提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
1. 哨兵
Redis 的主从复制模式下,⼀旦主节点由于故障不能提供服务,需要⼈⼯进⾏主从切换,同时⼤量的客⼾端需要被通知切换到新的主节点上,对于上了⼀定规模的应⽤来说,这种⽅案是⽆法接受的,于是 Redis 从 2.8 开始提供了 Redis Sentinel(哨兵)加个来解决这个问题
1.1 基本概念
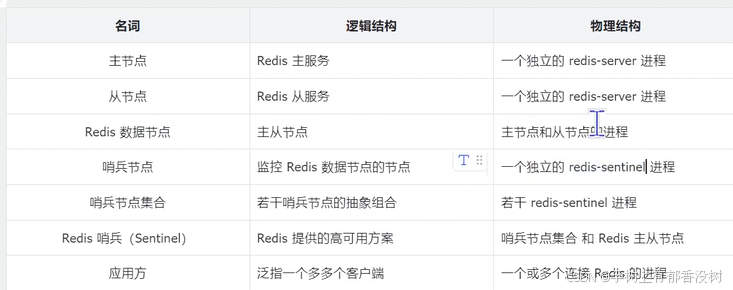
名词 逻辑结构 物理结构
主节点 Redis 主服务 ⼀个独⽴的 redis-server 进程
从节点 Redis 从服务 ⼀个独⽴的 redis-server 进程
Redis 数据节点 主从节点 主节点和从节点的进程
哨兵节点 监控 Redis 数据节点的节点 ⼀个独⽴的 redis-sentinel 进程
哨兵节点集合 若⼲哨兵节点的抽象组合 若⼲ redis-sentinel 进程
Redis 哨兵(Sentinel) Redis 提供的⾼可⽤⽅案 哨兵节点集合 和 Redis 主从节点
应⽤⽅ 泛指⼀个多多个客⼾端 ⼀个或多个连接 Redis 的进程
Redis Sentinel 是 Redis 的⾼可⽤实现⽅案,在实际的⽣产环境中,对提⾼整个系统的⾼可⽤是⾮常有帮助的,本节⾸先整体梳理主从复制模式下故障处理可能产⽣的问题,⽽后引出⾼可⽤的概念,最后重点分析 Redis Sentinel 的基本架构、优势,以及是如何实现⾼可⽤的。
1.2 手动恢复redis主从复制的流程
Redis 主从复制模式下,主节点故障后需要进⾏的⼈⼯ 作是⽐较繁琐的
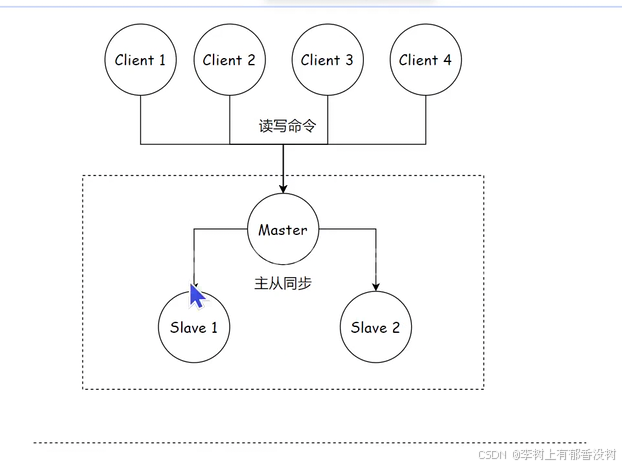
监控程序来监控服务器的运行状态,还要搭配一个报警程序,如果服务器运行出现了状态异常----》就要给程序员报警了(电话微信飞书)

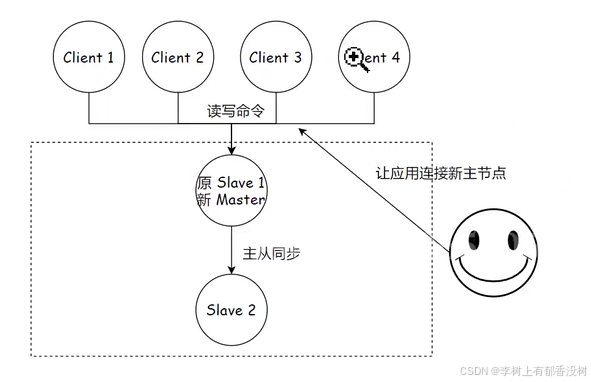
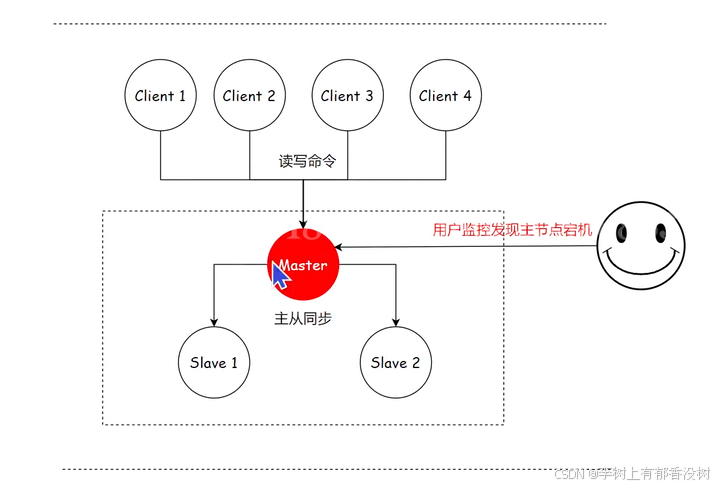
1)运维⼈员通过监控系统,发现 Redis 主节点故障宕机。
2)运维⼈员从所有节点中,选择⼀个(此处选择了 slave 1)执⾏ slaveof no one,使其作为新的主节点。
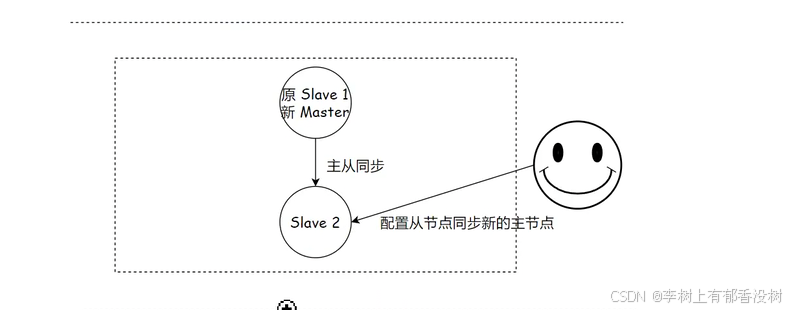
3)运维⼈员让剩余从节点(此处为 slave 2)执⾏ slaveof {newMasterIp} {newMasterPort} 从新主节点开始数据同步。
4)更新应⽤⽅连接的主节点信息到 {newMasterIp} {newMasterPort}。
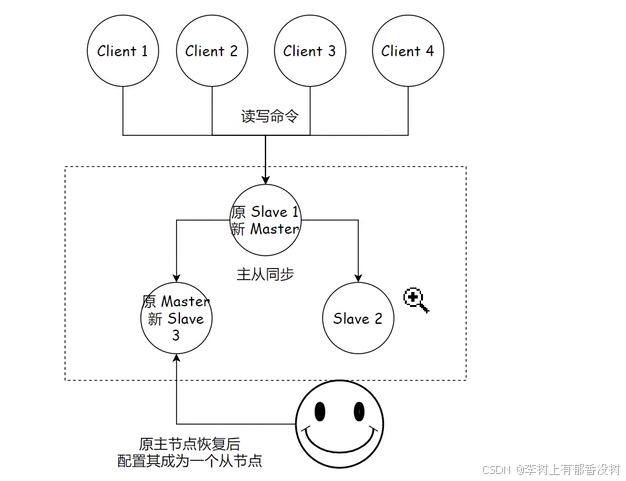
5)如果原来的主节点恢复,执⾏ slaveof {newMasterIp} {newMasterPort} 让其成为⼀个从节点。
上述过程可以看到基本需要⼈⼯介⼊,⽆法被认为架构是⾼可⽤的。⽽这就是 Redis Sentinel 所要做的。
1.3 哨兵⾃动恢复主节点故障
当主节点出现故障时,Redis Sentinel 能⾃动完成故障发现和故障转移,并通知应⽤⽅,从⽽实现真正的⾼可⽤。Redis Sentinel 是⼀个分布式架构,其中包含若⼲个 Sentinel 节点和 Redis 数据节点,每个Sentinel 节点会对数据节点和其余 Sentinel 节点进⾏监控,当它发现节点不可达时,会对节点做下线表⽰。如果下线的是主节点,它还会和其他的 Sentinel 节点进⾏ "协商",当⼤多数 Sentinel 节点对主节点不可达这个结论达成共识之后,它们会在内部 "选举" 出⼀个领导节点来完成⾃动故障转移的⼯作,同时将这个变化实时通知给 Redis 应⽤⽅。整个过程是完全⾃动的,不需要⼈⼯介⼊。整体的架构如图所⽰。
这⾥的分布式架构是指:Redis 数据节点、Sentinel 节点集合、客⼾端分布在多个物理节点上,不要与后边介绍的 Redis Cluster 分布式混淆。
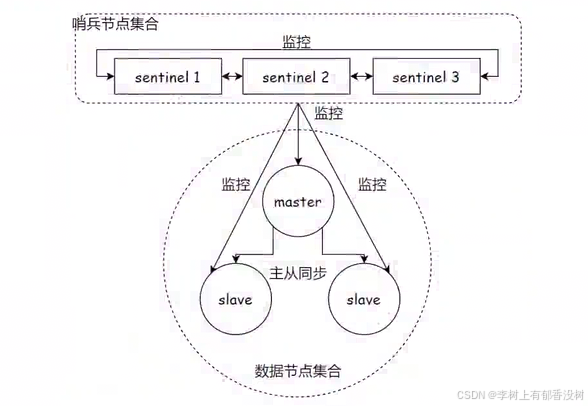
提供了三个redis sentinel进程,而且是多个,并且这三个哨兵进程就会监控现有的master和slave,监控:建立tcp连接,定期发送心跳包
从节点挂了,么有关系
Redis Sentinel 相⽐于主从复制模式是多了若⼲(建议保持奇数,所以最少也是三个)Sentinel 节点⽤于实现监控数据节点,哨兵节点会定期监控所有节点(包含数据节点和其他哨兵节点)。针对主节点故障的情况,故障转移流程⼤致如下:
1)主节点故障,从节点同步连接中断,主从复制停⽌。
2)哨兵节点通过定期监控发现主节点出现故障。哨兵节点与其他哨兵节点进⾏协商,达成多数认同主节点故障的共识。这步主要是防⽌该情况:出故障的不是主节点,⽽是发现故障的哨兵节点,该情况经常发⽣于哨兵节点的⽹络被孤⽴的场景下。
3)哨兵节点之间使⽤ Raft 算法选举出⼀个领导⻆⾊(从多个哨兵中选一个),由该节点负责后续的故障转移⼯作。
4)哨兵领导者开始执⾏故障转移:从节点中选择⼀个作为新主节点;让其他从节点同步新主节点;通知应⽤层转移到新主节点。
通过上⾯的介绍,可以看出 Redis Sentinel 具有以下⼏个功能:
• 监控: Sentinel 节点会定期检测 Redis 数据节点、其余哨兵节点是否可达。
• 故障转移: 实现从节点晋升(promotion)为主节点并维护后续正确的主从关系。
• 通知: Sentinel 节点会将故障转移的结果通知给应⽤⽅。
部署多个哨兵节点,目的是为了防止哨兵节点挂了,而且为了防止一个哨兵节点误判
1.4 使用docker搭建环境
redis服务
一个主,两个从,三个哨兵
所以就有六个节点了,按理说应该部署到不同服务器的,但是我们条件有限
bash
docker pull redis:5.0.9创建三个容器:一主两从
创建三个容器:三个哨兵
我们要先启动数据节点,在启动哨兵,不然哨兵就以为数据节点挂了,如果哨兵先启动的话
我们用docker-compose.yml
bash
version: '3.7'
services:
master:
image: 'redis:5.0.9'
container_name: redis-master
restart: always
command: redis-server --appendonly yes
ports:
- 6379:6379
slave1:
image: 'redis:5.0.9'
container_name: redis-slave1
restart: always
command: redis-server --appendonly yes --slaveof redis-master 6379
ports:
- 6380:6379
slave2:
image: 'redis:5.0.9'
container_name: redis-slave2
restart: always
command: redis-server --appendonly yes --slaveof redis-master 6379
ports:
- 6381:6379master,slave1,slave2这些名字是我们自己设定的
bash
docker-compose up -d
哨兵节点
然后是三个哨兵节点的docker命令了
redis哨兵节点是单独的redis服务器进程,只是监控
bash
version: '3.7'
services:
sentinel1:
image: 'redis:5.0.9'
container_name: redis-sentinel-1
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel1.conf:/etc/redis/sentinel.conf
ports:
- 26379:26379
sentinel2:
image: 'redis:5.0.9'
container_name: redis-sentinel-2
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel2.conf:/etc/redis/sentinel.conf
ports:
- 26380:26379
sentinel3:
image: 'redis:5.0.9'
container_name: redis-sentinel-3
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel3.conf:/etc/redis/sentinel.conf
ports:
- 26381:26379
bash
docker-compose up -d
为什么要映射这个配置文件呢,因为哨兵在运行过程中对配置文件进行自动的修改,所以不能拿一个配置文件去映射
然后是sentinel.conf里面的内容
创建 sentinel1.conf sentinel2.conf sentinel3.conf . 三份⽂件的内容是完全相同的.
bash
bind 0.0.0.0
port 26379
sentinel monitor redis-master redis-master 6379 2
sentinel down-after-milliseconds redis-master 1000这个就是sentinel1.conf文件里面的内容
bind 0.0.0.0表示其他节点都可以访问它
port 26379表示容器内部的端口号
sentinel monitor redis-master redis-master 6379 2让哨兵节点监控哪个redis服务器,第一个redis-master是服务的名字,第二个redis-master是服务的ip,6379 是master的端口号,是容器外部端口号,2是法定票数,就是达到法定票数的哨兵认为redis挂了,才是真正的挂了
bash
sentinel monitor 主节点名 主节点ip 主节点端⼝ 法定票数• 主节点名, 这个是哨兵内部⾃⼰起的名字.
• 主节点 ip, 部署 redis-master 的设备 ip. 此处由于是使⽤ docker, 可以直接写 docker 的容器名, 会被⾃动 DNS 成对应的容器 ip
• 主节点端⼝, 不解释.
• 法定票数, 哨兵需要判定主节点是否挂了. 但是有的时候可能因为特殊情况, ⽐如主节点仍然⼯作正常, 但是哨兵节点⾃⼰⽹络出问题了, ⽆法访问到主节点了. 此时就可能会使该哨兵节点认为主节点下线, 出现误判. 使⽤投票的⽅式来确定主节点是否真的挂了是更稳妥的做法. 需要多个哨兵都认为主节点挂了, 票数 >= 法定票数 之后, 才会真的认为主节点是挂了
sentinel down-after-milliseconds redis-master 1000表示心跳包的超时时间
主节点和哨兵之间通过⼼跳包来进⾏沟通. 如果⼼跳包在指定的时间内还没回来, 就视为是节点出现故障
这样还不能运行成功
同一网络问题
• 主节点 ip, 部署 redis-master 的设备 ip. 此处由于是使⽤ docker, 可以直接写 docker 的容器名, 会被⾃动 DNS 成对应的容器 ip
但是这样做的前提就是处于同一个docker网络中,或者处于同一个docker-compose.yml文件中的容器也是同一docker网络的
所以
bash
docker network ls列出局域网

为什么是redis的前缀呢,因为我们第一个数据节点的docker-compose.yml文件的目录名字就是redis
所以我们看出来了,同一个docker-compose.yml文件的容器会创建一个局域网,局域网的名字和docker-compose.yml文件所在目录有关
所以后面我们创建三个哨兵节点,可以把这三个哨兵节点加入三个数据节点的局域网中,而不是创建新的局域网
bash
version: '3.7'
services:
sentinel1:
image: 'redis:5.0.9'
container_name: redis-sentinel-1
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel1.conf:/etc/redis/sentinel.conf
ports:
- 26379:26379
sentinel2:
image: 'redis:5.0.9'
container_name: redis-sentinel-2
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel2.conf:/etc/redis/sentinel.conf
ports:
- 26380:26379
sentinel3:
image: 'redis:5.0.9'
container_name: redis-sentinel-3
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel3.conf:/etc/redis/sentinel.conf
ports:
- 26381:26379
networks:
default:
external:
name: redis_default所以在后面修改docker-compose.yml文件

这样就成功了
我们再次打开sentinel1.conf
发现已经有了变化了
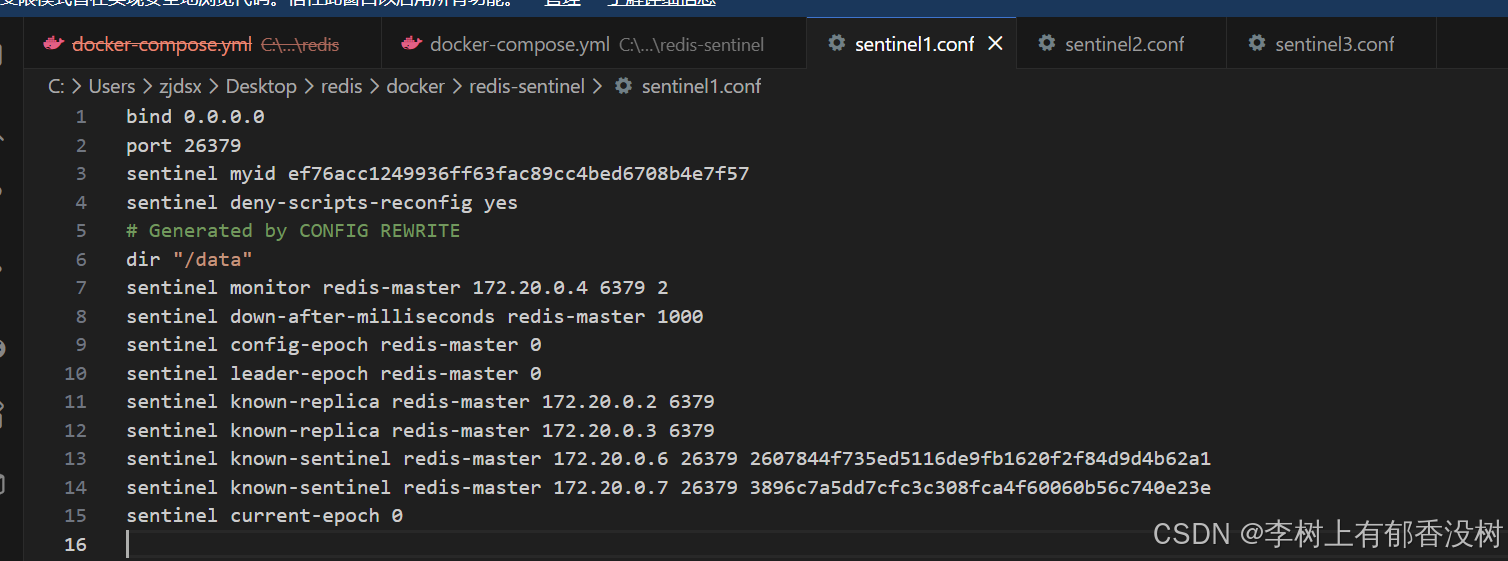
这些就是哨兵节点启动之后,自动会进行修改的
这个就是配置重写
对⽐这三份⽂件, 可以看到配置内容是存在差异的
1.5 哨兵节点的作用演示
我们先手动把主节点stop

这个时候哨兵节点已经开始工作了
bash
docker-compose logs相同目录下输入
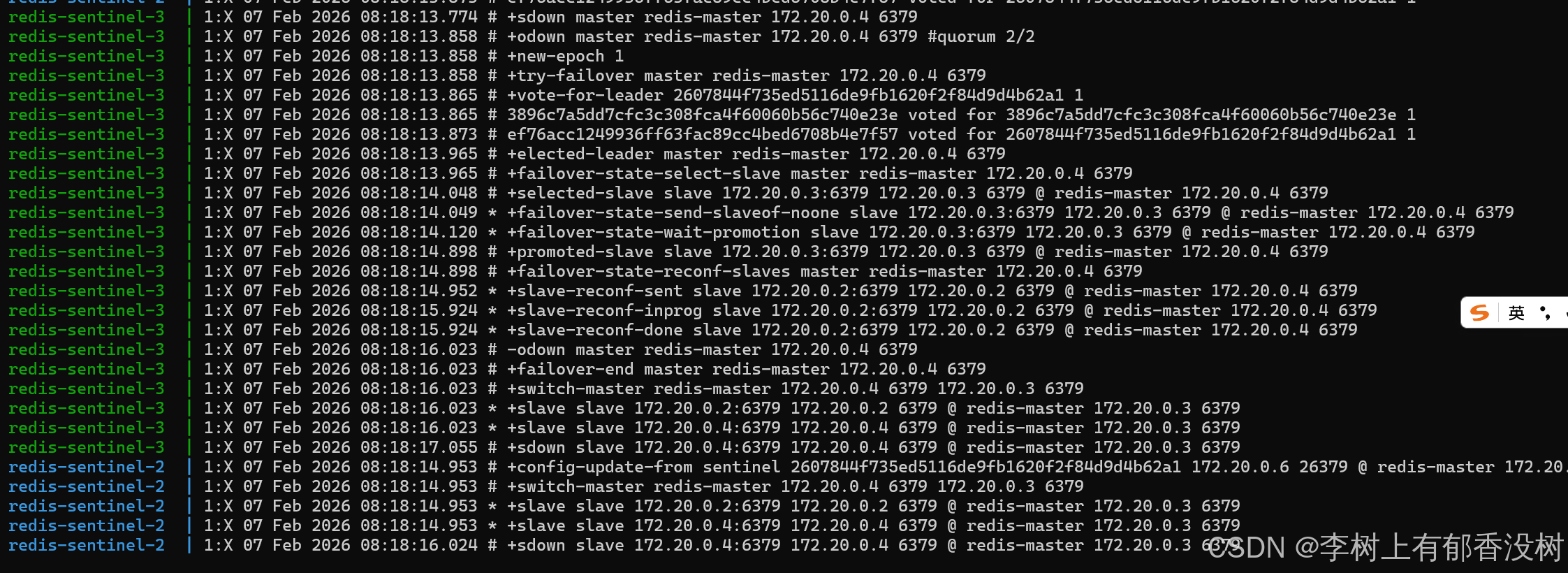
+sdown master redis-master 172.20.0.4 6379表示我这个哨兵认为主节点挂了
+odown master redis-master 172.20.0.4 6379 #quorum 2/2表示好几个哨兵都认为挂了,而且达到了法定票数
此时哨兵就需要选择一个从节点作为新的主节点
+switch-master redis-master 172.20.0.4 6379 172.20.0.3 6379这个就是主节点切换的意思
表示从0.4切换到了0.3
bash
+slave slave 172.20.0.2:6379 172.20.0.2 6379 @ redis-master 172.20.0.3 6379这个就表示让0.2以0.3为主节点
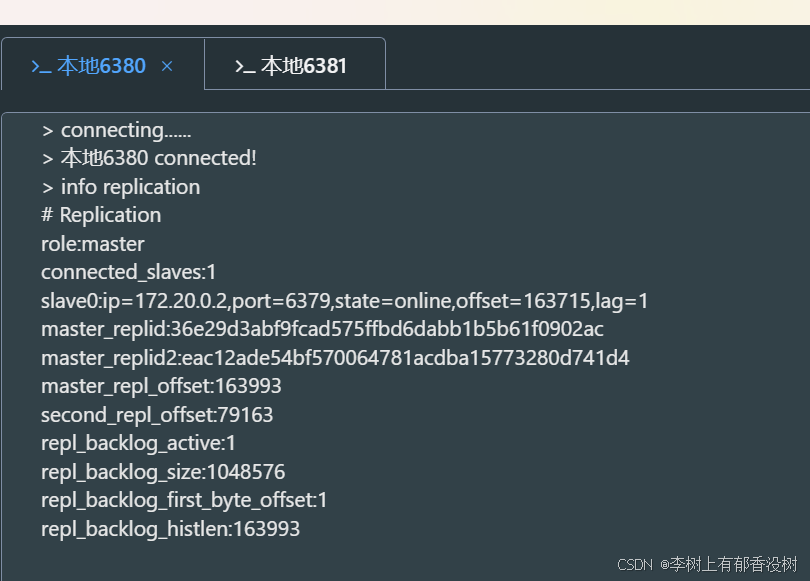
我们看到6380变成主节点了
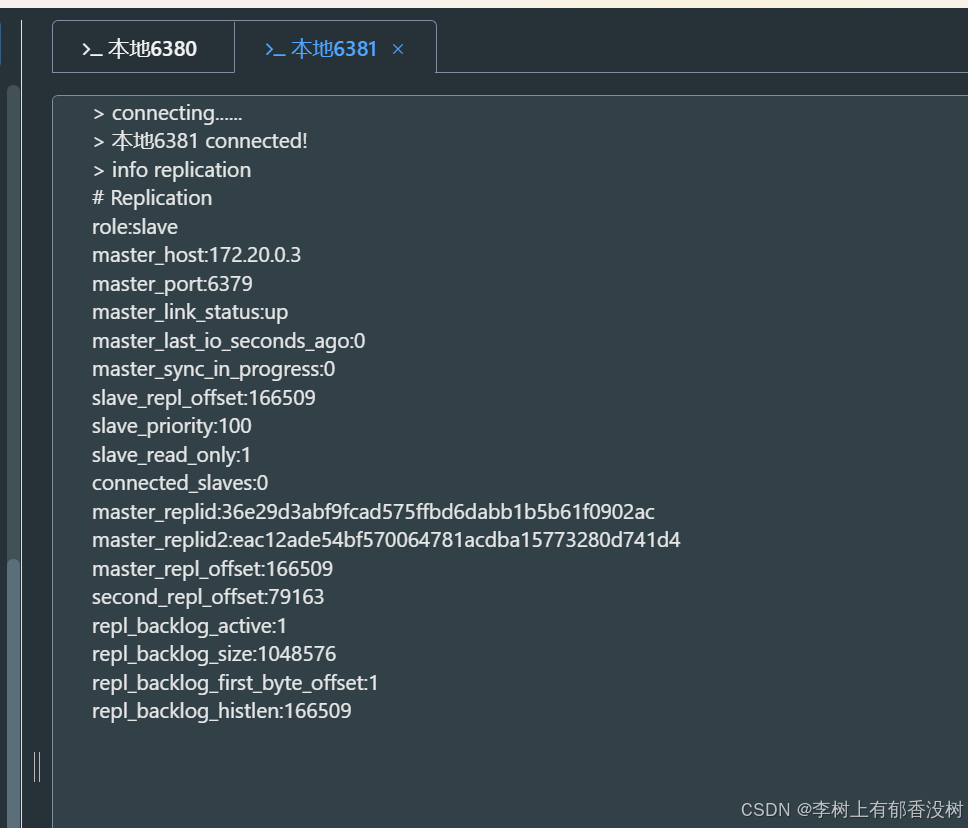
6381变成从节点了
而且给6380设置数据,也可以同步到6381
这个时候我们重新启动6379节点,就是原来的主节点

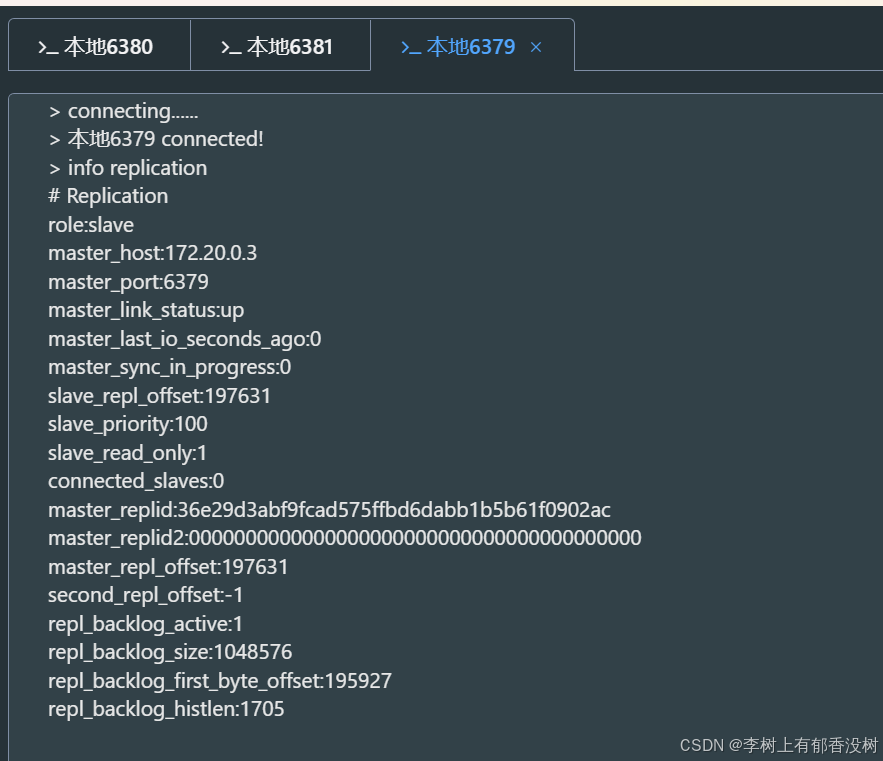
发现6379已经变为了从节点了,和日志说的一样
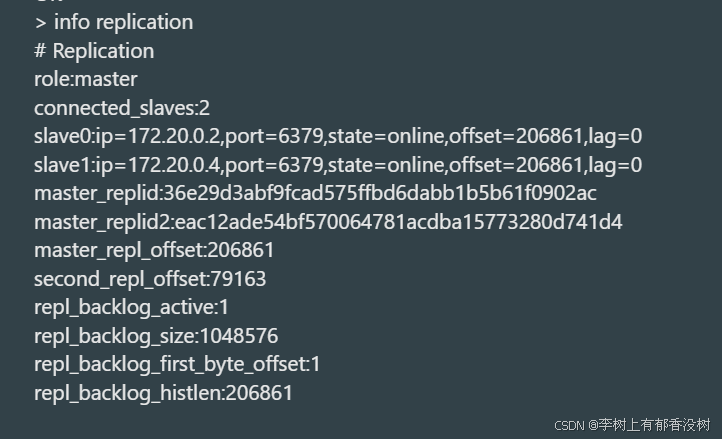
我们还可以看到6380的从节点的ip
结论
• Redis 主节点如果宕机, 哨兵会把其中的⼀个从节点, 提拔成主节点.
• 当之前的 Redis 主节点重启之后, 这个主节点被加⼊到哨兵的监控中, 但是只会被作为从节点使⽤
1.6 选举原理
假定当前环境如上⽅介绍, 三个哨兵(sentenal1, sentenal2, sentenal3), ⼀个主节点(redis-master), 两个从节点(redis-slave1, redis-slave2).
当主节点出现故障, 就会触发重新⼀系列过程.
-
主观下线
当 redis-master 宕机, 此时 redis-master 和三个哨兵之间的⼼跳包就没有了.此时, 站在三个哨兵的⻆度来看, redis-master 出现严重故障. 因此三个哨兵均会把 redis-master 判定为主观下线 (SDown)
-
客观下线
此时, 哨兵 sentenal1, sentenal2, sentenal3 均会对主节点故障这件事情进⾏投票. 当故障得票数 >= 配置的法定票数之后
此时意味着 redis-master 故障这个事情被做实了. 此时触发客观下线 (ODown)
-
选举出哨兵的 leader
接下来需要哨兵把剩余的 slave 中挑选出⼀个新的 master. 这个⼯作不需要所有的哨兵都参与. 只需要选出个代表 (称为 leader), 由 leader 负责进⾏ slave 升级到 master 的提拔过程.
这个选举的过程涉及到 Raft 算法
+vote-for-leader 3896c7a5dd7cfc3c308fca4f60060b56c740e23e 1就是投票谁为leader
2607844f735ed5116de9fb1620f2f84d9d4b62a1 voted for 2607844f735ed5116de9fb1620f2f84d9d4b62a1 1
ef76acc1249936ff63fac89cc4bed6708b4e7f57 voted for 2607844f735ed5116de9fb1620f2f84d9d4b62a1 1
这些都是投票,所以2607844f735ed5116de9fb1620f2f84d9d4b62a1 这个的票数最多
假定⼀共三个哨兵节点, S1, S2, S3
- 每个哨兵节点都给其他所有哨兵节点, 发起⼀个 "拉票请求". (S1 -> S2, S1 -> S3, S2 -> S1, S2 -> S3,S3 -> S1, S3 -> S2)
- 收到拉票请求的节点, 会回复⼀个 "投票响应". 响应的结果有两种可能, 投 or 不投.⽐如 S1 给 S2 发了个投票请求, S2 就会给 S1 返回投票响应.到底 S2 是否要投 S1 呢? 取决于 S2 是否给别⼈投过票了. (每个哨兵只有⼀票).如果 S2 没有给别⼈投过票, 换⽽⾔之, S1 是第⼀个向 S2 拉票的, 那么 S2 就会投 S1. 否则则不投.
- ⼀轮投票完成之后, 发现得票超过半数的节点, ⾃动成为 leader.如果出现平票的情况 (S1 投 S2, S2 投 S3, S3 投 S1, 每⼈⼀票), 就重新再投⼀次即可.这也是为啥建议哨兵节点设置成奇数个的原因. 如果是偶数个, 则增⼤了平票的概率, 带来不必要的开
销. - leader 节点负责挑选⼀个 slave 成为新的 master. 当其他的 sentenal 发现新的 master 出现了, 就说明选举结束了.
简⽽⾔之, Raft 算法的核⼼就是 "先下⼿为强". 谁率先发出了拉票请求, 谁就有更⼤的概率成为 leader.
这⾥的决定因素成了 "⽹络延时". ⽹络延时本⾝就带有⼀定随机性.
具体选出的哪个节点是 leader, 这个不重要, 重要的是能选出⼀个节点即可
- leader 挑选出合适的 slave 成为新的 master
挑选规则:
- ⽐较优先级. 优先级⾼(数值⼩的)的上位. 优先级是配置⽂件中的配置项( slave-priority 或者replica-priority ).
- ⽐较 replication offset 谁复制的数据多, ⾼的上位.
- ⽐较 run id , 谁的 id ⼩, 谁上位.,但是runid是随机生成的
当某个 slave 节点被指定为 master 之后,
-
leader 指定该节点执⾏ slave no one , 成为 master
-
leader 指定剩余的 slave 节点, 都依附于这个新 master
1.7 总结
⼀些注意事项:
• 哨兵节点不能只有⼀个. 否则哨兵节点挂了也会影响系统可⽤性.
• 哨兵节点最好是奇数个. ⽅便选举 leader, 得票更容易超过半数.不同哨兵应该是不同的服务器
• 哨兵节点不负责存储数据. 仍然是 redis 主从节点负责存储.
• 哨兵 + 主从复制解决的问题是 "提⾼可⽤性", 不能解决 "数据极端情况下写丢失" 的问题.
• 哨兵 + 主从复制不能提⾼数据的存储容量. 当我们需要存的数据接近或者超过机器的物理内存, 这样
的结构就难以胜任了.
为了能存储更多的数据, 就引⼊了集群.