文章:WorldRFT: Latent World Model Planning with Reinforcement Fine-Tuning for Autonomous Driving
代码:https://github.com/pengxuanyang/WorldRFT
单位:中国科学院自动化研究所多模态人工智能系统国家重点实验室
一、问题背景:纯视觉自动驾驶的"三大痛点"
传统自动驾驶方案要么依赖昂贵的激光雷达,要么需要大量人工标注(比如手动框选车辆、行人),成本高且落地难。而近年来兴起的"潜态世界模型"方案,试图让AI从摄像头画面中自主学习场景信息,实现无标注驾驶,但仍存在三个关键短板:
-
3D空间感知弱:AI学出的场景偏"平面化",无法精准判断车辆与障碍物的真实距离和位置关系,规划路线时容易"摸不准";
-
规划逻辑太笼统:一次性生成完整路线,抓不住路口、临近车辆等局部关键信息,路线精度不足;
-
安全意识被动:仅模仿人类司机的行驶轨迹,不会主动避撞,遇到人类没经历过的突发场景就容易"手足无措"。
这些问题导致纯视觉方案的碰撞风险高、实用性不足,难以大规模落地。
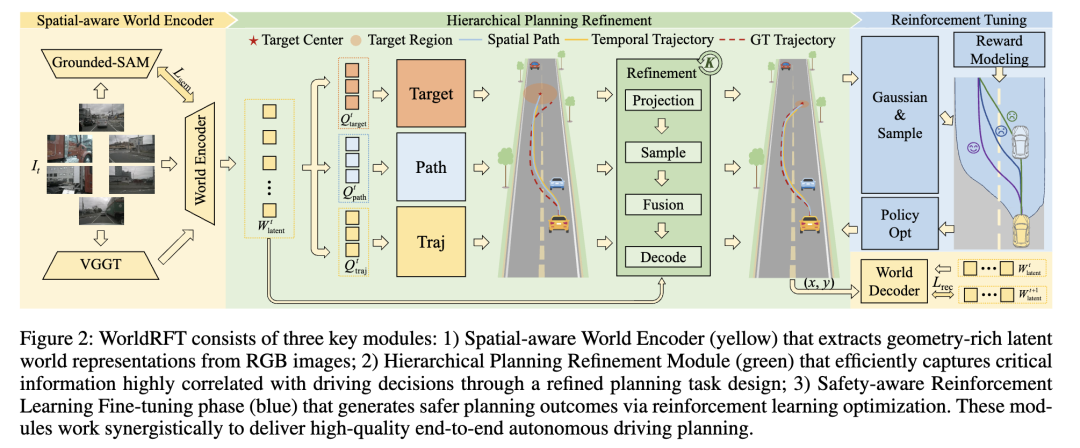
二、方法创新:三大核心设计,让AI"会看、会规划、会避撞"
WorldRFT针对痛点提出了三大创新模块,形成"场景理解→规划决策→安全优化"的完整闭环:
-
空间感知编码器(SWE):给AI装"3D眼睛" 融合视觉几何基础模型VGGT,从普通摄像头画面中提取精准的3D空间信息,不用激光雷达也能搞清楚"谁在哪个位置、离我多远",解决了纯视觉3D感知弱的问题。
-
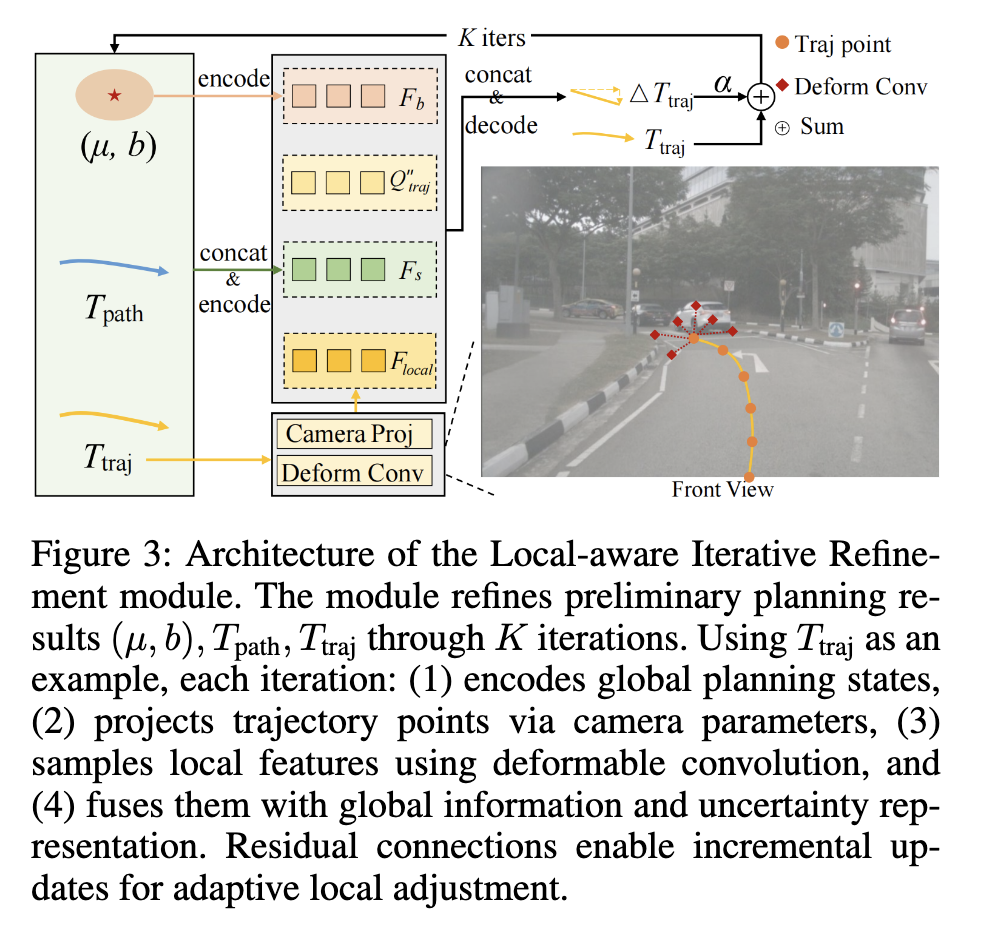
分层规划优化器(HPR):让规划"先抓大局、再抠细节" 不要求AI"一步到位"规划路线,而是拆成三个并行任务:先确定"大概能去的目标区域"(而非固定点,包容不确定性),再画"空间路径"(比如走中间车道),最后补"时间轨迹"(每个时间点该到哪)。同时通过迭代优化,结合路口、临近车辆等局部信息调整路线,兼顾全局合理和细节精准。
-
强化学习微调(RFT):培养"主动避撞意识" 设计碰撞惩罚机制------规划路线撞车就"扣分",倒逼AI重视安全;再通过"群体相对优化(GRPO)",让AI对比多条候选路线的安全性,选最优解。这让AI从"模仿人类"升级为"理解安全规则",实现主动避撞。
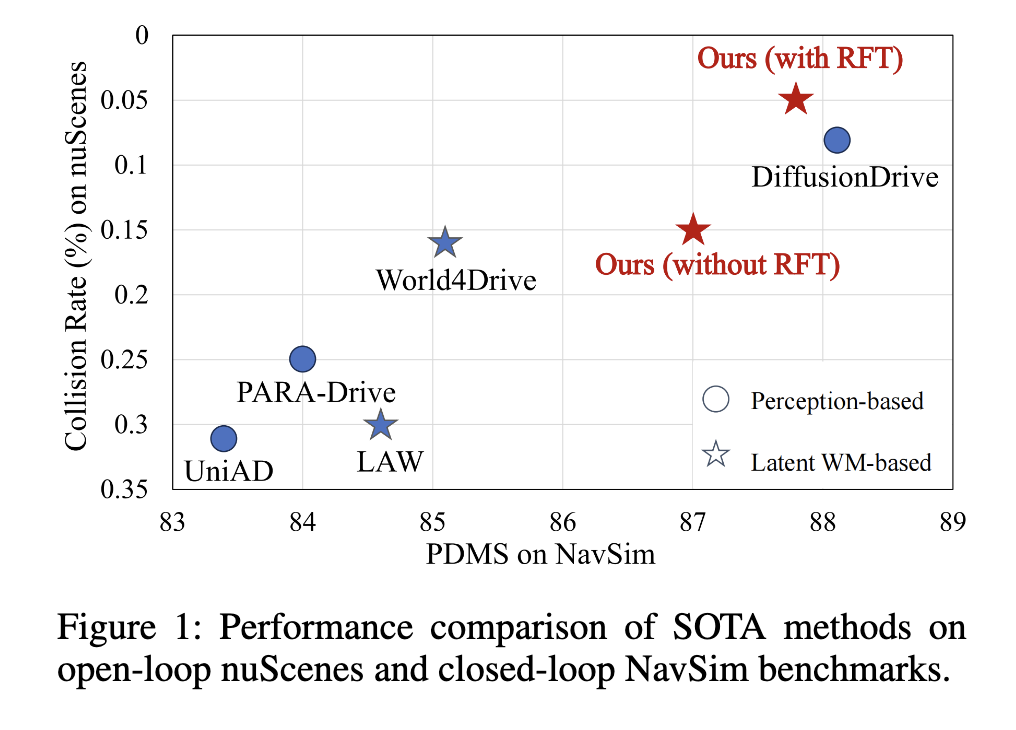
三、实验结果:数据说话,安全性和性能双突破
WorldRFT在两大权威 benchmark 上都取得了顶尖成绩,用数据证明了实力:
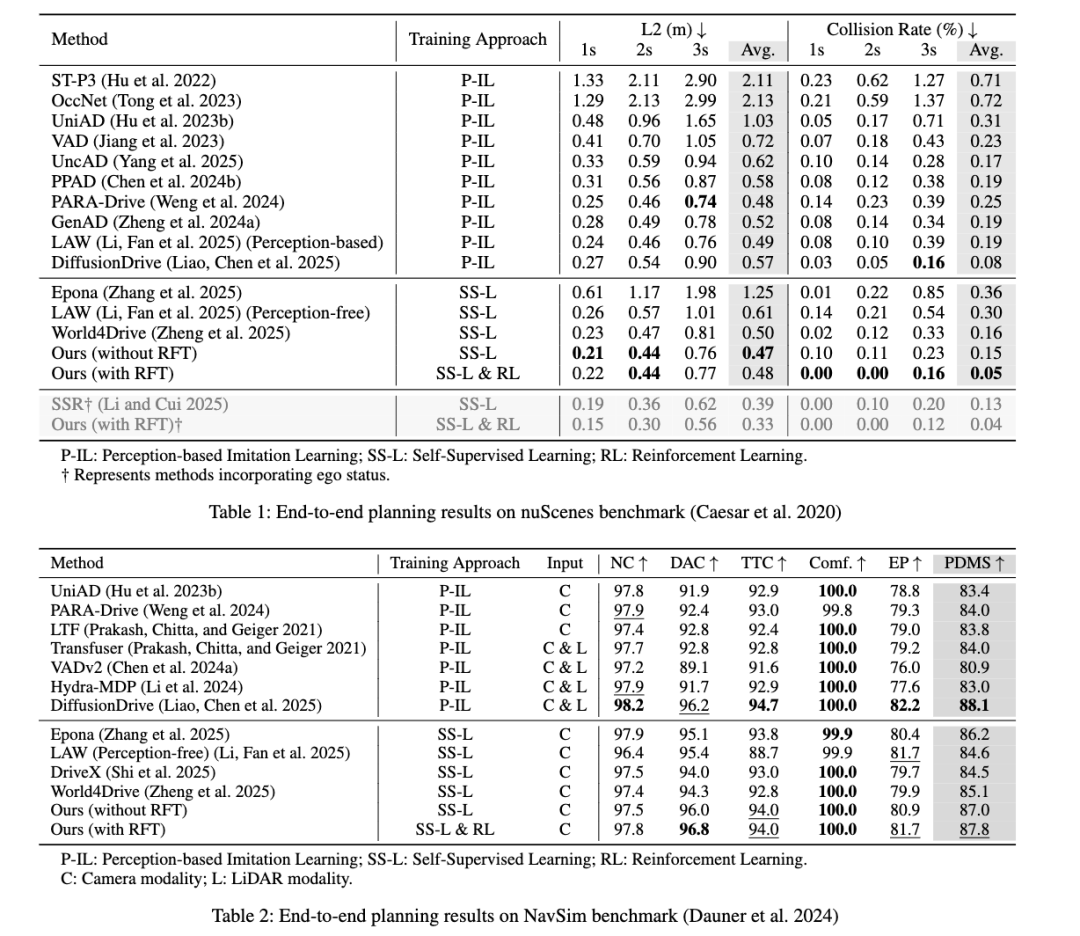
-
nuScenes(开放道路测试): 相比基线模型,碰撞率大幅降低83%(从0.30%降至0.05%),路线偏差减少21%(从0.61米缩至0.48米),成为所有无标注方案中碰撞率最低的模型,甚至超过了部分依赖人工标注的方案。
-
NavSim(封闭仿真测试): 仅用摄像头输入,综合性能得分(PDMS)达到87.8,接近依赖激光雷达的顶尖方案(88.1)。其中"车道合规性"得分96.8,是所有方案中最高的,说明模型能精准保持在车道内行驶,安全性拉满。
四、优势与局限:看清技术的当下与未来
核心优势
-
低成本易落地:无需激光雷达,也不用复杂人工标注,仅靠摄像头就能实现高安全驾驶,大幅降低研发和量产成本;
-
安全性突出:从被动模仿升级为主动避撞,碰撞率大幅降低,更符合真实道路的安全需求;
-
性能全面:兼顾路线精度、车道合规性、行驶舒适性,综合表现比肩激光雷达方案。
现存局限
-
对数据集标注准确性依赖较高,若数据中存在错误指令(比如左转标成直行),模型可能生成次优路线;
-
极端复杂场景(如恶劣天气、突发障碍物)的应对能力,还需更多真实数据验证;
-
强化学习微调阶段需要较多计算资源,对硬件有一定要求。
五、一句话总结
WorldRFT通过"3D感知+分层规划+安全强化学习"的创新组合,让纯视觉自动驾驶既不用昂贵设备、也不用复杂标注,还能实现主动避撞,为低成本、高安全的自动驾驶落地提供了全新可行路径。