今天不讲玄学,就把这张图拆透。看完能画出来,面试稳过。
看不懂没关系,看完这篇就懂了。
━━━━━━━━━━━━━━━━━━━━
◆ 先说历史:Transformer 本来是个翻译机
━━━━━━━━━━━━━━━━━━━━
2017 年,Google 的 8 个工程师发了篇论文《Attention Is All You Need》。
他们的目标很简单:做一个翻译机,把英语翻成德语。
很多人以为 Transformer 最早是 BERT,其实不是。BERT 是 2018 年的事儿,比原版 Transformer 晚了一年。原版就是个翻译模型,没那么多花活。
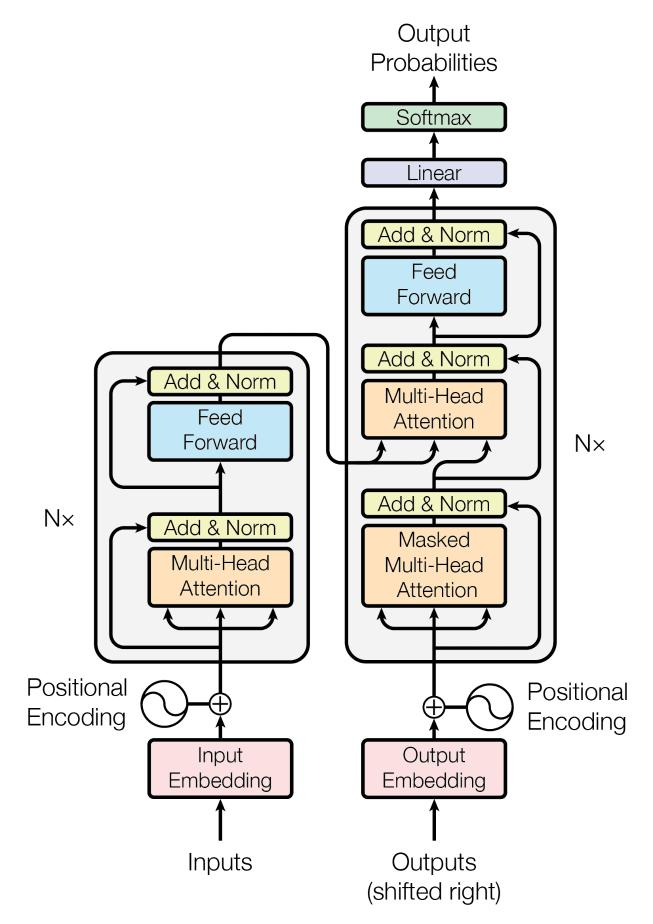
所以原版 Transformer 长这样:
▸ 左边:Encoder(编码器)------ 读原文
▸ 右边:Decoder(解码器)------ 写译文
「边读边写,读完再写。」
这就是为什么图里有两个框:左边是 Encoder,右边是 Decoder。
(剧透:现在的 GPT、Claude、Llama 都只用右半边 Decoder,左边 Encoder 基本没人用了。但面试还是会考原版架构,所以两边都得懂。)
━━━━━━━━━━━━━━━━━━━━
◆ Encoder:读原文的那一半
━━━━━━━━━━━━━━━━━━━━
看图左边的框。
从下往上看:
────────────────────
【第一步:Embeddings(词嵌入)】
把文字变成数字。
"Hello" → 0.2, -0.5, 0.8, ...(一串数字,叫向量)
每个词变成一个向量,维度取决于模型大小:原版论文是 512,BERT 是 768,DeepSeek 是 7168,GPT-4 级别的可能到 12288。
────────────────────
【第二步:Positional Encoding(位置编码)】
告诉模型"这是第几个词"。
为什么需要?因为 Transformer 是并行处理的,不像 RNN 一个一个读。它一眼看到所有词,但不知道顺序。
位置编码就是给每个词打上"第 1 个"、"第 2 个"的标签。
原版用的是正弦波(sin/cos),现在流行的是 RoPE(旋转位置编码)。
────────────────────
【第三步:Multi-Headed Self-Attention(多头自注意力)】
这是 Transformer 的核心。
「Self」= 自己看自己。每个词都看一眼句子里的其他词,决定"谁跟我最相关"。
「Multi-Headed」= 把维度切成多份,每份独立算 Attention,最后拼回来。至于每个头"学到了什么关系"------没人知道,模型自己学的。那些论文里说"第一个头学了语法"、"第二个头学了语义",都是看着 attention 可视化图硬编的故事,别信。
比如"我吃苹果":
▸ "吃"会重点关注"我"(谁在吃)和"苹果"(吃什么)
▸ "苹果"会重点关注"吃"(被怎么了)
这就是"注意力"的含义:不是平均看,而是有重点地看。
────────────────────
【Q、K、V 是什么?】
图里每个 Attention 框下面都有三个箭头:V、K、Q。
这三个东西是同一个输入向量,经过三个不同的线性变换得到的:
```
Q = 输入 × W_Q (W_Q 是可学习的权重矩阵)
K = 输入 × W_K
V = 输入 × W_V
```
为什么要拆成三份?因为"用来匹配"和"用来输出"是两件不同的事:
▸ Q 和 K 用来算相关度------"我该看谁?"
▸ V 用来提供实际内容------"看到了之后拿什么?"
历史演化:
▸ 不拆(最原始):自己和自己最像,没用
▸ 拆成 2 份(2014 年 Bahdanau Attention):Q 和 K 共用,V 单独,能用了
▸ 拆成 3 份(2017 年 Transformer):Q、K、V 各自独立,效果更好
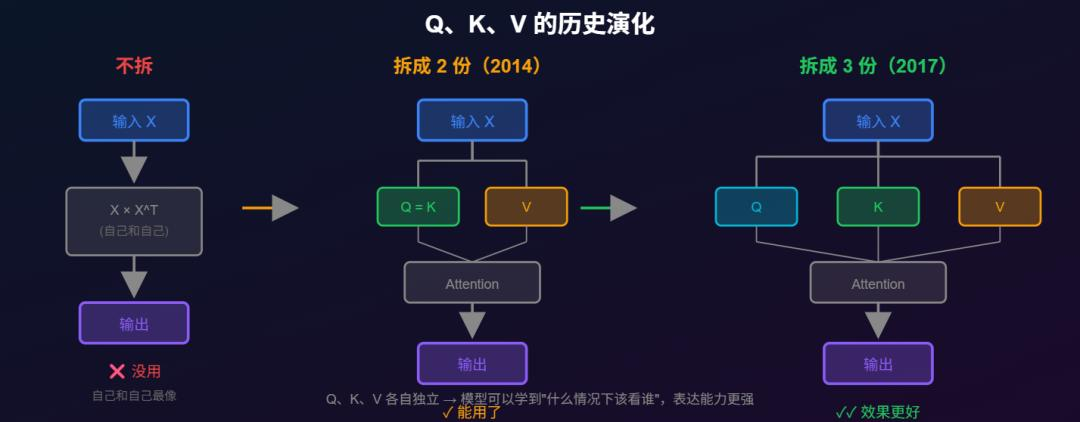
(配图:assets/qkv-evolution.svg)
Attention 做的事:用 Q 去匹配所有的 K,匹配度高的位置,就多拿一点那个位置的 V。
数学上:Attention(Q, K, V) = softmax(Q x Kᵀ / √d) x V
▸ Q x Kᵀ:算每对词的相关度(矩阵乘法)
▸ √d:除以维度的平方根,防止数字太大
▸ softmax:把相关度变成"注意力权重"(每行加起来等于 1)
-
注意:这不是词表概率,是"我该看哪些位置"的权重
-
假设句子有 100 个 token,输出是 100×100 的注意力矩阵
-
每一行是一个 token 对所有 100 个位置的关注度,比如 0.01, 0.02, 0.3, ..., 0.5, ...
-
意思是"我是第 5 个 token,我看第 3 个位置 30%,看第 50 个位置 50%......"
▸ × V:每个 token 用自己那一行的 100 个权重,对 100 个 V 向量加权求和,得到新表示
────────────────────
【第四步:Add & Norm(残差连接 + 层归一化)】
图里的 Add & Norm 框。
顺便说一句:字节 2024 年发的 Hyper-Connections(HC)、DeepSeek 2025 年底的 mHC(Manifold-Constrained Hyper-Connections,流形约束超连接),改的就是这个地方。
原版 Transformer 就 1 条残差流,每层做「输出 = f(输入) + 输入」,简单粗暴。
HC 的魔改:把简单的残差连接换成更复杂的线性变换------原版是「输出 = f(输入) + 输入」,HC 是「输出 = f(输入) + A·输入」,其中 A 是可学习的混合矩阵。本质上还是残差连接,只是从"直接加"变成了"加权混合"。
残差连接看着简单(就一个加法),但魔改空间很大。
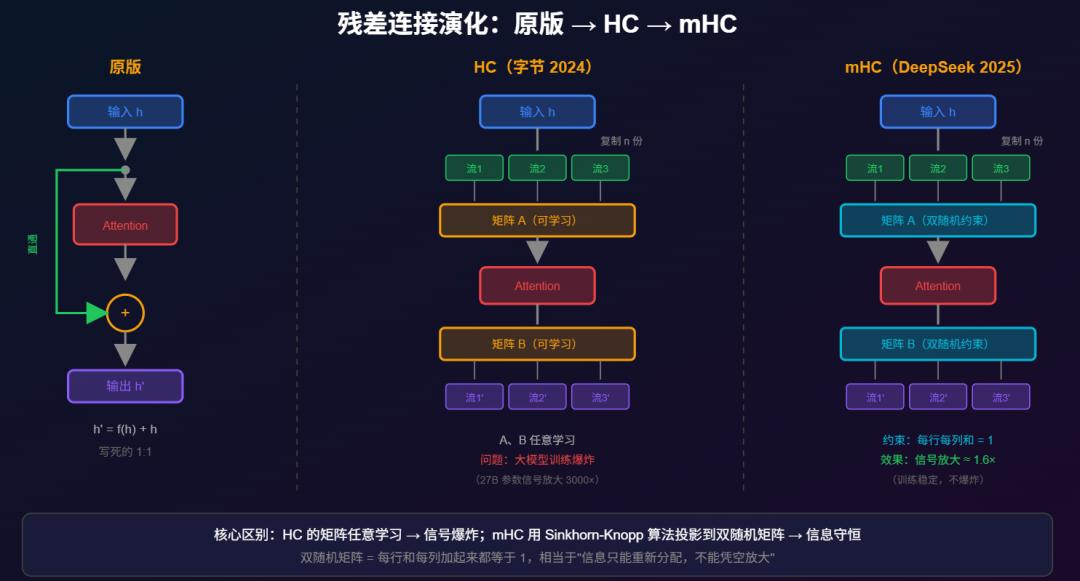
(配图:assets/hc-explain.svg)
(吐槽:mHC 名字叫"Manifold",但实际用的是 Birkhoff Polytope------双随机矩阵构成的凸多面体。凸多面体有角有棱,严格来说不是流形。流形的定义是"局部像欧几里得空间",但多面体的顶点和棱边处不满足这个条件。叫"Polytope-Constrained"更准确,但没"Manifold"听起来高大上。学术营销嘛,懂的都懂。详见:
https://en.wikipedia.org/wiki/Manifold)
▸ Add(残差连接):把输入直接加到输出上
输出 = Attention(输入) + 输入
为什么?防止信息丢失。就像抄作业时顺便把原题也抄上,万一算错了还能回头看。
▸ Norm(层归一化):把数字拉回正常范围
神经网络算着算着,数字会越来越大或越来越小。LayerNorm 把每一层的输出"标准化",让训练更稳定。
────────────────────
【第五步:Feed-Forward Network(前馈网络)】
图里的 Feed Forward 框。
就是两层全连接:
输出 = W₂ × ReLU(W₁ × 输入 + b₁) + b₂
人话:先放大 4 倍(512 → 2048),过一个激活函数,再缩回来(2048 → 512)。
注意区分:
▸ W₁ 和 W₂ 是**权重矩阵**(模型参数),形状固定:W₁ 是 512×2048,W₂ 是 2048×512
▸ 隐藏层是**中间结果**(向量/矩阵),形状取决于输入:1 个 token 就是 2048 维向量,100 个 token 就是 100×2048 矩阵
▸ ReLU 是逐元素操作(负数变 0),不改变形状
为什么要放大再缩小?给模型一个"思考空间"。放大时展开信息,缩小时压缩精华。
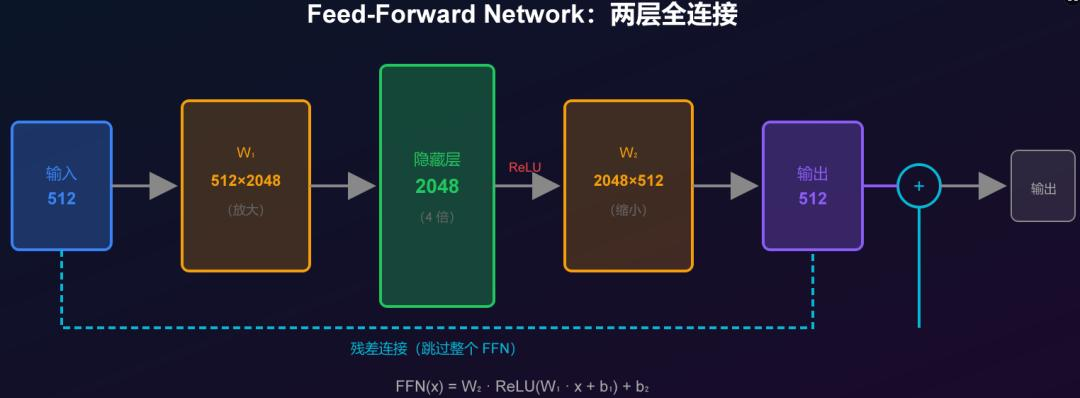
(配图:assets/ffn-explain.svg)
────────────────────
【第六步:重复 N 次】
图里写的"Nx Layers"。
原版论文是 6 层。现在的大模型动辄 32 层、64 层、128 层。
每一层都是:Attention → Add & Norm → FFN → Add & Norm
堆得越多,模型越"深",理解能力越强(理论上)。
━━━━━━━━━━━━━━━━━━━━
◆ Decoder:写译文的那一半
━━━━━━━━━━━━━━━━━━━━
看图右边的框。
Decoder 比 Encoder 多一个东西:它有「三件套」,不是两件套。
────────────────────
【第一件:Masked Multi-Headed Self-Attention(红色框)】
和 Encoder 的 Self-Attention 几乎一样,但多了一个"Mask"(遮罩)。
为什么要遮?
因为 Decoder 是在「生成」译文,一个词一个词往外蹦。
写第 3 个词的时候,第 4、5、6 个词还没生成呢------不能偷看未来。
Mask 的作用:把"未来"的位置遮住,Attention 只能看前面,不能看后面。
训练 vs 推理:
▸ **训练时**:模型一次看整句话,同时预测所有位置------必须 Mask,否则能偷看答案
▸ **推理时**:一个 token 一个 token 生成,后面的根本还没有------Mask 其实多余,但保留这个概念
「这就是为什么 GPT 只能往前写,不能往回改。」
────────────────────
【第二件:Multi-Headed Cross-Attention】
(注:这是原版 Encoder-Decoder 架构才有的。现在的 GPT、Claude、Llama 都是 Decoder-Only,**没有这一层**------因为根本没有 Encoder 了。但面试可能会考原版,所以还是得懂。)
这是 Encoder 和 Decoder 之间的桥梁。
注意看图:Cross-Attention 的 K 和 V 是从左边 Encoder 引过来的,只有 Q 是 Decoder 自己的。
什么意思?
▸ Q 来自 Decoder:我现在要写什么?
▸ K、V 来自 Encoder:原文说了什么?
「Decoder 拿着自己的问题,去 Encoder 那里找答案。」
这就是"边看原文边写译文"的实现方式。
翻译"我爱你"→"I love you"时:
▸ 写"I"的时候,Q 问"主语是谁",去 Encoder 找,发现"我"最相关
▸ 写"love"的时候,Q 问"动词是什么",去 Encoder 找,发现"爱"最相关
▸ 写"you"的时候,Q 问"宾语是谁",去 Encoder 找,发现"你"最相关
(注:这是 2017 年原版 Encoder-Decoder 的设计思路,那时候 Q、K、V 的含义人类还能理解。但 Encoder-Decoder 这个结构现在纯粹是个古董------GPT、Claude、Llama 全是 Decoder-Only,根本没有 Cross-Attention。后来 Google 的 T5(2019)还在坚持用 Encoder-Decoder,但也没挡住 Decoder-Only 一统天下。面试还在考这个,大家都在硬背一个已经被淘汰的设计。)
────────────────────
【第三件:Feed-Forward Network】
和 Encoder 一样,两层全连接,放大再缩小。
────────────────────
【最后:Linear + Softmax(输出层)】
图最上面。
▸ Linear:把向量(512 或 768 维)投影到词表大小(比如 50000 个词,输出就是长度 50000 的向量)
▸ Softmax:变成概率分布,50000 个词各自的概率,加起来等于 1
这里的 Softmax 才是真正映射到词表的概率------和前面 Attention 里的 Softmax(token 之间的注意力权重)不是一回事。
━━━━━━━━━━━━━━━━━━━━
◆ Pre-LN vs Post-LN:Norm 放哪里?
━━━━━━━━━━━━━━━━━━━━
仔细看图,Norm 是放在 Attention「前面」还是「后面」?
原版论文(2017):Post-LN
输出 = Norm(Attention(输入) + 输入)
先做 Attention,再加残差,最后 Norm。
现在主流(2020 后):Pre-LN
输出 = Attention(Norm(输入)) + 输入
先 Norm,再做 Attention,最后加残差。
「图里画的是原版 Post-LN。」
为什么现在都用 Pre-LN?
▸ 训练更稳定,不容易梯度爆炸
▸ 可以堆更多层(Post-LN 堆到 12 层就开始炸)
▸ 代价是理论上表达能力稍弱,但实践中无所谓
━━━━━━━━━━━━━━━━━━━━
◆ 现代演化:为什么现在不需要 Encoder 了?
━━━━━━━━━━━━━━━━━━━━
2017 年的原版 Transformer:Encoder + Decoder,两个框都要。
现在的 GPT、Claude、Llama:只有 Decoder,没有 Encoder。
为什么?
────────────────────
【历史原因】
原版是为了翻译设计的。翻译任务有两个独立的序列:
▸ 输入:英语句子(Source Sequence)
▸ 输出:德语句子(Target Sequence)
两个序列长度不一样,语言不一样,需要两个独立的处理器。
────────────────────
【现代做法】
现在的大模型把所有任务都变成了"续写":
▸ 翻译:"Translate: Hello → ",模型续写"你好"
▸ 问答:"Question: 什么是AI?Answer: ",模型续写答案
▸ 代码:"Write a function that sorts a list:\n",模型续写代码
「一切皆续写。」
既然是续写,就不需要两个独立的序列了。输入和输出拼成一个长序列,Decoder 自己处理就行。
────────────────────
【Decoder-Only 的优势】
▸ 架构更简单:少了 Encoder 和 Cross-Attention
▸ Scaling 友好:参数都集中在一个地方,堆得更高
▸ 通用性强:翻译、问答、写代码,同一个架构全搞定
────────────────────
【代价】
▸ 不能双向看:只能看前面,不能看后面
▸ 对某些任务(比如情感分类)不如 BERT 这种双向模型
但实践证明:更多参数压倒一切。Decoder-Only 架构更简单,参数更集中,堆得更高,赢了。
━━━━━━━━━━━━━━━━━━━━
◆ 三种架构总结
━━━━━━━━━━━━━━━━━━━━
Encoder-Decoder Encoder-Only Decoder-Only时间 2017 年 2018 年 2018 年+代表模型 原版Transformer BERT GPT/Claude/LlamaAttention 方向 Encoder双向+Decoder单向 双向 单向(只看前面)擅长 翻译/摘要 理解 生成现状 特定任务 式微 主流「2026 年的世界:Decoder-Only 一统天下。」
━━━━━━━━━━━━━━━━━━━━
◆ 再看一遍这张图
━━━━━━━━━━━━━━━━━━━━
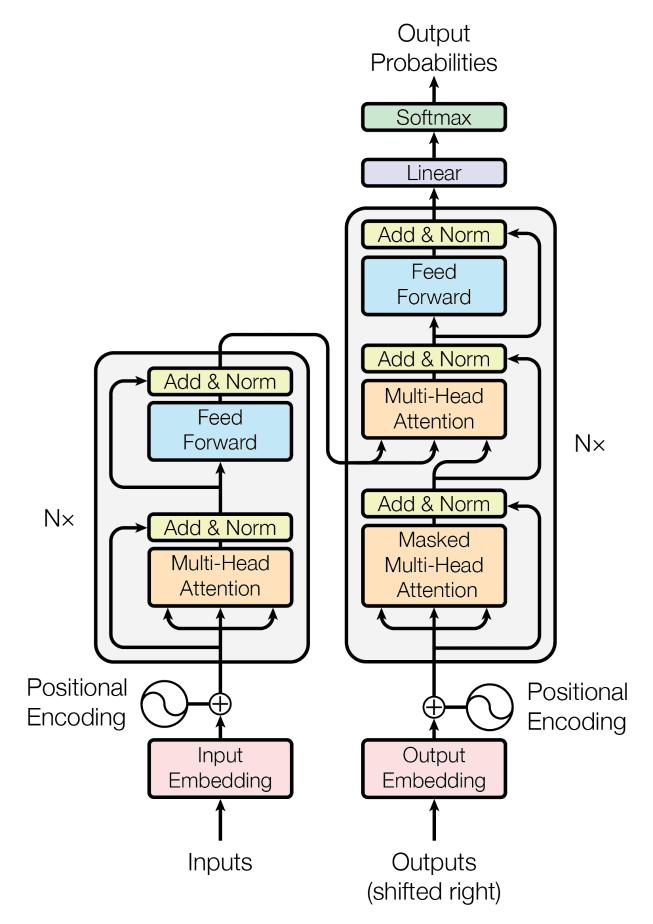
(配图:
assets/basic-transformer.png)
现在你应该能看懂了:
▸ 左边(Encoder):读原文,双向 Self-Attention
▸ 右边(Decoder):写译文,三件套
-
Masked Multi-Head Attention(只看前面)
-
Multi-Head Attention(Cross-Attention,去 Encoder 那里找信息)
-
Feed Forward
▸ Add & Norm:残差连接 + 层归一化
▸ 最下面:词嵌入 + 位置编码
▸ 最上面:输出层,预测下一个词
「这就是 2017 年那篇论文画的图。」
后来的 GPT 砍掉了左边。
后来的 BERT 砍掉了右边。
但核心思想没变:Self-Attention + 残差连接 + LayerNorm。
━━━━━━━━━━━━━━━━━━━━
◆ 一些细节(想深入的可以看)
━━━━━━━━━━━━━━━━━━━━
────────────────────
【为什么要除以 √d?】
Attention 公式里有个 √d(d 是维度)。
原因:高维空间里,两个随机向量的点积会变得很大。
维度 = 512 时,点积的期望值是 512。
维度 = 4096 时,点积的期望值是 4096。
Softmax 对大数字很敏感------数字太大,概率就变成 one-hot(只有一个是 1,其他全是 0)。
除以 √d 是为了把点积拉回正常范围,让 Softmax 输出更平滑。
────────────────────
【为什么是"多头"?】
Multi-Head 的意思是:把 Q、K、V 切成 8 份(或 16 份、32 份),每份独立做 Attention,最后拼起来。
总维度不变:假设总维度 512,8 个头,每个头就是 512/8=64 维。8 个头各自算完,concat 回 512。
为什么要多头?一个头只有一组 Q、K、V 投影,多头 = 多组投影 = 多种"看法"并行。
(前面说过了:网上那些"头 1 学语法、头 2 学语义"都是瞎猜的。有研究发现砍掉一半的头模型照样能跑。)
────────────────────
【位置编码的演化】
原版(2017):正弦波位置编码,加到词向量上
PE(pos, 2i) = sin(pos / 10000^(2i/d))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d))
现在主流:RoPE(旋转位置编码),乘到 Q 和 K 上
RoPE 的优势:
▸ 外推能力强:训练 4K 长度,推理能支持 128K
▸ 相对位置:只关心"第 5 个词和第 3 个词差 2 个位置",不关心绝对位置
这就是为什么现在的大模型能处理超长上下文。
━━━━━━━━━━━━━━━━━━━━
◆ 总结
━━━━━━━━━━━━━━━━━━━━
Transformer 的核心就三个东西:
-
Self-Attention:让每个词都能看到所有其他词
-
残差连接:防止信息丢失
-
LayerNorm:稳定训练
其他都是在这三个东西上做加法:
▸ 多头:多种关系一起学
▸ FFN:给模型一个"思考空间"
▸ Mask:防止偷看未来
▸ Cross-Attention:连接 Encoder 和 Decoder
原版是翻译机,左右两个框。
现在是续写机,只剩右边那个框。
「架构简化了,能力反而更强了。」
这就是 Transformer。没那么神秘。
━━━━━━━━━━━━━━━━━━━━
◆ 延伸阅读
━━━━━━━━━━━━━━━━━━━━
▸ 原论文:Vaswani et al. 2017 "Attention Is All You Need"
https://arxiv.org/abs/1706.03762
▸ 之前写的 No.26:Transformer 是怎么发明的?------回到深度学习的蛮荒时代@2016
(讲历史脉络,从 RNN/LSTM 到 Attention 的演化,最全)
▸ 之前写的 No.35:Transformer 的真相------向量在球面上滑行
(讲 Attention 的几何直觉)
▸ 之前写的 No.39:位置编码------AI 怎么知道"第一个词"和"最后一个词"?
(讲 RoPE 的原理)
━━━━━━━━━━━━━━━━━━━━
◆ 名词解释
━━━━━━━━━━━━━━━━━━━━
Encoder:编码器,读取输入序列,生成中间表示
Decoder:解码器,根据中间表示生成输出序列
Self-Attention:自注意力,让每个位置都能看到序列中的所有其他位置
Cross-Attention:交叉注意力,让 Decoder 能看到 Encoder 的信息
Mask:遮罩,防止 Decoder 偷看未来的位置
残差连接:把输入直接加到输出上,防止信息丢失
LayerNorm:层归一化,让每一层的输出保持在正常范围
FFN:前馈网络,两层全连接,放大再缩小
Multi-Head:多头,把 Attention 切成多份独立计算