上周四早上刚坐下,还没来得及摸鱼,产品就紧急拉了个会,说为了搞流量,咱们官网得做 SEO 优化。 然后直接甩了一份市场部出的 SEO 规范文档到群里:
这文档里的要求:每个页面要有独立标题、关键词,内容得是源码里能看见的... 最好这周就上线。"
这官网是前同事写的项目,一个标准的 Vue 3 + Vite 单页应用 (SPA) 。代码倒是写得挺优雅,但 SEO 简直就是裸奔。
做前端的都懂,SPA (单页面应用)这玩意儿,右键查看源代码,除了
index.html里万年不变的那套 TDK (标题、描述、关键词)外,就剩一个空的<div id="app"></div>。在爬虫眼里,不管哪个页面,看到的永远是同一个壳子,根本抓不到具体的业务内容。
面临的三大难题
-
时间太紧:市场部那边活动等着发,顶多给1天时间。
-
改动不敢太大:这项目跑得好好的,要是为了 SEO 重构把功能搞挂了,锅背不动。
-
数据其实挺死板 :目前这官网,大部分都是产品介绍、文档这种静态内容,接口请求回来的数据几个月都不一定变一次。
选型 为什么我不上 Nuxt?
-
迁移成本太高:把一个写好的 SPA 搬到 Nuxt,路由要改、Pinia 要改、API 请求要改,生命周期还得捋一遍。给我 1 天时间?搞不完啊。
-
运维太麻烦:现在是静态部署,简单稳定;上 SSR 还得额外部署 Node.js 服务器。
所以在这种情况下,Nuxt 重构这条路就不走不通了。那有没有一种招,既能保留现在的 SPA 写法,又能让它部署出来变成多页面呢?
有的,这正好是 SSG(静态站点生成) 的看家本领。配合 vite-ssg 这个神器,只需要改动一点代码就能实现SEO优化。
说白了,核心原理就是提前交卷 。以前是浏览器拿到空壳再执行js代码进行页面渲染,现在我们在打包阶段就把页面内容全拼接好了。部署上去后,用户请求的直接就是写满字的"成品 HTML"。这样一来,页面源码里全是干货,爬虫来了能看懂,SEO效果就杠杆的。
🛠️ 核心改造:从 SPA 到 SSG 的蜕变
首先需要在项目根目录下安装vite-ssg 然后对入口文件main.ts和路由进行改造
npm地址: www.npmjs.com/package/vit...
Bash
pnpm add -D vite-ssg入口文件改造 (main.ts)
vite-ssg 的核心代码改动在于替换 createApp。我们需要导出一个创建应用的函数,而不是直接挂载。
改造前:
ts
createApp(App).use(router).mount('#app')改造后:
ts
import { ViteSSG } from 'vite-ssg'
import App from './App.vue'
import { routes } from './router' // 注意:这里导出的是路由配置数组,不是 router 实例
// 核心改造:ViteSSG 接管应用创建
export const createApp = ViteSSG(
App,
{ routes, base: import.meta.env.BASE_URL },
({ app, router, routes, isClient, initialState }) => {
// 插件注册
const head = createHead()
app.use(head)
// 💡 优化点:第三方脚本的动态注入
// 将原本 index.html 里的 volc-collect.js 移到这里
// 仅在客户端环境加载,防止构建时报错
if (isClient) {
import('./utils/volc-collect.js').then(() => {
console.log('火山引擎统计脚本已加载')
})
}
}
)💡 为什么要改成导出?
- 以前 (
mount) :是命令式的。浏览器读到这行代码,立即干活,把 App 挂载到 DOM 上。 - 现在 (
export) :是把"启动权"交出去 。- Node.js (打包时):引入这个函数,在服务端跑一遍,生成 HTML 静态文件。
- 浏览器 (访问时) :
vite-ssg的客户端脚本也会引入这个函数,用来激活现有的 HTML,让它变回动态页面。
路由配置改造 (router/index.ts)
vite-ssg 对路由有两个硬性要求:
-
不能直接返回 router 实例 :它需要导出原始的
routes数组。 -
History 模式 :必须使用 Web History。 原因:Hash 片段(
#后)不参与 HTTP 请求,服务器无法匹配例如/about/index.html的物理文件,SSG 生成的多页面会失效。
改造前(传统的 SPA 导出):
ts
import { createRouter, createWebHistory } from 'vue-router'
const routes = [
{ path: '/', component: () => import('../views/Home.vue') },
// ... 其他路由
]
const router = createRouter({
history: createWebHistory(),
routes
})
export default router // 直接导出实例,SSG 无法解析改造后(适配 SSG):
ts
import { RouteRecordRaw } from 'vue-router'
// 1. 导出 routes 数组供 ViteSSG 使用
export const routes: RouteRecordRaw[] = [
{
path: '/',
name: 'Home',
component: () => import('../views/Home.vue')
}
// ... 其他路由
]攻坚战一:环境兼容性治理(填坑实录)
这是 SSG 改造中最容易崩溃的环节。构建过程是在 Node.js 环境下运行的,如果你在vue3组件 setup 顶层(非浏览器生命周期钩子内)直接访问了 window 或 document,Node 环境会报 ReferenceError。
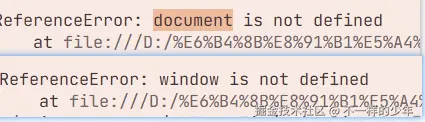
1. 修复报错处理 window、document is not defined
- 逻辑层: 很多组件库或工具函数会在文件顶部直接访问
window,导致打包报错。 必须增加环境判定。严格使用if (typeof window !== 'undefined')或import.meta.env.SSR进行判断。
js
export const isClient = typeof window !== 'undefined'
export function getViewportWidth() {
if (isClient) return null
return window.innerWidth
}
...- 组件层(UI 逻辑): 凡是涉及 DOM/BOM 的操作,一律下沉到
onMounted。
js
<script setup>
import { ref, onMounted } from 'vue'
const width = ref(0)
// ❌ 错误写法:构建时会直接报错 ReferenceError
// width.value = window.innerWidth
// ✅ 正确写法:等到组件挂载(浏览器环境)后再访问
onMounted(() => {
width.value = window.innerWidth
console.log(document.title)
})
</script>2. 接口请求适配(绝对路径问题)
在浏览器端,我们习惯用相对路径,例如 /api(配合 Vite Proxy);但在 SSG 构建阶段,Node 环境并不知道相对路径指向哪里。
改造方案:Axios 封装 :利用 import.meta.env.SSR 动态切换 baseURL。
ts
import axios from 'axios'
const service = axios.create({
// import.meta.env.SSR 是 Vite 提供的环境变量
baseURL: import.meta.env.SSR
? 'http://xxxx/api' // SSG 构建时:使用绝对路径
: '/api', // 浏览器运行时:用相对路径走代理
timeout: 5000
})
export default service3. 脚本注入(第三方 SDK 动态加载)
原先在 index.html 里直接硬编码的 <script>(如火山引擎 volc-collect.js、百度统计等),由于内部包含大量立即执行的 DOM 操作,会导致构建直接挂掉。
改造方案:从 HTML 移出,改在 main.ts 中动态加载 利用 ViteSSG 提供的 isClient 参数,我们可以确保这些脚本只在浏览器环境运行
js
// main.js
import { ViteSSG } from 'vite-ssg'
import App from './App.vue'
export const createApp = ViteSSG(
App,
{ routes },
({ app, isClient }) => {
// 核心:只在客户端(浏览器)环境加载这些脚本
if (isClient) {
// 动态导入,构建时 Node 会直接忽略这段代码
import('./plugins/baidu-analytics.js')
import('./plugins/volc-engine.js')
}
}
)攻坚战二:让 HTML "有血有肉" (onServerPrefetch)
默认情况下,onMounted 里的数据请求在 SSG 打包阶段根本不会跑,生成的 HTML 还是个空壳。
想要让爬虫看到真实数据,必须得请出 onServerPrefetch。说白了,就是告诉构建工具:"兄弟,打包的时候别光顾着编译代码,顺手帮我把这些接口也请求一下,把数据直接焊死在 HTML 里。"
实战代码:
ts
<script setup>
import { ref, onServerPrefetch } from 'vue';
import { getCompanyInfo } from '../api/common';
const info = ref(null);
// 核心:服务端渲染/SSG 构建时触发
// 在这里请求的数据会被自动序列化到 HTML 中
onServerPrefetch(async () => {
const res = await getCompanyInfo();
info.value = res.data;
});
</script>🔍 攻坚战三:全方位的 SEO 细节打磨
解决了"能看"的问题,还得解决"好看"和"好抓"的问题。在动手前,我们得先搞清楚我们的"甲方"------蜘蛛(爬虫) 到底想要什么。
🕷️ 什么是"蜘蛛/爬虫"?它抓完代码后干了什么?
简单来说,蜘蛛就是搜索引擎派出的"全自动化信息搬运工"。它的工作逻辑分为三步:
-
抓取 (Crawling) :它顺着链接爬行,不看 UI 华不华丽,只打包 HTML 源码带走。
-
索引 (Indexing) :抓回的代码存入搜索引擎巨大的数据库,并记录每个页面"在讲什么"。
-
查询 (Querying) : 【核心关键】 当用户搜索时,搜索引擎是在自己的数据库里翻找,而不是全网现找。
扎心真相:为什么 SPA 会在 SEO 面前"高度近视"?
很多同学纳闷:"我的 SPA 也有 TDK(标题、描述、关键词),百度也能搜到官网名啊。" 这其实是封面与白纸 的问题:
-
本质原因 :SPA 本质上只有一个真实的
index.html骨架和一套基础的 TDK。它所谓的"页面切换",其实是根据路由动态切换脚本(JS) 来渲染内容的。 -
蜘蛛视角 :对于蜘蛛来说,你的项目就像一本书,只有封面(首页)印了字,翻开后每一页都是需要执行 JS 才能显现的"无字天书" 。由于蜘蛛抓取时通常不等待异步 JS 执行完成,它搬回数据库的每一页都是白纸。
举个例子:
-
用户搜索 "产品官网名" :搜索引擎在数据库里找到了首页(封面)的 TDK,能搜到你,这叫"有品牌词排名"。
-
用户搜索 "资产管理方案" :这个词在
/asset路由下。但在蜘蛛搬回的数据库里,/asset页面还是首页的 TDK ,内容区是一片空白。因为真正的"资产管理方案"文案要等 页面JS 执行完才会渲染 ,而爬虫只抓到了空壳源码。结果就是搜索引擎翻遍数据库也找不到这个词,这就是所谓的内页无收录、无排名。
SSG 的本质:就是在构建时预执行 JS,把"无字天书"直接印成实实在在的 HTML 文字,确保蜘蛛搬回数据库的每一页都内容满满。
1. TDK 动态注入 (@unhead/vue)
首先需要安装 @unhead/vue
bash
pnpm add @unhead/vue然后在组件中使用 useHead 为每个页面定制 Title、Description、Keywords。
js
import { useHead } from '@unhead/vue'
useHead({
title: '页面标题',
meta: [
{
name: 'description',
content: '页面解释',
},
{
name: 'keywords',
content: '关键词',
},
],
})2. 自动化 Sitemap 与 Robots
如果说 SSG 是把"无字天书"印成了文字,那么 Sitemap 和 Robots 就是告诉蜘蛛: "这儿有书,快来读,顺着这张图爬准没错!"
🛠️ 自动生成 Sitemap
安装 vite-ssg-sitemap 后,通过配置 onFinished 钩子,让它在构建完成后自动扫描 dist 目录并生成站点地图。
1. 安装插件
bash
pnpm add -D vite-ssg-sitemap2. vite.config.ts 配置全攻略
这一步的核心是在 ssgOptions 钩子里配置 onFinished。意思就是:等所有 HTML 页面都生成好了,再扫描一遍 dist 目录,把所有路由地址汇总成一张地图。
js
// vite.config.ts
import { defineConfig } from 'vite'
import generateSitemap from 'vite-ssg-sitemap'
export default defineConfig({
// ... 其他配置
ssgOptions: {
script: 'async',
formatting: 'minify',
// 核心逻辑:SSG 构建完成后自动触发
onFinished() {
generateSitemap({
// 1. 必填:你官网部署后的正式域名。
// 生成的 sitemap.xml 里需要用这个域名 + 路由路径拼成完整 URL (如 https://site.com/about)
hostname: 'https://your-website.com/',
// 2. 扫描目录:通常是打包后的输出目录
outDir: 'dist'
})
},
},
})验证结果: 当你运行 pnpm run build 后,你会发现 dist 目录下多了 sitemap.xml和 robots.txt 文件。

robots.txt: 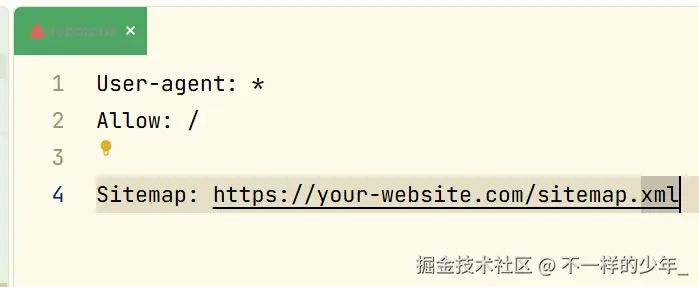
-
User-agent:这里的*是通配符,表示这段规则对所有的搜索引擎爬虫(百度的百度蜘蛛、谷歌的 Googlebot、必应的 Bingbot 等)都生效。 -
Allow:这里/代表根目录。这行指令告诉蜘蛛,整个网站的所有公开页面你都可以随意抓取。- 注:如果你有不想让搜到的页面(如
/admin),可以配合Disallow: /admin使用。
- 注:如果你有不想让搜到的页面(如
-
Sitemap: https://your-website.com/sitemap.xml这是最关键的一行。它直接把我们刚才自动生成的站点地图地址甩给蜘蛛。蜘蛛一进站,第一眼看到这个地址,就会立刻去读地图,从而精准、高效地抓取你全站的内页,而不至于在你的网站里"迷路"。
生成的 sitemap.xml:其实就是给爬虫看的一份导航清单,告诉它:"我网站里有这些页面,你按着这个列表一个个去抓就行,别漏了。"
xml
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url><loc>https://your-website.com/</loc></url>
<url><loc>https://your-website.com/product</loc></url>
<url><loc>https://your-website.com/about</loc></url>
</urlset>3. 扫除障碍:代码层的 SEO 修正
- 路由去重: 将根路由 / 直接指向核心组件,别用 301 重定向;多一次跳转就多交一次"过路费",别让分数扣在半路上
js
// ❌ 错误做法: 导致权重分散的重定向
const routes = [
{ path: '/', redirect: '/home' }, // 爬虫访问根路径时会被踢到 /home
{ path: '/home', component: Home }
];
// ✅ 正确做法: 根路径直接渲染
const routes = [
{ path: '/', component: Home }, // 爬虫直接抓取内容,权重集中在根域名
// 如果需要兼容 /home,可以让它指向同一个组件或做 canonical 处理
];- 补全 Alt: 全局搜索
<img>标签,给关键图片加上精准的alt描述(如"企业资产管理系统界面"),这是图片搜索流量的主要来源。
js
<!-- ❌ 错误做法: 搜索引擎不知道这是什么 -->
<img src="/assets/dashboard-v2.png" />
<!-- ✅ 正确做法: 精准描述图片内容 -->
<img
src="/assets/dashboard-v2.png"
alt="企业资产管理系统数据可视化仪表盘"
/>- 链路修正: 导航栏严禁使用
div+click跳转 !必须使用router-link。router-link在 SSG 构建时会渲染为标准的<a>标签,爬虫才能顺藤摸瓜抓取内页。- 如果只用点击事件,爬虫看来这就是个死胡同。
js
<!-- ❌ 错误做法: div + click 是爬虫的死胡同 -->
<div class="nav-item" @click="$router.push('/products')">
产品中心
</div>
<!-- ✅ 正确做法: SSG/SSR 会渲染为 <a href="/products"> -->
<router-link to="/products" class="nav-item">
产品中心
</router-link>4. 性能与结构化数据
在解决了页面渲染和基础爬取问题后,市场部又给出了两点非常专业的 SEO 建议,这也是很多开发者容易忽略的:
图片去 Base64 化:让蜘蛛跑得快一点
默认情况下,Vite 会将小于 4kb 的图片转为 Base64 编码内联进 HTML。
SEO 痛点: 百度爬虫(蜘蛛)在抓取时非常"呆",过长的 Base64 编码会显著增加 HTML 体积,导致抓取超载,蜘蛛还没读到页面的核心文字就"饱了",从而放弃后续内容的抓取。
优化方案: 在 vite.config.ts 中调整 assetsInlineLimit 阈值为 0,强制所有图片以独立 URL 链接形式引入。
ts
// vite.config.ts
export default defineConfig({
build: {
// 设置为 0,禁用图片转 base64,确保蜘蛛抓取时路径清晰、HTML 精简
assetsInlineLimit: 0,
}
})结构化数据:给搜索引擎"喂"一张专属 Logo
虽然我们已经有了 Favicon,但搜索引擎在搜索结果页展示的 Logo 需要通过 JSON-LD 结构化数据 显式声明。
优化方案: 在首页增加符合 Schema.org 标准的脚本块。这能极大增加网站在搜索结果中展示品牌 Logo 的概率。 通常在源码中是这样显现的:
js
<script type="application/ld+json">
{
"@context": "https://schema.org", // 声明标准: 告诉蜘蛛:"咱们按 schema.org 这个国际通用标准来聊天。
"@type": "Organization", // 身份定义:告诉蜘蛛:"我是一个'组织/公司',不是个人博客或小新闻。
"url": "https://your-website.com/", // 主页地盘:是我们的官号唯一地址,防止权重被其他镜像站分散
"logo": "https://your-website.com/images/logo.png" // 门面担当:定那张要显示在搜索结果左侧的小方图
}
</script>我们可以在Vue中使用 @unhead/vue 的 useHead 动态注入此脚本。
实战代码:动态注入结构化数据
js
<script setup>
import { useHead } from '@unhead/vue'
import logoUrl from '@/assets/logo.png' // 假设这是你的logo路径
useHead({
script: [
{
type: 'application/ld+json',
children: JSON.stringify({
"@context": "https://schema.org",
"@type": "Organization",
"name": "你的品牌名称",
"url": "https://your-website.com/",
"logo": logoUrl
})
}
]
})
</script>注:市场部说对于百度搜索的话,logo结构化数据的图片比例得是4:3比较好
小结
- HTML 瘦身:禁用 Base64 后的 HTML 源码更干净,关键词密度(文字占比)相对提升,更有利于收录。
- 搜索展现:logo结构化数据是目前主流搜索引擎(百度、谷歌)最推崇的"沟通方式",能让你的网站在搜索结果里看起来更专业。
示例(谷歌搜索网站的 Logo 展示):
成果展示
经过一天的极限改造,运行 npm run build 后:
-
Dist 目录变化: 不再是单一的
index.html,而是生成了/download.html,/purchase.html等多个页面html文件。原来的: 单页面文件

优化后的: 多页面
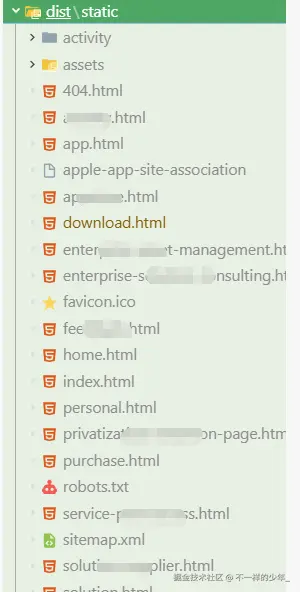
-
源码查看: 右键"查看网页源代码",不再是空荡荡的
<div id="app"></div>,而是充满了具体的业务文案和<meta>标签。 -
Lighthouse: SEO 评分从 80+ 飙升至 100 分 (注:此评分仅代表技术规范达标,真实排名还需看内容质量与外链积累)。
总结与思考
在时间极其有限的情况下,Vite-SSG 是 Vue SPA 项目实现 SEO 优化的最佳"中间态"方案。
它不需要 Nuxt 那样伤筋动骨的迁移成本,却能以最小的代价换取 80% 的 SSR 收益。虽然在处理海量动态数据上不如 SSR 完美,但对于企业官网、文档站、活动页这些,已经完全够用了
这次优化主要做了三件事:
- 填坑: 解决
window、API 路径等环境差异。 - 注水: 用
onServerPrefetch让静态 HTML 充满数据。 - 指路: 用 Sitemap 和 TDK 告诉爬虫"看这里"。
希望能给同样面临"SEO 突击检查"的兄弟们提供一个可落地的思路!