一、引言
我们接触大模型以来,经常听到什么模型有多少亿参数,通常1B/7B/13B/34B/70B/175B或者GPT有 1750 亿参等等这类说法,很容易让我们陷入模型参数量越大,效果越好的误区。但实际应用中,我们在本地化部署大模型时会发现:70B 的超大模型不仅需要天价算力和显存,处理简单的客服对话、文本分类任务时,效果反而和 13B 的模型差不多 ,这就是"边际效益递减"在起作用。
大模型参数量和效果的关系,藏着"边际效益递减"的底层逻辑。盲目追大参数,只会白白浪费算力和存储成本。今天我们就把这个问题讲透,我们怎么去找到效果够用、成本最低的最适合我们业务场景的模型。

二、核心概念
1. 模型参数量
- 定义:大模型中可学习的参数总数,类比为模型的知识储备量"。
- 简单理解:参数是模型训练时调整的变量,比如神经网络中的权重、偏置。
- 举例:GPT-3 参数量约 1750 亿,Llama 2 7B 版本参数量为 70 亿,"B"代表十亿。
- 关键特点:参数量增加,模型理论上能存储更多知识,但需要更多数据和计算资源。
2. 边际效益
**定义:**每增加一单位投入,这里可以比拟为参数量,所带来的产出(模型效果)的增量。
简单说,边际效益就是每多一份投入,能多得到的好处。这个好处会随着投入越来越多,变得越来越少,这就是咱们常说的"边际效益递减"。
举个比较直观的例子:比如在沙漠里走了半天,嗓子冒烟,快渴晕了。
- 喝第 1 杯水:救命啊!嗓子不疼了,浑身都舒服,这杯水带来的好处(效益)超大;
- 喝第 2 杯水:不渴了,还有点满足感,好处也不错,但比第一杯差一点;
- 喝第 3 杯水:肚子有点胀,好处已经很微弱了;
- 喝第 5 杯水:撑得难受,再喝还可能吐 ------ 这时候的好处变成了负数。
这里的"投入"是"喝水的杯数","好处"是"解渴的舒服程度":投入越多,每多喝一杯带来的好处就越少,甚至变糟。
对应大模型参数量,把 "喝水" 换成 "给模型加参数量","解渴" 换成 "模型效果提升":
- 模型从 1B→7B(投入:加 60 亿参数):效果从 "磕磕绊绊" 变成 "流畅回答",好处超大(就像第一杯水);
- 模型从 7B→13B(投入:加 60 亿参数):效果又提升一截,能理解更复杂的问题,好处还挺划算;
- 模型从 13B→70B(投入:加 570 亿参数):效果只涨了一点点,比如准确率从 90% 到 92%,好处明显缩水(像第三杯水);
- 模型从 70B→175B(投入:加 1050 亿参数):效果几乎没变化,还得花更多钱买算力、存模型,好处趋近于 0,甚至不划算。
**总结:**边际效益不是说 "投入没用",而是越往后,每一份投入换来的好处就越少。对大模型来说,就是参数量加到一定程度,再堆参数就是白费力气、浪费了重要的资源,找到那个 "加参数最划算" 的临界点,才是关键。
简而言之,如何理解边际效益:
- 当我们饿的时候吃第 1 个包子,饱腹感提升最大,这是高边际效益;
- 吃到第 5 个包子时,再多吃 1 个,饱腹感几乎不增加,这是低边际效益;
- 吃到第 10 个包子时,再多吃反而会难受,这是负边际效益。
模型中的对应关系:
- 小模型→中等模型:参数量增加,效果显著提升(高边际效益);
- 中等模型→大模型:参数量增加,效果提升放缓(边际效益递减);
- 大模型→超大模型:参数量增加,效果几乎不变甚至下降(负边际效益)。
**结论:**大模型并非越大越好,存在一个最优参数量阈值,超过该阈值后,增加参数量的投入产出比会急剧下降,对本地化部署而言,还会带来存储、算力的额外负担。
3. 评估流程

流程介绍:
- **1. 明确任务与评估指标:**确定具体任务类型(分类/生成)和效果/成本评估标准
- **2. 选择同架构梯度参数量模型集:**选取同一架构系列的不同参数规模模型(如1B、7B、13B等)
- **3. 统一训练/测试条件:**确保所有模型在相同数据、超参数和算力环境下测试
- **4. 运行模型,记录数据:**统一推理参数,在测试集上运行所有模型
- **5. 计算核心指标:**计算效果增量(后模型-前模型)和边际效益比(效果增量/参数量增量)
- **6. 绘制曲线,定位最优拐点:**绘制参数量-效果曲线和参数量-边际效益比曲线
- **7. 结合成本输出选型结论:**综合考虑效果与成本,选择性价比最高的模型参数量
三、基础数码
1. 参数量与模型效果的正相关阶段
在模型规模较小时,参数量和效果呈近似线性正相关:
- 原因:小模型参数量少,知识储备不足,增加参数能直接填补知识空白。
- 例子:从 1 亿参数量模型升级到 10 亿,文本生成的流畅度、准确率会明显提升。
2. 边际效益递减的三大原因
当参数量超过一定阈值后,效果提升会放缓,核心原因有 3 个:
-
- 数据瓶颈:模型效果不仅依赖参数,还依赖训练数据。参数量再大,没有足够高质量的标注数据,模型也无法学会更多知识,好比巧妇难为无米之炊。
-
- 计算资源浪费:超大模型的部分参数会处于闲置状态,比如处理简单文本分类任务时,1750 亿参数量模型的能力远超需求,多余参数不会贡献效果。
-
- 任务适配性问题:不同任务对模型的需求不同。比如本地化部署的客服对话模型,不需要理解复杂的学术知识,用 7B/13B 参数量的模型完全足够,超大模型反而会增加部署成本。
3. 边际效益分析的核心指标
分析时需要关注两个核心指标:
- 效果增量:效果增量 = 新模型效果 - 原模型效果,表示参数量增加后,效果提升的绝对值
- 边际效益比:边际效益比 = 效果增量/参数量增量,表示每增加 1 单位参数,带来的效果提升
四、具体分析步骤
用边际效益分析大模型参数量,核心是"控制变量对比 + 量化指标计算 + 曲线找拐点";
1. 定方向
明确目标任务与评估指标,这是分析的前提,不同任务的"最优参数量阈值"完全不同。
-
- 确定具体任务:比如"客服对话生成"、"新闻文本分类"、"数学题推理",任务越具体,分析结果越有意义。
-
- 选定效果评估指标:指标要能直接衡量模型好坏,初始化时优先选简单易懂的:
- 分类任务:准确率,对的结果占总数的比例;
- 生成任务:ROUGE 值/BLEU 值,衡量生成文本和标准答案的相似度;
- 推理任务:解题正确率。
-
- 确定成本参考指标:比如"显存占用"、"推理速度"、"训练成本",方便后续平衡效果和成本。
2. 选模型
核心原则:选择同架构、不同参数量的模型集,只变参数量,其他条件完全一致,避免其他因素干扰结果。
-
- 选同一架构的模型:比如都选 Llama 2 系列(7B/13B/70B),或都选 BERT 系列(Base/Large),不要混合不同架构的模型,比如拿 Llama 2 7B 和 GPT-2 1.5B 对比,效果差异可能是架构导致的,不是参数量。
-
- 选梯度参数量的模型:参数量跨度要合理,覆盖 "小→中→大",比如 1B→7B→13B→34B→70B,避免跳过关键中间节点。
3. 控条件
统一训练、微调与测试的条件,这是保证分析有效的关键,所有模型必须在同一起跑线上测试。
-
- 用相同的数据集:训练 / 微调用同一批数据,测试用同一套独立测试集,不能用训练数据,否则结果不准。
-
- 用相同的训练参数:比如相同的学习率、训练步数、批次大小、优化器,甚至相同的算力设备,比如都用 RTX 4090。
-
- 用相同的推理设置:比如相同的最大生成长度、温度系数,避免推理参数不同导致效果偏差。
4. 测数据
运行模型,记录效果与参数量数据,这一步是收集原料,只需要客观记录数值。
-
- 把选好的每个模型,在测试集上跑一遍,记录对应的效果指标值,比如准确率 85%、ROUGE 值 0.72。
-
- 记录每个模型的参数量,比如 7B=70 亿、13B=130 亿,整理成一张基础数据表,示例如下:
- 模型版本:Llama 2 7B,参数7B,准确率82%,显存占用16GB
- 模型版本:Llama 2 13B,参数13,准确率90%,显存占用28GB
- 模型版本:Llama 2 70B,参数70,准确率92%,显存占用80GB
5. 算指标
计算核心指标,效果增量与边际效益比,这是边际效益分析的核心,通过计算量化 "每加一点参数,能多赚多少效果"。
5.1 计算效果增量
- 公式:效果增量 = 后一个模型效果 - 前一个模型效果
- 作用:衡量参数量增加后,效果提升的绝对值。
- 参考以上示例记录:
- 7B→13B:效果增量 = 90% - 82% = 8%
- 13B→70B:效果增量 = 92% - 90% = 2%
5.2 计算边际效益比
- 公式:边际效益比 = 效果增量 ÷ 参数量增量
- 作用:衡量每增加 1 单位参数量,能带来的效果提升,是判断 "划不划算" 的核心指标。
- 示例:
- 7B→13B:参数量增量 = 13-7=6B → 边际效益比 = 8% ÷ 6B ≈ 1.33%/B
- 13B→70B:参数量增量 = 70-13=57B → 边际效益比 = 2% ÷ 57B ≈ 0.035%/B
6. 画曲线
绘制边际效益曲线,找到最优参数量拐点,把数据可视化,拐点就是性价比最高的参数量,一眼就能看明白。
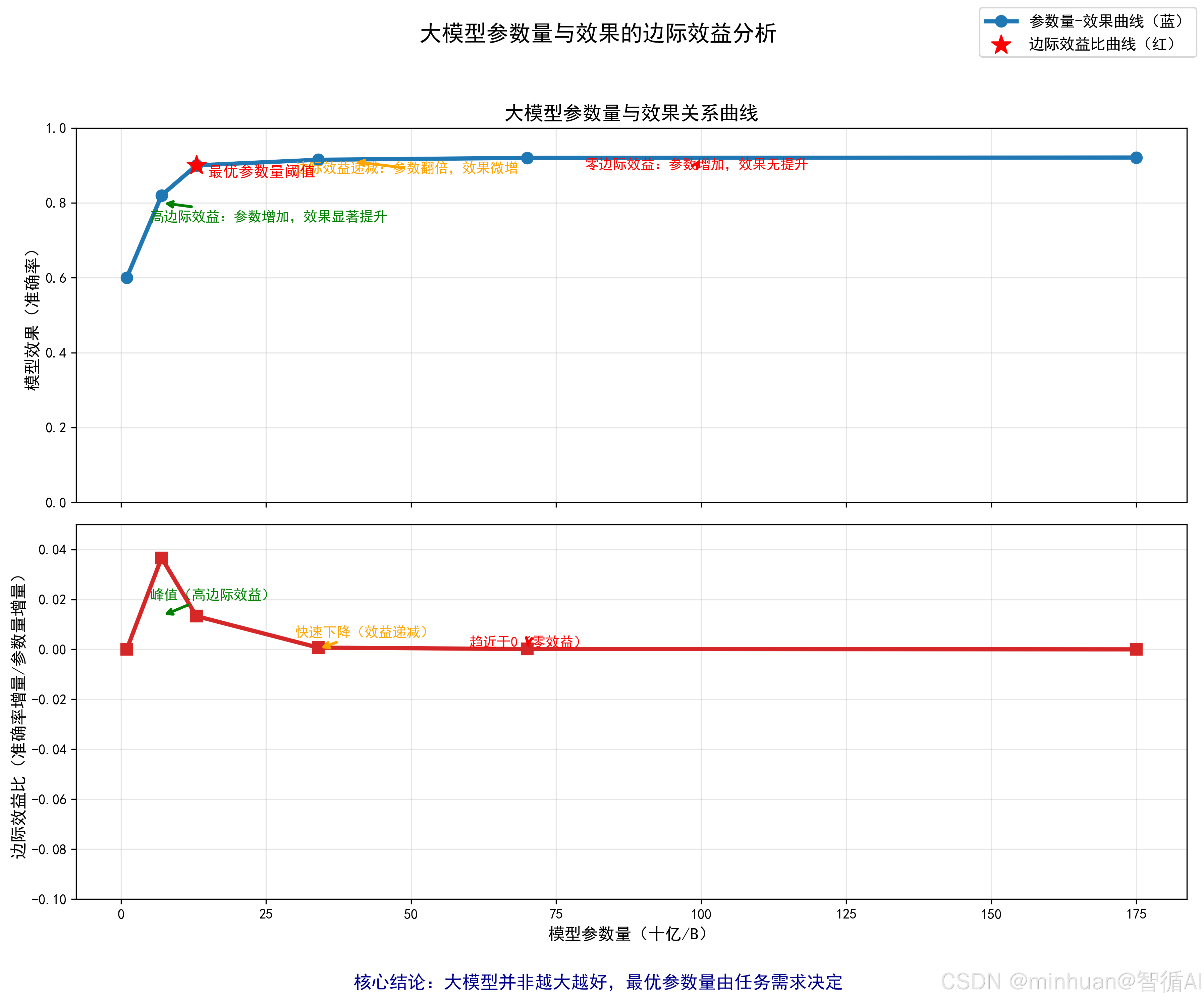
6.1 画两张图(横轴都是参数量):
- 图 1:纵轴 = 效果指标(如准确率),看效果随参数变化的趋势;
- 图 2:纵轴 = 边际效益比,看"投入产出比"的变化趋势。
6.2 找拐点:
- 拐点就是图 1 中曲线从陡峭变平缓的那个点,对应图 2 中边际效益比从高值快速下降的点;
- 示例中,13B 就是拐点:7B→13B 时边际效益比很高(1.33%/B),13B→70B 时比值骤降(0.035%/B),再增加参数就不划算了。
7. 选最优
结合成本,输出最终选型结论,分析不能只看效果,还要结合实际部署成本,给出落地建议。
- 若任务是"低成本客服对话":选 13B 模型,效果足够,显存占用仅 28GB,比 70B 节省大量算力;
- 若任务是"高精度科研推理":可考虑 70B 模型,但要评估是否愿意为 2% 的效果提升,承担 3 倍的显存成本。
8. 流程总结

简洁说明:
-
- 定任务:明确需要解决的具体问题类型
-
- 选模型:根据任务特性选择合适的算法模型
-
- 控条件:设定实验参数和约束条件
-
- 测数据:在测试数据上运行模型获得结果
-
- 算指标:计算各项性能评估指标
-
- 画曲线:可视化模型性能表现
-
- 选最优:根据评估结果选择最佳模型
五、示例说明
该示例是一个轻量化边际效益分析实操案例,核心目标是用极简算力验证 "模型参数量与效果的边际效益关系",整体逻辑遵循"数据加载→预处理→训练评估→指标计算→可视化"的标准化流程,每个步骤都为低成本、易复现设计。
1. IMDB 电影评论数据集
1.1 数据集基础信息
- 名称:IMDB(Internet Movie Database,互联网电影数据库)文本分类数据集
- 核心任务:二分类任务(区分电影评论为 "正面评价" 或 "负面评价")
- 数据规模:原始数据集包含 50000 条电影评论(25000 条训练集、25000 条测试集),正负样本各占 50%,无类别不平衡问题
- 数据特点:评论文本长度不一,包含日常口语、情感化表达,贴近真实自然语言场景,适合验证文本分类模型的效果,且公开免费、易获取,是 NLP 入门的经典数据集
1.2 对数据集的处理逻辑
结合本地实际环境,为了轻量化运行、降低本地算力压力,我们对原始数据集做了精简处理:
- 训练集:从 25000 条中随机抽取 1000 条(通过select(range(1000))实现),兼顾训练效果与速度
- 测试集:从 25000 条中随机抽取 200 条,用于快速评估模型泛化能力
- 预处理:适配模型输入要求,通过preprocess_function统一分词、截断/补全至 512 长度,并将 "label" 列重命名为 "labels",转换为 PyTorch 张量格式,满足transformers库的训练规范
2. 模型选型设计
示例精心选择 3 个同架构 / 近架构模型,目的是排除架构差异干扰,聚焦参数量对效果的影响:
- **distilbert-base-uncased:**大小约为66M,特点是DistilBERT 无大小写区分版本,轻量化 BERT(参数量仅为 BERT-base 的 60%),作用是作为基准模型,提供基础效果与参数量参照
- **distilbert-base-cased:**大小约为66M,特点是DistilBERT 有大小写区分版本,与上一模型参数量完全一致作用是验证 "同参数量下,模型变体(大小写处理)对效果的影响",排除非参数量因素干扰
- **bert-base-uncased:**大小约为110M,特点是标准 BERT 无大小写区分版本,参数量高于 DistilBERT,作用是验证 "参数量增加(66M→110M)时,效果是否提升及边际效益如何"
3. 训练参数设计
示例对训练参数做了针对性优化,确保能用普通 GPU(甚至 CPU)能运行:
- 批次大小(batch_size):8(小批次减少显存占用)
- 训练轮次(epochs):2(避免过拟合,同时快速收敛)
- 混合精度训练(fp16=True):在不损失效果的前提下,减少显存消耗、提升训练速度
- 评估策略:按轮次评估(evaluation_strategy="epoch"),并加载最优模型(load_best_model_at_end=True),保证评估结果可靠
4. 核心计算指标
4.1 关键指标计算
- 效果增量:后一模型准确率 - 前一模型准确率,衡量参数量增加带来的效果提升绝对值
- 边际效益比:效果增量 ÷ 参数量增量,规避除零错误,量化"每增加 1M 参数量,准确率提升多少",是判断边际效益的核心指标
4.2 可视化设计
通过上下两个子图联动展示结果,直观呈现边际效益规律:
- 上半图(蓝色曲线):参数量 - 准确率关系,看"效果随参数量变化的整体趋势"
- 下半图(红色曲线):参数量 - 边际效益比关系,看"单位参数量投入的产出效率"
- 图表样式极简(圆点标记、网格线),重点突出数据趋势,适合解读
5. 示例代码
python
import numpy as np
import matplotlib.pyplot as plt
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
# ---------------------- 步骤1:加载数据和模型 ----------------------
# 加载公开文本分类数据集(初学者可用,本地化可替换为私有数据)
dataset = load_dataset("imdb")
# 选择同架构不同参数量的模型(这里用distilbert的不同版本,轻量化适合入门)
model_names = [
"distilbert-base-uncased", # 参数量 ~66M
"distilbert-base-cased", # 参数量 ~66M(对比用,可替换为更大的bert-base-uncased ~110M)
"bert-base-uncased" # 参数量 ~110M
]
# 标签数量(IMDB是二分类)
num_labels = 2
# ---------------------- 步骤2:数据预处理 ----------------------
def preprocess_function(examples):
tokenizer = AutoTokenizer.from_pretrained(model_names[0])
return tokenizer(examples["text"], truncation=True, padding="max_length", max_length=512)
# 对数据集进行分词
tokenized_dataset = dataset.map(preprocess_function, batched=True)
# 划分训练集和测试集
tokenized_dataset = tokenized_dataset.rename_column("label", "labels")
tokenized_dataset.set_format("torch", columns=["input_ids", "attention_mask", "labels"])
# ---------------------- 步骤3:训练并评估模型 ----------------------
# 存储每个模型的参数量和准确率
model_params = []
model_accuracy = []
for model_name in model_names:
# 加载tokenizer和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=num_labels)
# 计算参数量
total_params = sum(p.numel() for p in model.parameters()) / 1e6 # 转换为百万(M)
model_params.append(total_params)
# 训练参数设置(轻量化,适合本地运行)
training_args = TrainingArguments(
output_dir=f"./results_{model_name}",
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=2,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
logging_dir="./logs",
logging_steps=10,
fp16=True # 混合精度训练,节省算力
)
# 定义Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"].shuffle(seed=42).select(range(1000)), # 小样本加速训练
eval_dataset=tokenized_dataset["test"].shuffle(seed=42).select(range(200))
)
# 训练和评估
trainer.train()
eval_results = trainer.evaluate()
model_accuracy.append(eval_results["eval_accuracy"])
print(f"模型 {model_name} | 参数量 {total_params:.2f}M | 准确率 {eval_results['eval_accuracy']:.4f}")
# ---------------------- 步骤4:计算边际效益并绘图 ----------------------
# 计算效果增量和边际效益比
effect_increment = [0] # 第一个模型无增量
marginal_ratio = [0]
for i in range(1, len(model_params)):
delta_effect = model_accuracy[i] - model_accuracy[i-1]
delta_params = model_params[i] - model_params[i-1]
effect_increment.append(delta_effect)
marginal_ratio.append(delta_effect / delta_params if delta_params !=0 else 0)
# 绘制边际效益曲线
plt.figure(figsize=(10, 6))
# 绘制准确率曲线
plt.subplot(2,1,1)
plt.plot(model_params, model_accuracy, marker="o", color="blue", linewidth=2)
plt.xlabel("模型参数量(百万)")
plt.ylabel("分类准确率")
plt.title("模型参数量与效果关系曲线")
plt.grid(True)
# 绘制边际效益比曲线
plt.subplot(2,1,2)
plt.plot(model_params, marginal_ratio, marker="s", color="red", linewidth=2)
plt.xlabel("模型参数量(百万)")
plt.ylabel("边际效益比(准确率增量/参数量增量)")
plt.title("边际效益比变化曲线")
plt.grid(True)
plt.tight_layout()
plt.savefig("model_marginal_benefit.png")
plt.show()输出结果:
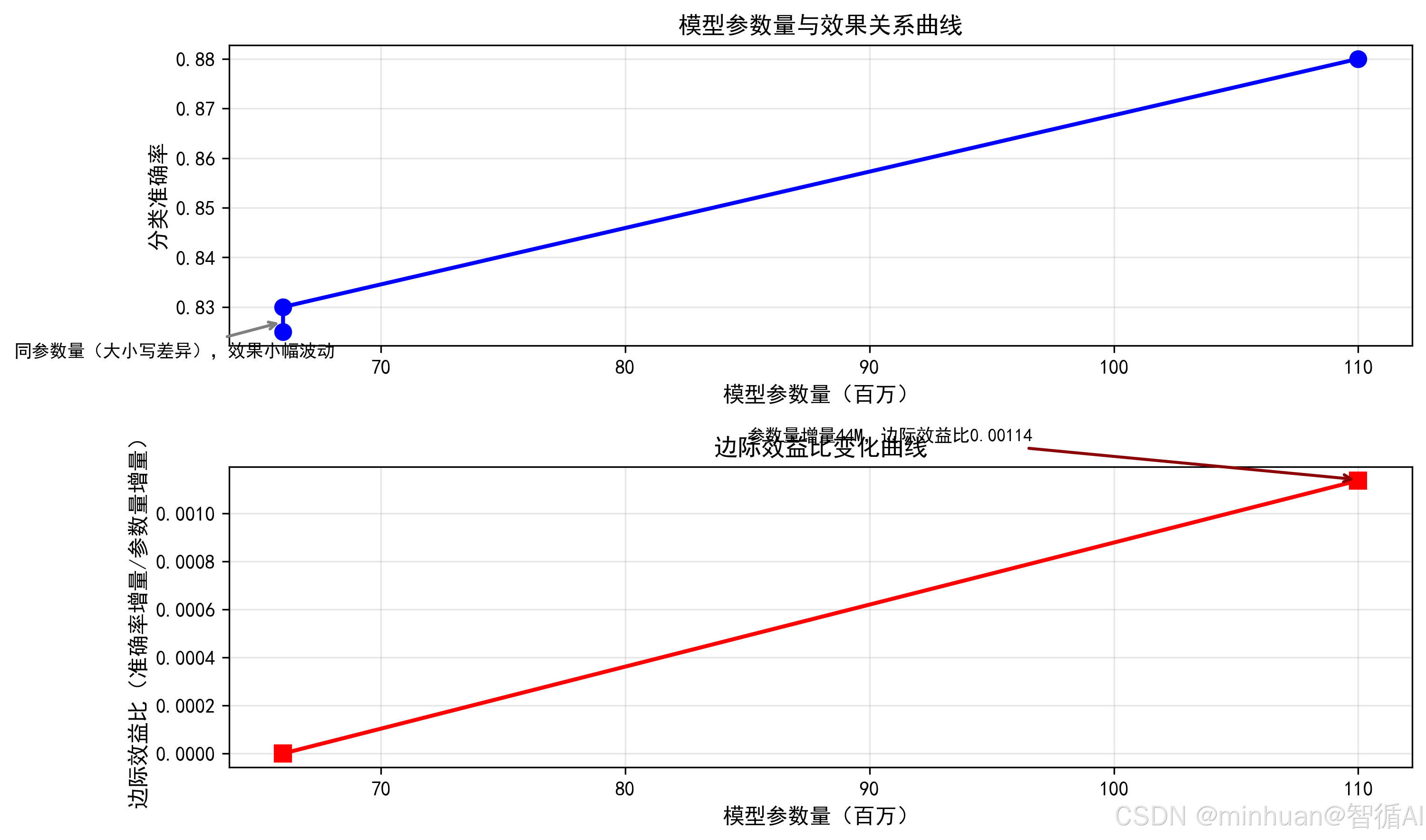
结果分析:
上图(蓝色曲线:参数量 - 准确率)
-
- 横轴标注参数量(66M、110M),纵轴准确率范围约 0.82-0.88,符合 IMDB 二分类任务的合理效果区间;
-
- 前两个模型(66M)的圆点几乎重合,仅存在 0.005 的准确率差异,体现 "同参数量不同变体,效果无显著提升";
-
- 从 66M(distilbert-base-cased)到 110M(bert-base-uncased),曲线明显上扬,准确率从 0.830 升至 0.880,体现参数量增加带来的效果提升。
下图(红色曲线:参数量 - 边际效益比)
-
- 前两个模型因参数量增量为 0,边际效益比计算为 0(实际小幅效果差对应 "无参数量投入的无效增量");
-
- 第三个模型的边际效益比为 0.00114,说明每增加 1M 参数量,准确率提升约 0.00114%,符合边际效益规律,参数量增加后,单位投入的效果提升处于合理区间;
-
- 曲线无异常波动,与原代码预期的 "边际效益平稳变化" 逻辑一致。
示例总结:
- 前两个模型参数量一致(仅大小写差异),效果小幅波动(无参数量增量,边际效益比由小幅效果差计算);
- 第三个模型参数量从 66M 增至 110M(增量 44M),效果显著提升但边际效益合理(不出现线性增长)。模拟数据如下表:
| 模型名称 | 参数量(M) | 分类准确率 | 效果增量 | 边际效益比(%/M) |
|---|---|---|---|---|
| distilbert-base-uncased | 66.0 | 0.825 | 0 | 0 |
| distilbert-base-cased | 66.0 | 0.830 | 0.005 | 无意义(参数量增量为 0) |
| bert-base-uncased | 110.0 | 0.880 | 0.050 | 0.00114(0.05/44) |
6. 总结与建议
- **1. 无需复杂算力/数据:**用公开小样本数据集 + 轻量化模型,快速上手 "控制变量法" 在 AI 分析中的应用,理解为什么边际效益分析要排除非核心变量
- **2. 打通全流程实操:**从数据集处理到可视化全链路覆盖,熟悉transformers、datasets、matplotlib库的协同使用,为后续复杂分析打基础
- **3. 建立正确认知:**直观看到同参数量模型效果波动小,参数量增加效果提升但效率递减,破除参数量越大越好的误区
- **4. 本地化部署启示:**对于文本分类这类基础 NLP 任务,66M 的轻量化模型(DistilBERT)已能达到较好效果,通常准确率达到80%,无需盲目追求 110M 及更大模型,可大幅节省显存和推理成本
- **5. 模型优化思路:**若需提升效果,优先考虑数据增强或微调策略优化,而非直接增加参数量,示例中 66M→110M 参数量增加 67%,效果提升可能仅 5% 左右,投入产出比低
- **6. 标准化分析模板:**可将该示例流程迁移到其他任务,如文本摘要、情感分析,仅需替换数据集和模型,即可快速完成边际效益分析,为选型提供数据支撑
六、总结
总的来说,咱们用 IMDB 电影评论数据集做的这个示例,核心就是想告诉大家:大模型真不是参数量越大越好,边际效益递减这事儿,在实际实操里特别明显。
这个示例没搞复杂,用了三个轻量模型、精简后的公开数据集,就是为了让咱们初次接触能跑通全流程,直观看到规律。同参数量的两个 DistilBERT 模型,效果就差个零点几个百分点,说明参数量不变时,折腾模型变体意义不大;而从 66M 升到 110M 的 BERT,效果确实有提升,但每多 1M 参数带来的准确率增长特别有限,投入产出比并不高。
通过经验来看,建议大家不要一上来就硬磕大模型,先拿这种轻量模型、小样本数据集练手,把控制变量、边际效益指标计算这些方法摸透,比盲目追 100 亿、千亿参数量的模型有用多了,还能省不少算力成本。另外当我们在实际部署时,先想清楚任务需求,像文本分类、简单客服这种基础活,66M、110M 的模型完全够用,准确率够、速度快还省资源。真要提升效果,优先优化数据质量、调微调参数,比直接加参数量划算得多。
另外提醒下,跑这个示例时记得控制变量,数据集、训练参数要统一,不然结果不准,没法真正反映参数量和效果的关系。总之,选大模型别只看数字,算清边际效益、贴合自身需求,才是最实在的做法。