梯度累积,几乎是所有 OOM 的"第一反应"
在大模型训练里,只要显存一炸,几乎一定会有人说一句话:
"那我们开梯度累积吧。"
这句话出现的频率,可能仅次于:
"batch 再小一点。"
而且很多时候,梯度累积确实能救命:
- batch size 从 8 变成 1
- accumulation steps = 8
- 训练终于能跑了
loss 在降,日志在刷,GPU 不再 OOM。
一切看起来都很好。
但只要你把这个配置长期用下去,你迟早会遇到一些说不清的问题:
- 训练变慢了
- 模型行为变得"迟钝"
- 调参越来越没手感
- 同样的配置,在另一个任务上突然失效
于是你会开始怀疑:
"梯度累积......是不是也没那么'免费'?"
答案是:
它确实不免费,而且它换走的东西,往往比显存更重要。
先给一个不绕弯子的结论(非常重要)
在展开之前,我先把这篇文章最核心的判断写出来:
梯度累积节省的,不是"训练成本",
而是"单步显存峰值";
而它换走的,是:
时间、信号密度、调参手感,以及系统稳定性。
如果你只把梯度累积当成"batch 的替代品",
那后面所有问题都会显得莫名其妙。
第一层误解:把梯度累积当成"等价的大 batch"
这是几乎所有人都会犯的第一个错误。
理论上我们常听到一句话:
"梯度累积 + 小 batch ≈ 大 batch。"
从数学期望的角度,这句话并不完全错。
但工程里有一个非常重要的前提,经常被忽略:
"等价"只存在于理想化假设中,
而真实训练过程,远不满足这些假设。
在真实训练中:
- 梯度不是独立同分布
- 优化器有状态
- 学习率调度按 step 走
- dropout、layer norm 都在参与
这些因素叠加起来,意味着:
梯度累积 ≠ 简单的大 batch。
理论等价 vs 工程现实差异
第二层:梯度累积到底"省了什么显存"
我们先把它真正"省掉"的东西说清楚。
梯度累积能省的,只有一件事
单次 forward + backward 的激活显存。
也就是说:
- batch size = 1
- accumulation = N
每一次前向 / 反向,显存里只需要容纳:
text
1 × sequence_length × hidden_dim × layer而不是:
text
N × sequence_length × hidden_dim × layer这对 activation 占主导的模型 来说,非常关键。
但注意一个细节:
梯度、参数、优化器状态的显存,并没有减少。
它们在整个累积周期内,一直都在。
所以梯度累积解决的,是一个非常特定的问题:
"单步 OOM"问题,而不是"总体显存压力"问题。
第三层:梯度累积换走的第一个成本------时间
这是最显性的成本,但经常被低估。
假设你原本是:
text
batch = 8
一步 = 1 次 forward + backward现在变成:
text
batch = 1
accumulation = 8
一步 = 8 次 forward + backward从计算量上看:
- 理论 FLOPs 相同
- 实际 wall time 几乎一定更长
原因包括:
- kernel launch 次数增加
- CPU/GPU 同步更频繁
- cache 局部性变差
这意味着:
你用显存,换走的是训练吞吐率。
在短实验里可能无所谓,
但在长期训练或频繁试验中,差距会被不断放大。
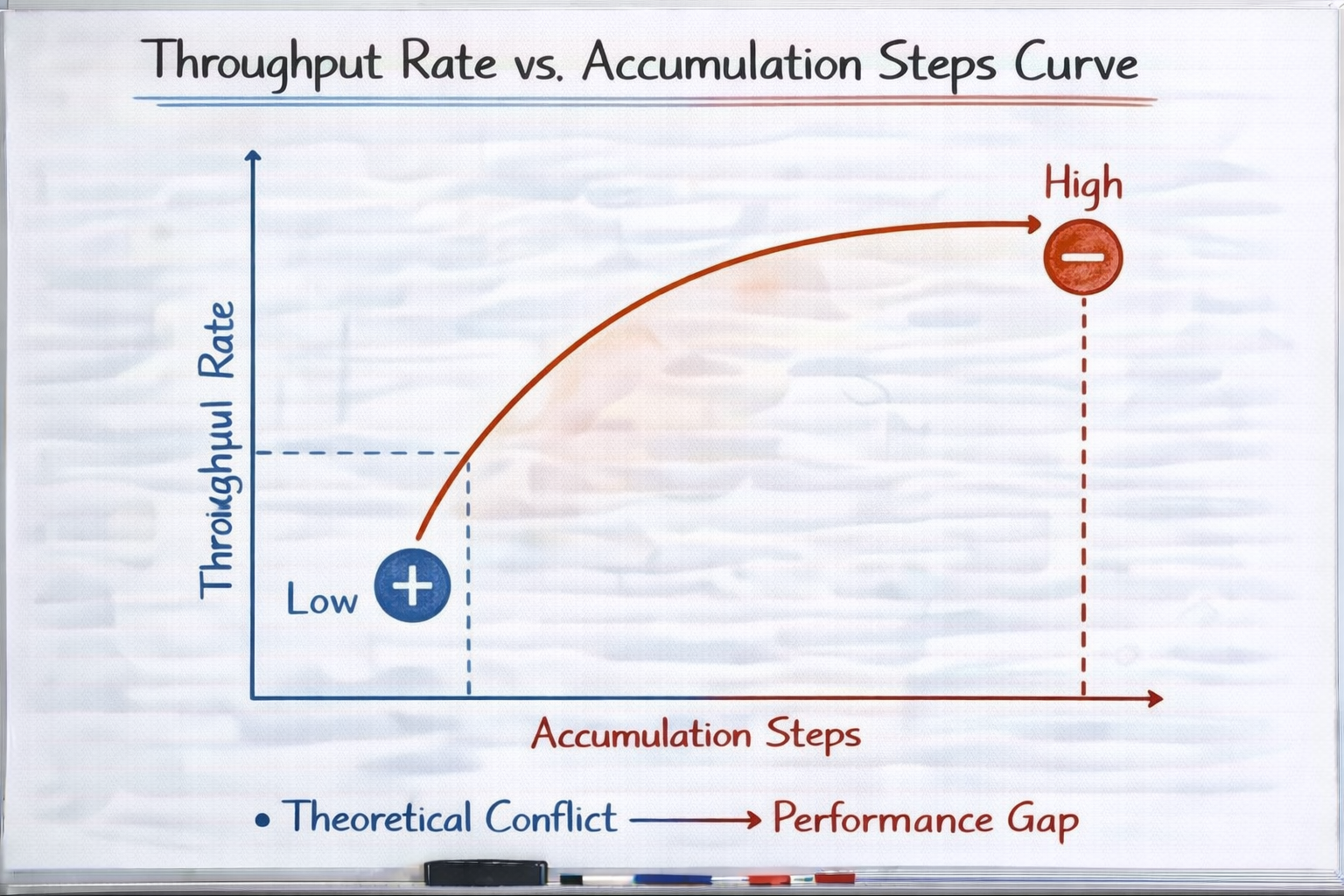
吞吐率 vs accumulation steps 曲线
第四层:梯度累积换走的第二个成本------"梯度信号密度"
这是一个非常关键、但很少被明确说出来的代价。
在正常 batch 训练中:
- 一次 backward
- 梯度是 N 条样本的平均
而在梯度累积中:
- 多次 backward
- 梯度在 optimizer step 前被不断"加和"
这带来一个微妙但重要的变化:
梯度更新的"节奏"变了。
模型在更长时间里:
- 使用的是"旧参数"
- 累积的是"历史信号"
当任务复杂、分布变化快时,这会导致:
- 更新滞后
- 行为调整变慢
- 对新信号反应迟钝
你会感觉模型:
"好像在学,但学得不灵。"
第五层:优化器状态,在梯度累积下会"变味"
这是一个偏底层、但非常真实的问题。
以 Adam 为例,它维护的是:
- 一阶动量
- 二阶动量
在正常训练中:
- 每一步,动量都会更新
- 它们反映的是"近期梯度统计"
但在梯度累积中:
- 多个 mini-step 不更新优化器
- 动量只在最终 step 更新一次
这意味着什么?
意味着:
优化器对梯度变化的感知,被人为"稀释"了。
在一些任务中,这会导致:
- 震荡减少(看起来更稳)
- 收敛变慢
- 对难样本反应变弱
于是你可能会误判:
"是不是学习率太小?"
然后开始调另一个旋钮。
第六层:学习率调度,在梯度累积下经常被"暗改"
这是一个非常常见但极其隐蔽的坑。
很多训练代码里,学习率调度是按 step 走的:
python
scheduler.step()当你引入梯度累积后,如果你没特别处理:
- step 数变少
- 学习率 decay 变慢
结果是:
你以为只改了 batch,
其实连学习率曲线都一起改了。
这会导致:
- 前期学习率过高时间更长
- 后期衰减不充分
- 模型表现不稳定
很多"调不动"的问题,根本不是模型问题,
而是调度和累积叠加的副作用。
第七层:梯度累积对"调参手感"的破坏
这是一个非常工程师视角的问题。
在没有梯度累积时:
- 调学习率 → 行为变化很快
- 改 loss → 几步内就能看到趋势
而在高 accumulation 的情况下:
- 行为反馈延迟
- 变化被平滑
- 很难判断"是不是有效"
你会开始觉得:
"怎么什么都不太灵了?"
这不是你变菜了,
而是:
你把一个高反馈系统,
变成了低频反馈系统。
调参自然会变得痛苦。
第八层:为什么梯度累积会"掩盖结构性问题"
这是最危险的一点。
当模型出现问题时:
- 本该通过改架构
- 或改切分
- 或改任务设计
但梯度累积能让你:
- "先跑起来"
- "暂时不 OOM"
于是你可能会:
用梯度累积,
掩盖本该正视的系统设计问题。
比如:
- sequence length 本该减
- attention 本该裁剪
- 模型规模本该调整
梯度累积让你暂时不用面对这些问题,
但它们并没有消失。
一个非常真实的使用演化路径
text
一开始:梯度累积救命
中期:训练能跑,但慢
后期:越来越难调
最后:不知道哪里出了问题注意:
这里每一步的选择,都"很合理"。
问题在于:
你一直在用一个"应急手段",跑一个"长期系统"。
那梯度累积什么时候是"合理的"?
说清楚代价,不代表否定它。
梯度累积在以下场景中,通常是合理的:
- 资源受限的探索期
- 快速验证想法
- 不追求极致性能
- 行为变化不敏感的任务
一句话总结:
梯度累积适合"先活下来",
不适合"长期精调"。
一个非常实用的自检问题
在你决定继续用梯度累积之前,可以问自己一句话:
我现在遇到的问题,
真的是"显存不够",
还是"系统设计不合适"?
如果你不敢肯定,
那梯度累积大概率只是把问题往后推。
很多团队在显存受限时大量依赖梯度累积,但真正卡住的往往不是显存,而是训练反馈变慢、行为难以判断。用LLaMA-Factory online进行小规模对照实验,更容易区分:哪些问题是显存约束导致的,哪些其实是模型和系统设计的问题。
总结:梯度累积省的是显存,花的是系统复杂度
我用一句话,把这篇文章彻底收住:
梯度累积从来不是"免费午餐",
它只是让你用
时间、信号密度和调参难度,
换取一段显存缓冲。
当你开始:
- 意识到它的代价结构
- 不再把它当成默认选项
- 在"能跑"和"好调"之间做取舍
你才真正开始工程化地使用梯度累积。