目录
[1.1 核心功能概述](#1.1 核心功能概述)
[1.2 完整实战代码](#1.2 完整实战代码)
[1.3 代码逐模块详细解析](#1.3 代码逐模块详细解析)
[1.3.1 基础模块(复用+简单补充)](#1.3.1 基础模块(复用+简单补充))
[1.3.2 视频采集与预处理(完全复用,简要说明)](#1.3.2 视频采集与预处理(完全复用,简要说明))
[1.3.3 核心:手势判断逻辑(新增重点)](#1.3.3 核心:手势判断逻辑(新增重点))
[1.3.4 手势显示与程序退出(新增显示逻辑)](#1.3.4 手势显示与程序退出(新增显示逻辑))
[2.1 核心功能概述](#2.1 核心功能概述)
[2.2 完整实战代码](#2.2 完整实战代码)
[2.3 代码逐模块详细解析](#2.3 代码逐模块详细解析)
[2.3.1 库导入与姿态检测器初始化(核心新增)](#2.3.1 库导入与姿态检测器初始化(核心新增))
[2.3.2 静态图片读取与预处理](#2.3.2 静态图片读取与预处理)
[2.3.3 关键点坐标输出与可视化](#2.3.3 关键点坐标输出与可视化)
[2.3.4 3D姿态可视化(新增亮点)](#2.3.4 3D姿态可视化(新增亮点))
[2.3.5 程序退出与资源释放](#2.3.5 程序退出与资源释放)
[三、MediaPipe脸部关键点检测(Face Mesh)](#三、MediaPipe脸部关键点检测(Face Mesh))
[3.1 核心功能概述](#3.1 核心功能概述)
[3.2 完整实战代码](#3.2 完整实战代码)
[3.3 代码逐模块详细解析](#3.3 代码逐模块详细解析)
[3.3.1 库导入与脸部网格初始化(核心新增)](#3.3.1 库导入与脸部网格初始化(核心新增))
[3.3.2 摄像头采集与视频预处理](#3.3.2 摄像头采集与视频预处理)
[3.3.3 核心:关键点标注与脸部网格绘制](#3.3.3 核心:关键点标注与脸部网格绘制)
在上一篇博客中,我们已经掌握了MediaPipe+OpenCV实现实时手部关键点检测的核心方法,了解了MediaPipe轻量化、高精度的优势,以及OpenCV与MediaPipe配合的关键要点。本节课我们将基于手部检测的基础,拓展学习MediaPipe的另外三个核心视觉检测功能------手势识别、人体姿态检测、脸部关键点检测,继续用实战代码拆解逻辑,帮大家快速上手MediaPipe的更多应用场景,夯实计算机视觉入门基础。
本文将保持和上一篇一致的结构,每一个功能都包含「核心功能概述→完整实战代码→逐模块详细解析→运行前置条件→新手避坑要点→功能拓展」,确保新手能跟着代码一步步操作,既能跑通效果,也能理解背后的逻辑,避免"复制粘贴式学习"。
一、MediaPipe手势识别(基于手部关键点的延伸)
手势识别是手部关键点检测的核心延伸应用,我们在上一篇手部关键点检测的基础上,通过计算关键点之间的距离,判断手指的伸直状态,进而实现0-10的手势计数(none~ten),可直接用于简单的数字交互、手势控制等场景。
1.1 核心功能概述
本次手势识别代码基于MediaPipe手部检测模块,实现以下核心功能:
-
调用电脑默认摄像头,采集实时视频流,实时检测画面中最多2只手的关键点;
-
通过计算特定关键点之间的距离,判断每根手指的伸直状态,用flag计数统计伸直的手指数量;
-
在视频画面上实时显示识别到的手势(none/one/two/.../ten),同时绘制手部关键点及骨骼连接;
-
支持ESC键退出识别,自动释放摄像头资源,兼容上一篇的基础配置,降低学习成本。
1.2 完整实战代码
python
import cv2
import mediapipe as mp
gesture = ["none", "one", "two", "three", "four", "five", "six", "seven", "eight", "nine", "ten"]
flag = 0
mp_drawing = mp.solutions.drawing_utils
mp_hands = mp.solutions.hands
hands = mp_hands.Hands(
static_image_mode=False,
max_num_hands=2,
min_detection_confidence=0.75,
min_tracking_confidence=0.75)
cap = cv2.VideoCapture(0)
while True:
flag = 0
ret, frame = cap.read()
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 因为摄像头是镜像的,所以将摄像头水平翻转
# 不是镜像的可以不翻转
frame = cv2.flip(frame, 1)
results = hands.process(frame)
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
# if results.multi_handedness:
# for hand_label in results.multi_handedness:
# print(hand_label)
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
# print('hand_landmarks:', hand_landmarks)
# 计算关键点的距离,用于判断手指是否伸直
p0_x = hand_landmarks.landmark[0].x
p0_y = hand_landmarks.landmark[0].y
p5_x = hand_landmarks.landmark[5].x
p5_y = hand_landmarks.landmark[5].y
distance_0_5 = pow(p0_x - p5_x, 2) + pow(p0_y - p5_y, 2)
base = distance_0_5 / 0.6
p4_x = hand_landmarks.landmark[4].x
p4_y = hand_landmarks.landmark[4].y
distance_5_4 = pow(p5_x - p4_x, 2) + pow(p5_y - p4_y, 2)
p8_x = hand_landmarks.landmark[8].x
p8_y = hand_landmarks.landmark[8].y
distance_0_8 = pow(p0_x - p8_x, 2) + pow(p0_y - p8_y, 2)
p12_x = hand_landmarks.landmark[12].x
p12_y = hand_landmarks.landmark[12].y
distance_0_12 = pow(p0_x - p12_x, 2) + pow(p0_y - p12_y, 2)
p16_x = hand_landmarks.landmark[16].x
p16_y = hand_landmarks.landmark[16].y
distance_0_16 = pow(p0_x - p16_x, 2) + pow(p0_y - p16_y, 2)
p20_x = hand_landmarks.landmark[20].x
p20_y = hand_landmarks.landmark[20].y
distance_0_20 = pow(p0_x - p20_x, 2) + pow(p0_y - p20_y, 2)
if distance_0_8 > base:
flag += 1
if distance_0_12 > base:
flag += 1
if distance_0_16 > base:
flag += 1
if distance_0_20 > base:
flag += 1
if distance_5_4 > base * 0.3:
flag += 1
if flag >= 10:
flag = 10
# 关键点可视化
mp_drawing.draw_landmarks(frame,
hand_landmarks,
mp_hands.HAND_CONNECTIONS)
cv2.putText(frame, gesture[flag], (50, 50), 0, 1.3, (0, 0, 255), 3)
cv2.imshow('MediaPipe Hands', frame)
if cv2.waitKey(1) & 0xFF == 27:
break
cap.release()
cv2.destroyAllWindows()效果展示: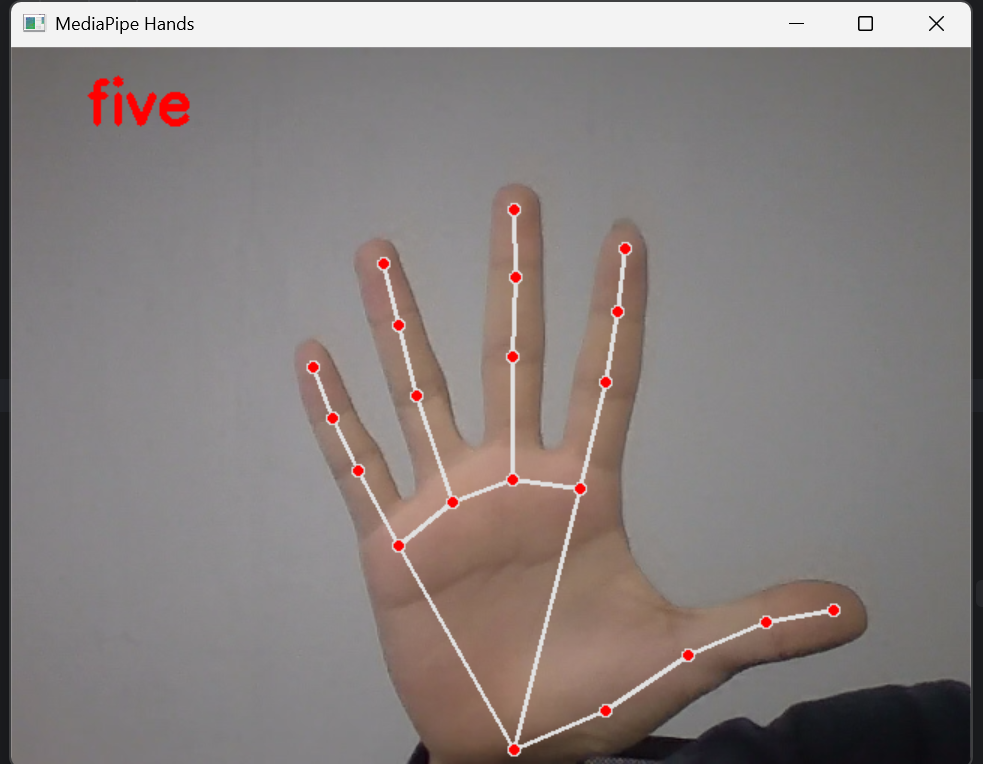
1.3 代码逐模块详细解析
手势识别代码基于上一篇的手部关键点检测,大部分基础模块(库导入、手部检测器初始化、视频采集)完全复用,重点新增了「手势判断逻辑」,我们重点解析新增部分,复用部分简要带过,避免冗余。
1.3.1 基础模块(复用+简单补充)
python
import cv2
import mediapipe as mp
gesture = ["none", "one", "two", "three", "four", "five", "six", "seven", "eight", "nine", "ten"]
flag = 0
mp_drawing = mp.solutions.drawing_utils
mp_hands = mp.solutions.hands
hands = mp_hands.Hands(
static_image_mode=False,
max_num_hands=2,
min_detection_confidence=0.75,
min_tracking_confidence=0.75)
cap = cv2.VideoCapture(0)新增核心变量解析(重点):
-
gesture = [...]:手势列表,索引0对应"无手势(none)",索引1对应"1根手指(one)",依次到索引10对应"10根手指(ten)"(实际最多5根手指,设到10是为了避免flag溢出,后续会做限制)。 -
flag = 0:手势计数标志,用于统计伸直的手指数量,初始值为0(默认无手势),每检测到一根伸直的手指,flag加1,最终通过flag索引gesture列表,得到识别结果。
其余模块(mp_drawing、mp_hands初始化、摄像头调用)与上一篇手部检测完全一致,参数含义可参考上一篇,此处不再重复解析,重点关注后续的手势判断逻辑。
1.3.2 视频采集与预处理(完全复用,简要说明)
python
while True:
flag = 0 # 每次循环重置flag,避免上一帧的计数影响当前帧
ret, frame = cap.read()
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) # BGR转RGB,适配MediaPipe
frame = cv2.flip(frame, 1) # 水平翻转,解决摄像头镜像问题
results = hands.process(frame) # 手部关键点检测
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR) # RGB转BGR,适配OpenCV显示重点注意:flag = 0 必须放在while循环内部(每帧重置),否则会导致flag持续累加(比如上一帧检测到2根手指,下一帧未检测到手,flag仍为2),造成手势识别错误。
1.3.3 核心:手势判断逻辑(新增重点)
手势判断的核心原理:通过计算「手指指尖关键点」与「手腕/指根关键点」之间的距离,判断手指是否伸直------距离大于设定的阈值,视为手指伸直,flag加1;距离小于阈值,视为手指弯曲,不计数。
python
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
# 1. 计算基准距离(手腕0号关键点与食指根5号关键点的距离)
p0_x = hand_landmarks.landmark[0].x
p0_y = hand_landmarks.landmark[0].y
p5_x = hand_landmarks.landmark[5].x
p5_y = hand_landmarks.landmark[5].y
distance_0_5 = pow(p0_x - p5_x, 2) + pow(p0_y - p5_y, 2)
base = distance_0_5 / 0.6 # 基准阈值,用于判断手指是否伸直
# 2. 计算各手指关键点距离(指尖与手腕/指根)
# 拇指:指根5号与指尖4号的距离
p4_x = hand_landmarks.landmark[4].x
p4_y = hand_landmarks.landmark[4].y
distance_5_4 = pow(p5_x - p4_x, 2) + pow(p5_y - p4_y, 2)
# 食指:手腕0号与指尖8号的距离
p8_x = hand_landmarks.landmark[8].x
p8_y = hand_landmarks.landmark[8].y
distance_0_8 = pow(p0_x - p8_x, 2) + pow(p0_y - p8_y, 2)
# 中指:手腕0号与指尖12号的距离
p12_x = hand_landmarks.landmark[12].x
p12_y = hand_landmarks.landmark[12].y
distance_0_12 = pow(p0_x - p12_x, 2) + pow(p0_y - p12_y, 2)
# 无名指:手腕0号与指尖16号的距离
p16_x = hand_landmarks.landmark[16].x
p16_y = hand_landmarks.landmark[16].y
distance_0_16 = pow(p0_x - p16_x, 2) + pow(p0_y - p16_y, 2)
# 小指:手腕0号与指尖20号的距离
p20_x = hand_landmarks.landmark[20].x
p20_y = hand_landmarks.landmark[20].y
distance_0_20 = pow(p0_x - p20_x, 2) + pow(p0_y - p20_y, 2)
# 3. 根据距离阈值,判断手指是否伸直,累加flag
if distance_0_8 > base: # 食指伸直
flag += 1
if distance_0_12 > base: # 中指伸直
flag += 1
if distance_0_16 > base: # 无名指伸直
flag += 1
if distance_0_20 > base: # 小指伸直
flag += 1
if distance_5_4 > base * 0.3: # 拇指伸直(阈值稍小,适配拇指结构)
flag += 1
if flag >= 10: # 限制最大flag为10(避免索引越界)
flag = 10
# 4. 手部关键点可视化(与上一篇一致)
mp_drawing.draw_landmarks(frame,
hand_landmarks,
mp_hands.HAND_CONNECTIONS)逐点解析(新手必看):
-
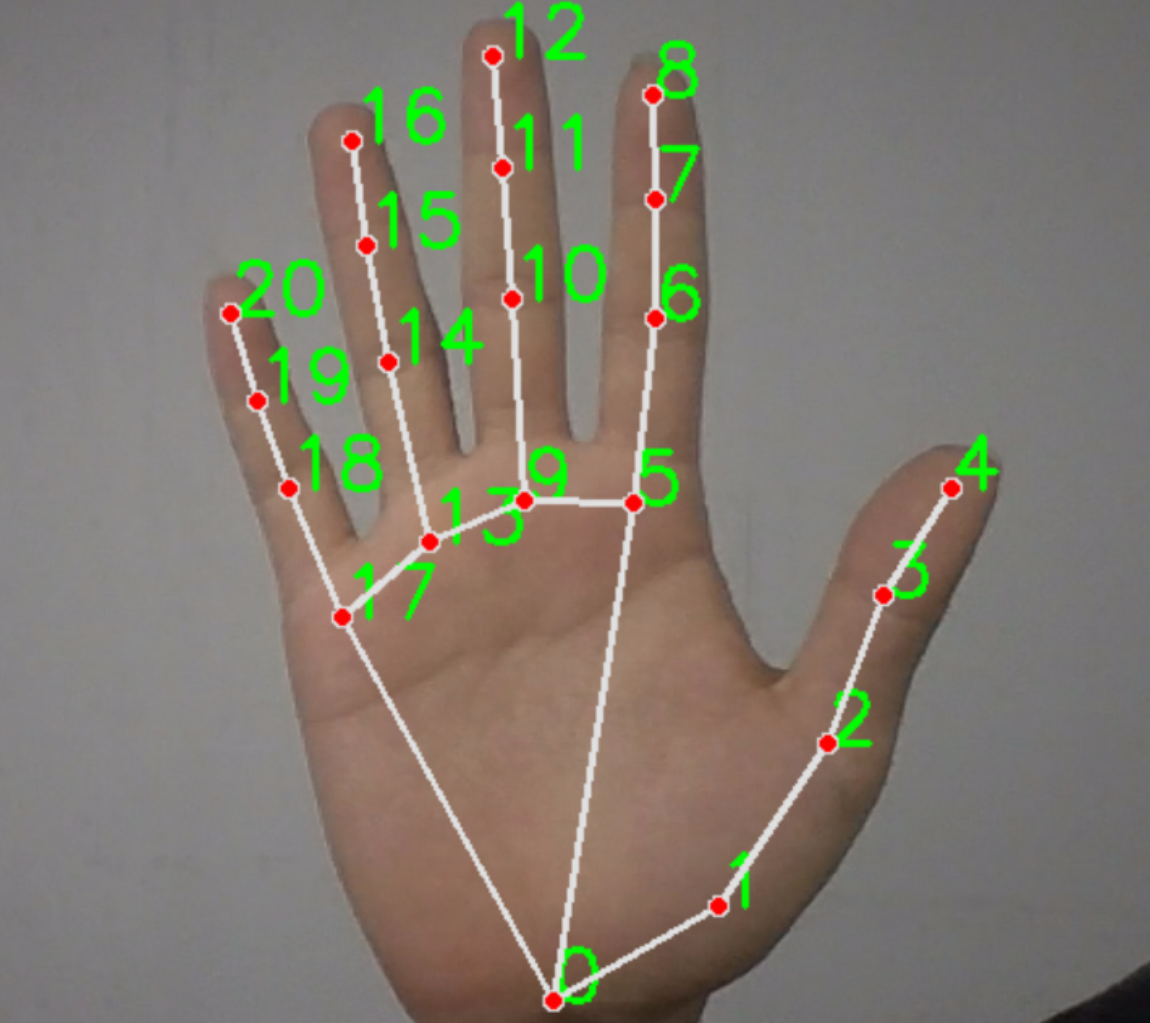
基准距离计算:选取「手腕0号关键点」和「食指根5号关键点」的欧氏距离(此处用平方和替代,避免开方运算,提升速度),除以0.6得到base基准阈值。基准阈值的作用是:适配不同距离的手势(比如手靠近摄像头时,关键点距离变大,base也会变大;手远离时,base变小),避免因距离变化导致识别错误。
-
各手指距离计算:
-
拇指:特殊处理,计算「指根5号」与「指尖4号」的距离(因为拇指与手腕的距离过近,无法准确判断);
-
食指、中指、无名指、小指:统一计算「手腕0号」与「各自指尖(8、12、16、20号)」的距离,逻辑更简单,识别更稳定。
-
-
手指伸直判断:
-
食指~小指:距离大于base,视为伸直;
-
拇指:距离大于base×0.3,视为伸直(拇指结构特殊,伸直时与指根的距离比其他手指小,所以阈值适当缩小);
-
flag累加后限制为10,因为gesture列表最大索引为10,避免flag溢出导致程序报错。
-
1.3.4 手势显示与程序退出(新增显示逻辑)
python
cv2.putText(frame, gesture[flag], (50, 50), 0, 1.3, (0, 0, 255), 3)
cv2.imshow('MediaPipe Hands', frame)
if cv2.waitKey(1) & 0xFF == 27:
break
cap.release()
cv2.destroyAllWindows()新增部分:cv2.putText(...),在视频画面的(50,50)位置,用红色(0,0,255)、字号1.3、线条粗细3的字体,显示当前识别到的手势(gestureflag),让识别结果直观可见。其余退出逻辑、资源释放与上一篇完全一致。
二、MediaPipe人体姿态检测(全身关键点定位)
人体姿态检测是MediaPipe另一核心功能,可实时检测人体33个关键点(涵盖头部、躯干、四肢),用于动作识别、健身计数、姿态矫正等场景。与手部检测、手势识别不同,姿态检测支持静态图片和动态视频两种模式,本次代码以静态图片检测为例,后续可轻松拓展为实时视频检测。
2.1 核心功能概述
-
读取本地静态图片(img.png),检测图片中人体的33个关键点;
-
打印每个关键点的三维坐标(x、y归一化坐标,z深度坐标),统计关键点总数;
-
在原图上绘制人体关键点及骨骼连接线条,生成带关键点标注的图片;
-
生成人体姿态的3D可视化图表,直观查看关键点的空间位置关系;
-
支持按键退出,自动释放窗口资源,代码结构清晰,新手易上手。
2.2 完整实战代码
python
import cv2
import mediapipe as mp
if __name__ == '__main__':
'''
mp_pose.Pose()其参数:
1)static_image_mode:静态图像还是连续帧视频;
2)model_complexity:人体姿态估计模型,0表示速度最快,精度最低(三者之中),1表示速度中间,精度中间(三者之中),2表示速度最慢,精度最高(三者之中);
3)smooth_landmarks:是否平滑关键点;
4)enable_segmentation:是否对人体进行抠图;
5)min_detection_confidence:检测置信度阈值;
6)min_tracking_confidence:各帧之间跟踪置信度阈值;
'''
mp_pose = mp.solutions.pose
pose = mp_pose.Pose(static_image_mode=True,
model_complexity=1,
smooth_landmarks=True,
# enable_segmentation=True,
min_detection_confidence=0.5,
min_tracking_confidence=0.5)
drawing = mp.solutions.drawing_utils
# read img BGR to RGB
img = cv2.imread("img.png")
cv2.imshow("input", img)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
results = pose.process(img)
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
print(len(results.pose_landmarks.landmark))
for i in range(len(results.pose_landmarks.landmark)):
x=results.pose_landmarks.landmark[i].x
y=results.pose_landmarks.landmark[i].y
z=results.pose_landmarks.landmark[i].z
print(x,y,z)
drawing.draw_landmarks(img, results.pose_landmarks, mp_pose.POSE_CONNECTIONS)
cv2.imshow("keypoint", img)
drawing.plot_landmarks(results.pose_world_landmarks, mp_pose.POSE_CONNECTIONS)
cv2.waitKey(0)
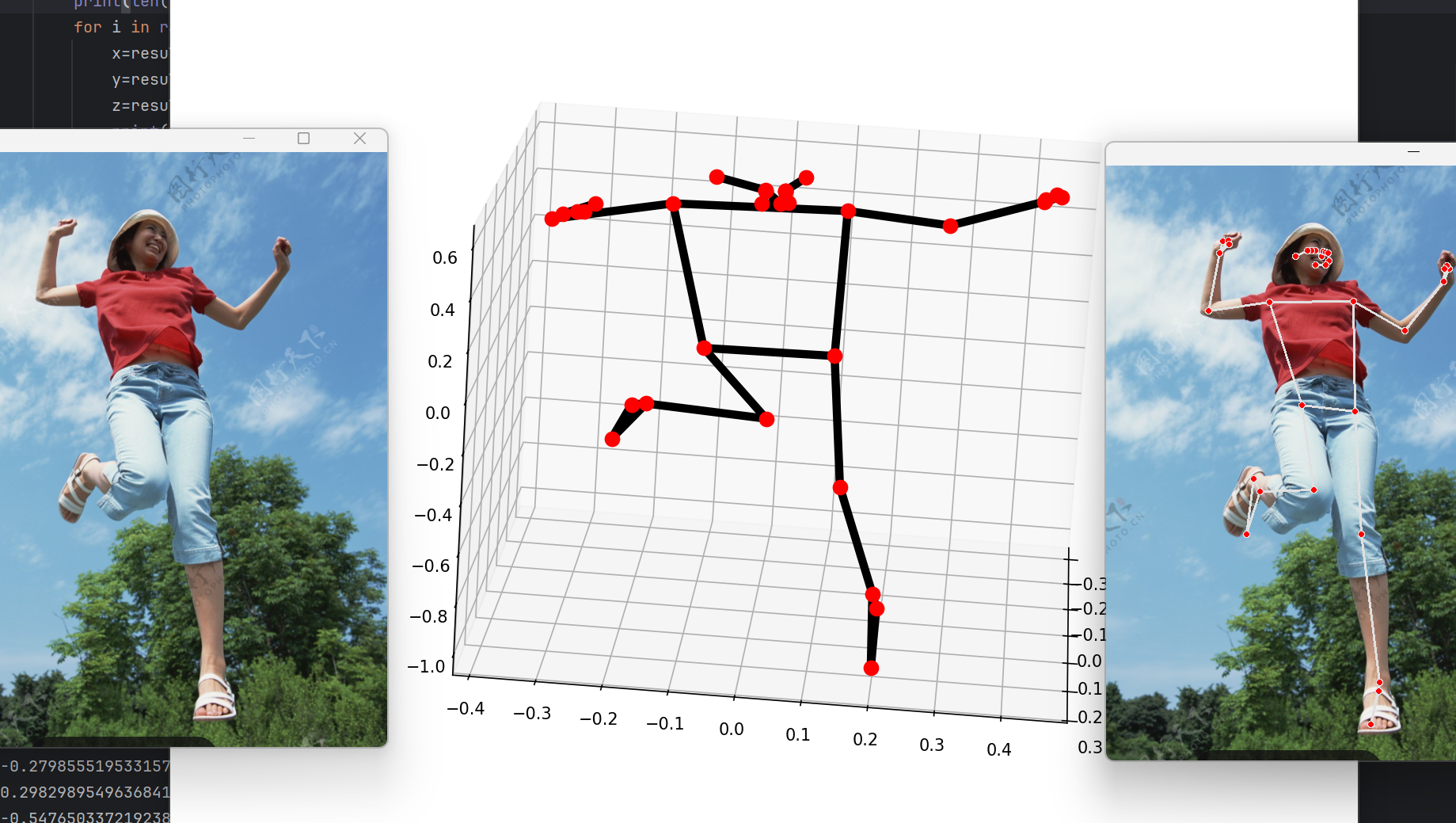
cv2.destroyAllWindows()效果展示:
2.3 代码逐模块详细解析
姿态检测使用MediaPipe的mp_pose模块,与手部检测模块(mp_hands)逻辑相似,但参数和关键点更多,重点解析姿态检测专属的模块和参数,基础模块(库导入、颜色转换)简要带过。
2.3.1 库导入与姿态检测器初始化(核心新增)
python
import cv2
import mediapipe as mp
if __name__ == '__main__':
mp_pose = mp.solutions.pose # 导入姿态检测核心模块
pose = mp_pose.Pose(static_image_mode=True,
model_complexity=1,
smooth_landmarks=True,
# enable_segmentation=True,
min_detection_confidence=0.5,
min_tracking_confidence=0.5)
drawing = mp.solutions.drawing_utils # 绘图工具,与手部检测一致核心解析:
-
mp_pose = mp.solutions.pose:MediaPipe姿态检测核心模块,内置33个人体关键点检测模型,支持静态图片和动态视频两种模式,模型采用BlazePose架构,兼顾精度和速度。 -
pose = mp_pose.Pose(...):初始化姿态检测器,6个核心参数(新手重点关注前4个),详细说明如下:-
static_image_mode:检测模式,True为静态图片模式(本次使用),False为动态视频模式。静态模式下,每帧都重新检测关键点;动态模式下,会跟踪已检测到的人体,提升帧率。 -
model_complexity:模型复杂度(0/1/2),权衡速度和精度:-
0:速度最快,精度最低,适合低性能设备(如树莓派);
-
1:速度和精度均衡(默认),适合普通电脑;
-
2:速度最慢,精度最高,适合对精度要求高的场景(如专业动作识别)。
-
-
smooth_landmarks:是否平滑关键点,True表示平滑(减少关键点抖动,提升稳定性),False表示不平滑(适合静态图片,影响不大)。 -
enable_segmentation:是否对人体进行抠图(分离人体和背景),True表示启用抠图,会生成人体掩码,可用于背景替换等场景;本次注释掉,暂不启用。 -
min_detection_confidence:最小检测置信度(0.0~1.0),与手部检测一致,值越大,检测越精准,越难检测到人体。 -
min_tracking_confidence:最小追踪置信度(0.0~1.0),仅动态模式(static_image_mode=False)生效,值越大,追踪越稳定。
-
-
drawing = mp.solutions.drawing_utils:绘图工具,用于绘制人体关键点和骨骼连接,与手部检测、手势识别完全一致,无需修改。
2.3.2 静态图片读取与预处理
python
# 读取本地图片,OpenCV默认BGR格式
img = cv2.imread("img.png")
cv2.imshow("input", img) # 显示原始图片
# 颜色空间转换:BGR→RGB,适配MediaPipe
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 执行姿态检测
results = pose.process(img)
# 颜色空间转换:RGB→BGR,适配OpenCV显示
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)新手必注意:
-
cv2.imread("img.png"):读取本地图片,需确保"img.png"文件与代码文件在同一文件夹下,否则需填写完整路径(如"D:/images/img.png"),否则会读取失败,后续代码报错。 -
颜色空间转换(BGR↔RGB)是必做步骤,与手部检测、手势识别一致,遗漏会导致检测结果错误或画面颜色失真。
2.3.3 关键点坐标输出与可视化
python
# 打印关键点总数(固定33个)
print(len(results.pose_landmarks.landmark))
# 遍历33个关键点,打印每个关键点的三维坐标
for i in range(len(results.pose_landmarks.landmark)):
x=results.pose_landmarks.landmark[i].x
y=results.pose_landmarks.landmark[i].y
z=results.pose_landmarks.landmark[i].z
print(x,y,z)
# 绘制关键点和骨骼连接(核心)
drawing.draw_landmarks(img, results.pose_landmarks, mp_pose.POSE_CONNECTIONS)
# 显示带关键点标注的图片
cv2.imshow("keypoint", img)核心解析:
-
results.pose_landmarks:存储检测到的人体关键点信息,是一个列表,包含33个关键点(固定数量),每个关键点有x、y、z三个坐标(x、y为归一化坐标,z为深度坐标)。 -
mp_pose.POSE_CONNECTIONS:MediaPipe内置的人体骨骼连接规则,定义了33个关键点之间的连接关系(如头部→颈部、颈部→肩部、肩部→肘部等),无需手动定义,绘图工具会自动连接。 -
关键点坐标含义:与手部检测一致,x、y取值0~1(相对于图片宽高),z以人体骨盆为原点,值越小,关键点越靠近摄像头;若需将x、y转换为像素坐标,需乘以图片宽高(如int(x*w)、int(y*h))。
2.3.4 3D姿态可视化(新增亮点)
python
drawing.plot_landmarks(results.pose_world_landmarks, mp_pose.POSE_CONNECTIONS)这是姿态检测的亮点功能:results.pose_world_landmarks 存储的是关键点的3D世界坐标(而非归一化坐标),drawing.plot_landmarks 会生成一个3D可视化窗口,展示人体姿态的空间位置关系,可拖动窗口旋转查看,直观理解关键点的三维分布(适合新手学习人体关键点的位置)。
2.3.5 程序退出与资源释放
python
cv2.waitKey(0) # 等待按键输入(任意按键退出)
cv2.destroyAllWindows() # 关闭所有窗口,释放资源与手部检测不同:cv2.waitKey(0) 表示"等待任意按键输入后退出"(适合静态图片查看),而动态视频检测用cv2.waitKey(1)(每帧停留1毫秒)。
2.4功能拓展思路
-
拓展为实时视频姿态检测:将静态图片读取(cv2.imread)改为摄像头采集(cv2.VideoCapture(0)),外层添加while循环,修改为动态模式(static_image_mode=False),实现实时姿态检测;
-
动作识别:通过判断关键点的位置关系,识别简单动作(如站立、蹲下、举手、弯腰),比如"蹲下"时,膝盖关键点(25、26号)与髋关节关键点(23、24号)的距离变小;
-
健身计数:比如计数深蹲、俯卧撑次数,通过检测人体姿态的变化(如深蹲时膝盖弯曲幅度),触发计数逻辑;
-
人体抠图与背景替换:启用enable_segmentation=True,获取人体掩码,结合OpenCV的.bitwise_and函数,实现背景替换(如将背景换成纯色、图片);
-
多人体检测:MediaPipe姿态检测支持多人体同时检测,无需修改参数,直接读取包含多个人体的图片/视频即可。
三、MediaPipe脸部关键点检测(Face Mesh)
MediaPipe的Face Mesh(脸部网格)功能,可实时检测脸部478个关键点,涵盖额头、眼睛、鼻子、嘴巴、脸颊、下巴等所有脸部区域,精度极高,可用于人脸表情识别、虚拟化妆、人脸特效等场景。本次代码实现实时视频脸部关键点检测,标注关键点序号,绘制脸部网格,贴合新手实战需求。
3.1 核心功能概述
-
调用电脑默认摄像头,采集实时视频流,实时检测画面中最多2张人脸;
-
检测每张人脸的478个关键点,打印关键点总数,可选打印每个关键点的三维坐标;
-
在视频画面上标注每个关键点的序号(0~477),绘制脸部网格(FACEMESH_TESSELATION),直观呈现关键点分布;
-
使用MediaPipe内置的网格绘制风格,让脸部网格更清晰、美观;
-
支持ESC键退出检测,自动释放摄像头资源,兼容前三个功能的基础逻辑。
3.2 完整实战代码
python
import cv2
import mediapipe as mp
# 初始化 Mediapipe 模块
mp_face_mesh = mp.solutions.face_mesh
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
# 设置 Face Mesh 参数
face_mesh = mp_face_mesh.FaceMesh(
static_image_mode=False,
max_num_faces=2,
refine_landmarks=True,
min_detection_confidence=0.5,
min_tracking_confidence=0.5
)
# 打开摄像头
cap = cv2.VideoCapture(0)
while cap.isOpened():
success, frame = cap.read()
h, w = frame.shape[:2]
if not success:
print("无法读取摄像头画面")
break
# 转换颜色空间
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = face_mesh.process(frame_rgb)
# 绘制关键点
if results.multi_face_landmarks:
for face_landmarks in results.multi_face_landmarks:
print(len(face_landmarks.landmark)) # 478
for i in range(len(face_landmarks.landmark)):
x = face_landmarks.landmark[i].x
y = face_landmarks.landmark[i].y
# z = face_landmarks.landmark[i].z
# print(x,y,z)
cv2.putText(frame, str(i), (int(x * w), int(y * h)), cv2.FONT_HERSHEY_SIMPLEX, 0.3, (0, 255, 0), 2)
mp_drawing.draw_landmarks(
image=frame,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_TESSELATION,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles.get_default_face_mesh_tesselation_style()
)
# 显示结果
cv2.imshow('Face Mesh', frame)
if cv2.waitKey(1)==27:
break
cap.release()
cv2.destroyAllWindows()3.3 代码逐模块详细解析
脸部关键点检测使用MediaPipe的mp_face_mesh模块,新增了专属的绘图风格模块(mp_drawing_styles),关键点数量(478个)远多于手部和姿态检测,重点解析专属模块、参数和绘制逻辑,基础模块简要带过。
3.3.1 库导入与脸部网格初始化(核心新增)
python
import cv2
import mediapipe as mp
# 初始化 Mediapipe 模块(脸部网格专属)
mp_face_mesh = mp.solutions.face_mesh
mp_drawing = mp.solutions.drawing_utils # 绘图工具(复用)
mp_drawing_styles = mp.solutions.drawing_styles # 脸部绘图风格(新增)
# 设置 Face Mesh 参数,初始化脸部检测器
face_mesh = mp_face_mesh.FaceMesh(
static_image_mode=False,
max_num_faces=2,
refine_landmarks=True,
min_detection_confidence=0.5,
min_tracking_confidence=0.5
)核心解析(新手重点关注):
-
mp_face_mesh = mp.solutions.face_mesh:MediaPipe脸部网格核心模块,内置478个人脸关键点检测模型,采用Face Mesh架构,能高精度定位脸部所有区域的关键点,支持实时检测。 -
mp_drawing_styles = mp.solutions.drawing_styles:脸部绘图风格专属模块,内置多种预设的绘图风格(如网格风格、轮廓风格),无需手动设置线条颜色、粗细,让绘制效果更美观。 -
face_mesh = mp_face_mesh.FaceMesh(...):初始化脸部检测器,5个核心参数,详细说明如下:-
static_image_mode:检测模式,False为动态视频模式(本次使用),True为静态图片模式,逻辑与手部、姿态检测一致。 -
max_num_faces:最多可检测的人脸数量,默认值为1,本次设为2,支持同时检测两张人脸。 -
refine_landmarks:是否优化关键点精度,True表示优化(重点优化眼睛、嘴唇等细节部位的关键点),False表示不优化,新手建议设为True,提升检测精度。 -
min_detection_confidence、min_tracking_confidence:与前三个功能一致,分别控制检测精度和追踪稳定性,新手设为0.5即可。
-
3.3.2 摄像头采集与视频预处理
python
cap = cv2.VideoCapture(0) # 调用默认摄像头
while cap.isOpened(): # 循环条件:摄像头正常打开
success, frame = cap.read() # 读取摄像头帧
h, w = frame.shape[:2] # 获取画面宽高(用于关键点坐标转换)
if not success:
print("无法读取摄像头画面")
break
# 颜色空间转换:BGR→RGB,适配MediaPipe
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 执行脸部关键点检测
results = face_mesh.process(frame_rgb)补充说明:
-
cap.isOpened():比while True更严谨的循环条件,会判断摄像头是否正常打开,若摄像头异常(如未连接、被占用),会直接退出循环,避免报错。 -
h, w = frame.shape[:2]:获取画面宽高,后续将关键点的归一化坐标(x、y)转换为像素坐标(int(x*w)、int(y*h)),用于标注关键点序号。 -
异常处理:
if not success: break,若摄像头无法读取帧(如遮挡、异常),打印提示并退出循环,提升程序稳定性。
3.3.3 核心:关键点标注与脸部网格绘制
这是脸部检测的核心模块,包含"关键点序号标注"和"脸部网格绘制"两个功能,逻辑与手部检测类似,但关键点更多、绘制风格更特殊。
python
if results.multi_face_landmarks: # 判断是否检测到人脸关键点
for face_landmarks in results.multi_face_landmarks: # 遍历每张人脸
print(len(face_landmarks.landmark)) # 打印关键点总数(固定478个)
# 遍历478个关键点,标注序号
for i in range(len(face_landmarks.landmark)):
x = face_landmarks.landmark[i].x
y = face_landmarks.landmark[i].y
# z = face_landmarks.landmark[i].z # 深度坐标,可选打印
# print(x,y,z)
# 标注关键点序号(字体缩小,避免遮挡)
cv2.putText(frame, str(i), (int(x * w), int(y * h)),
cv2.FONT_HERSHEY_SIMPLEX, 0.3, (0, 255, 0), 2)
# 绘制脸部网格(核心,使用内置风格)
mp_drawing.draw_landmarks(
image=frame, # 要绘制的画面
landmark_list=face_landmarks, # 人脸关键点列表
connections=mp_face_mesh.FACEMESH_TESSELATION, # 脸部网格连接规则
landmark_drawing_spec=None, # 不单独绘制关键点(避免与序号重叠)
connection_drawing_spec=mp_drawing_styles.get_default_face_mesh_tesselation_style() # 内置网格风格
)逐点解析(新手必看):
-
results.multi_face_landmarks:存储所有检测到的人脸关键点信息,是一个列表,每张人脸对应一个face_landmarks对象,每个对象包含478个关键点。 -
关键点序号标注:-
字体设为0.3(较小),颜色为绿色(0,255,0),线条粗细2,避免序号过大遮挡脸部网格和其他关键点;
-
z轴深度坐标被注释,若需要查看,取消注释即可,z值以脸部中心点为原点,值越小,关键点越靠近摄像头。
-
以上就是mediapipe的一些进阶、其他用法功能。