HOG特征提取+SVM分类器
1、Hog特征提取过程
步骤 1:预处理图像 (标准化,提升鲁棒性)
①转灰度图:丢弃颜色信息(颜色对目标检测无核心帮助,还会增加计算量)。
②Gamma 校正(可选):对图像做灰度值非线性变换,抑制光照变化的影响(比如过亮、过暗区域的细节保留)。
③裁剪或缩放:将图像块调整为 winSize(64x64)尺寸(对应训练 / 检测的窗口大小),保证特征提取的一致性。
步骤 2:计算图像梯度 (提取边缘 / 纹理信息,梯度能反映图像的边缘、纹理变化,目标的轮廓就是强梯度区域,这是 HOG 特征的核心来源)
①对每个像素点,分别计算水平梯度(x 方向)和垂直梯度(y 方向)(常用 Sobel 算子或简单差分法)。
②由每个像素的 x、y 梯度,计算两个关键值:
梯度幅值:反映梯度的强度(边缘的清晰程度)。
梯度方向:反映边缘的朝向(范围 0-180° 或 0-360°)
最终得到两张和原图尺寸一致的「梯度幅值图」和「梯度方向图」。
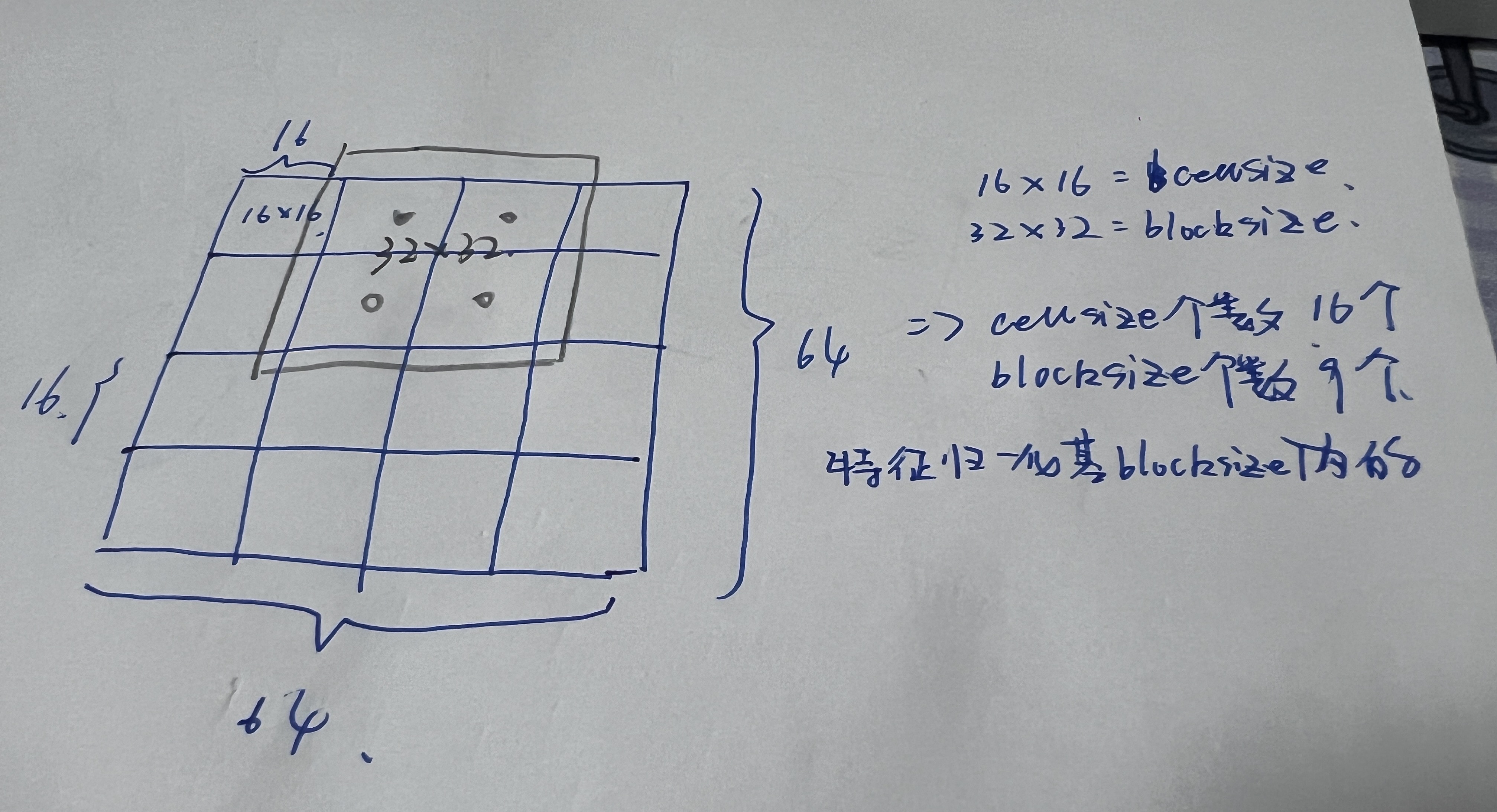
步骤 3:细胞单元(cellSize)构建梯度直方图(量化特征)
①将 winSize梯度幅度图和梯度方向图按 cellSize分别划分为多个独立细胞单元;
②对每个细胞单元内的所有像素,构建直方图( 区间个数nbins);其中梯度方向决定哪个区间计数,梯度幅值决定计数的权重。
③每个细胞单元最终得到一个长度为 nbins的一维数组,这是最基础的局部特征,反映该区域的纹理方向分布。
步骤 4:将相邻的多个细胞单元组合成一个块(Block),Block内特征归一化。
块的滑动步长为 blockStride,在 winSize 窗口内滑动,对每个块内的所有细胞直方图进行归一化处理(常用 L2 归一化),消除光照、对比度变化带来的特征偏差(比如同一目标在亮处和暗处的梯度幅值差异)。
步骤 5:拼接所有块特征,得到一位数组即最终 HOG 特征向量。
如果不打算细究具体的实现算法,我理解Hog特征就是基于图像的梯度与局部梯度的直方图经过一系列计算的新向量化表示。
2、SVM分类器判断
下文详解
3、非极大值抑制(NMS)
非极大值抑制(NMS)的唯一核心作用是去除目标检测过程中产生的大量重复、重叠的候选检测框,只保留置信度最高、最具代表性的那个框;属于 目标检测的推理 / 检测阶段
4、绘制边框,得到检测结果
使用二分类模型实现目标检测原理:
SVM 本身确实只是二分类模型,它完全没有能力直接预测目标的坐标值,最终能得到检测框坐标,是「HOG + 滑动窗口 + 多尺度缩放」这套组合流程的功劳,SVM 只在其中承担「分类判断」的单一角色。
第一步:SVM 的训练阶段(只做二分类,和坐标无关)
训练时,只给 SVM 喂两种数据,让它学习「是目标」和「不是目标」的区分:
正样本:裁剪好的「仅包含目标」的图像块(尺寸和 HOG 的 winSize 一致,比如 64x64),提取 HOG 特征后,标注为「1」(是目标)。
负样本:不包含目标的图像块(尺寸同样 64x64),提取 HOG 特征后,标注为「-1」(不是目标)。
训练完成后,这个 SVM 只有一个能力:输入一个 64x64 图像块的 HOG 特征,返回一个分类结果(是目标 / 不是目标),附带一个置信度得分,它完全不知道这个图像块来自整张图片的哪个位置。
第二步:检测阶段(滑动窗口 + 多尺度,让 SVM "间接" 产出坐标)
检测时,坐标不是 SVM 预测的,而是「滑动窗口」遍历图像时的「窗口位置」决定的,流程如下:
固定尺寸滑动窗口(遍历单张图)
以 HOG 的 winSize(64x64)为窗口大小,以一定步长(比如 16 像素),在整张输入图片上「从左到右、从上到下」滑动。
每滑动到一个位置,就裁剪出这个窗口对应的 64x64 图像块,提取 HOG 特征。
把这个 HOG 特征输入给训练好的 SVM,让 SVM 做二分类判断:「这个窗口里是目标吗?」。
如果 SVM 判断「是目标」(置信度得分较高),就记录下「这个窗口在整张图上的左上角坐标 + 窗口尺寸(64x64)」,这就是最初的检测框坐标(x, y, w, h)。
多尺度缩放(解决不同大小的目标)
因为目标在图片中可能有大有小(比如近处的人更大,远处的人更小),固定 64x64 窗口无法检测到所有尺寸的目标。
所以会先把输入图片按不同比例缩放(比如缩小为 0.8 倍、0.6 倍...),形成一组「多尺度图像金字塔」。
对每一张缩放后的图像,都执行上面的「滑动窗口 + SVM 分类」流程,收集所有 SVM 判断为「是目标」的窗口位置。
最终坐标整合
所有尺度下的窗口,都会映射回原始图片的尺寸(还原缩放带来的坐标偏差),形成最终的 locations 检测框列表。
hog.detectMultiScale() 其实已经封装了「滑动窗口 + 多尺度缩放 + SVM 分类 + 坐标还原」这一系列操作,所以直接返回了可用的检测框坐标。
注意:
1.HOG 参数
HOG 有多个参数,包括窗口大小、块(block)大小、单元格(cell)大小等。这些参数同时影响边界框的尺寸和宽高比。如果候选框的尺寸不同,可能需要进行尺寸调整。
2.旋转敏感性
HOG 对图像旋转非常敏感,因此如果图像发生倾斜,提取的特征向量可能不适用于目标检测。
3.同一对象的差异性
即便是同一个目标,不同的边界框也可能生成不同的 HOG 向量。因此,需要借助机器学习模型判断目标是否被正确检测到。
数据集-VOC
xml
<!-- 典型Pascal VOC标注文件结构 -->
<annotation>
<folder>VOC2012</folder>
<filename>2007_000027.jpg</filename> <!-- ← 从这里提取 -->
<size>
<width>486</width>
<height>500</height>
<depth>3</depth>
</size>
<object> <!-- ← 每个object标签对应一个目标 -->
<name>person</name> <!-- ← 目标类别 -->
<bndbox> <!-- ← 边界框坐标(关键!) -->
<xmin>174</xmin> <!-- ← 提取 -->
<ymin>101</ymin> <!-- ← 提取 -->
<xmax>349</xmax> <!-- ← 提取 -->
<ymax>351</ymax> <!-- ← 提取 -->
</bndbox>
</object>
<object>
<!-- 可以有多个object -->
</object>
</annotation>提取关键信息
python
def read_voc_xml(xmlfile):
root = ET.parse(xmlfile).getroot()
boxes = {"filename": root.find("filename").text,
"objects": []}
for box in root.iter('object'):
bb = box.find('bndbox')
obj = {
"name": box.find('name').text,
"xmin": int(bb.find("xmin").text),
"ymin": int(bb.find("ymin").text),
"xmax": int(bb.find("xmax").text),
"ymax": int(bb.find("ymax").text),
}
boxes["objects"].append(obj)
return boxesHog特征提取与SVM训练
python
import xml.etree.ElementTree as ET
import glob
import cv2
import random
import sklearn.svm as svm
import pickle
import numpy as np
import time
if __name__ == "__main__":
data_path = 'F:\\ObjectDetection\\oxford-iiit-pet\\annotations\\xmls\\'
data_xmls = glob.glob(data_path + '*.xml')
img_path = 'F:\\ObjectDetection\\oxford-iiit-pet\\images\\'
winSize = (64, 64)
blockSize = (32, 32)
blockStride = (16, 16)
cellSize = (16, 16)
nbins = 9
num_samples = 10000
positive = [] # 猫
negative = [] # 其他动物
for xml in data_xmls:
result = read_voc_xml(xml)
if result['objects'][0]['name'] != 'cat':
continue
object = result['objects'][0]
img = img_path + result['filename']
img = cv2.imread(img)
xmin, xmax, ymin, ymax = object["xmin"], object["xmax"], object["ymin"], object["ymax"]
xmin, xmax, ymin, ymax = make_square(xmin, xmax, ymin, ymax)
sample = img[ymin:ymax, xmin:xmax]
sample = cv2.resize(sample, winSize)
positive.append(sample)
if len(positive) >= num_samples:
print('--------- positive success ---------')
break
for xmlfile in data_xmls:
result = read_voc_xml(xmlfile)
if result["objects"][0]["name"] == "cat":
continue
object = result['objects'][0]
img = img_path + result['filename']
img = cv2.imread(img)
height, width = img.shape[:2]
boxsize = random.randint(winSize[0], min(height, width))
x = random.randint(0, width - boxsize)
y = random.randint(0, height - boxsize)
sample = img[y:y + boxsize, x:x + boxsize]
sample = cv2.resize(sample, winSize)
negative.append(sample)
if len(negative) >= num_samples:
print('--------- negative success ---------')
break
images = positive + negative
labels = ([1] * len(positive) + [0] * len(negative))
hog = cv2.HOGDescriptor(winSize, blockSize, blockStride, cellSize, nbins)
data = []
for img in images:
features = hog.compute(img)
data.append(features.flatten())
data = np.array(data, dtype=np.float32)
labels = np.array(labels, dtype=np.int32)
print('--------- svm start ---------')
ts = time.time()
svm = cv2.ml.SVM_create()
svm.setType(cv2.ml.SVM_C_SVC) # 用于设置 SVM 的模型类型,决定 SVM 适用的任务场景,引入惩罚参数 C(后续可额外配置),允许少量样本违反间隔约束,用于解决线性不可分问题,提升模型的泛化能力。
svm.setKernel(cv2.ml.SVM_RBF) # 核函数的作用是将低维线性不可分的数据映射到高维空间,使其在高维空间中线性可分;径向基函数(Radial Basis Function),也称为高斯核,是最常用的非线性核函数
svm.setTermCriteria((cv2.TERM_CRITERIA_MAX_ITER + cv2.TERM_CRITERIA_EPS, 100000, 1e-8)) # 设置 SVM 训练过程的终止条件;「最大迭代次数」或「精度收敛」任一条件即终止
svm.train(data,
cv2.ml.ROW_SAMPLE, # 指定样本数据的组织格式,表示每一行对应一个训练样本,每一列对应一个特征(这是最常用的数据组织方式,符合大多数人的数据预处理习惯
labels)
te = time.time() - ts
# 保存模型
svm.save('F:\\ObjectDetection\\save_model\\svm_model.yml')
print(svm.getSupportVectors().shape)
print('--------- svm end ---------')
print('fit time: {}s'.format(te))测试代码
python
import glob
import cv2
import xml.etree.ElementTree as ET
if __name__ == "__main__":
data_path = 'F:\\ObjectDetection\\oxford-iiit-pet\\annotations\\xmls\\'
data_xmls = glob.glob(data_path + '*.xml')
img_path = 'F:\\ObjectDetection\\oxford-iiit-pet\\images\\'
model_path = 'F:\\ObjectDetection\\save_model\\svm_model.yml'
winSize = (64, 64) # 检测从窗口大小,即每次提取HOG特征的图像块大小,训练的时候是将图像按照标注提取出目标区域resize到winSize
blockSize = (32, 32) # 块大小, HOG特征以块为单位进行归一化,减少光照等因素影响
blockStride = (16, 16) # 快步长,相邻块之间的偏移量,巨鼎了块的覆盖密度
cellSize = (16, 16) # 细胞单元大小,每个细胞单元内计算梯度方向直方图
nbins = 9 # 梯度方向直方图的分箱树,即把 0~180°(或 0~360°)梯度方向划分为 9 个区间,统计每个区间的梯度幅值
svm = cv2.ml.SVM_load(model_path)
hog = cv2.HOGDescriptor(winSize, blockSize, blockStride, cellSize, nbins) # 创建 HOG 特征描述符实例
hog.setSVMDetector(svm.getSupportVectors()[0]) # SVM 模型的支持向量设置为 HOG 检测器的分类器,让HOG提取特征后可直接用该 SVM 进行目标分类/检测
for data_xml in data_xmls[:5]:
result = read_voc_xml(data_xml)
img = cv2.imread(img_path + result['filename'])
bbox = result['objects'][0]
start_point = (bbox['xmin'], bbox['ymin']) # 真实框左上角坐标
end_point = (bbox['xmax'], bbox['ymax']) # 真实框右下角坐标
annotated_img = cv2.rectangle(img, start_point, end_point, (0,0,255)) # 绘制矩形框,参数依次是「图片」「左上角坐标」「右下角坐标」「颜色(BGR 格式,(0,0,255) 对应红色)」,默认线宽为 1
locations, scores = hog.detectMultiScale(img) # 用 HOG+SVM 对图片进行多尺度目标检测,自动缩放图片;locations:所有检测到的目标边界框坐标(x, y, w, h)左上坐标+宽高,scores:对应每个检测框的置信度得分,得分越高,检测结果越可靠。
# ------------ 选择置信度最高的------------
# x, y, w, h = locations[np.argmax(scores.flatten())] # 选取检测得分最高的边界框(取 scores 最大值对应的位置)
# cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 5)
# cv2.imshow(f"{result['filename']}: {result['objects'][0]['name']}", annotated_img)
# key = cv2.waitKey(0)
# cv2.destroyAllWindows()
# if key == ord('q'):
# break
# ------------ 使用NMS ------------
boxes = locations.tolist()
confidences = scores.flatten().tolist()
indices = cv2.dnn.NMSBoxes(boxes, confidences,
score_threshold=0.5, # 信度阈值:过滤掉得分低于 0.5 的低质量框
nms_threshold=0.3 # IOU 阈值:重叠度超过 0.3 的框,保留得分最高的,去除其他
)
if len(indices) > 0:
# 兼容 OpenCV 返回格式,提取有效索引
indices = indices.flatten()
# 取第一个最优框(也可遍历所有筛选后的框)
best_idx = indices[0]
x, y, w, h = boxes[best_idx]
# 绘制筛选后的检测框
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 5)
cv2.imshow(f"{result['filename']}: {result['objects'][0]['name']}", annotated_img)
key = cv2.waitKey(0)
cv2.destroyAllWindows()
if key == ord('q'):
break需要运行的,路径和import自己改一下哈。有不正确的地方请指出!