如何将NotebookLM PDF版PPT转为可编辑版本PPT
NotebookLM 的输出为不可编辑的PDF格式,本文致力于将其变为可编辑ppt格式。但由于转换过程基于OCR,生成PPT时最好要求白色背景 ,且输出仅能保留每页PPT的内容,会损失其格式,只能保留每页PPT上的文字和图表 。因此,该文,更加适用于采用NotebookLM 生成多份PPT,选择需要的内容再手动排版。如果希望能完整输出一模一样的可编辑PPT, 请忽略该文。
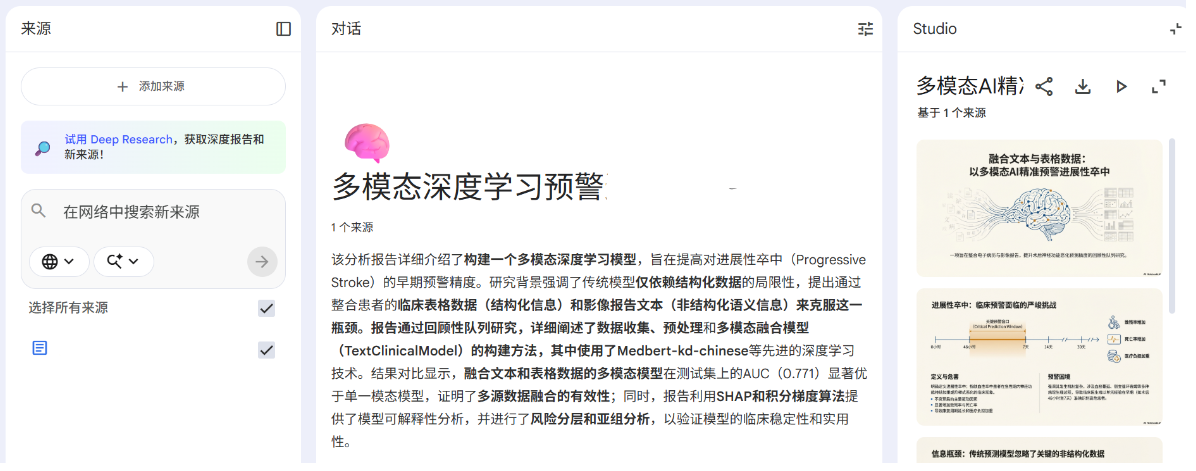
Step1:NotebookLM生产所需内容的ppt
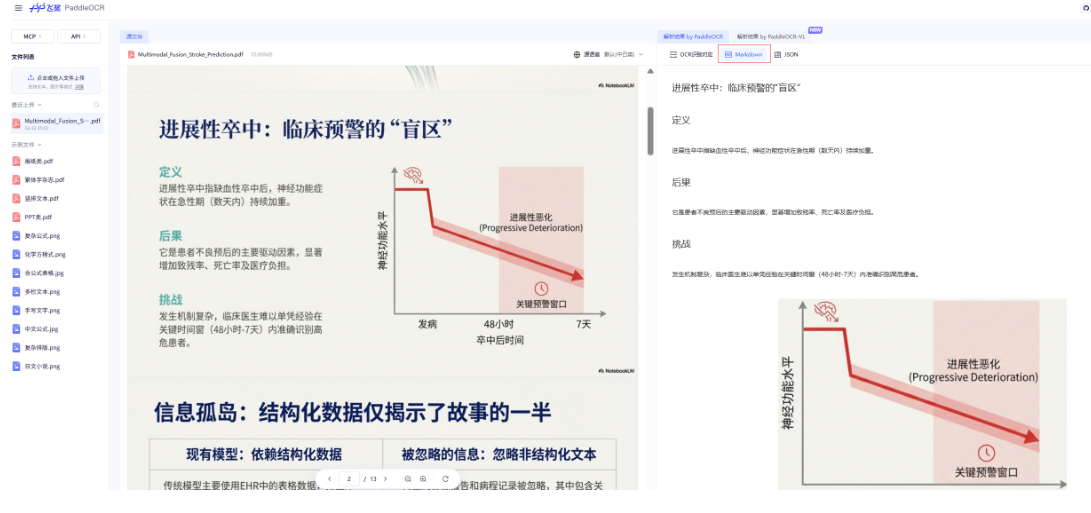
Step2:paddleocr在线将ppt转为md
网址:https://aistudio.baidu.com/paddleocr/task导出识别结果为markdown。
注:https://github.com/hiroi-sora/Umi-OCR是paddleocr的本地包装。
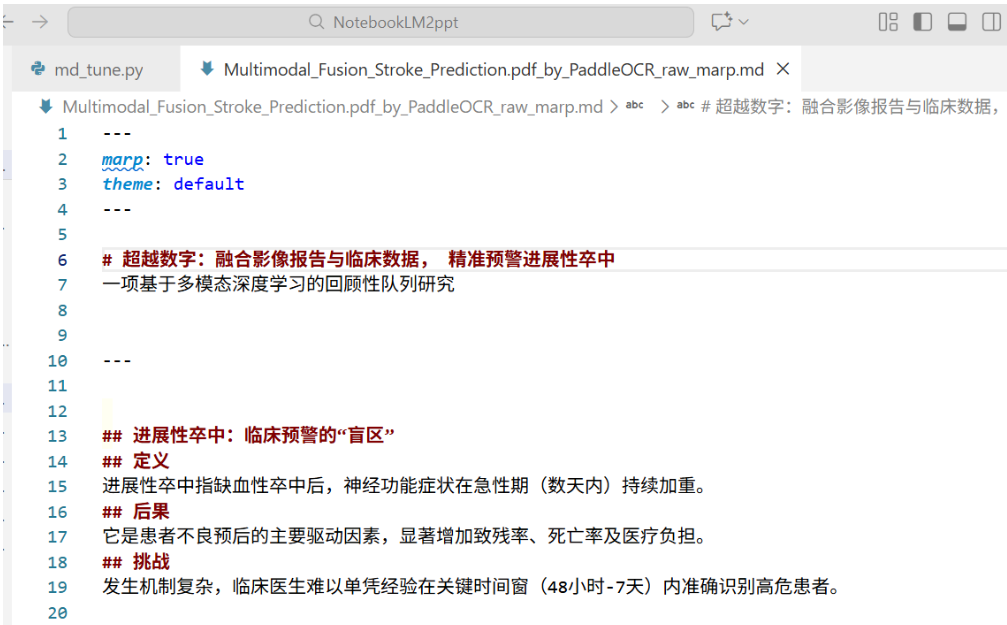
Step3:Vscode Marp插件+LibreOffice 25.8转为可编辑PPT
(1)下述代码将md转为Marp插件PPT模式
python
import os
def process_marp_markdown(input_file, output_file=None):
"""
处理 Markdown 文件:添加 Marp 头部,并将 'NotebookLM' 替换为分页符
"""
# 1. 定义要插入的 Marp 头部信息
marp_header = """---
marp: true
theme: default
---
"""
# 如果没有指定输出文件名,默认在原文件名后加 _marp
if output_file is None:
filename, ext = os.path.splitext(input_file)
output_file = f"{filename}_marp{ext}"
try:
# 2. 读取原始 MD 文件
with open(input_file, 'r', encoding='utf-8') as f:
content = f.read()
# 3. 核心逻辑:替换关键词为分页符
# 注意:我们在 --- 前后都加了 \n\n,确保 Markdown 语法正确识别为分页
processed_content = content.replace("NotebookLM", "\n\n---\n\n")
# 4. 拼接头部 + 处理后的内容,并写入新文件
final_content = marp_header + processed_content
with open(output_file, 'w', encoding='utf-8') as f:
f.write(final_content)
print(f"✅ 处理成功!")
print(f"📂 输入文件: {input_file}")
print(f"📄 输出文件: {output_file}")
except FileNotFoundError:
print(f"❌ 错误: 找不到文件 '{input_file}',请检查路径。")
except Exception as e:
print(f"❌ 发生未知错误: {e}")
if __name__ == "__main__":
INPUT_FILE = "Multimodal_Fusion_Stroke_Prediction.pdf_by_PaddleOCR_raw.md"
process_marp_markdown(INPUT_FILE)(2)导出为可编辑PPT输出
前置环境:LibreOffice 25.8安装 https://blog.csdn.net/xc_zhou/article/details/137695479
导出为可编辑PPT输出