使用随机森林RF做分类建模,有训练集和预测集分类准确率图,还有特征重要性排序图,代码内有注释,可学习性强,直接替换数据就可以用,想要的可以加好友我。
最近在做一个分类建模的项目,用随机森林(Random Forest,简称RF)玩了一把,效果还挺不错,来给大家分享一下。
首先呢,咱们得有训练集和预测集。这里我就假设已经有了这样两个数据集,训练集叫traindata*,预测集叫test* data。
python
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# 读取数据(这里假设数据已经按正确格式准备好,直接读取)
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
# 分离特征和标签
X = train_data.drop('label_column', axis=1) # 假设'label_column'是标签列
y = train_data['label_column']
# 划分训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)代码分析来啦!import部分就是引入需要的库,pandas用于数据处理,numpy提供数值计算支持,RandomForestClassifier是随机森林分类器,traintestsplit用于划分训练集和验证集,accuracy_score用来计算准确率,matplotlib.pyplot用于画图。
读取数据部分,直接用pd.read_csv读取假设好的训练集和预测集数据文件。
分离特征和标签很简单,用drop方法把标签列去掉就得到特征X,标签单独存为y。
划分训练集和验证集这里,testsize=0.2**表示留出20%作为验证集,random state=42是为了保证每次划分结果一致,这样方便复现和对比。
接下来,创建随机森林分类器并训练模型:
python
# 创建随机森林分类器
rf = RandomForestClassifier(random_state=42)
# 训练模型
rf.fit(X_train, y_train)这里就很直接啦,实例化一个随机森林分类器rf,然后用训练集数据Xtrain**和y train来训练它。
训练完模型,咱们就可以做预测和计算准确率啦:
python
# 预测
y_pred = rf.predict(X_val)
# 计算准确率
accuracy = accuracy_score(y_val, y_pred)
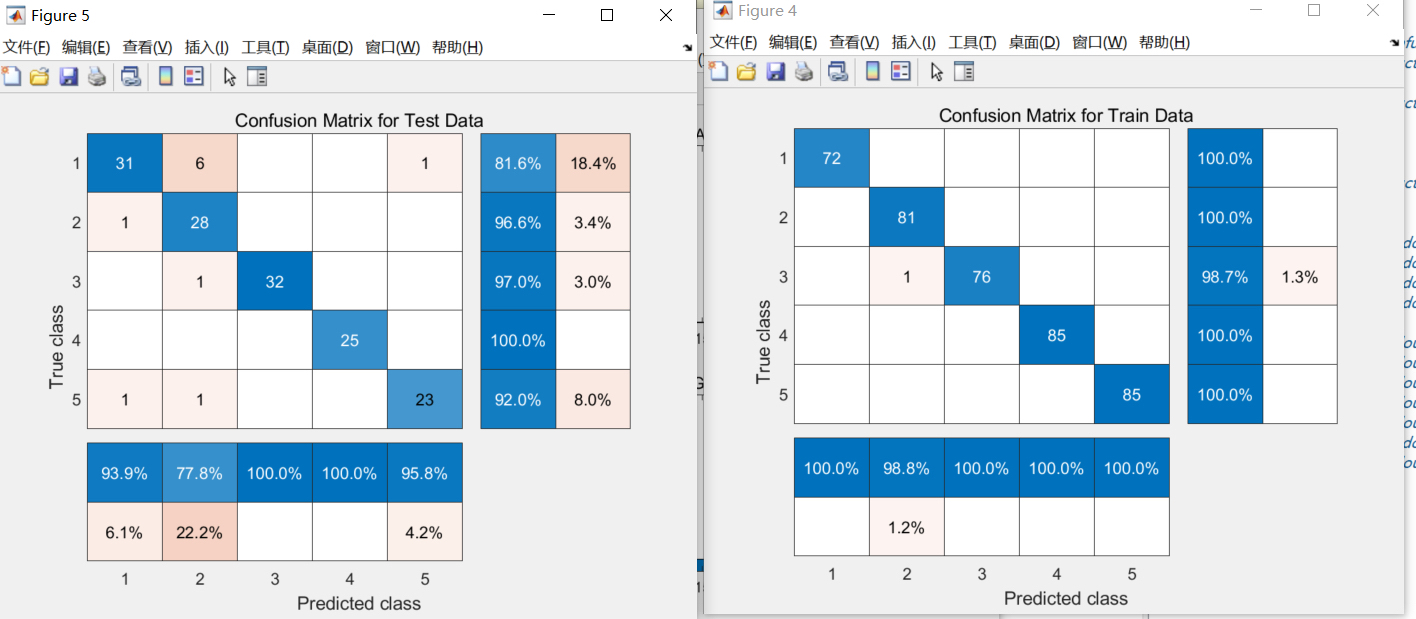
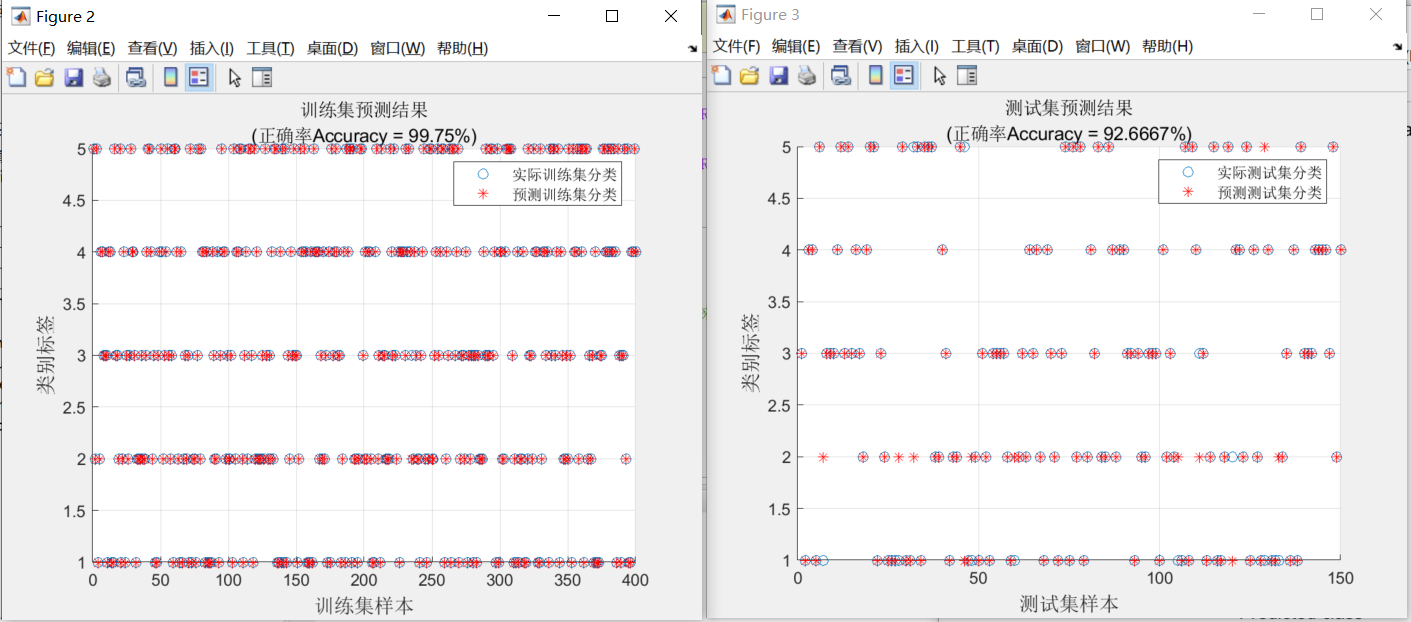
print(f"验证集准确率: {accuracy}")先对验证集Xval**进行预测得到y pred,然后用accuracyscore**计算预测结果和真实标签y val的准确率并打印出来。
最后,咱们来看看怎么画特征重要性排序图:
python
# 获取特征重要性
importances = rf.feature_importances_
std = np.std([tree.feature_importances_ for tree in rf.estimators_], axis=0)
indices = np.argsort(importances)[::-1]
# 打印特征排名
print("特征重要性排序:")
for f in range(X_train.shape[1]):
print("%d. feature %d (%f)" % (f + 1, indices[f], importances[indices[f]]))
# 绘制特征重要性图
plt.figure(figsize=(10, 6))
plt.title("Feature importances")
plt.bar(range(X_train.shape[1]), importances[indices],
color="r", yerr=std[indices], align="center")
plt.xticks(range(X_train.shape[1]), indices)
plt.xlim([-1, X_train.shape[1]])
plt.show()这段代码先获取特征重要性importances,再计算标准差std,然后对重要性进行排序得到indices。接着打印出特征排名,最后用matplotlib画出特征重要性排序图。
画分类准确率图其实也类似,不过是把训练集和验证集的准确率变化情况画出来,这里就不详细写代码啦,大家可以根据上面的思路自己尝试一下。
总之,随机森林在分类建模里真的很好用,代码也不算复杂,有了这些代码,替换自己的数据就可以轻松上手啦。想要更多交流或者代码细节的,欢迎加好友哦!