Cursor 等 AI IDE 在 2025 年快速普及,显著降低了写代码的成本,却没有自动降低对齐规范、验证质量、跨人协作的系统成本,导致进入一种高波动的对话式编程陷阱:生成很快、返工更多、交付不稳。
本文提出一个可落地的工程范式:AI 工程化,把 AI 从聊天式代码生成器升级为在工程约束内执行交付的引擎。 以 Spec 驱动 + 自动化验证闭环 + 规则资产化 + 错误知识沉淀 为核心,通过可审计、可复现的交付流程,实现效率与质量的同步提升。
一、引言:Cursor 普及之后,为什么更先进反而更累?
"我有Cursor,但我依然在重复劳动。"
这是2025年许多开发者的真实写照。当我们从传统的IDE切换到Cursor时,以为拥有了AI超能力,却发现实际工作流程变成了这样:
css
需求一句话描述 → AI 生成一堆通用代码
跑起来发现不符合项目架构、封装规范、权限/埋点规则
人工修补 + 再追问修复
修了 A 又引入 B,循环往复这类循环并不是 Cursor 的问题,而是我们把它当作更聪明的代码生成器,却仍用对话式临时交付的方式组织工程生产。对个人小需求,这样或许足够,但当项目进入多人协作、复杂系统、质量约束的阶段,纯对话会暴露出系统性短板。 它的特征不是AI 不会写,而是写得很快但交付不稳。
二、行业现状:AI IDE 强在生成,弱在交付
AI IDE 的能力并不等价于工程交付能力。
AI IDE 解决了什么?
- 代码生成/补全,如页面骨架、接口调用、常见逻辑、样板代码
- 代码理解,如解释局部逻辑、定位可疑点、给出修改方案
- 局部重构,如改变量名、抽函数、迁移局部写法
AI IDE 没有自动解决什么?
软件交付依赖的关键环节不会因为"能生成代码"而自动成立:
- 架构一致性:分层约束、依赖方向、模块边界、可扩展性
- 非功能约束:性能、稳定性、安全、兼容、可观测性
- 可验证性:构建、测试、静态检查、安全扫描、回归证据
- 可协作性:统一风格、可审查变更、可复现流程、可沉淀经验
AI IDE 把编码成本降下来了,但对齐成本、验证成本、协作成本并没有自动下降。 这也解释了为什么很多人体验是局部变快、整体不稳。
三、问题剖析:为什么提问式编程效率不高
不少人把问题归结为"提示词写得不好"。但从工程角度上,更常见的根因是:输入不可执行、输出不可验收、过程不可复现。具体体现在四类系统性问题。
3.1 上下文缺失:AI 看到的是文件,不是系统
AI 不知道你们的工程现实:
- 代码规范(命名、异常、日志、埋点、线程/生命周期)
- 基础设施(网络封装、缓存策略、统一错误码、鉴权)
- 业务规则(权限模型、灰度开关、风控限制、边界场景)
- 历史包袱(兼容逻辑、技术债、隐式约定)
于是 AI 更容易给出通用正确,而不是在你们项目里正确。
3.2 无法验证:缺少自动验收,需开发人员自行验证兜底
对话式生成的最大成本,不在写不出来,而在你不知道它是不是合格:
- 能否编译、构建、打包?
- 能否通过单测、回归、快照?
- 是否破坏权限、埋点、缓存、兼容?
- 是否引入安全风险(敏感日志、注入、越权)?
如果验证不自动化,就会形成AI 生成,需要人来验收的低效模式。
3.3 不可复现:同需求不同天、不同人、不同模型,输出不同
工程需要确定性,但对话是即时态:
- 提示词风格变了,输出就变
- 模型版本变了,输出就变
- 少引用一个文件,输出就偏
最终团队很难形成可复制产线。
3.4 无法协作:个人提示词难以变成团队制度
团队协作需要统一语言:
- 目录职责边界、组件模式、接口契约
- PR 模板、验收清单、风险说明
- 错误复盘、知识库、规范迭代机制
而个人提示词很难演进成团队资产,AI 只能为个人提效。
四、对话式陷阱 vs 工程化闭环
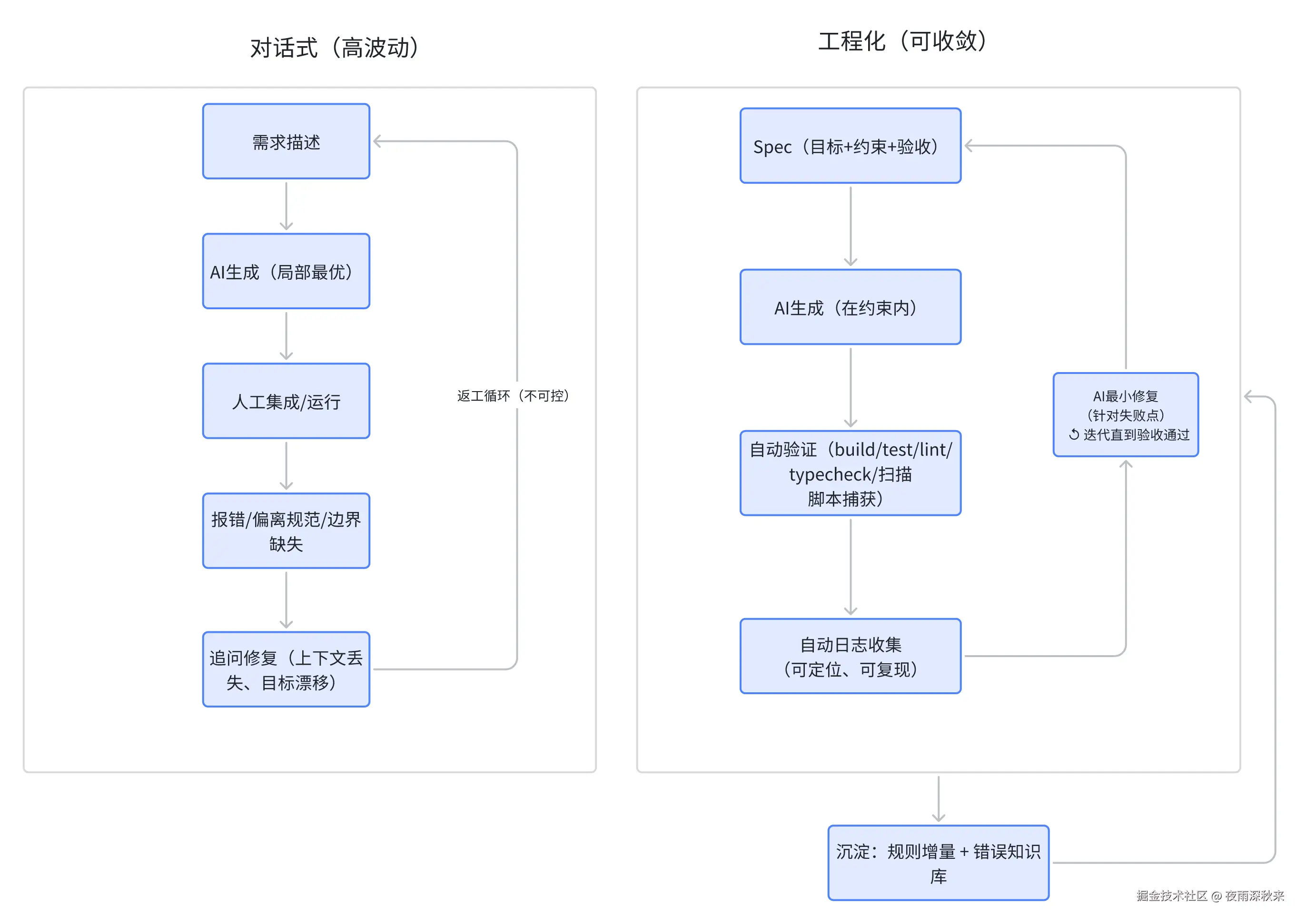
工程化的关键不是让 AI 一次做对,而是让"错误暴露更快、修复输入更准确、迭代更可收敛"。
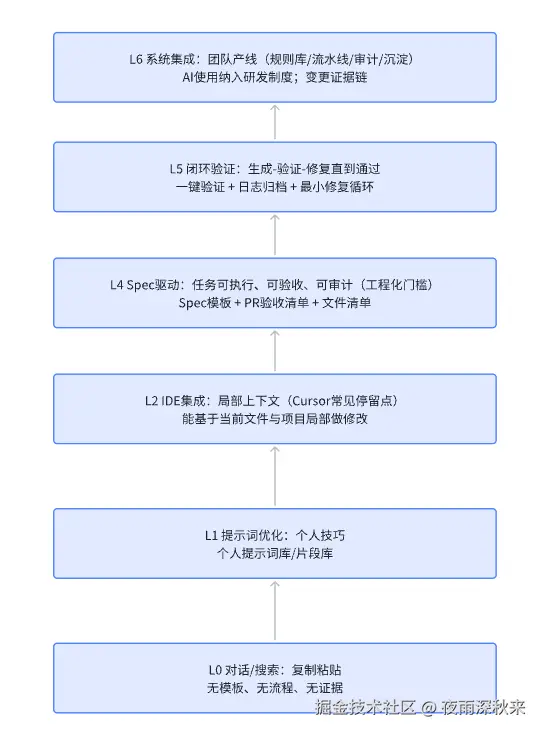
五、能力成熟度模型
个人使用cursor开发获得的项目级经验很难变成团队资产,为了便于团队落地,把能力分级从"行为描述"升级为"组织资产模型"。
六、AI 工程化核心要素
主要包括规则资产化、Spec 驱动、验证闭环、知识沉淀。
6.1 基本框架:
规则资产化,梳理团队编程规则,项目级别规则以及项目组织架构形成模型可读文档:
css
project-context.md:架构、技术栈、目录职责、关键约定
code-style.md:命名、异常处理、日志/埋点、注释规范
component-patterns.md:页面骨架、组件拆分、状态管理模式
api-conventions.md:请求封装、错误码、重试/降级/缓存策略
security-checklist.md:敏感信息、权限校验、输入输出处理
observability.md:埋点、日志字段、Trace/Span 约定(如有)Spec 驱动开发,把需求变成可执行的任务单 对比两种输入:
低质量输入:"帮我写个用户管理页面"
工程化输入(Spec):明确目标、约束、文件清单、边界、验收标准Spec 模板:
【任务ID】:
【背景/目标】(用户可感知):
【范围】(包含/不包含):
【技术约束】(必须/禁止):
【文件清单】(新建/修改):
【边界与失败策略】(空态/权限/网络/兼容):
【验收标准】
构建:
测试:
静态检查:
安全/合规:
关键用例:自动化验证闭环 闭环的核心是:生成之后立刻验证,失败之后用日志驱动最小修复。 不需要一开始就把所有测试做齐,建议按"最小可行验证"逐步扩展:
bash
第 1 阶段:lint / format / typecheck(最快暴露低级错误)
第 2 阶段:build(暴露依赖、打包、资源、编译问题)
第 3 阶段:unit test / snapshot(暴露逻辑回归)
第 4 阶段:e2e / 集成测试(暴露关键路径)知识沉淀,把每次失败变成下次成功的先验 建立错误知识库(可按模块/类型组织):
记录:错误现象、根因、最小修复、如何预防、关联规则
把预防写回规则资产(规则增量机制)
下一次 Spec 默认引用相关规则,降低重复踩坑6.2 实践要素:
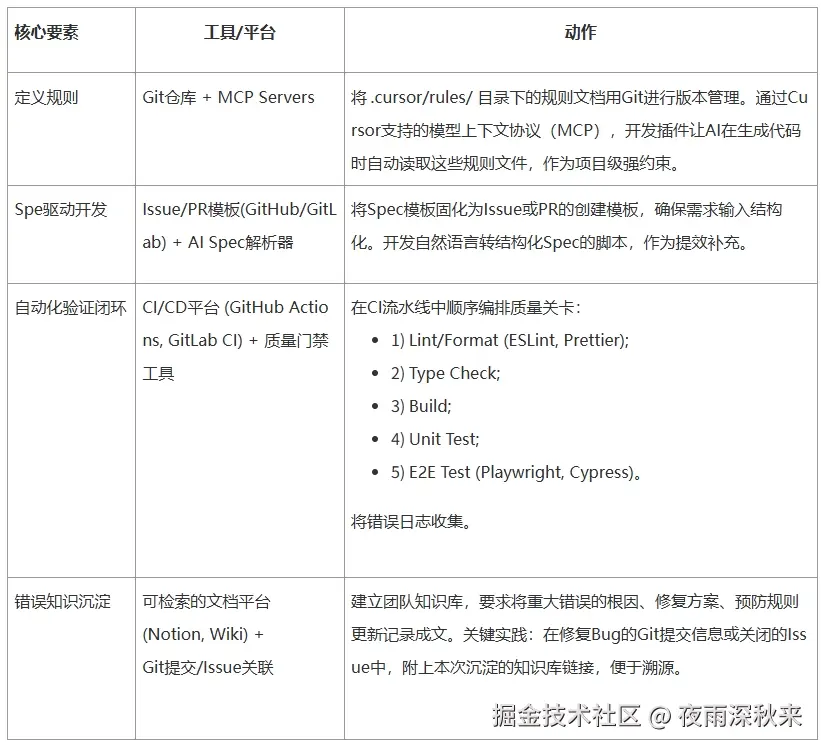
6.3 工程实践流程:

七、AI 工程化接下来会走向哪里?
结合过去两年的工具演进: 1、提示词工程退潮,规格/契约工程上升 组织会把经验沉淀为模板与契约,而不是靠个人技巧。 2、AI 从助手变成流水线节点 AI 将更紧密地连接构建结果、测试失败、扫描报告、依赖风险,成为交付链路的一环。 3、可审计成为默认门槛 未来评审不仅看代码,也看证据链,验证结果、风险说明、影响范围、回滚策略等。
八、结语:开发者角色升级,不是被替代
当我们从指令式编程走向AI 工程化,变化不在于谁写代码,而在于谁定义系统:
- 开发者从代码生产者升级为交付系统设计师
- 价值从写得快转向交付稳、可复制、可审计
- AI 从生成答案转向在约束内持续迭代直到通过验收
AI 工程化的终点不是 AI 取代人,而是:人负责定义规则与质量边界,AI 负责在边界内高效率执行。 这才是 Cursor 这类工具真正能释放的长期生产力。