文章目录
- 储备知识
- threadCache
- centralCache
-
- [向 PageCache 申请内存](#向 PageCache 申请内存)
- [向 PageCache 释放内存](#向 PageCache 释放内存)
- pageCache
-
- _idSpanMap
-
- 原理:
- [对比 hash:](#对比 hash:)
- [使用基数树而不是 vector:](#使用基数树而不是 vector:)
- [NewSpan给 CentralCache 内存](#NewSpan给 CentralCache 内存)
- MapObjectToSpan
- ReleaseSpanToPageCache
- SizeClass
- 扩展以及参考文章
-
- [代替 malloc](#代替 malloc)
- [malloc 底层相关文章以及其他内存池](#malloc 底层相关文章以及其他内存池)
本人实现源码:https://gitee.com/xfuturejianchi/concurrent-memory-pool
储备知识
malloc就是内存池,不同编译器平台用的不同,gcc使用ptmalloc
操作系统会执行brk或者mmap来申请虚拟地址空间(一般不是特别大的空间都是brk)
为了优化 malloc,减少内存碎片,所以 google 开发了 tcmalloc 这个著名内存池
threadCache
FreeList 结构
cpp
void* _freeList = nullptr; ///< 指向空闲链表头部的指针
size_t _maxSize = 1; ///< 当前可持有的最大内存块数量(动态调整)
size_t _size = 0; ///< 当前链表中实际内存块数量用于小于 256KB 内存分配,线程独享
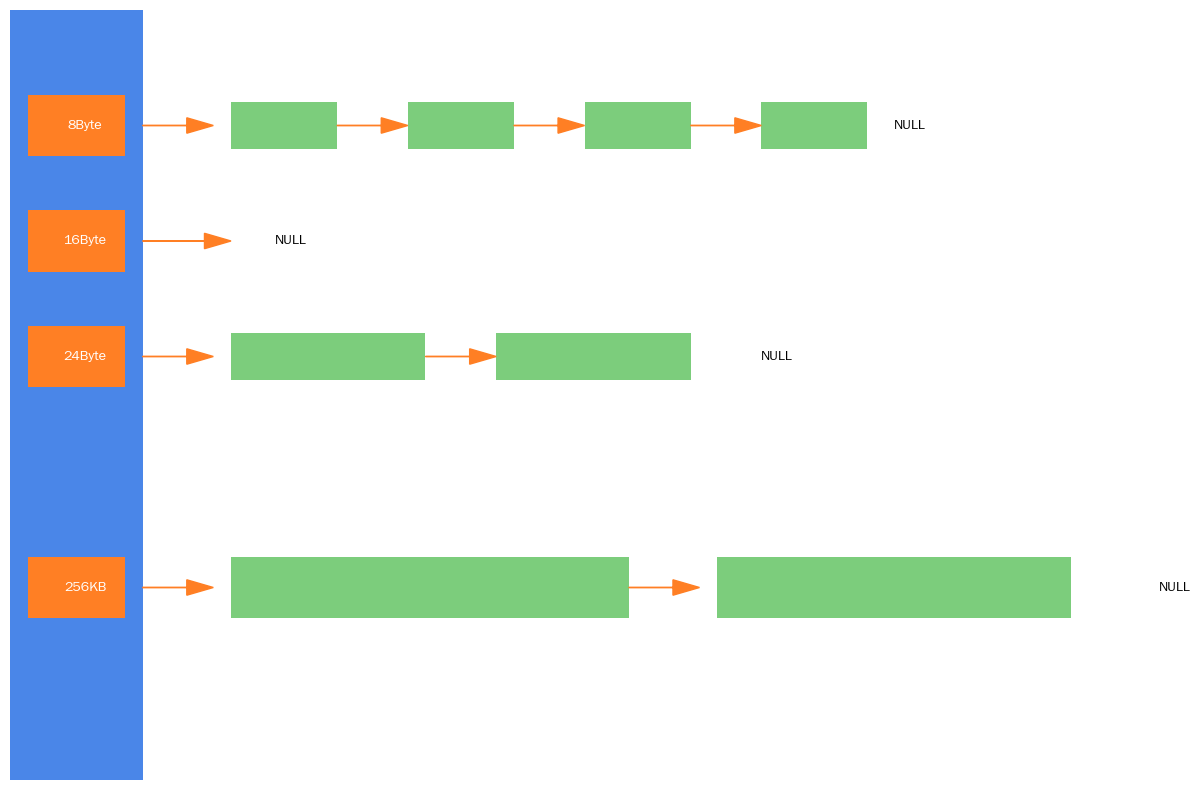
申请内存:
- 判断空间是否超过 256KB
- 计算对齐后的大小和自由链表索引
cpp
/**
* @brief 向上对齐到指定粒度
*
* 使用位运算实现高效对齐:
* (bytes + alignNum - 1) & ~(alignNum - 1)
*
* @param bytes 原始字节数
* @param alignNum 对齐粒度(2的幂)
* @return size_t 对齐后的字节数
*/
static inline size_t _RoundUp(size_t bytes, size_t alignNum)
{
return ((bytes + alignNum - 1) & ~(alignNum - 1));
}
/**
* @brief 根据不同范围使用不同对齐粒度进行向上对齐
*
* @param size 原始大小
* @return size_t 对齐后的大小
*
* 对齐策略:
* - size <= 128: 8字节对齐
* - size <= 1024: 16字节对齐
* - size <= 8KB: 128字节对齐
* - size <= 64KB: 1024字节对齐
* - size <= 256KB: 8KB对齐
* - 超过256KB: 按页面对齐(8KB)
*/
static inline size_t RoundUp(size_t size)
{
if (size <= 128)
{
return _RoundUp(size, 8);
}
else if (size <= 1024)
{
return _RoundUp(size, 16);
}
else if (size <= 8*1024)
{
return _RoundUp(size, 128);
}
else if (size <= 64*1024)
{
return _RoundUp(size, 1024);
}
else if (size <= 256 * 1024)
{
return _RoundUp(size, 8*1024);
}
else
{
return _RoundUp(size, 1<<PAGE_SHIFT);
}
}
cpp
/**
* @brief 计算对齐后的索引(内部函数)
*
* @param bytes 字节数
* @param align_shift 对齐的位数偏移
* @return size_t 计算得到的索引
*
* 计算公式:((bytes + 2^align_shift - 1) >> align_shift) - 1
*/
static inline size_t _Index(size_t bytes, size_t align_shift)
{
return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;
}
/**
* @brief 根据内存大小计算对应的自由链表索引
*
* @param bytes 要分配的内存大小(不超过MAX_BYTES)
* @return size_t 对应的自由链表索引
*
* 该函数实现了复杂的索引映射逻辑,将不同范围的内存大小
* 映射到208个不同的自由链表中
*/
static inline size_t Index(size_t bytes)
{
assert(bytes <= MAX_BYTES);
// 每个范围内的链表数量:16 + 56 + 56 + 56 + 24 = 208
static int group_array[4] = { 16, 56, 56, 56 };
if (bytes <= 128){
return _Index(bytes, 3); // 8字节对齐,索引范围 [0, 15]
}
else if (bytes <= 1024){
// 减去前一个范围的起始点,加上前几个范围的总和
return _Index(bytes - 128, 4) + group_array[0]; // [16, 71]
}
else if (bytes <= 8 * 1024){
return _Index(bytes - 1024, 7) + group_array[1] + group_array[0]; // [72, 127]
}
else if (bytes <= 64 * 1024){
return _Index(bytes - 8 * 1024, 10) + group_array[2] + group_array[1] + group_array[0]; // [128, 183]
}
else if (bytes <= 256 * 1024){
return _Index(bytes - 64 * 1024, 13) + group_array[3] + group_array[2] + group_array[1] + group_array[0]; // [184, 207]
}
else{
assert(false); // 不应该到这里
}
return -1;
}- 判断是否对应 index 还有内存
- 如果没有,向 CentralCache 申请
cpp
/**
* @brief 计算从CentralCache一次批量获取的内存块数量
*
* 批量获取策略:
* - 最少2个,最多512个
* - 计算公式:MAX_BYTES / size
*
* @param size 单个内存块的大小
* @return size_t 批量获取的数量
*/
static size_t NumMoveSize(size_t size)
{
assert(size > 0);
// 计算批量大小,确保有足够的内存复用价值
int num = MAX_BYTES / size;
if (num < 2)
num = 2; // 最少2个
if (num > 512)
num = 512; // 最多512个
return num;
}
size_t batchNum = min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));- 动态调整阈值
cpp
// 动态调整:每次成功申请后增加阈值
if (_freeLists[index].MaxSize() == batchNum)
{
_freeLists[index].MaxSize() += 1;
}- 调用 FetchRangeObj 向 CentralCache 申请内存
cpp
/**
* @brief 批量从CentralCache获取内存块
*
* 该函数是CentralCache向ThreadCache提供内存的主要接口。
* 它从一个Span中获取指定数量的内存块,供ThreadCache使用。
*
* 批量获取的优势:
* - 减少锁获取次数
* - 提高内存局部性
* - 降低CentralCache的访问频率
*
* @param start 输出参数,获取的内存块链表起始位置
* @param end 输出参数,获取的内存块链表结束位置
* @param batchNum 期望获取的内存块数量
* @param size 单个内存块的大小
* @return size_t 实际获取的内存块数量(可能小于batchNum)
*/
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size)
{
// 第一步:计算对应的SpanList索引并加锁
size_t index = SizeClass::Index(size);
_spanLists[index]._mtx.lock();
// 第二步:获取一个有空闲内存的Span
Span* span = GetOneSpan(_spanLists[index], size);
assert(span); // Span必须存在
assert(span->_freeList); // Span必须有空闲内存
// 第三步:从Span的_freeList中取出batchNum个内存块
// start指向取出的第一个内存块
start = span->_freeList;
end = start;
size_t i = 0;
size_t actualNum = 1; // 至少取出1个
// 遍历链表,取出最多batchNum个节点
// 注意:循环条件是 i < batchNum - 1,因为end已经指向第一个节点
while (i < batchNum - 1 && NextObj(end) != nullptr)
{
end = NextObj(end);
++i;
++actualNum;
}
// 更新Span的状态
span->_freeList = NextObj(end); // Span的新空闲链表头
NextObj(end) = nullptr; // 取出的链表的尾部置空
span->_useCount += actualNum; // 增加使用计数
// 第四步:释放锁并返回
_spanLists[index]._mtx.unlock();
return actualNum;
}- 根据下标找到 span 加锁,然后 GetOneSpan、
- GetOneSpan 的策略:
- 根据 SpanList 一个个遍历 Span,如果 Span 的 _freeList 为空就接着遍历下一个 Span
- 如果这个 SpanList 的所有 Span 都没有空间,对 central 对应的 SpanList 解锁,开始调用
NewSpan(SizeClass::NumMovePage(size))向 PageCache 申请内存 - 标记 NewSpan 返回的 Span 为正在使用,同时记录该 Span 的内存块的大小(Span 的 _freeList 分割的内存块的大小)
- 对这个 Span 初始化------根据页面号进行偏移来获取实际地址,通过 _n 成员得知分得的页数,然后就可以得知 end 地址,开始根据内存块大小进行切分
- 重新对 centralCache 对应的 SpanList 加锁,把 span 头插,并且作为返回值返回
cpp
Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{
// 第一步:遍历SpanList,查找_freeList非空的Span
// 这种"先查找缓存"的策略可以减少向PageCache申请的次数
Span* it = list.Begin();
while (it != list.End())
{
if (it->_freeList != nullptr)
{
// 找到有空闲内存块的Span,直接返回
return it;
}
else
{
// 该Span已被完全分配,继续查找下一个
it = it->_next;
}
}
// 第二步:没有找到可用的Span,需要向PageCache申请
// 重要:释放当前锁,避免与其他线程死锁
// CentralCache的锁是按大小分类的,PageCache是全局锁
list._mtx.unlock();
// 获取PageCache全局锁,申请指定页数的Span
PageCache::GetInstance()->_pageMtx.lock();
Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));
span->_isUse = true; // 标记Span为使用中
span->_objSize = size; // 记录该Span管理的内存块大小
PageCache::GetInstance()->_pageMtx.unlock();
// 第三步:将Span切分成等大小的内存块
// 内存布局:Span包含N个页面,每个页面8KB
// Span被切分成 M = (N * 8KB) / size 个内存块
// 计算Span的起始地址和总大小
char* start = (char*)(span->_pageId << PAGE_SHIFT); // 页面号转换为实际地址
size_t bytes = span->_n << PAGE_SHIFT; // 总字节数 = 页数 * 8KB
char* end = start + bytes; // 结束地址
// 切分Span的内存,构建自由链表
// 1. 初始化:第一个内存块作为链表头
span->_freeList = start;
start += size; // 移动到下一个内存块位置
void* tail = span->_freeList; // tail指向链表尾部
int i = 1;
// 2. 循环切分:构建链表
while (start < end)
{
++i;
// 将前一个节点指向当前节点
NextObj(tail) = start;
// tail移动到当前节点
tail = NextObj(tail);
// start移动到下一个内存块
start += size;
}
// 3. 链表尾部置空
NextObj(tail) = nullptr;
// 第四步:将Span插入SpanList头部
// 重新获取锁
list._mtx.lock();
list.PushFront(span);
return span;
}- 如果实际对应 Span 只有一个内存节点就直接返回,否则放入对应哈希桶的自由链表中(start 给用户)
- 记得把 Span 的 _freeList 和 _userCount 更新,然后对对应 SpanList 解锁
- FetchRangeObj 返回实际获得的内存块,还有内存块的 start end。就可以更新 _freeListsindex 了
释放内存
传参 size(内存块大小) 和 void*
- 判断空间是否超过 256KB
- 计算自由链表索引
- 向对应 _freeList Push ptr
- 归还后,判断对应 _freeList Size 是否超过允许拥有的 MaxSize
- 超过,就执行
ListTooLong(_freeLists[index], size);size 表示内存块大小
- ListTooLong 策略:
- 将自由链表中一半的内存(按MaxSize计算)归还给CentralCache。
- 优势:
- 减少 ThreadCache 内存占用
- 让内存可以在不同线程间复用
cpp
/**
* @brief 将过多的内存归还给CentralCache
*
* 该函数将自由链表中一半的内存(按MaxSize计算)归还给CentralCache。
* 这样可以:
* 1. 减少ThreadCache的内存占用
* 2. 让内存可以在不同线程间复用
* 3. 避免内存碎片化
*
* @param list 自由链表引用
* @param size 内存块大小
*/
void ThreadCache::ListTooLong(FreeList& list, size_t size)
{
void* start = nullptr;
void* end = nullptr;
// 取出当前最大数量的内存块
list.PopRange(start, end, list.MaxSize());
// 把end->next = nullptr,所以后续调用可以直接遍历start,不需要传参end
// 将这些内存块归还给CentralCache
CentralCache::GetInstance()->ReleaseListToSpans(start, size);
}CentralCache::ReleaseListToSpans(void* start, size_t size)策略:
- 计算索引,对对应 SpanList 加锁
- 遍历 start
- 调用PageCache::MapObjectToSpan 找到对应的 span 应该在哪
- 更新 span: 把 start 插入到对应 span,更新 span _useCount,如果 _useCount == 0,开始归还 pagecache 合并
- 从 Central 对应 SpanList 移除该 span
- 释放 SpanList 锁
- 开始申请 PageCache 锁执行ReleaseSpanToPageCache,然后释放 PageCahe 锁
- 大于128 page的直接还给堆
- 对span前后的页,尝试进行合并,缓解内存碎片问题(根据 Span->pageId 寻找)
- 合并出超过128页的span没办法管理,不合并了
- 合并后给 idSpanMap
- 申请 SpanList 锁
- 释放 SpanList 锁
PageCache::MapObjectToSpan(void*) 策略:根据 start 找到内存块对应页,根据页找到从哪个 span 获取的,返回 Span*
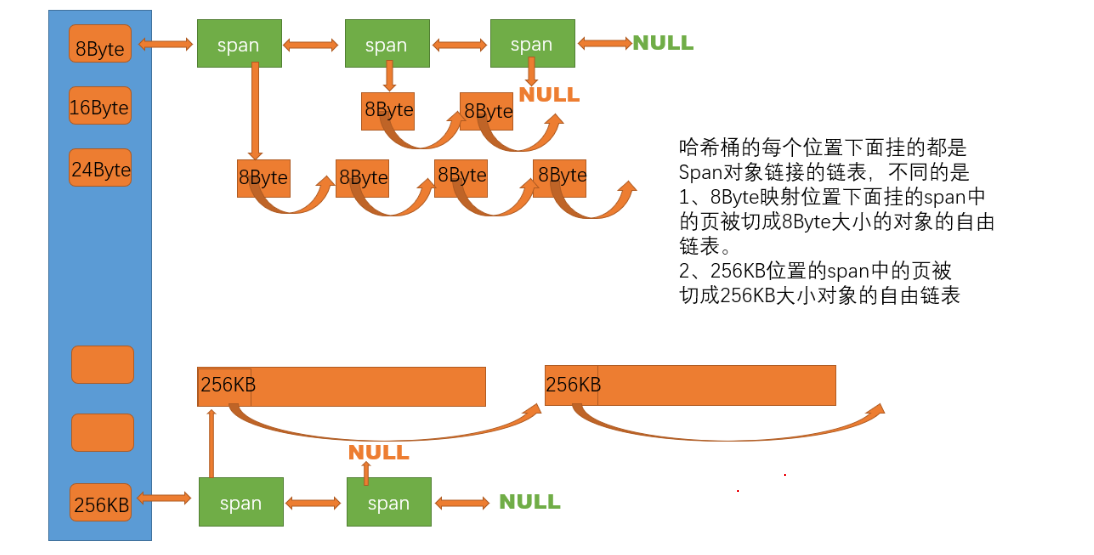
centralCache
cpp
struct Span
{
PAGE_ID _pageId = 0; ///< 起始页面ID(页面号 × 8KB = 实际起始地址)
size_t _n = 0; ///< 该Span包含的页面数量
Span* _next = nullptr; ///< 双向链表的下一个Span
Span* _prev = nullptr; ///< 双向链表的上一个Span
size_t _objSize = 0; ///< 该Span中分割的单个内存块大小
size_t _useCount = 0; ///< 当前已被分配出去的内存块数量(用于判断是否可以回收)
void* _freeList = nullptr; ///< 空闲内存块链表的头指针
bool _isUse = false; ///< Span是否正在被使用
};根据合适时机回收 threadCache
多线程取,所以会需要加桶锁
向 PageCache 申请内存
cpp
// 获取一个K页的span
Span* PageCache::NewSpan(size_t k)
{
assert(k > 0);
// 大于128 page的直接向堆申请
if (k > NPAGES-1)
{
void* ptr = SystemAlloc(k);
//Span* span = new Span;
Span* span = _spanPool.New();
span->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;
span->_n = k;
//_idSpanMap[span->_pageId] = span;
_idSpanMap.set(span->_pageId, span);
return span;
}
// 先检查第k个桶里面有没有span
if (!_spanLists[k].Empty())
{
Span* kSpan = _spanLists[k].PopFront();
// 建立id和span的映射,方便central cache回收小块内存时,查找对应的span
for (PAGE_ID i = 0; i < kSpan->_n; ++i)
{
//_idSpanMap[kSpan->_pageId + i] = kSpan;
_idSpanMap.set(kSpan->_pageId + i, kSpan);
}
return kSpan;
}
// 检查一下后面的桶里面有没有span,如果有可以把他它进行切分
for (size_t i = k+1; i < NPAGES; ++i)
{
if (!_spanLists[i].Empty())
{
Span* nSpan = _spanLists[i].PopFront();
//Span* kSpan = new Span;
Span* kSpan = _spanPool.New();
// 在nSpan的头部切一个k页下来
// k页span返回
// nSpan再挂到对应映射的位置
kSpan->_pageId = nSpan->_pageId;
kSpan->_n = k;
nSpan->_pageId += k;
nSpan->_n -= k;
_spanLists[nSpan->_n].PushFront(nSpan);
// 存储nSpan的首位页号跟nSpan映射,方便page cache回收内存时
// 进行的合并查找
//_idSpanMap[nSpan->_pageId] = nSpan;
//_idSpanMap[nSpan->_pageId + nSpan->_n - 1] = nSpan;
_idSpanMap.set(nSpan->_pageId, nSpan);
_idSpanMap.set(nSpan->_pageId + nSpan->_n - 1, nSpan);
// 建立id和span的映射,方便central cache回收小块内存时,查找对应的span
for (PAGE_ID i = 0; i < kSpan->_n; ++i)
{
//_idSpanMap[kSpan->_pageId + i] = kSpan;
_idSpanMap.set(kSpan->_pageId + i, kSpan);
}
return kSpan;
}
}
// 走到这个位置就说明后面没有大页的span了
// 这时就去找堆要一个128页的span
//Span* bigSpan = new Span;
Span* bigSpan = _spanPool.New();
void* ptr = SystemAlloc(NPAGES - 1);
bigSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;
bigSpan->_n = NPAGES - 1;
_spanLists[bigSpan->_n].PushFront(bigSpan);
return NewSpan(k);
}向 PageCache 释放内存
根据计算 ThreadCache 的空间点太长,调用函数取出来一部分节点来给 CentralCache 回收。通过桶下标定位到 centralCache 对应 Span 的 spanList 位置,然后通过基数树找到对应 Span 进行回收
pageCache
以页为单位存储,centralCache 没有内存对象时,从 pageCache 分配一定 page 切割,分配给 centralCache 。当 Span 的几个跨度页对象都回收后,pageCache 会回收 centralCache 满足套件的 Span 对象,并且合并相邻的页缓解内存碎片问题。
_idSpanMap
使用基数树快速完成内存块向 Span 的映射
原理:
- 使用内存块的地址可以确定内存块所在页号
- _idSpanMap 标明页号和 Span 的映射关系
- 使用 _idSpanMap 来映射页号
对比 hash:
- 使用 hash 在并发访问时需要加锁
- 如果不加锁会因操作节点导致 hash 结构发生变化,并发访问出现问题
- 基数树没有这个问题
使用基数树而不是 vector:
- 优化空间:
- 在 32 位下,一页 8KB,一共有 32 - (3 + 10) = 16,2^16 张页,一页我们使用一个指针指向,那么就需要 2^16*4 = 2^18 = 0.25MB 存放地址
- 在 64 位下,一共有 64 - (3 + 10) = 48,2^48 张页,一页我们使用一个指针指向,那么就需要 2^48*8 = 2^51 = 2048TB 存放地址
- 所以为了适配 64 位,我们应该使用基数树来映射,比如基数树第一层表示前 15bit,第二层表示 15 bit ,第三次表示 21bit 然后按需开辟空间,而不是一次开辟完全。一次减少指针的内存占用
NewSpan给 CentralCache 内存
- 判断如果内存大于 128page,直接找堆要
- 检查第 k 个桶里面有没有 span
- 如果有就申请,并且通过 _idSpanMap 映射页号和 span
- 如果没有,进行切分
- 再没有,向堆申请 128page span
cpp
/**
* @brief SpanList数组
*
* 129个SpanList,按页数索引:
* - _spanLists[1]:管理1页Span
* - _spanLists[2]:管理2页Span
* - ...
* - _spanLists[128]:管理128页Span
* - _spanLists[128+]:大于128页的Span
*/
SpanList _spanLists[NPAGES];
/**
* @brief Span对象的内存池
*
* 使用ObjectPool预分配Span对象,避免频繁的new/delete
*/
ObjectPool<Span> _spanPool;
/**
* @brief 页号到Span的映射表
*
* 使用TCMalloc风格的一级页映射:
* - 键:页号(PAGE_ID)
* - 值:Span指针
*
* 映射范围:32 - PAGE_SHIFT = 19位,可映射512MB地址空间
* 页号 = 地址 >> 13,因此可以映射 2^(19+13) = 2^32 = 4GB 虚拟地址空间
*
* 映射策略:
* - 每个Span的起始页和结束页都建立映射
* - 方便快速查找任意地址所属的Span
*/
//std::unordered_map<PAGE_ID, Span*> _idSpanMap; // 备用方案:使用unordered_map
//std::map<PAGE_ID, Span*> _idSpanMap; // 备用方案:使用std::map
TCMalloc_PageMap1<32 - PAGE_SHIFT> _idSpanMap; // 当前方案:使用TCMalloc风格页映射MapObjectToSpan
通过地址找到 Span
- 通过地址找到起始页
- 通过起始页根据_idSpanMap找到 Span
ReleaseSpanToPageCache
通过传入 Span 完成 Span 合并
- 通过 Span 记录的页号寻找前后的 Span 然后合并后更新 _idSpanMap
SizeClass
- 加上 alignNum - 1 确保任何起始位置都能"跨越"到下一个对齐边界
cpp
/**
* @brief 向上对齐到指定粒度
*
* 使用位运算实现高效对齐:
* (bytes + alignNum - 1) & ~(alignNum - 1)
*
* @param bytes 原始字节数
* @param alignNum 对齐粒度(2的幂)
* @return size_t 对齐后的字节数
*/
static inline size_t _RoundUp(size_t bytes, size_t alignNum)
{
return ((bytes + alignNum - 1) & ~(alignNum - 1));
}
/**
* @brief 根据不同范围使用不同对齐粒度进行向上对齐
*
* @param size 原始大小
* @return size_t 对齐后的大小
*
* 对齐策略:
* - size <= 128: 8字节对齐
* - size <= 1024: 16字节对齐
* - size <= 8KB: 128字节对齐
* - size <= 64KB: 1024字节对齐
* - size <= 256KB: 8KB对齐
* - 超过256KB: 按页面对齐(8KB)
*/
static inline size_t RoundUp(size_t size)
{
if (size <= 128)
{
return _RoundUp(size, 8);
}
else if (size <= 1024)
{
return _RoundUp(size, 16);
}
else if (size <= 8*1024)
{
return _RoundUp(size, 128);
}
else if (size <= 64*1024)
{
return _RoundUp(size, 1024);
}
else if (size <= 256 * 1024)
{
return _RoundUp(size, 8*1024);
}
else
{
return _RoundUp(size, 1<<PAGE_SHIFT);
}
}扩展以及参考文章
代替 malloc
不同平台替换⽅式不同。 基于unix的系统上的glibc,使⽤了weak alias的⽅式替换。具体来说是
因为这些⼊⼝函数都被定义成了weak symbols,再加上gcc⽀持 alias attribute,所以替换就变
成了这种通⽤形式:
void* malloc(size_t size) THROW attribute__ ((alias (tc_malloc)))
因此所有malloc的调⽤都跳转到了tc_malloc的实现
具体参考这⾥:GCC attribute 之weak,alias属性_gcc weak alias-CSDN博客
有些平台不⽀持这样的东西,需要使⽤hook的钩⼦技术来做。
malloc 底层相关文章以及其他内存池
https://zhuanlan.zhihu.com/p/384022573
malloc()背后的实现原理------内存池 - 阿照的日志