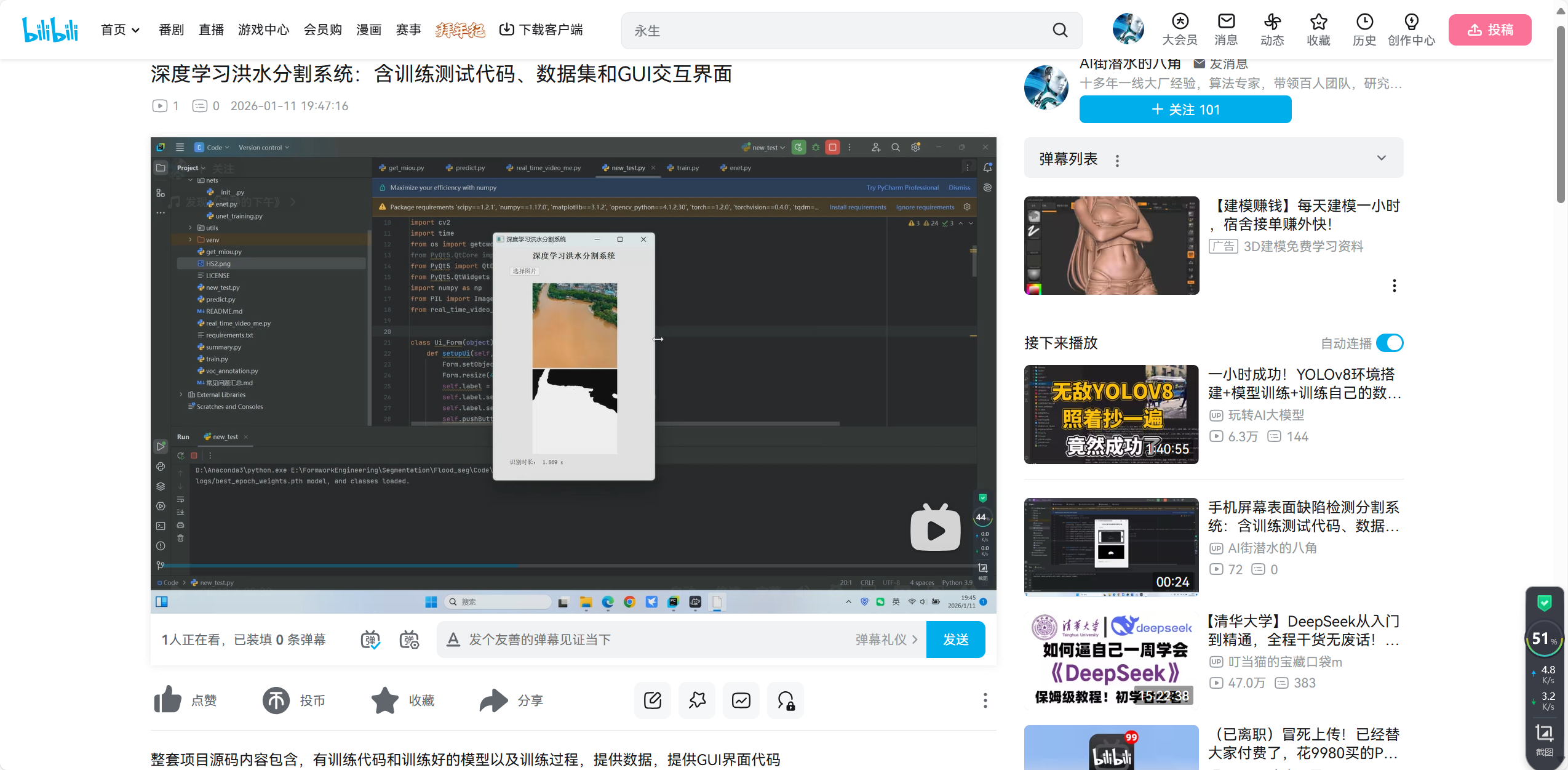
第一步:准备数据
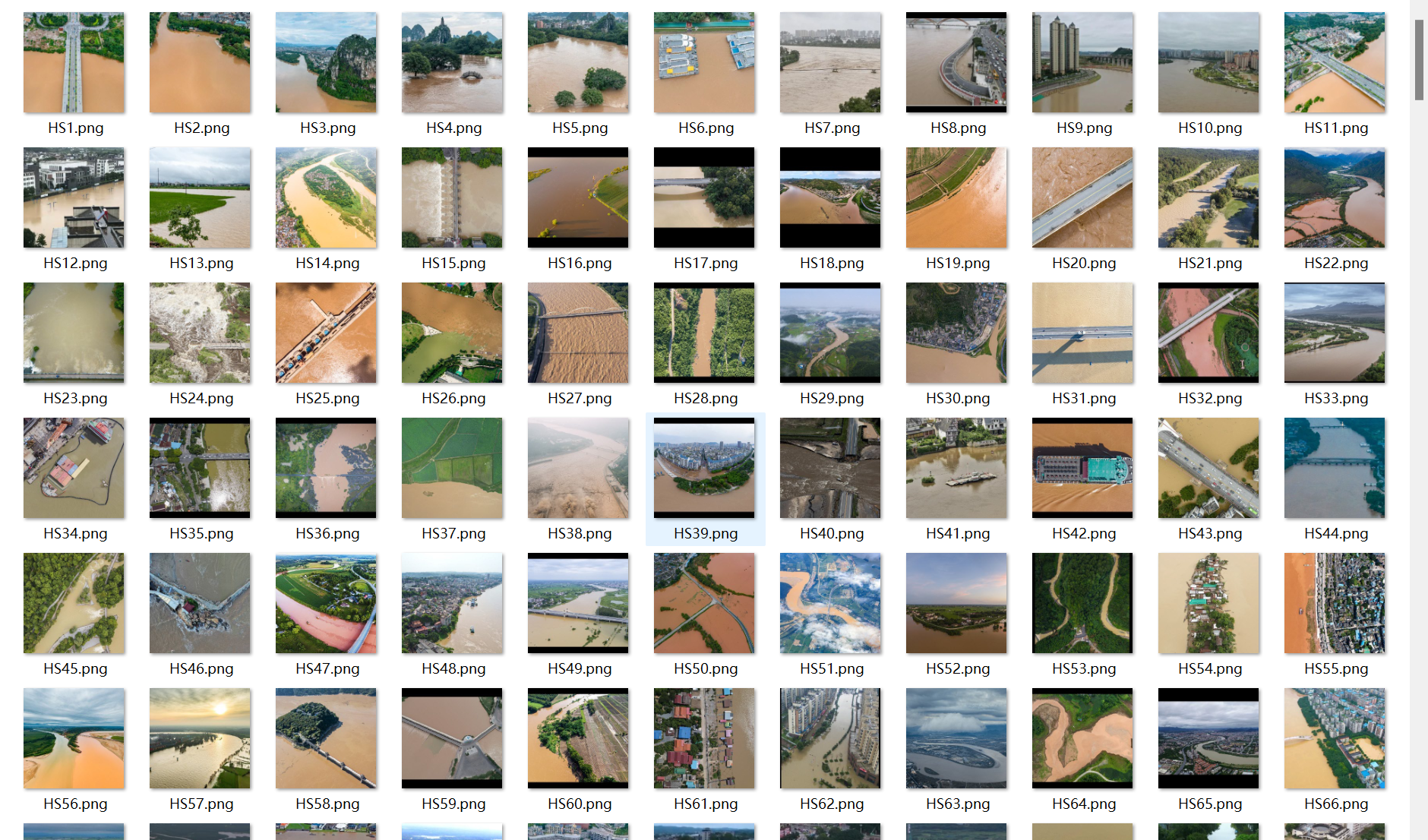
洪水分割-深度学习图像分割数据集
洪水分割数据,可直接应用到一些常用深度学习分割算法中,比如FCN、Unet、SegNet、DeepLabV1、DeepLabV2、DeepLabV3、DeepLabV3+、PSPNet、RefineNet、HRnet、Mask R-CNN、Segformer、DUCK-Net模型等
数据集总共有663对图片,数据质量非常高,甚至可应用到工业落地的项目中

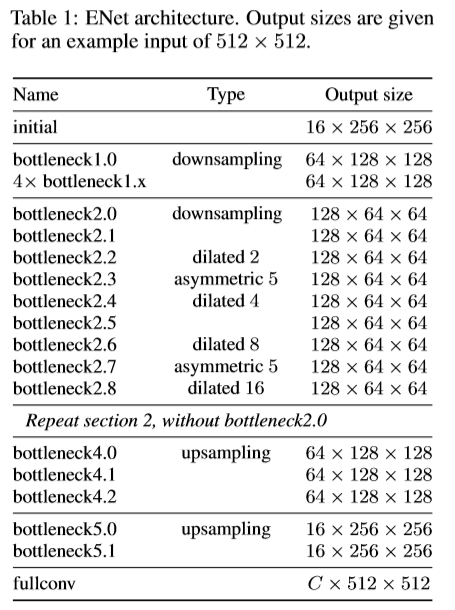
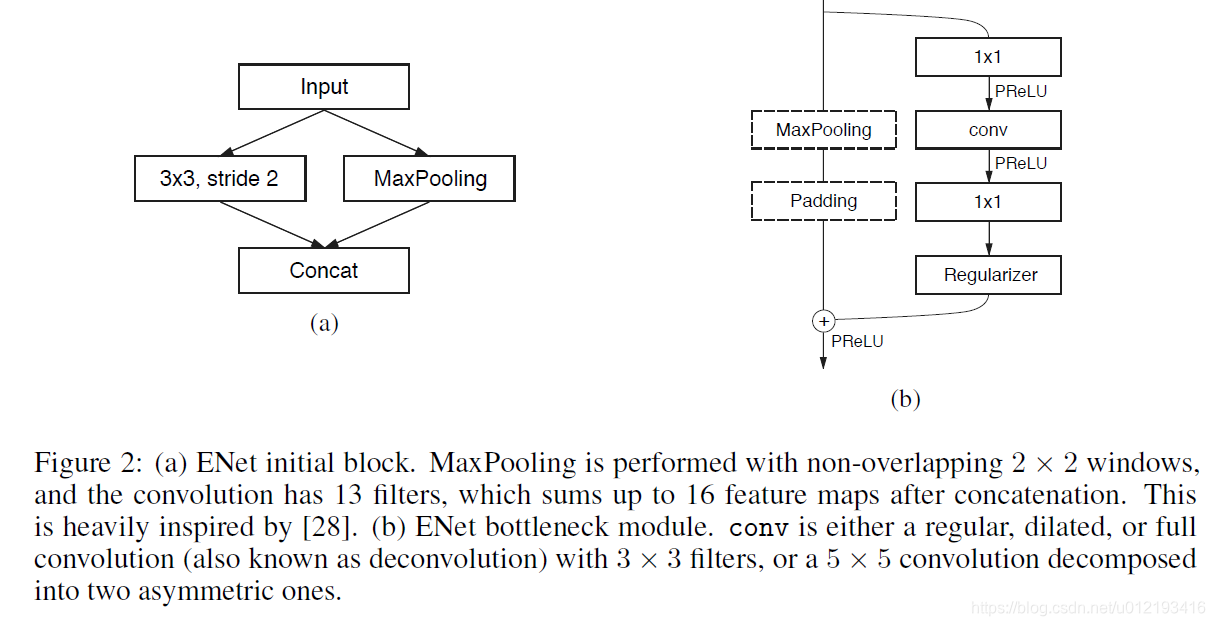
第二步:搭建模型
本文选择ENet,其网络结构分别如下:
第三步:训练代码
1)损失函数为:dice_loss + focal_loss
2)网络代码:
python
class ENet(nn.Module):
"""Generate the ENet model.
Keyword arguments:
- num_classes (int): the number of classes to segment.
- encoder_relu (bool, optional): When ``True`` ReLU is used as the
activation function in the encoder blocks/layers; otherwise, PReLU
is used. Default: False.
- decoder_relu (bool, optional): When ``True`` ReLU is used as the
activation function in the decoder blocks/layers; otherwise, PReLU
is used. Default: True.
"""
def __init__(self, num_classes, encoder_relu=False, decoder_relu=True):
super().__init__()
self.initial_block = InitialBlock(3, 16, relu=encoder_relu)
# Stage 1 - Encoder
self.downsample1_0 = DownsamplingBottleneck(
16,
64,
return_indices=True,
dropout_prob=0.01,
relu=encoder_relu)
self.regular1_1 = RegularBottleneck(
64, padding=1, dropout_prob=0.01, relu=encoder_relu)
self.regular1_2 = RegularBottleneck(
64, padding=1, dropout_prob=0.01, relu=encoder_relu)
self.regular1_3 = RegularBottleneck(
64, padding=1, dropout_prob=0.01, relu=encoder_relu)
self.regular1_4 = RegularBottleneck(
64, padding=1, dropout_prob=0.01, relu=encoder_relu)
# Stage 2 - Encoder
self.downsample2_0 = DownsamplingBottleneck(
64,
128,
return_indices=True,
dropout_prob=0.1,
relu=encoder_relu)
self.regular2_1 = RegularBottleneck(
128, padding=1, dropout_prob=0.1, relu=encoder_relu)
self.dilated2_2 = RegularBottleneck(
128, dilation=2, padding=2, dropout_prob=0.1, relu=encoder_relu)
self.asymmetric2_3 = RegularBottleneck(
128,
kernel_size=5,
padding=2,
asymmetric=True,
dropout_prob=0.1,
relu=encoder_relu)
self.dilated2_4 = RegularBottleneck(
128, dilation=4, padding=4, dropout_prob=0.1, relu=encoder_relu)
self.regular2_5 = RegularBottleneck(
128, padding=1, dropout_prob=0.1, relu=encoder_relu)
self.dilated2_6 = RegularBottleneck(
128, dilation=8, padding=8, dropout_prob=0.1, relu=encoder_relu)
self.asymmetric2_7 = RegularBottleneck(
128,
kernel_size=5,
asymmetric=True,
padding=2,
dropout_prob=0.1,
relu=encoder_relu)
self.dilated2_8 = RegularBottleneck(
128, dilation=16, padding=16, dropout_prob=0.1, relu=encoder_relu)
# Stage 3 - Encoder
self.regular3_0 = RegularBottleneck(
128, padding=1, dropout_prob=0.1, relu=encoder_relu)
self.dilated3_1 = RegularBottleneck(
128, dilation=2, padding=2, dropout_prob=0.1, relu=encoder_relu)
self.asymmetric3_2 = RegularBottleneck(
128,
kernel_size=5,
padding=2,
asymmetric=True,
dropout_prob=0.1,
relu=encoder_relu)
self.dilated3_3 = RegularBottleneck(
128, dilation=4, padding=4, dropout_prob=0.1, relu=encoder_relu)
self.regular3_4 = RegularBottleneck(
128, padding=1, dropout_prob=0.1, relu=encoder_relu)
self.dilated3_5 = RegularBottleneck(
128, dilation=8, padding=8, dropout_prob=0.1, relu=encoder_relu)
self.asymmetric3_6 = RegularBottleneck(
128,
kernel_size=5,
asymmetric=True,
padding=2,
dropout_prob=0.1,
relu=encoder_relu)
self.dilated3_7 = RegularBottleneck(
128, dilation=16, padding=16, dropout_prob=0.1, relu=encoder_relu)
# Stage 4 - Decoder
self.upsample4_0 = UpsamplingBottleneck(
128, 64, dropout_prob=0.1, relu=decoder_relu)
self.regular4_1 = RegularBottleneck(
64, padding=1, dropout_prob=0.1, relu=decoder_relu)
self.regular4_2 = RegularBottleneck(
64, padding=1, dropout_prob=0.1, relu=decoder_relu)
# Stage 5 - Decoder
self.upsample5_0 = UpsamplingBottleneck(
64, 16, dropout_prob=0.1, relu=decoder_relu)
self.regular5_1 = RegularBottleneck(
16, padding=1, dropout_prob=0.1, relu=decoder_relu)
self.transposed_conv = nn.ConvTranspose2d(
16,
num_classes,
kernel_size=3,
stride=2,
padding=1,
bias=False)
def forward(self, x):
# Initial block
input_size = x.size()
x = self.initial_block(x)
# Stage 1 - Encoder
stage1_input_size = x.size()
x, max_indices1_0 = self.downsample1_0(x)
x = self.regular1_1(x)
x = self.regular1_2(x)
x = self.regular1_3(x)
x = self.regular1_4(x)
# Stage 2 - Encoder
stage2_input_size = x.size()
x, max_indices2_0 = self.downsample2_0(x)
x = self.regular2_1(x)
x = self.dilated2_2(x)
x = self.asymmetric2_3(x)
x = self.dilated2_4(x)
x = self.regular2_5(x)
x = self.dilated2_6(x)
x = self.asymmetric2_7(x)
x = self.dilated2_8(x)
# Stage 3 - Encoder
x = self.regular3_0(x)
x = self.dilated3_1(x)
x = self.asymmetric3_2(x)
x = self.dilated3_3(x)
x = self.regular3_4(x)
x = self.dilated3_5(x)
x = self.asymmetric3_6(x)
x = self.dilated3_7(x)
# Stage 4 - Decoder
x = self.upsample4_0(x, max_indices2_0, output_size=stage2_input_size)
x = self.regular4_1(x)
x = self.regular4_2(x)
# Stage 5 - Decoder
x = self.upsample5_0(x, max_indices1_0, output_size=stage1_input_size)
x = self.regular5_1(x)
x = self.transposed_conv(x, output_size=input_size)
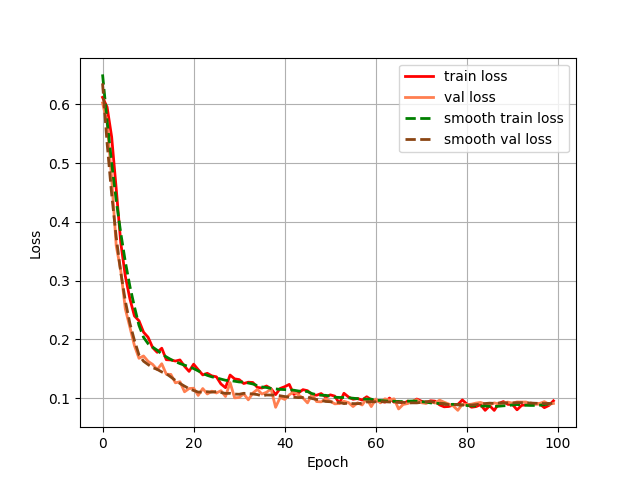
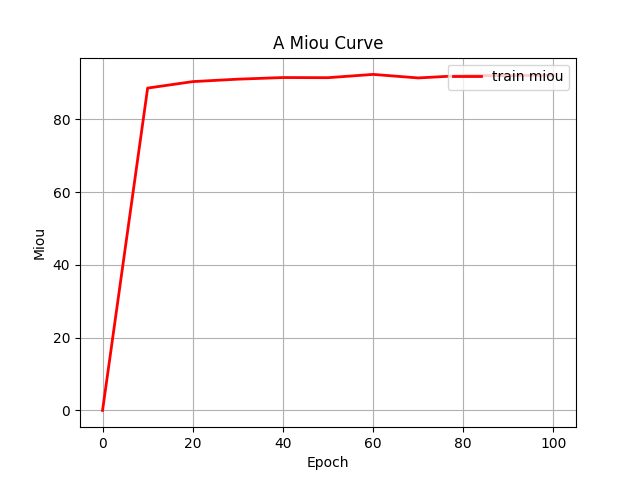
return x第四步:统计一些指标(训练过程中的loss和miou)

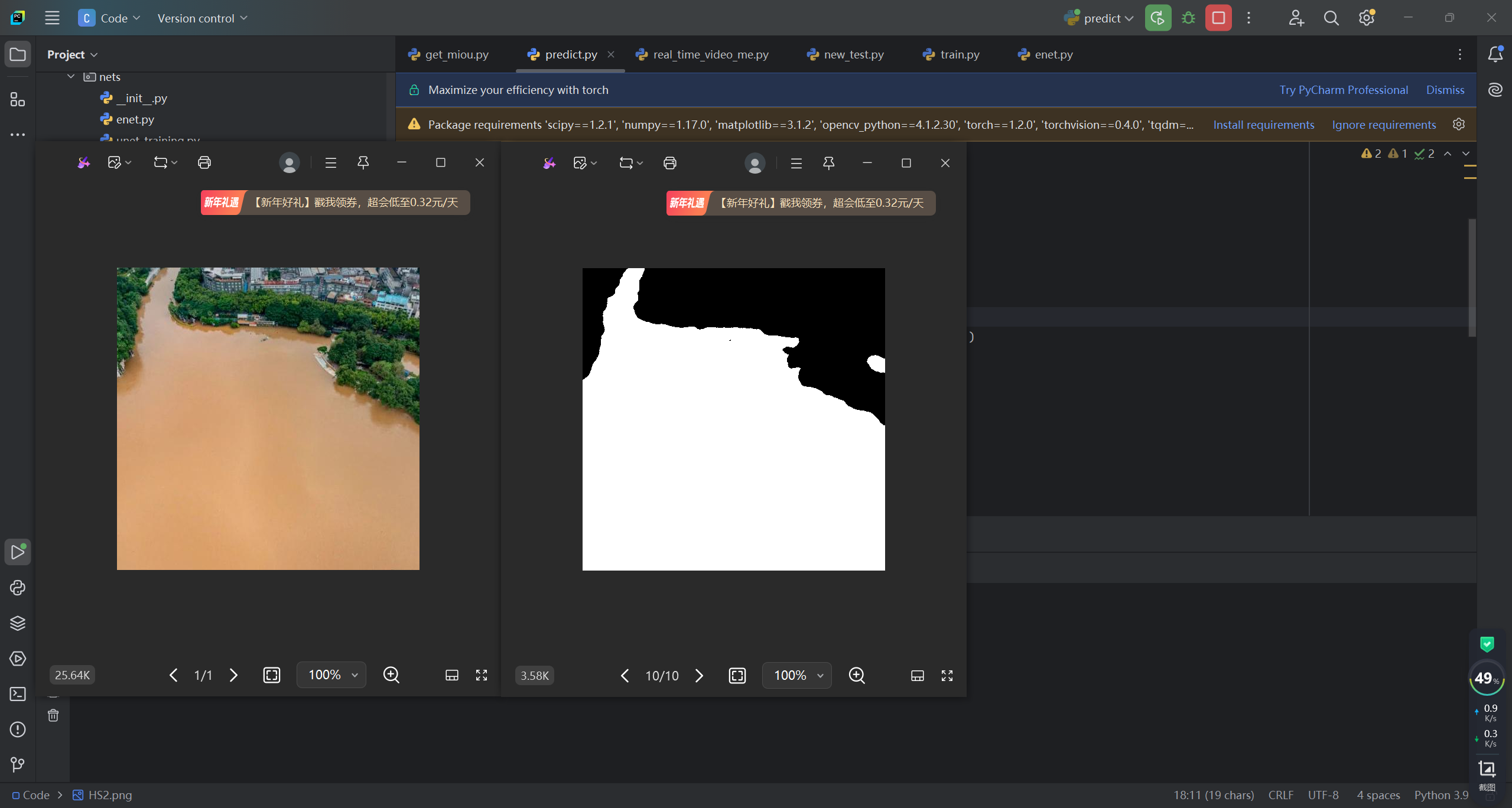
第五步:推理预测代码
第六步:整个工程的内容
项目完整文件下载请见演示与介绍视频的简介处给出:➷➷➷