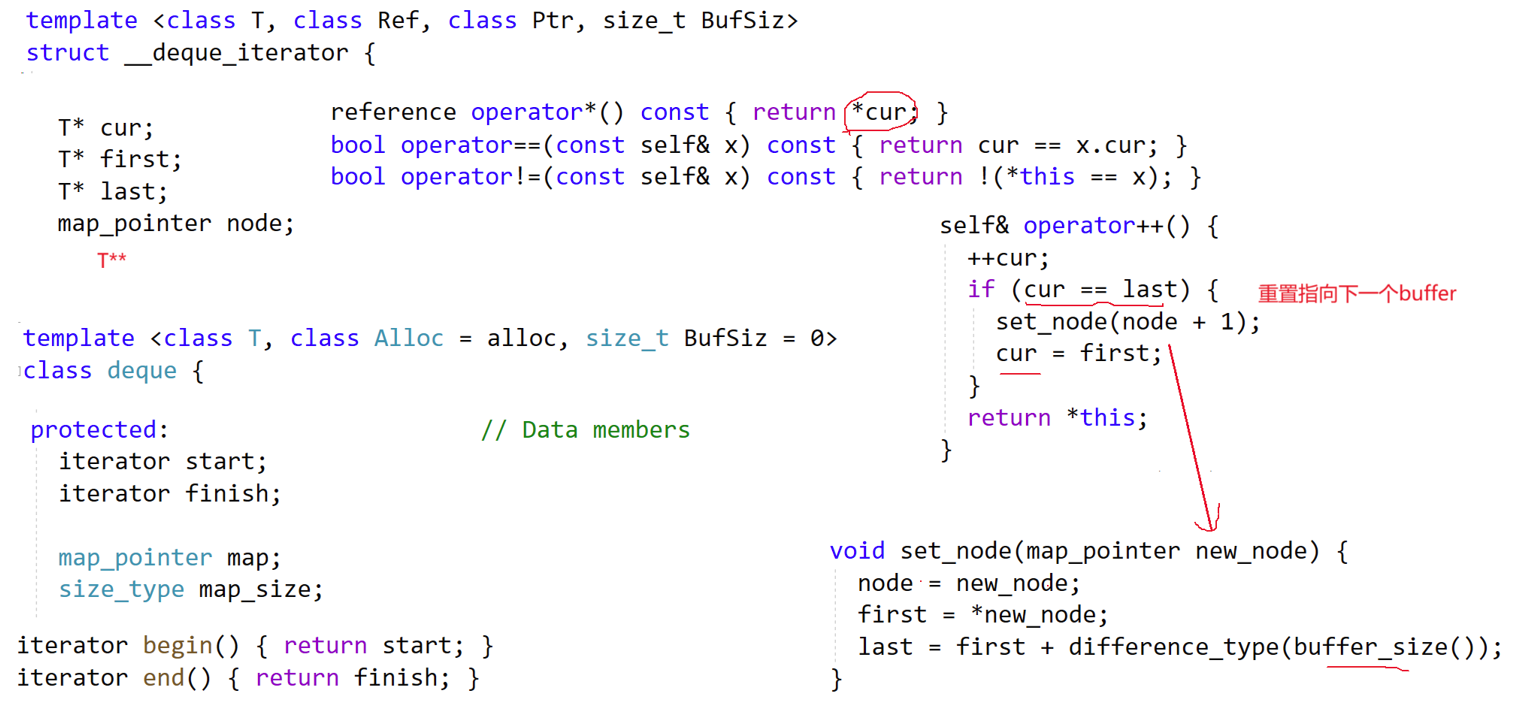
库中deque的迭代器设计比较复杂,string,vector的迭代器是直接对原生指针进行typedef,list的迭代器是对节点的指针用类进行封装,deque的迭代器是用四个指针进行封装(因为要跨缓冲区遍历)
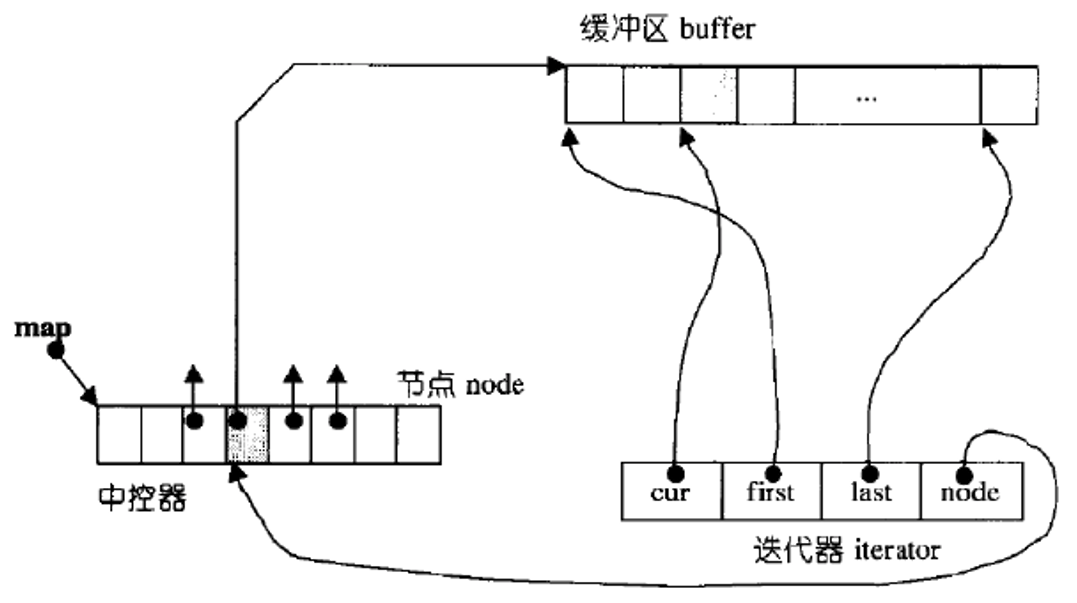
cur:指向当前缓冲区中正在访问的元素 (如图中迭代器的cur指向某个元素);
first:指向当前缓冲区的起始位置 (比如第一个缓冲区的0);
last:指向当前缓冲区的末尾位置 (比如第一个缓冲区的7);
node(二级指针):指向中控器中当前缓冲区对应的指针 (即中控器指针数组里的某个元素)。
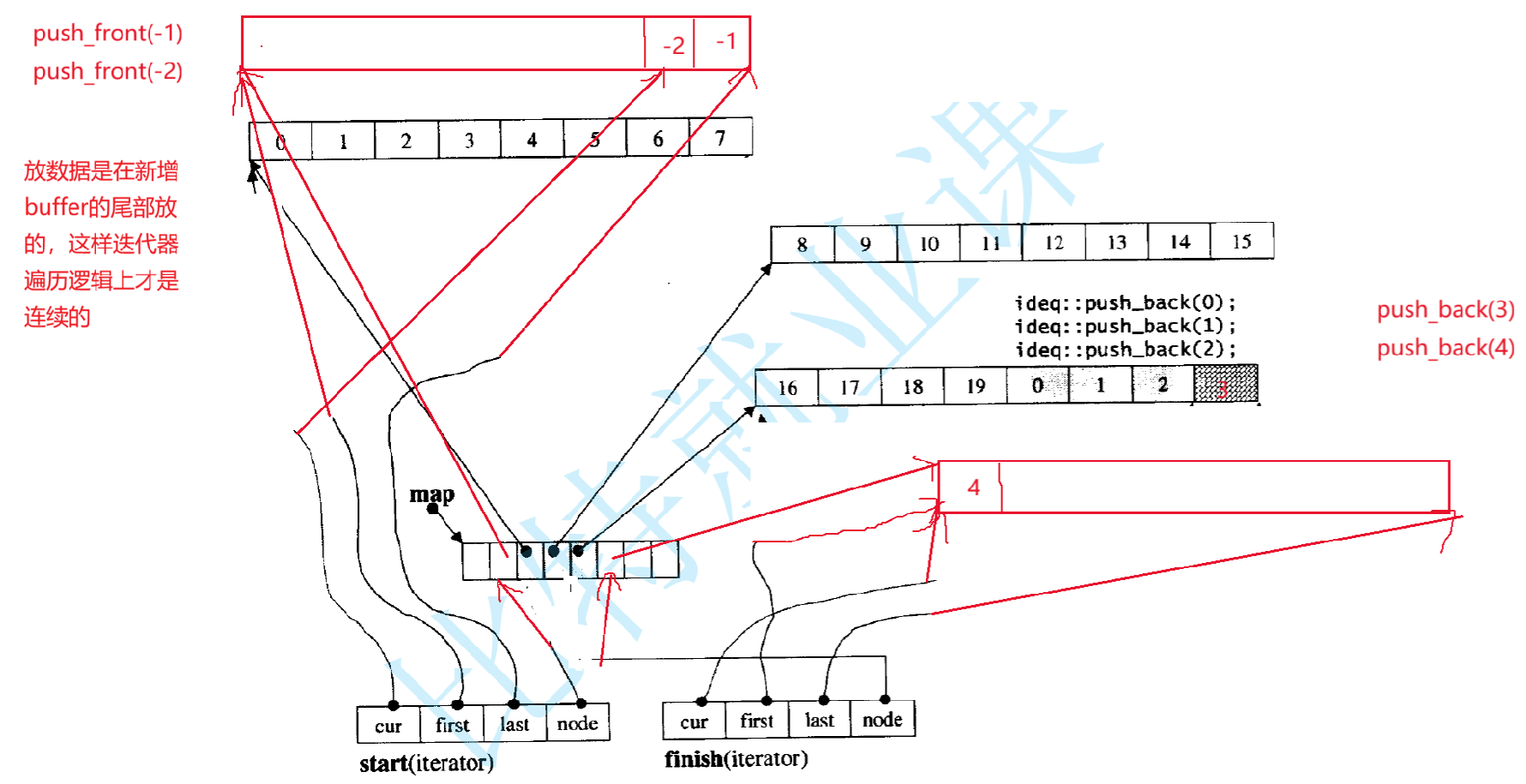
元素的存储逻辑 :push_back(尾插)会往最后一个缓冲区的末尾 添加元素,若该缓冲区已满,则新建一个缓冲区并挂到中控器;push_front(头插)会往第一个缓冲区的开头 添加元素,若该缓冲区已满,则新建缓冲区挂到中控器(原第一个buffer不是从中控数组的开始位置开始放的,而是差不多放在一个中间位置,这样的优点就是头插不需要对中控数组马上扩容的,方便头插)。
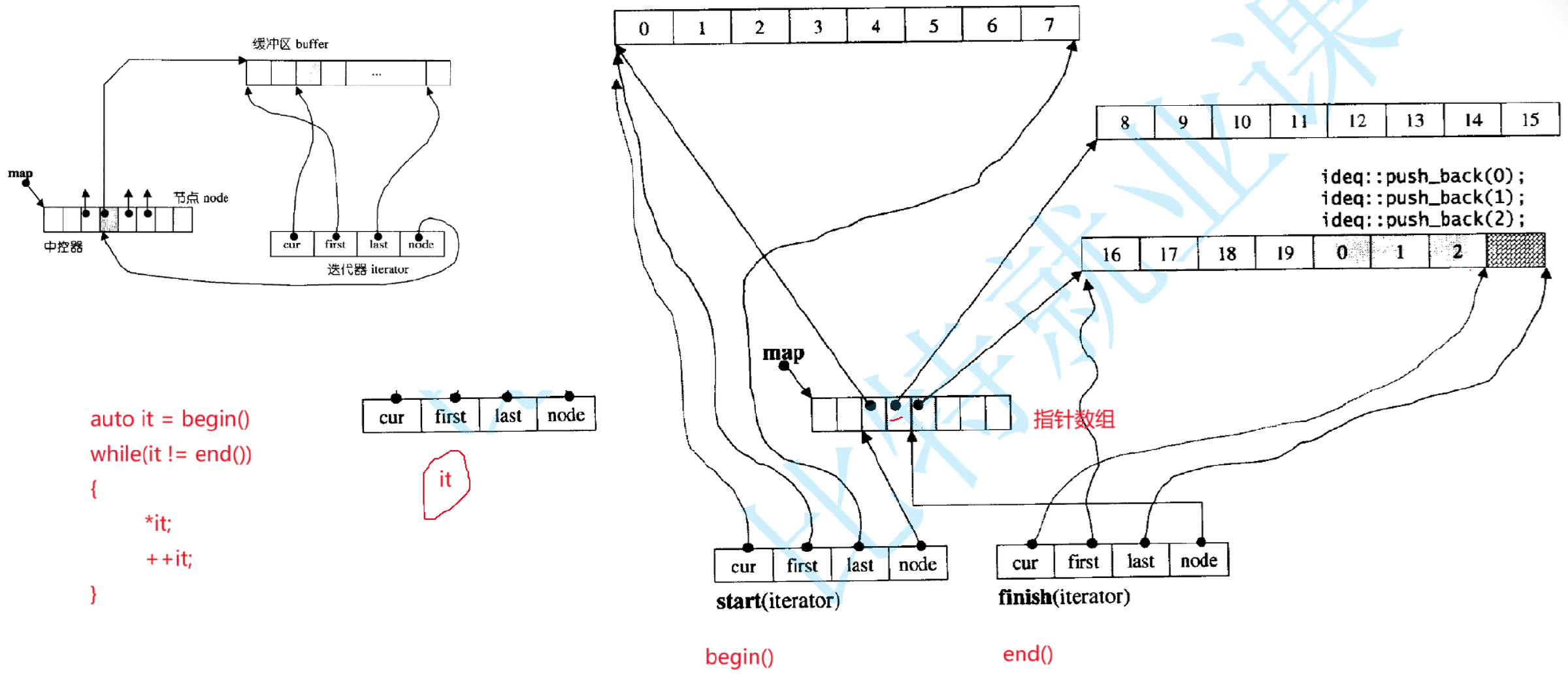
迭代器的遍历逻辑 (对应图左侧的循环auto it = begin(); while(it != end()) {*it; ++it;}):
begin()返回start迭代器(一个临时的deque<int>::iterator对象);
调用迭代器的拷贝构造函数 (__deque_iterator的拷贝构造是浅拷贝),将临时对象的 4 个成员(cur/first/last/node)依次赋值给it的对应成员;
拷贝完成后,it成为一个独立的迭代器对象,但它的 4 个成员指针和start指向相同的内存地址(比如it.cur = start.cur = &buf0[0])。
cpp
迭代器的浅拷贝是安全的:因为迭代器只是 "指向数据的工具",不管理内存,拷贝仅复制指针值,不会导致数据重复或内存泄漏。- 当++it时,先让cur指向当前缓冲区的下一个元素;
- 若cur到达last(当前缓冲区末尾),则通过node(++node)找到中控器里下一个缓冲区的指针,然后将first/last切换为新缓冲区的起止,cur指向新缓冲区的first(实现跨缓冲区遍历);
- begin()对应的是start迭代器:cur指向第一个缓冲区的第一个元素,node指向中控器第一个缓冲区的指针;
- end()对应的是finish迭代器:cur指向最后一个缓冲区的下一个位置(不是实际元素),node指向中控器最后一个缓冲区的指针。
结合图中push_back操作看deque的扩容
图右侧的ideq::push_back(0); push_back(1); push_back(2);展示了尾插逻辑:
- 尾插会优先往最后一个缓冲区的末尾添加元素;
- 若最后一个缓冲区已满(比如图中前两个缓冲区07、815已存满),则新建一个缓冲区(图中第三个16~23),并在中控器的指针数组中添加指向该缓冲区的指针;
- 新元素(0、1、2)被存入新缓冲区的起始位置(或末尾,取决于缓冲区是否为空)。
补充:图中map是一个指向中控数组的指针(二级指针)
这是对应源码的核心逻辑,可以对照看一下
并且还有一些情况不能直接除和模,比如要访问第12个数据,前提是前面每个buffer是存满的,像上上图第一个buffer存了两个数据(不满),要把第一个buffer的数据个数减掉,然后再来计算在第几个buffer,在第几个buffer中的哪个位置,要进行好几步计算
1.1 deque的优缺点
一、deque 的核心优点
- 头尾插入 / 删除操作高效(时间复杂度 O (1))
-
- 原因:deque的头尾操作 仅需操作第一个 / 最后一个缓冲区的头尾位置 (若缓冲区未满,直接插入 / 删除;若缓冲区已满,只需新增一个缓冲区并挂到中控器,无需移动其他元素)。很适合做stack和queue的默认适配容器
-
- 对比:
优于vector:vector尾插虽 O (1) 但扩容时需拷贝整块内存,头插则需移动所有元素(O (n));
优于list:list头尾操作也是 O (1),但deque单缓冲区内连续存储,缓存效率更高。
- 对比:
- 动态扩容成本极低
-
- 原因:deque扩容是新增独立的分段缓冲区,只需在中控器的指针数组中添加新缓冲区的地址,无需像vector那样拷贝原有的所有元素(vector扩容的拷贝成本是 O (n))。
-
- 场景:当需要频繁动态扩展容器大小时,deque的扩容开销远低于vector。
- 单缓冲区内连续存储,缓存命中率远高于list
原因:deque的每个缓冲区是连续内存,访问缓冲区内的元素时,能利用 CPU 缓存的 "局部性原理"(一次加载整个缓存行),避免list分散节点导致的频繁缓存未命中。
实际表现:遍历deque的效率远高于list,接近vector的遍历效率。 - 支持随机访问(时间复杂度 O (1))
原因:通过中控器的指针数组,可快速定位元素所在的缓冲区(计算map的索引),再通过缓冲区的偏移量找到目标元素(bufoffset)。
对比:list不支持随机访问(需遍历节点,O (n)),deque的随机访问能力比list更灵活。
二、deque 的核心缺点
- 中间位置的插入 / 删除效率低(时间复杂度 O (n))
-
- 原因:中间操作需要移动 "插入 / 删除位置之后的所有元素"------ 若元素跨多个缓冲区,需移动多个缓冲区内的元素(而list中间操作是 O (1),仅需调整指针)。
-
- 场景:若业务需频繁在容器中间操作,deque远不如list高效。
- 随机访问效率低于vector
-
- 原因:deque的随机访问需经过 "中控器找缓冲区指针→缓冲区内部找偏移" 两步跳转,而vector是直接的内存地址偏移 (仅需
base_ptr + index),硬件层面更高效。
- 原因:deque的随机访问需经过 "中控器找缓冲区指针→缓冲区内部找偏移" 两步跳转,而vector是直接的内存地址偏移 (仅需
-
- 实际表现:deque的\[\]操作虽然是 O (1),但实际执行速度比vector慢 2~3 倍。
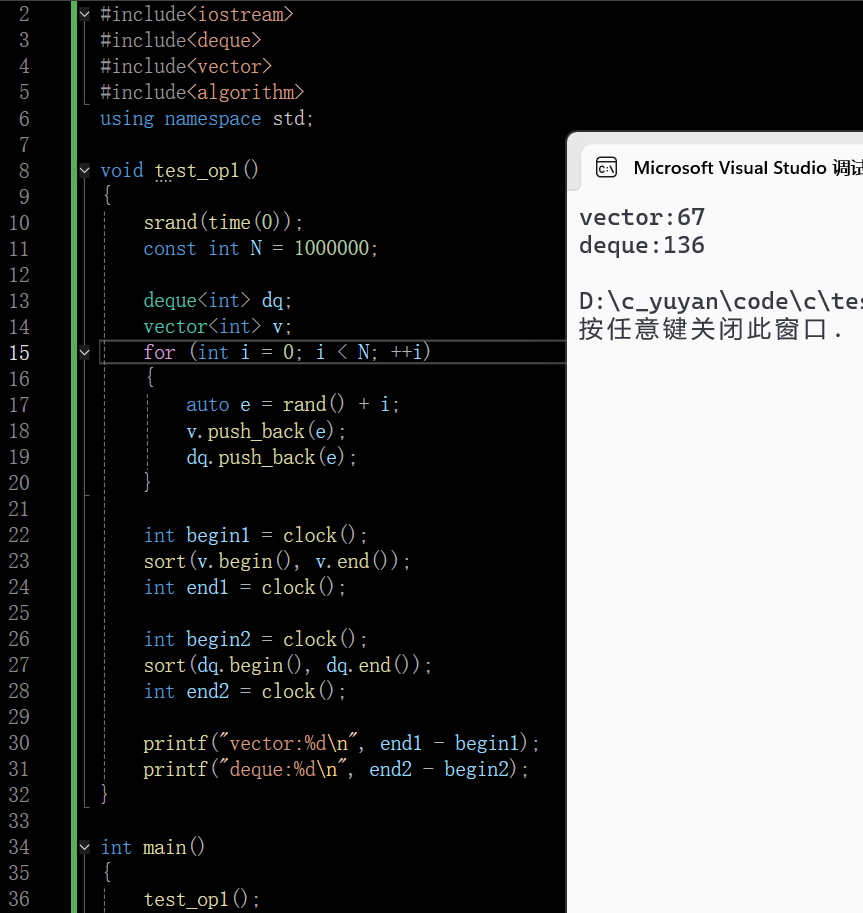
这里是用STL中的sort间接体现 deque 的随机访问效率劣势,STL 的sort的核心要求是容器支持随机访问迭代器 ,且排序过程中会频繁执行随机访问操
而vector和deque的随机访问底层逻辑差异,会被sort的高频随机访问放大,最终体现在耗时上
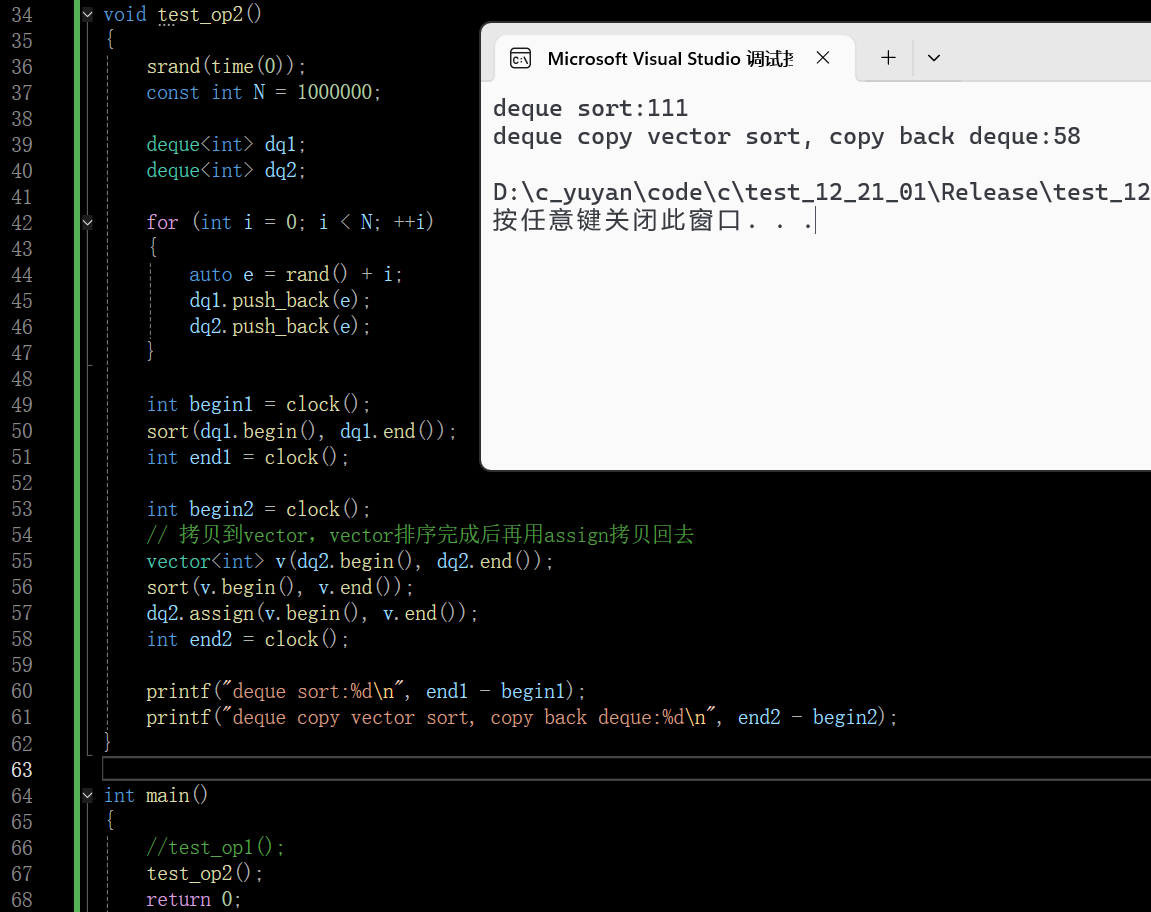
拷贝到vector排序都快一筹
- 实际表现:deque的\[\]操作虽然是 O (1),但实际执行速度比vector慢 2~3 倍。
- 迭代器复杂且操作成本高
-
- 原因:deque的迭代器是 "智能指针类型"(包含cur/first/last/node四个成员),
++it/--it等操作需判断是否跨缓冲区(涉及node跳转、first/last更新),而vector的迭代器是普通指针(操作仅需简单地址偏移)。
- 原因:deque的迭代器是 "智能指针类型"(包含cur/first/last/node四个成员),
-
- 限制:deque迭代器不支持 "随意加减法"(如
it += 5)------ 需逐次判断跨缓冲区,效率远低于vector迭代器。
- 限制:deque迭代器不支持 "随意加减法"(如
- 存在内存碎片化风险
原因:deque由多个独立的分段缓冲区组成,虽然单个缓冲区是连续的,但整体内存是分散的(不像vector是整块连续内存),长期频繁扩容可能导致更多内存碎片。
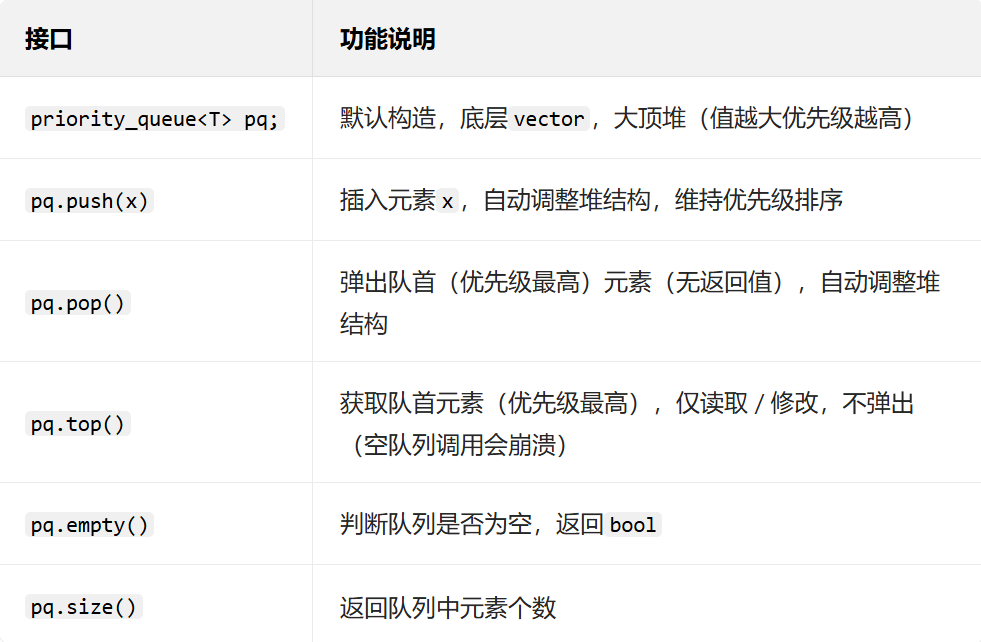
二、priority_queue(优先级队列)
2.1 核心定义
priority_queue没有单独的头文件,其包含在queue这个头文件中
priority_queue也是一个容器适配器,其核心特性是:内部元素会自动按 "优先级" 排序,每次访问 / 弹出的都是优先级最高的元素(默认是 "值越大优先级越高")。
底层本质是:基于「随机访问容器(默认vector)」+「堆排序算法」实现,本质是一棵完全二叉树结构的堆(默认大顶堆)。
其模板还有一个参数是仿函数,后面我会出一篇文章单独来写,其接口的含义与之前容器也有些区别
2.2 底层结构与核心依赖
- 容器适配器特性
priority_queue依赖底层容器存储数据,满足两个要求:
-
- 底层容器必须支持随机访问(需 /at()或随机访问迭代器);
-
- 支持push_back()/pop_back()/size()/empty()等接口。
默认底层容器是vector,也可指定deque(但不能用 list------list 不支持随机访问,堆算法无法执行)。
- 支持push_back()/pop_back()/size()/empty()等接口。
- 堆算法的支撑
STL 通过make_heap(构建堆)、push_heap(插入元素调整堆)、pop_heap(弹出元素调整堆)等算法,基于底层容器的连续内存,维护堆的结构:
-
- 大顶堆(默认):根节点(队首)是最大值,每个父节点值≥子节点;
-
- 小顶堆(自定义):根节点是最小值,每个父节点值≤子节点。
2.3 核心特性
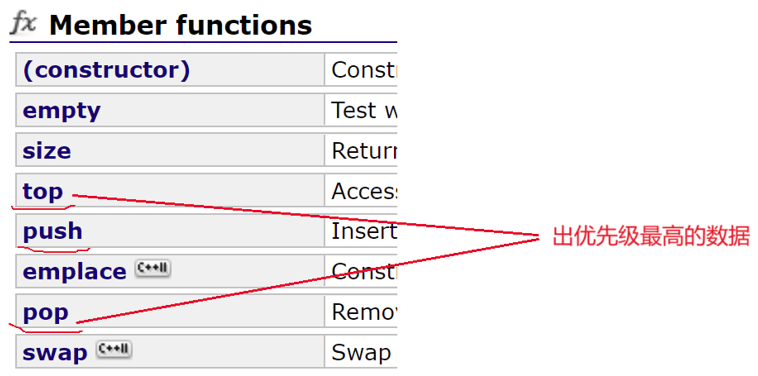
- 优先级自动排序:插入元素时,容器会自动调整堆结构,保证队首始终是优先级最高的元素(无需手动排序);
- 访问限制 :仅能访问队首(优先级最高)元素,不支持随机访问、不支持遍历(无begin()/end()迭代器);
- 时间复杂度:
-
- push()(插入元素):O (logn)(堆的上浮调整);
-
- pop()(弹出队首):O (logn)(堆的下沉调整);
-
- top()(获取队首):O (1)(直接访问堆顶);
-
- 构建堆(初始化):O (n)。

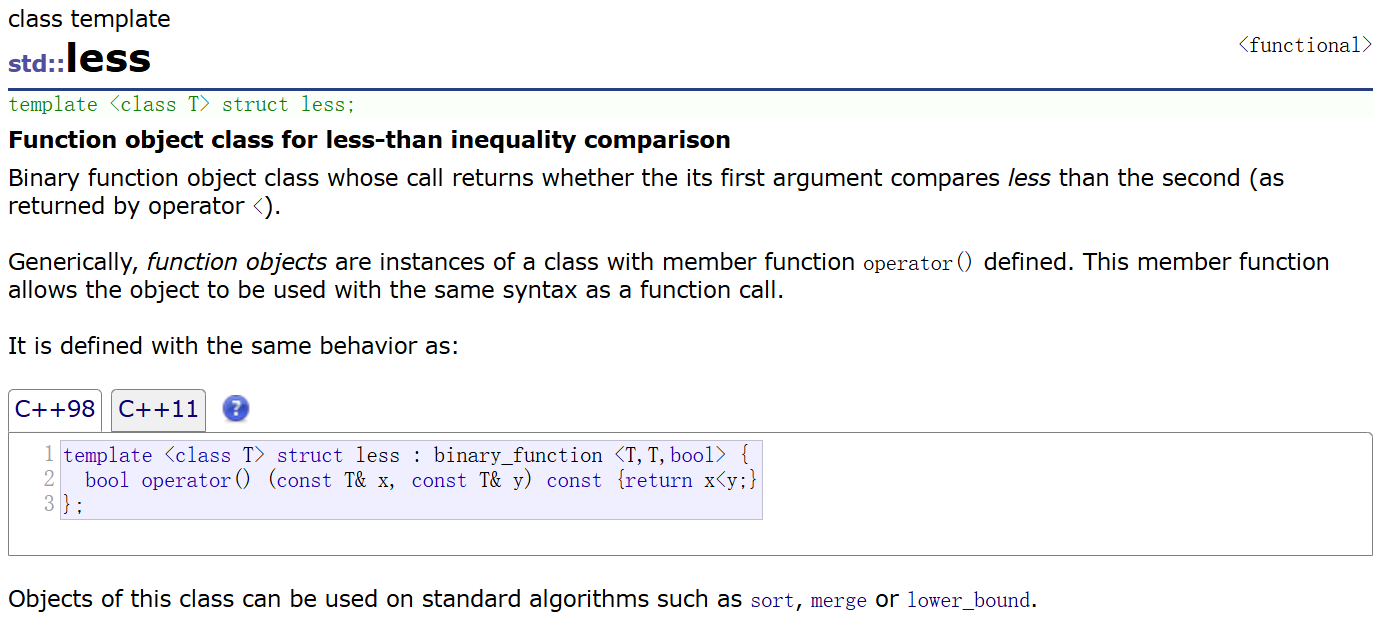
2.4 关键用法:自定义优先级(小顶堆 / 自定义规则)

默认是 "大顶堆",若需调整优先级,需指定「底层容器」+「比较规则」:
库里面实现的两个仿函数的类型,仿函数就是重载了一个运算符operator(),其就可以像函数一样去使用,仿照函数功能的一个类,有些书上也被叫做函数对象(这个类的对象具有像函数一样去调用的功能)
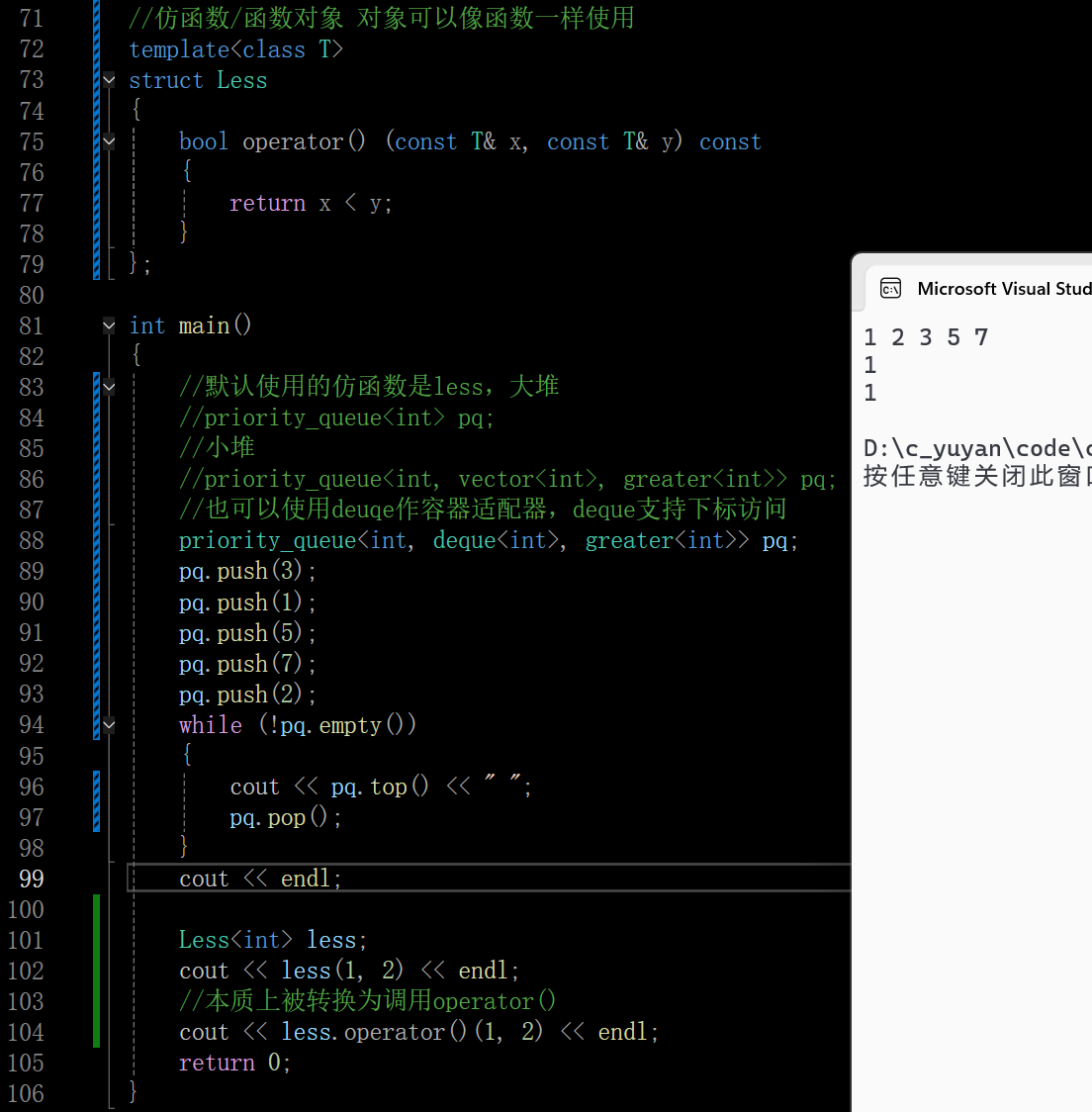
补充一点:主流的容器适配器(stack/queue/priority_queue)为了保证自身数据结构的访问规则,是刻意不暴露迭代器接口的
stack/queue:完全不暴露迭代器(STL 标准实现)
这两个适配器的设计目标是严格遵循固定的访问规则:
-
- stack:仅支持 "后进先出(LIFO)",只能访问 / 操作栈顶元素;
-
- queue:仅支持 "先进先出(FIFO)",只能访问 / 操作队首 / 队尾元素。
如果暴露迭代器(begin()/end()),用户可以遍历、修改任意位置的元素,直接打破stack/queue的核心访问规则(比如stack本应只能操作栈顶,却能通过迭代器修改栈底元素),违背其设计初衷。
priority_queue:同样不暴露迭代器
priority_queue的设计目标是 "仅能访问优先级最高的堆顶元素",其底层依赖堆结构(完全二叉树):
-
- 若暴露迭代器,用户可能直接修改堆中任意元素,破坏堆的结构(堆的有序性依赖严格的父 / 子节点关系),导致
priority_queue的优先级规则失效;
- 若暴露迭代器,用户可能直接修改堆中任意元素,破坏堆的结构(堆的有序性依赖严格的父 / 子节点关系),导致
-
- 因此 STL 中
priority_queue也无迭代器接口,仅提供top()访问堆顶、push()/pop()调整堆结构。
- 因此 STL 中
三、priority_queue的模拟实现
3.1 向上调整建大堆
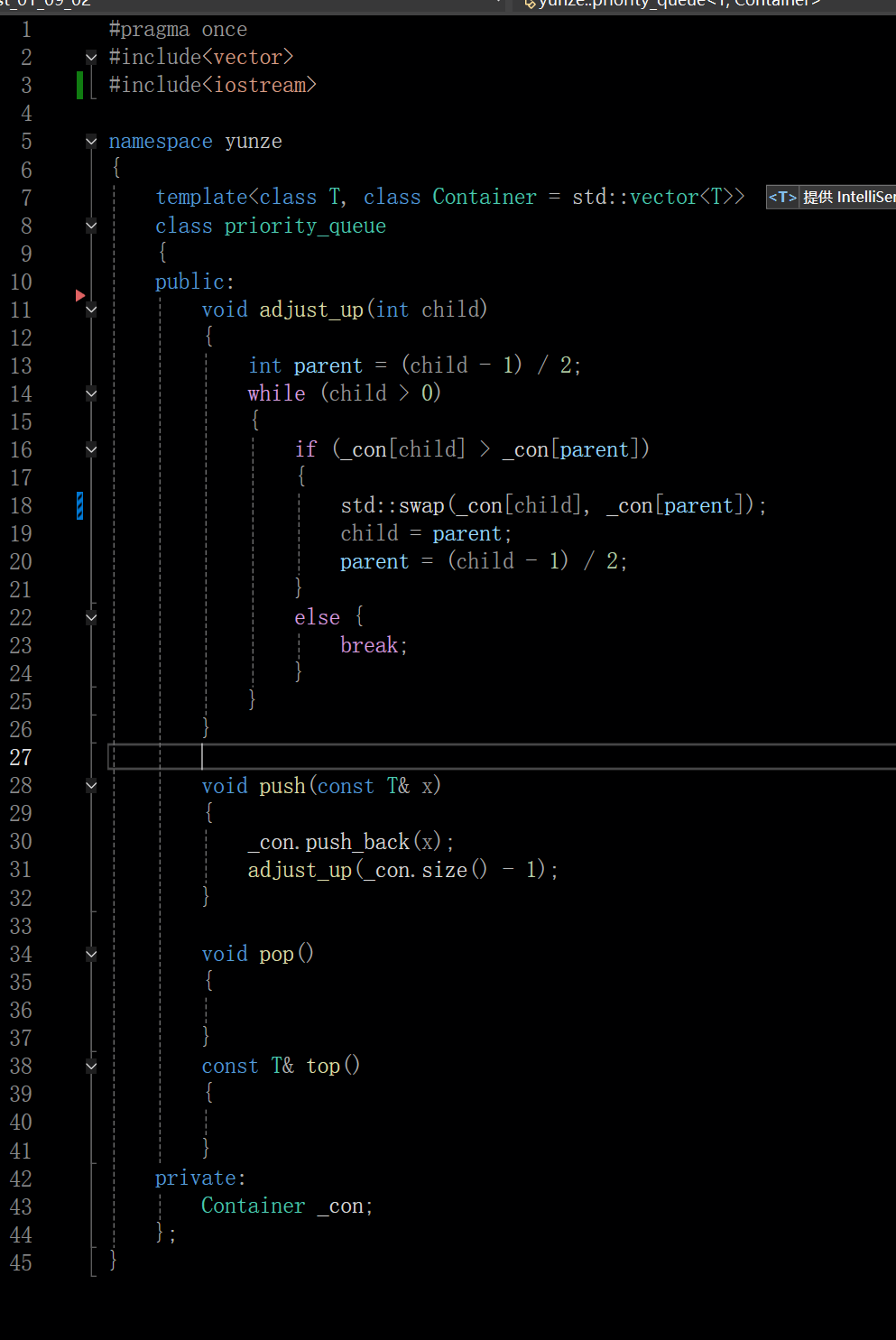
这里有的在用swap可能会遇到各种各样的问题,我结合我所遇到的问题把该过程的原因梳理一下:
在调试代码时我发现,在包含iostream和algorithm头文件的时候,使用swap只要不加st::就会报错,且无论包含iostream,algorithm,程序都可以使用std::swap,原因如下:
3.1.1 ADL(参数依赖查找)
一、 核心原因是 ADL(参数依赖查找)规则 + 内置类型的特性:
- 调用未指定命名空间的函数(如 swap(a,b))时,编译器先在「当前命名空间」(如上述代码的 yunze)和「全局命名空间」查找;
- 若未找到,会去「参数 a/b 的类型所属的命名空间」补充查找;
- 代码中 swap 的参数是 std::vector< int > 的元素(类型为 int),int 是内置类型,仅归属于全局命名空间,不属于 std 命名空间;
- 当写 swap(...) 时,编译器只会按以下顺序查找:
-
- 第一步:当前命名空间(yunze)------ 没有定义 swap;
-
- 第二步:全局命名空间 ------ 没有定义 swap;
-
- 第三步:参数类型所属的命名空间(仅全局)------ 仍无 swap;
即便 < iostream >/< algorithm > 让 std 命名空间中存在 std::swap,但 ADL 规则不会让编译器去 std 命名空间找 "未加前缀的 swap",因此必然报错。当参数是 std 命名空间下的类型(如 std::string、std::vector 对象),ADL 才会自动去 std 里找 swap,不用加 std::。
二、为什么包含 < iostream >/< algorithm >,用 std::swap 就可以?
核心原因是 这两个头文件都间接包含了 < utility >:
- std::swap 的官方定义在 < utility > 头文件中;
- 主流编译器(GCC/MSVC/Clang)的:
-
- < iostream >:内部依赖 < utility >(处理输入输出的字符串 / 缓冲区等),会间接包含它;
-
- < algorithm >:内部很多算法(如排序)需要用到 std::swap,也会间接包含 < utility >;
- 因此,只要包含这两个头文件之一,编译器就能找到 std 命名空间中 std::swap 的定义,调用 std::swap 自然编译通过。
添加 using namespace std; 后,调用 swap 时不用加 std:: 前缀也能编译通过,核心原因是这条语句的本质是将 std 命名空间的所有标识符 "导入" 到当前作用域,让编译器能直接找到 std::swap。
一、using namespace std; 的核心作用
using namespace std; 是 C++ 的命名空间使用指令,它的本质是:
告诉编译器:"在当前作用域中,查找未指定命名空间的标识符时,除了查找当前命名空间、全局命名空间,还要自动去 std 命名空间查找。"
简单说,这条语句相当于给 std 命名空间的所有内容(比如 swap、vector、cout 等)"去掉了 std:: 前缀",让你可以直接使用这些标识符。
二**、结合场景:加了 using namespace std; 后,swap 能被找到的全过程**
还是以 T=int 的代码为例,添加 using namespace std; 后,编译器查找 swap(_conchild, _conparent) 的步骤变成了:
- 第一步:查找当前命名空间(yunze)→ 没有 swap;
- 第二步:查找全局命名空间 → 没有 swap;
- 第三步:因为加了 using namespace std;,编译器额外查找 std 命名空间 → 找到 std::swap;
- 编译器确认 std::swap 匹配参数类型(int),调用成功,编译通过。
对比没加 using namespace std; 的情况:编译器只走前两步,找不到 swap 就报错;加了之后多了第三步,能找到 std::swap
3.2 pop() + 向下调整建大堆
删除数据要做向下调整,是不能在数组中直接挪动后面的数据来覆盖前面的数据。
原因有二:
- 对于vector这样的容器,向前挪动数据效率很低
- 且挪动数据之后,结构就全乱了,要重新建堆,而建堆的代价又是O(n)
所以最佳方式就是不要动大结构,收尾数据交换,只后再进行尾删,vector尾删的效率很高
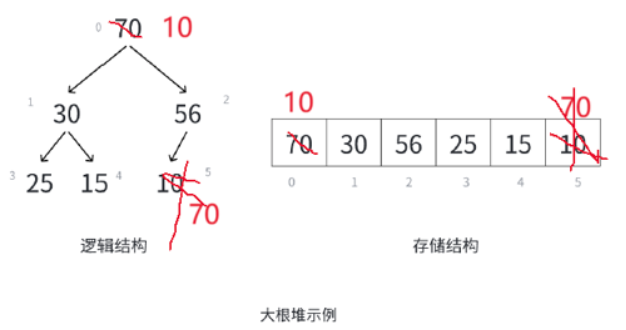
删除之后左右子树都是大堆,要进行向下调整
3.3 迭代器区间初始化 + 向下调整建大堆
迭代器区间初始化栈和队列没有支持,但是优先级队列支持了
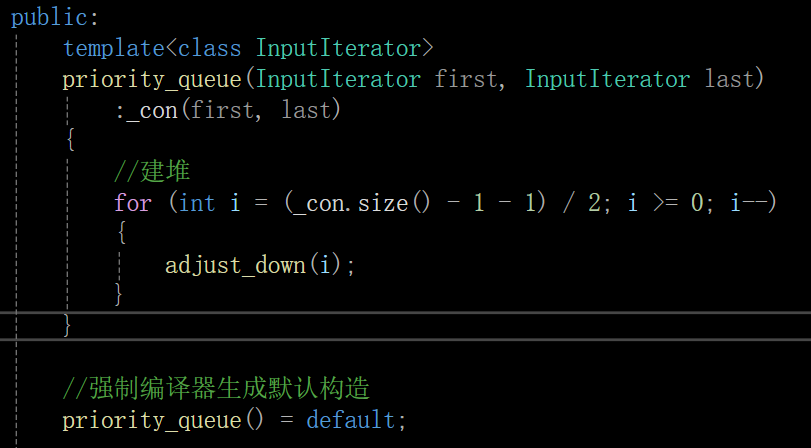
这里也可以遍历first和last之间的的值,直接调用push,但push就是向上调整和建堆了,我二叉树的文章深入理解二叉树与堆:结构、实现与典型应用有写过,向上调整建堆的效率是没有向下调整建堆高的,所以说这里不建议使用遍历调用push的方法,而是找到最后一个不是叶子的节点,从右向左,从下向上采用向下调整建大堆的方法
详细解释一下这里的代码:
InputIterator是一个遵循 C++ 标准库的命名习惯、用来表示 "输入迭代器 " 模板参数的名称,用它作为名字,是为了表明这个构造函数接收的参数是 "输入迭代器类型"(符合输入迭代器的行为要求,不一定是特定类型,只要某个类型满足迭代器的核心行为,就可以被当作迭代器使用)
cpp
"输入迭代器" 的要求:
支持 ++ 操作(单向移动,指向后一个元素);
支持 * 解引用(读取指向的元素,不能只写);
支持 != 比较(判断是否遍历到区间末尾);
支持拷贝构造 / 赋值(比如 It it = first;)由于这里指向数组元素地址的指针(比如 int*),刚好匹配迭代器行为,相当于一个容器迭代器
cpp
++p:指针移动到下一个元素(比如 int* 指针 ++,地址 + 4,指向数组中下一个 int);
*p:解引用指针,读取数组元素;
p != q:比较两个指针的地址,判断是否遍历到末尾;
指针本身就是基础类型,天然支持拷贝、赋值。容器迭代器的行为
cpp
容器迭代器是标准库专门设计的类型,天生就是为了满足迭代器行为:
++it:迭代器移动到下一个元素(底层由容器实现,比如 vector 迭代器本质是封装了指针,++ 就是指针移动);
*it:读取迭代器指向的元素;
it != end():判断是否遍历到末尾;
支持拷贝、赋值等基础操作。模板参数也是可以轻松 "兼容" 两种类型的 :
_con(first, last) 里,容器的区间构造函数会遍历 [first, last),而遍历只需要 ++、*、!= 这几个行为)。
所以:
- 传
vector::iterator:编译器推导InputIterator = vector::iterator,遍历用迭代器的++/*; - 传
int*:编译器推导InputIterator = int*,遍历用指针的++/*; - 两种情况都能正常执行
_con(first, last),因为容器的区间构造函数本身就支持 "任意满足输入迭代器行为的类型"。
补充一下:构造函数里的 _con(first, last) 是直接调用容器(比如 std::vector)的区间构造函数,容器会自动遍历 [first, last) 区间,把所有元素拷贝到 _con 中
cpp
priority_queue() = default;再说一下这行代码的作用:
一、这句代码的核心作用:显式要求编译器生成 "默认构造函数"
默认构造函数是指不需要传任何参数就能调用的构造函数 (比如 priority_queue< int > pq; 这种无参创建对象的方式,就会调用默认构造)。
C++ 的规则是:
- 如果你的中没有显式定义任何构造函数,编译器会自动生成一个默认构造函数(做一些基础初始化,比如前面_con 会被 std::vector 的默认构造初始化);
- 但如果类中显式定义了其他构造函数(比如代码里的 "迭代器区间构造函数"),编译器就不会再自动生成默认构造函数。
而 priority_queue() = default; 是 C++11 引入的语法,作用是:
显式告诉编译器:"我需要你帮我生成一个默认的无参构造函数",功能和编译器自动生成的默认构造完全一致(比如初始化 _con 为空的 std::vector)。
由于代码中已经显式定义了 "迭代器区间构造函数"(priority_queue(InputIterator first, InputIterator last)),所以编译器不会自动生成默认构造函数。
此时如果尝试无参创建 priority_queue 对象(比如 main 函数里注释掉的 yunze::priority_queue< int > pq;),编译器会报错。
完整的初始化流程(无参创建对象时)
- 调用
priority_queue的默认构造函数(由priority_queue() = default;让编译器生成); - 编译器生成的默认构造函数会执行「逐成员初始化」------ 对每个成员变量,调用其自身的默认构造函数;
- 成员变量 _con 是
std::vector< T >类型,因此会调用 std::vector 的无参构造函数,初始化一个空的 vector(size=0,底层无内存分配); - 最终 pq 成为一个空的优先级队列(pq.empty() 返回 true)。
如果手动写默认构造,效果完全一致
cpp
// 和 priority_queue() = default; 功能完全一致
priority_queue()
{
// 空函数体------编译器会自动在这里调用 _con 的无参构造
}之所以用 = default;,是因为它更简洁,且能让编译器生成 "更高效的默认构造函数"(和编译器自动生成的原生默认构造完全一致)。
3.4 size

四、完整源码
queue.h
cpp
#pragma once
#include<iostream>
#include<vector>
#include<list>
#include<deque>
using namespace std;
namespace yunze
{
template<class T, class Container = deque<T>>
class queue
{
public:
//队尾入数据
void push(const T& x)
{
//Container若不支持push_back就会报错,说明容器不适配
_con.push_back(x);
}
//队头出数据
void pop()
{
_con.pop_front();
}
//取队头数据
const T& front()
{
return _con.front();
}
//取队尾数据
const T& back()
{
return _con.back();
}
size_t size() const
{
return _con.size();
}
bool empty() const
{
return _con.empty();
}
private:
//vector<T> _v;
Container _con;
};
}stack.h
cpp
#pragma once
#include<iostream>
#include<vector>
#include<list>
#include<deque>
using namespace std;
namespace yunze
{
//template<class T>
//class stack //数组栈
//{
// // ...
//private:
// T* _a;
// size_t _top;
// size_t _capacity;
//};
template<class T, class Container = deque<T>>
class stack
{
public:
//构造析构拷贝不用写,没有其他需求,默认生成的够用
void push(const T& x)
{
//Container若不支持push_back就会报错,说明容器不适配
_con.push_back(x);
}
void pop()
{
_con.pop_back();
}
//top这里不用[],因为不一定是vector
const T& top()
{
//容器一般都有一个front和back接口,如vector和list
return _con.back();
}
size_t size() const
{
return _con.size();
}
bool empty() const
{
return _con.empty();
}
private:
//vector<T> _v;
Container _con;
};
}priority_queue.h
cpp
#pragma once
#include<vector>
#include<iostream>
using namespace std;
namespace yunze
{
template<class T, class Container = std::vector<T>>
class priority_queue
{
public:
template<class InputIterator>
priority_queue(InputIterator first, InputIterator last)
:_con(first, last)
{
//建堆
for (int i = (_con.size() - 1 - 1) / 2; i >= 0; i--)
{
adjust_down(i);
}
}
//强制编译器生成默认构造
priority_queue() = default;
void adjust_up(int child)
{
size_t parent = (child - 1) / 2;
while (child > 0)
{
if (_con[child] < _con[parent])
{
swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else {
break;
}
}
}
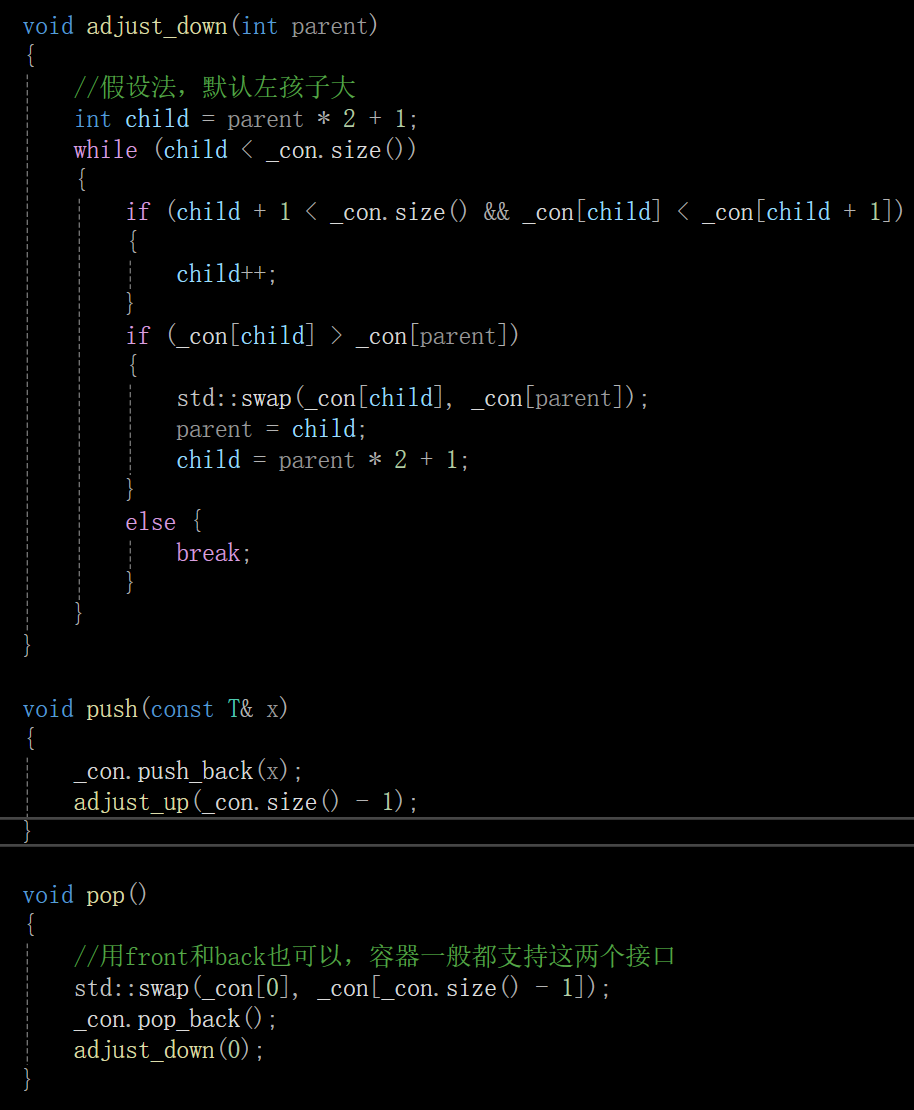
void adjust_down(int parent)
{
//假设法,默认左孩子大
size_t child = parent * 2 + 1;
while (child < _con.size())
{
if (child + 1 < _con.size() && _con[child] > _con[child + 1])
{
child++;
}
if (_con[child] < _con[parent])
{
swap(_con[child], _con[parent]);
parent = child;
child = parent * 2 + 1;
}
else {
break;
}
}
}
void push(const T& x)
{
_con.push_back(x);
adjust_up(_con.size() - 1);
}
void pop()
{
//用front和back也可以,容器一般都支持这两个接口
swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
adjust_down(0);
}
const T& top() const
{
return _con[0];
}
bool empty() const
{
return _con.empty();
}
size_t size() const
{
return _con.size();
}
private:
Container _con;
};
}test.cpp
cpp
#define _CRT_SECURE_NO_WARNINGS 666
//#include"stack.h"
//int main()
//{
// //yunze::stack<int, vector<int>> st;//数组栈
// //yunze::stack<int, list<int>> st;//数组栈
// yunze::stack<int> st;
// st.push(1);
// st.push(2);
// st.push(3);
// st.push(4);
//
// while (!st.empty())
// {
// cout << st.top() << " ";
// st.pop();
// }
// cout << endl;
// return 0;
//}
//#include"queue.h"
////默认也是用deque适配
//int main()
//{
// yunze::queue<int> q;
// //不能使用vector适配,vector不支持头删
// //yunze::queue<int, vector<int>> q;
//
// //队列只能使用list适配
// //yunze::queue<int, list<int>> q;
// q.push(1);
// q.push(2);
// q.push(3);
// q.push(4);
// while (!q.empty())
// {
// cout << q.front() << " ";
// q.pop();
// }
// cout << endl;
// return 0;
//}
//#include<deque>
//
//int main()
//{
// deque<int> dp;
// dp.push_back(1);
// dp.push_back(1);
// dp.push_back(1);
// dp.push_front(2);
// dp.push_front(3);
// dp.push_front(4);
// dp[0] += 10;
// for (auto e : dp)
// {
// cout << e << " ";
// }
// cout << endl;
// return 0;
//}
//#include<queue>
//#include<iostream>
//using namespace std;
//
////仿函数/函数对象 对象可以像函数一样使用
//template<class T>
//struct Less
//{
// bool operator() (const T& x, const T& y) const
// {
// return x < y;
// }
//};
//int main()
//{
// //默认使用的仿函数是less,大堆
// //priority_queue<int> pq;
// //小堆
// //priority_queue<int, vector<int>, greater<int>> pq;
// //也可以使用deuqe作容器适配器,deque支持下标访问
// priority_queue<int, deque<int>, greater<int>> pq;
// pq.push(3);
// pq.push(1);
// pq.push(5);
// pq.push(7);
// pq.push(2);
// while (!pq.empty())
// {
// cout << pq.top() << " ";
// pq.pop();
// }
// cout << endl;
//
// Less<int> less;
// cout << less(1, 2) << endl;
// //本质上被转换为调用operator()
// cout << less.operator()(1, 2) << endl;
// return 0;
//}
#include"priority_queue.h"
int main()
{
//yunze::priority_queue<int> pq;
int a[] = { 30, 4, 2, 66, 3 };
yunze::priority_queue<int> pq(a, a + 5);
pq.push(3);
pq.push(1);
pq.push(5);
pq.push(7);
pq.push(2);
while (!pq.empty())
{
cout << pq.top() << " ";
pq.pop();
}
cout << endl;
return 0;
}结语
