第四章 项目目录结构:src/、configs/、data/、tests/ 的黄金布局
-
- [0. 先说结论:目录结构的目标不是"好看",而是"五可"](#0. 先说结论:目录结构的目标不是“好看”,而是“五可”)
- [1. 为什么必须采用 src/ 布局(而不是"随便放.py")](#1. 为什么必须采用 src/ 布局(而不是“随便放.py”))
- [2. 黄金布局全貌:一眼看懂工程项目的骨架](#2. 黄金布局全貌:一眼看懂工程项目的骨架)
- [3. 四大核心目录:你必须知道每个目录的边界](#3. 四大核心目录:你必须知道每个目录的边界)
- [3.1 src/:项目唯一真相(Single Source of Truth)](#3.1 src/:项目唯一真相(Single Source of Truth))
-
- [src/ 的三条硬规则](#src/ 的三条硬规则)
- [Mermaid:src/ 的调用关系建议](#Mermaid:src/ 的调用关系建议)
- [3.2 configs/:参数从代码里拔出来,项目才可迁移](#3.2 configs/:参数从代码里拔出来,项目才可迁移)
- [3.3 data/:数据必须分层,否则你永远不知道"哪个是最终结果"](#3.3 data/:数据必须分层,否则你永远不知道“哪个是最终结果”)
- [3.4 tests/:你不需要高覆盖率,但必须能防止"自己坑自己"](#3.4 tests/:你不需要高覆盖率,但必须能防止“自己坑自己”)
-
- [tests/ 最小要求(建议你抄走)](#tests/ 最小要求(建议你抄走))
- [4. scripts/ 与 notebooks/:它们的定位必须明确](#4. scripts/ 与 notebooks/:它们的定位必须明确)
- [5. runs/ 与 reports/:交付闭环的关键,不是摆设](#5. runs/ 与 reports/:交付闭环的关键,不是摆设)
-
- [runs/:一次运行 = 一个可追溯目录](#runs/:一次运行 = 一个可追溯目录)
- reports/:面向人类的交付物
- [6. 常见坑与"强制规避策略"](#6. 常见坑与“强制规避策略”)
-
- [坑 1:把路径写死在代码里](#坑 1:把路径写死在代码里)
- [坑 2:把业务逻辑塞进 scripts](#坑 2:把业务逻辑塞进 scripts)
- [坑 3:data/ 里混进 runs 产物](#坑 3:data/ 里混进 runs 产物)
- [坑 4:Notebook 变成垃圾场](#坑 4:Notebook 变成垃圾场)
- [7. 本章最低交付(MDR):你必须交付什么?](#7. 本章最低交付(MDR):你必须交付什么?)
- [8. 小结:目录结构不是形式,是你长期复利的起点](#8. 小结:目录结构不是形式,是你长期复利的起点)
(从"脚本堆"升级为"可维护、可复现、可交付的工程项目")
如果你做过两三个数据分析/AI 项目,你一定见过下面这些目录:
final.ipynb、final2.ipynb、final_final.ipynbdata.xlsx、data_new.xlsx、data_new(1).xlsxmodel.pkl放在桌面,或者散落在各个子目录- 配置写死在代码里:路径、阈值、超参、API Key 都是常量
- 合作者拉仓库后第一句话是:"怎么跑?"
这不是你不认真,而是你缺一个"工程化的默认布局"。
目录结构是工程纪律的第一层:它决定了你的项目会不会越做越乱,能不能复现,能不能交付。
本章我给你一个在科研/数据分析/AI 工程都通用的"黄金布局":
src/、configs/、data/、tests/ 为核心,配合 runs/、reports/ 做闭环。
0. 先说结论:目录结构的目标不是"好看",而是"五可"
你搭目录结构不是为了优雅,而是为了让项目具备以下能力:
- 可维护:代码模块边界明确,改动不牵一发动全身
- 可复现:配置、数据版本、运行产物可追踪
- 可评估:评测脚本与测试数据清晰,指标可回放
- 可扩展:新增功能、数据源、模型不会导致结构崩塌
- 可交付:别人 5 分钟内能跑起来,10 分钟内看懂产物
这也是本专栏的"学习协议"落地方式之一:结构先行,后面才谈效率与技巧。
1. 为什么必须采用 src/ 布局(而不是"随便放.py")
很多人会把 Python 包直接放在项目根目录:
text
project/
myproj/
notebooks/
data/这会带来两个长期隐患:
-
导入行为不稳定
Notebook 工作目录不同、运行入口不同,
import myproj可能指向不同位置,出现"能跑但解释不清"的玄学问题。 -
同名污染
根目录里出现
utils.py、random.py、json.py这种文件名,很容易与标准库或第三方库冲突。
采用标准的 src/ 布局,能显著降低这些问题:
text
project/
src/
myproj/
__init__.py
...你会发现:当代码只从 src/ 导入,Notebook、脚本、测试、CLI 的行为更一致,团队协作也更稳定。
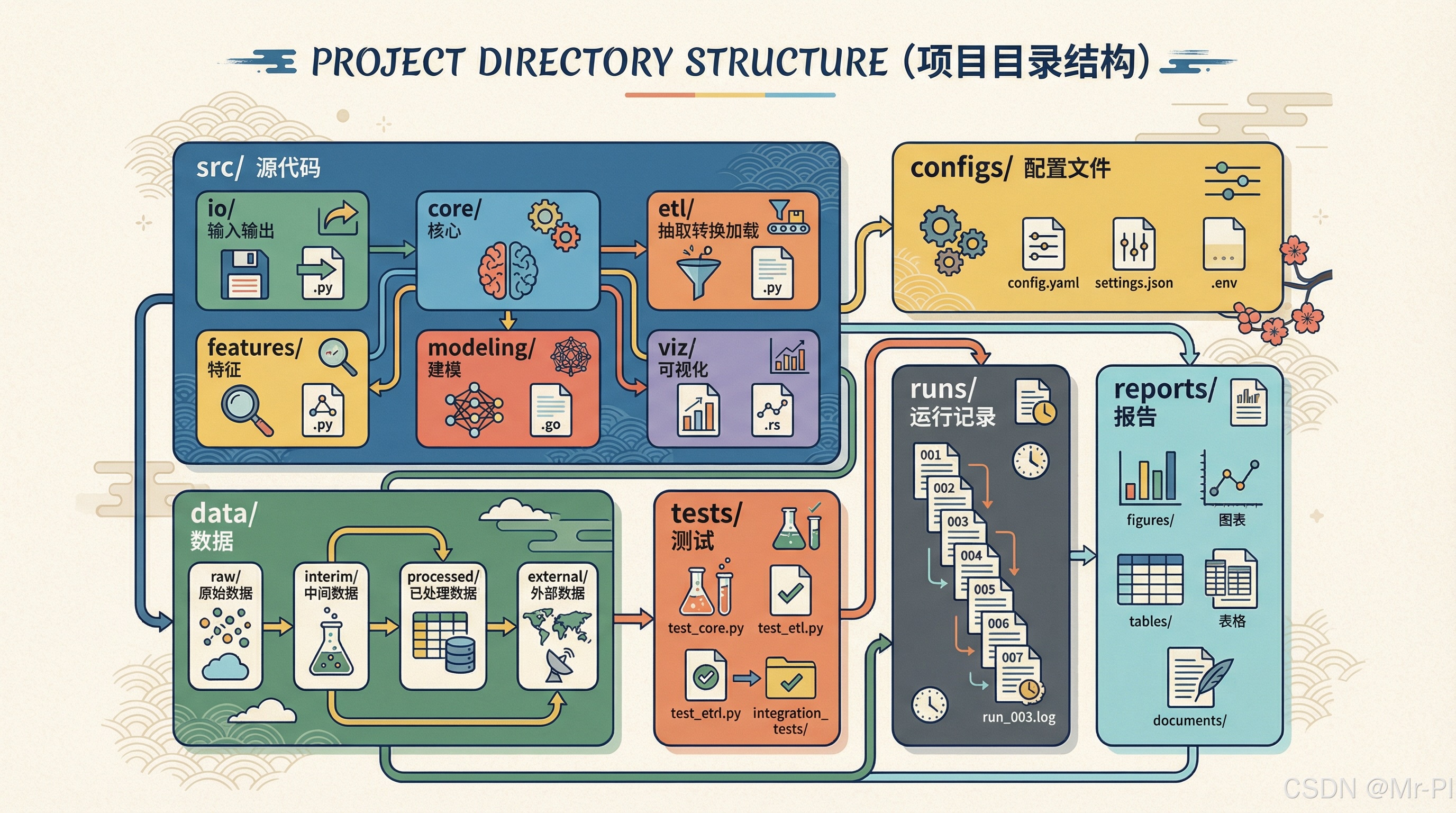
2. 黄金布局全貌:一眼看懂工程项目的骨架
先给你一个完整布局(你可以直接复制作为项目模板):
text
project/
README.md
pyproject.toml # 或 requirements.txt(入门阶段也可)
.gitignore
src/
myproj/
__init__.py
io/
loaders.py # 数据加载、路径规范、输入校验
core/
config.py # 配置加载(YAML/ENV)
logging.py # 日志初始化
errors.py # 异常分层
etl/
clean.py # 清洗模板
audit.py # 审计与数据质量摘要
features/
build.py # 特征工程
modeling/
train.py # 训练
infer.py # 推理
metrics.py # 指标与评估
viz/
charts.py # 图表模板
configs/
default.yaml
dev.yaml
prod.yaml # 若有部署场景
data/
raw/ # 原始数据(只读)
interim/ # 中间产物(可删)
processed/ # 清洗后/特征后数据
external/ # 外部来源数据(可选)
notebooks/
00_index.ipynb
01_eda.ipynb
02_pipeline.ipynb
tests/
test_etl_clean.py
test_metrics.py
scripts/
run_etl.py
run_train.py
run_eval.py
runs/
2026-01-10_1030/
params.json
metrics.json
log.txt
artifacts/
reports/
figures/
tables/
report.md这套结构的核心是:
src/放"可复用的真逻辑"configs/放"可迁移的参数与环境差异"data/分层管理数据生命周期tests/保障长期可维护性runs/与reports/负责交付闭环
3. 四大核心目录:你必须知道每个目录的边界
下面我们逐一拆解 src/、configs/、data/、tests/ 的"黄金规则"。
3.1 src/:项目唯一真相(Single Source of Truth)
src/ 里放的是:可复用、可测试、可维护的核心代码。
src/ 的三条硬规则
规则 1:Notebook 不允许出现核心逻辑
Notebook 可以调用 src/,但核心逻辑必须下沉。
规则 2:入口脚本不写业务逻辑
scripts/run_train.py 只负责:解析参数 → 调用 src/ → 落盘输出。
真正的训练逻辑在 src/myproj/modeling/train.py。
规则 3:模块按职责划分,不按步骤划分
不推荐 step1.py/step2.py,推荐 etl/clean.py、modeling/train.py 这种"职责稳定"的结构。
Mermaid:src/ 的调用关系建议
scripts/run_train.py 入口
myproj.core.config 读取配置
myproj.io.loaders 读取数据
myproj.etl.clean 清洗
myproj.features.build 特征工程
myproj.modeling.train 训练
myproj.modeling.metrics 评估
runs// 产物落盘
你只要坚持这个结构,项目就不会失控。
3.2 configs/:参数从代码里拔出来,项目才可迁移
configs/ 的目标是:让"同一份代码"在不同环境下工作。
典型要放进配置的东西包括:
- 数据路径与输入格式
- 清洗规则(列名、缺失值策略、阈值)
- 模型超参(seed、训练轮数、阈值)
- 输出目录(runs/reports 路径)
- 日志级别(INFO/DEBUG)
配置管理的最小建议(别一开始搞复杂)
你可以从 configs/default.yaml 开始,未来再扩展多环境配置。
yaml
# configs/default.yaml
project:
name: myproj
run_dir: runs
data:
input_path: data/raw/sample.csv
output_path: data/processed/clean.csv
train:
seed: 42
test_size: 0.2
logging:
level: INFO关键收益:
当你把参数写进 YAML,你的项目就具备了"可迁移性"和"可复现记录能力"(因为 params 可以落盘)。
3.3 data/:数据必须分层,否则你永远不知道"哪个是最终结果"
数据目录最常见的灾难是:所有文件混在一起,谁也不知道哪个可删,哪个是原始输入,哪个是最终结果。
我建议用"四层"模型,足够通用:
raw/:原始数据,只读,不修改interim/:中间产物,可删(cache)processed/:清洗后、可复用的数据external/:外部数据源(可选)
Mermaid:数据生命周期示意
data/raw 原始输入
etl.clean 清洗
data/processed 清洗后数据
features.build 特征数据
model.train 模型与指标
runs/ 运行产物
reports/ 可交付报告
一句话规则:
raw 不动,processed 可复用,interim 可随时重建。
3.4 tests/:你不需要高覆盖率,但必须能防止"自己坑自己"
很多同学抗拒测试,觉得浪费时间。我的观点很明确:
科研/数据项目不追求 90% 覆盖率,但必须有最小测试来防回归。
tests/ 最小要求(建议你抄走)
至少覆盖三类:
- 数据契约测试:列名、类型、缺失率是否符合预期
- 关键函数测试:清洗、特征、指标计算的核心逻辑
- 回归测试:同样输入时,关键指标不应无故漂移
示例测试(非常简化版):
python
def test_clean_keeps_required_columns():
import pandas as pd
from myproj.etl.clean import clean_df
df = pd.DataFrame({"a": [1, None], "b": [2, 3]})
out = clean_df(df)
assert set(out.columns) == {"a", "b"}你只要坚持写这种"最小断言",项目长期可维护性会明显提升。
4. scripts/ 与 notebooks/:它们的定位必须明确
很多项目乱,是因为 scripts/ 和 notebooks/ 混入了业务逻辑。
scripts/:只做入口,不做业务
scripts 的职责是:
- 解析参数
- 读取配置
- 调用 src
- 落盘 runs/reports
notebooks/:只做叙事与探索
Notebook 的职责是:
- 探索数据
- 展示过程
- 解释结果
- 调参对比(但核心逻辑仍在 src)
你可以把 Notebook 当成"论文的叙事载体",把 src 当成"真正可交付的工程"。
5. runs/ 与 reports/:交付闭环的关键,不是摆设
如果你只搭了 src/configs/data/tests,却没有 runs/reports,你依然会在交付时被卡住。原因是:你缺"证据链"。
runs/:一次运行 = 一个可追溯目录
建议命名:runs/YYYY-MM-DD_hhmm/
必须包含(最低要求):
- params(本次运行用的配置快照)
- metrics(指标输出)
- log(日志)
- artifacts(模型、图表、导出文件)
reports/:面向人类的交付物
- figures/ 图
- tables/ 表
- report.md / report.pdf
你要区分清楚:
runs 是给你自己和机器看的;reports 是给导师/客户/评审看的。
6. 常见坑与"强制规避策略"
坑 1:把路径写死在代码里
策略:路径必须进 configs,并由 core/paths.py 统一解析。
坑 2:把业务逻辑塞进 scripts
策略:scripts 只允许 80 行以内,超过就说明你在写业务逻辑了,必须下沉 src。
坑 3:data/ 里混进 runs 产物
策略:运行产物只进 runs,不进 data。data 只放"可复用数据"。
坑 4:Notebook 变成垃圾场
策略:Notebook 超过 10 个且没有编号,基本宣告失控。
强制用 00_ 01_ 02_ 编号,且每个 Notebook 都应对应一个明确目的。
7. 本章最低交付(MDR):你必须交付什么?
按照专栏"学习协议",本章完成后你至少交付:
- 一个符合黄金布局的项目骨架(含 src/configs/data/tests)
- 一个能跑通的最小流水线:读入 → 清洗 → 输出(哪怕只处理 sample 数据)
- 一次 runs 落盘(params/log/artifacts 至少具备)
- 一个最小 pytest 测试(至少 1 个断言)
- README 写清楚:如何安装、如何运行、输出在哪里
你做到这些,你的项目就真正开始"像工程"了。
8. 小结:目录结构不是形式,是你长期复利的起点
你会发现:当你采用标准目录结构后,很多问题会自动消失:
- 导入不再玄学
- 参数不再散落
- 数据不再混乱
- 运行产物可追溯
- 合作者知道怎么跑
- 作品集看起来像真实工程项目
下一章我们会把 configs 再进一步工程化:用 YAML/ENV 做配置管理,让项目真正做到"可迁移"。
《第五章 配置管理:用 YAML/ENV 让项目可迁移》
如果你愿意,把你现在项目的目录结构贴出来(截图或文字都行),我可以按本章的黄金布局给你做一次"最小改造方案":保留你现有内容,尽量少移动文件,但让项目立刻具备可维护与可复现的工程结构。