【强化学习实战】第十一章:Gymnasium库的介绍和使用(1)、出租车游戏代码详解(Sarsa & Q learning)
本篇只讲 如何使用gymnasium库中内置的 游戏环境,并用Sarsa和Q-learning两种算法,展示出租车调度游戏 案例。至于如何自定义强化学习环境,下一个篇章讲解。
一、Gym内置环境介绍
1、强化学习工具:Gym
我们要评价一个深度学习算法 的优劣,只要让所有算法去跑同一个数据集 ,然后对比结果指标就可以评价一个算法的优劣了。但是强化学习不同于深度学习,要检测一个强化学习算法 的优劣,是让所有算法在相同的环境和条件下 去运行,然后看哪个算法的效果好,这个算法就强大。所以强化学习需要的是一个标准化环境。
gym是OpenAI团队开发的,是最早和最广泛使用的强化学习环境库。但是2021年后OpenAI团队不再更新和维护这个库了,此后Farama基金会接手并升级为gymnasium,所以gymnasium是gym库的后续维护版本,完全兼容gym,我们只需要将import gym替换为import gymnasium as gym即可。也所以本篇其实讲的是gymnasium库,为了书写方便还用gym这个名字,就是后面你都默认gym就是gymnasium就行了。
Gym提供了一个统一的接口来控制和交互各种环境,用于开发和比较强化学习算法的工具包和测试平台。Gym内置了很多游戏的仿真环境,比如出租车游戏、悬崖游戏等,不同的游戏所用的网格、规则、奖励都不一样,适合为强化学习的算法做测试。同时,Gym还提供了页面渲染,可以可视化的查看效果。
这是gymnasium官网: https://gymnasium.farama.org/ 本篇的代码、小例子都是官网的案例。
建议在conda环境 下安装Gymnasium库:pip install gymnasium 。如果import gymnasium as gym不报错就算是安装完毕了。就是这么简单。此后如果仍然出现环境问题,就按照报错提示,百度搜索,基本都可以搞定。
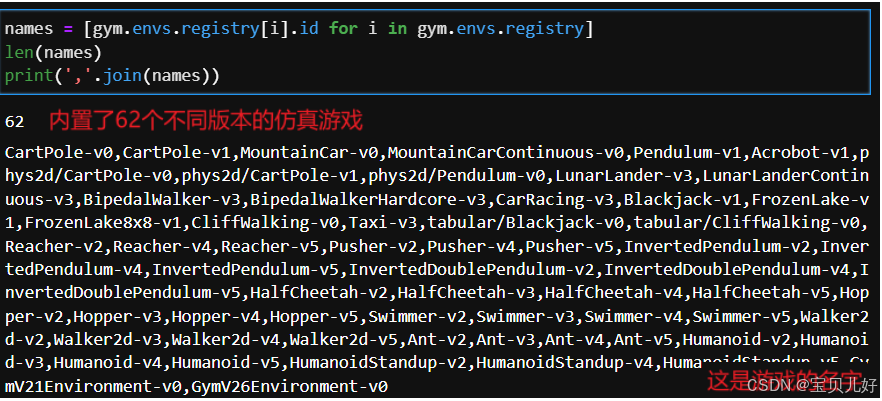
2、Gym内置了哪些仿真游戏的环境?
我们用代码将内置的游戏名都调出,对游戏的名称混个脸熟吧: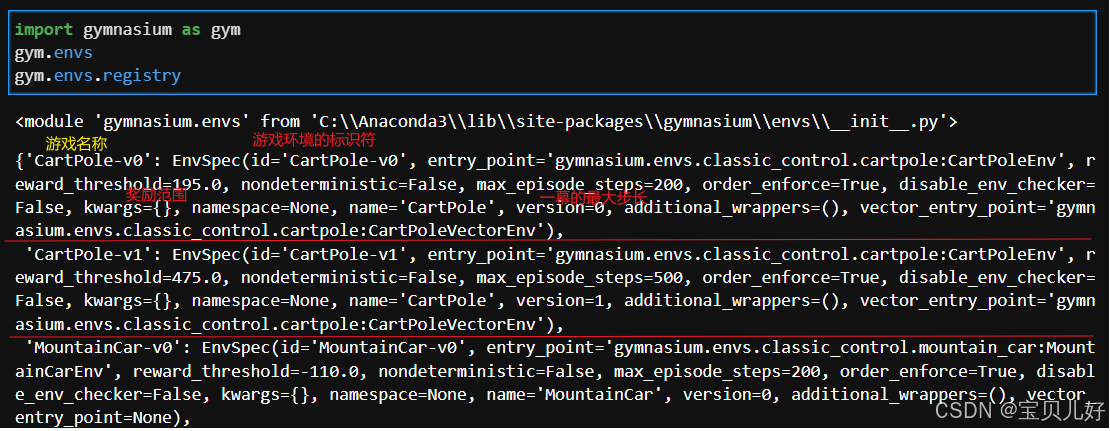
3、官网内置小游戏示例:生成环境->重置环境->执行一步->渲染环境->释放环境
LunarLander-v3 是飞行器着陆月球的小游戏模拟,下面的代码也是gymnasuim官网首页的小游戏:
python
import gymnasium as gym
# 初始化环境 Initialise the environment
env = gym.make("LunarLander-v3", render_mode="human")
#重置环境,获取经验数据 Reset the environment to generate the first observation
observation, info = env.reset(seed=42)
i=1
for _ in range(1000): #走1000步
# 在这里添加你的策略 this is where you would insert your policy
action = env.action_space.sample() #agent在策略下采取动作
# 动作导致环境、系统奖励的变化 step (transition) through the environment with the action
# 下一个state、本次reward、是否到达终止状态、是否要中断、相关信息
#receiving the next observation, reward and if the episode has terminated or truncated
observation, reward, terminated, truncated, info = env.step(action)
# If the episode has ended then we can reset to start a new episode
if terminated or truncated: #如果到达终止状态,或者需要中断,就重置环境。也就是重新开始再来一局游戏
print('第{}轮游戏结束'.format(i))
i+=1
observation, info = env.reset()
env.close() #清空环境代码 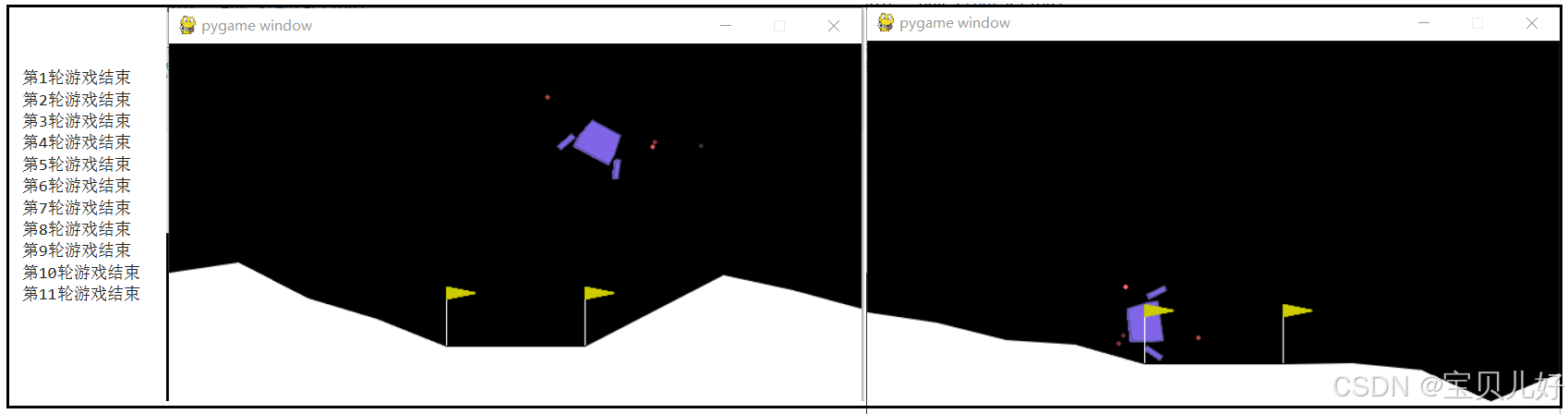 这个小游戏是让飞船随机走1000步,生成了上面11条episodes的经验数据。下面是对上面代码的解读:
这个小游戏是让飞船随机走1000步,生成了上面11条episodes的经验数据。下面是对上面代码的解读:
(1)使用gym.make() 创建一个gym内置的小游戏(LunarLander-v3)的环境实例。第一个参数是游戏的名字。参数render_mode指定如何可视化环境,值有"ansi" / "rgb_array" / "human"。在后面执行env.render()可视化的时候,这里的不同的render_mode值对应着不同的可视化效果。
(2)环境生成后,必须得用env.reset() 重置环境,才能开始游戏。通俗理解就是必须要先回到游戏初始状态,就是从头开始玩游戏。
env.reset()的参数seed是环境的随机种子,相同的种子使实验可复现,不同的种子会让环境内的随机事件不同,如LunarLander-v3游戏中的飞船初始位置、月球表面、着陆的目标区域等会有所不同。
env.reset()返回2个变量:
observation:游戏的初始状态state0。
info :初始状态的相关辅助诊断信息,主要用于调试和debug。
(3)for循环agent是在这个环境中走1000步。当然如果比如agent只走了100步就落到月球表面了,那就game over了,那变量terminated和truncated的值就会变成True,此时执行if语句,就会再重置一次环境,就可以接着从头继续玩游戏了,直到玩1000步,for循环结束,结束游戏。从代码运行结果上看,这1000步游戏,总共玩了11轮episodes,也就是完了11次游戏,当然最后一次游戏可能是玩了一半就强制中断了(truncated)。
(4)在for循环中:
第1步是在既定策略下,用env.action_space.sample() 生成动作。
第2步是用env.step() 执行动作。env.step()返回5个变量:
observation:agent达到的新状态。
reward:agent获得的系统奖励。
terminated:bool值,True or False。True表示游戏正常结束,是step返回的信号,同时环境也停止,agent结束游戏。
truncated:bool值,True or False。True表示游戏非正常中断,是环境发出的截断信号,如果想继续玩游戏,那得调用env.reset()重启环境。如果没有重启,环境也随之自动停止。
info:本步(step)的相关其他辅助信息,方便调试、学习、记录等的一些辅助信息。
(5)说明:Gymnasium的核心是Env类 ,它定义了强化学习环境 的标准接口。所有环境都继承自这个基类,确保了接口的一致性和兼容性。通过gymnasium/core.py文件可以查看Env类的完整定义,其中包含了智能体与环境交互的关键方法。Env类 的主要方法包括:
- env.reset(): 重置环境到初始状态,返回初始观测和信息
- env.action_space.sample() :在某个策略下随机选择动作
- env.step(action): 执行一步动作,返回观测、奖励、终止标志、截断标志和信息
- env.render(): 调用环境数据进行可视化,渲染环境画面。可视化的效果取决于环境的设置,也就是你在gym.make()中的参数render_mode的设置。
- env.close(): 关闭环境,释放资源
上面几种方法记住后,你就可以:生成仿真环境->重置仿真环境->执行一步->渲染环境->释放环境,这些基础操作了。
4、进一步详解环境可视化的几种模式 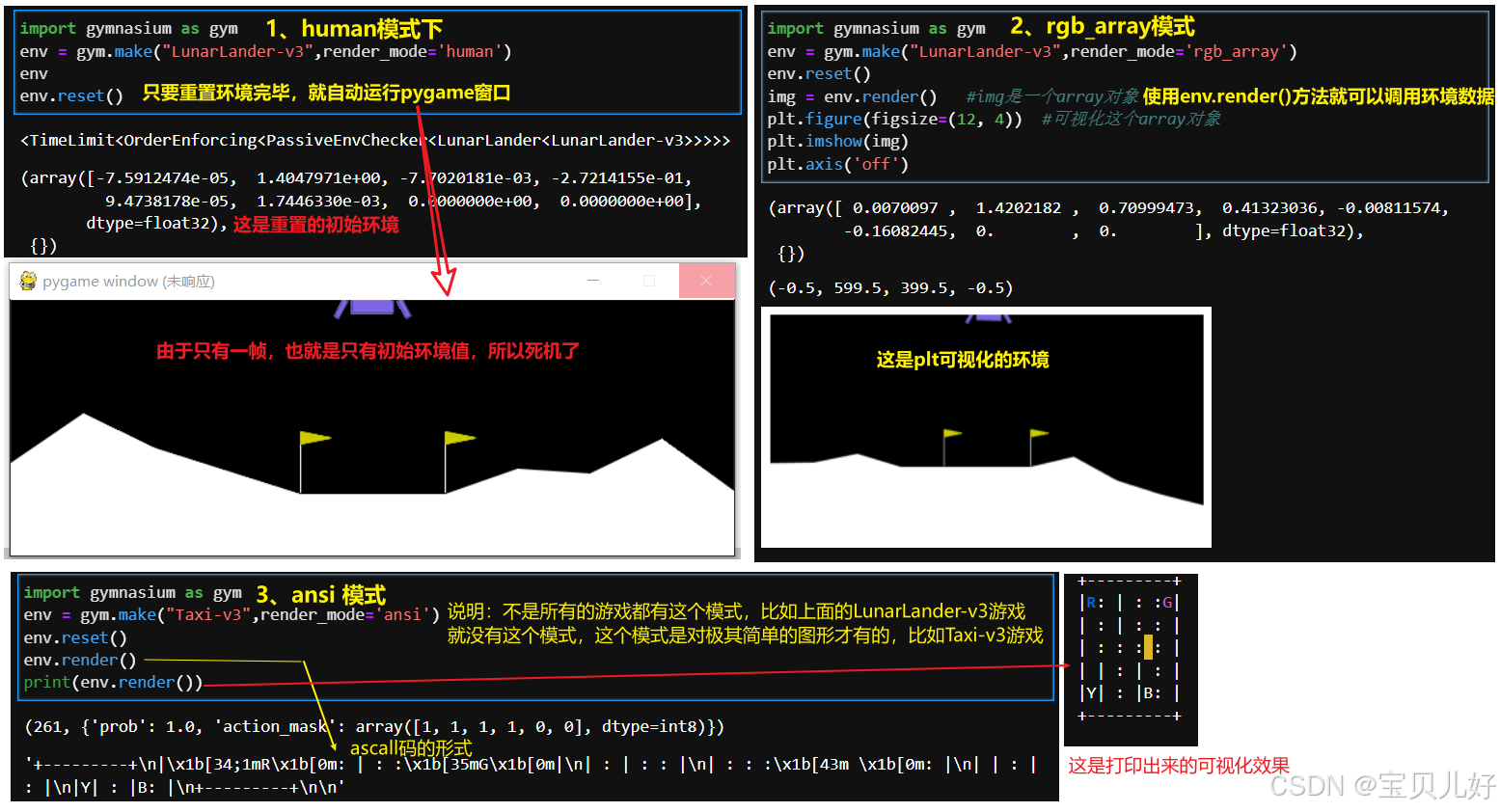 "human"模式是供人观察的模式,环境会自动持续渲染,无需调用render()函数。但是其他模式就得用render函数调用显示了。
"human"模式是供人观察的模式,环境会自动持续渲染,无需调用render()函数。但是其他模式就得用render函数调用显示了。
5、理解agent和环境交互:Agent-Environment Loop  这个训练是强化学习中的最小、最简单的循环,下面代码是用倒立摆(CartPole)游戏的示例。CartPole是强化学习中最经典的控制问题之一,常用于算法验证和教学演示。其核心目标是通过控制小车左右移动,使顶部的杆子保持直立不倒。
这个训练是强化学习中的最小、最简单的循环,下面代码是用倒立摆(CartPole)游戏的示例。CartPole是强化学习中最经典的控制问题之一,常用于算法验证和教学演示。其核心目标是通过控制小车左右移动,使顶部的杆子保持直立不倒。
python
import gymnasium as gym
env = gym.make("CartPole-v1", render_mode="human") #创建倒立摆游戏环境
observation, info = env.reset() #重置环境
print(f"初始状态: {observation}") # [小车的位置, 小车的速度, 杆的角度, 杆的角速度]
episode_over = False
total_reward = 0
step = 1
while not episode_over: #一个episode中,agent和环境之间的交互
#这里可以设置你的策略,但是我们用随机策略,所以不用写了
action = env.action_space.sample() # 随机选择动作 0 = push cart left, 1 = push cart right
observation, reward, terminated, truncated, info = env.step(action) #走一步
# reward: +1 for each step the pole stays upright
# terminated: True if pole falls too far (agent failed)
# truncated: True if we hit the time limit (500 steps)
total_reward += reward
print(f"第{step}步的动作是:{action}, 系统奖励/总奖励是:{reward}/{total_reward}, 到达的新状态是:{observation}, 小球是否掉落:{terminated}")
step +=1
episode_over = terminated or truncated #跳出循环
print(f"Episode finished! Total reward: {total_reward}")
env.close()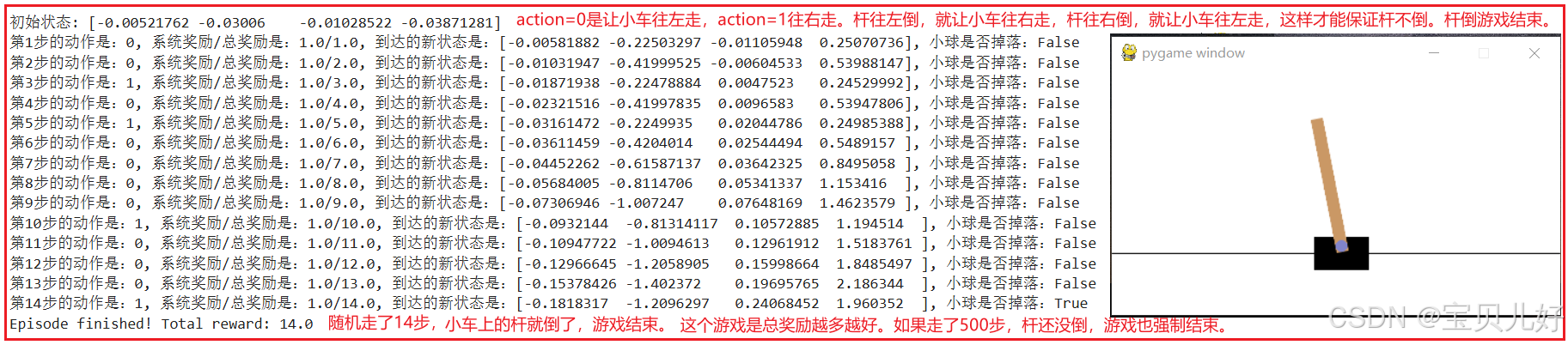 上面代码是agent在随机策略下 ,和环境交互一轮 游戏的过程。也就是我们可以得到随机策略下一条episode的经验数据。
上面代码是agent在随机策略下 ,和环境交互一轮 游戏的过程。也就是我们可以得到随机策略下一条episode的经验数据。
6、获取内置游戏的状态空间、动作空间
动作空间 定义了agent可以选择的所有可能动作。动作空间决定了智能体能够做出的决策范围。
状态空间定义了环境可以返回给agent的所有可能状态或观测值。状态空间决定了agent所能感知到的环境信息范围。
Gymnasium中的每个内置环境都可以通过env.action_space 属性来获取动作空间,通过env.observation_space属性来获取状态空间。下面以CartPole-v1游戏为例展示:
python
import gymnasium as gym
env = gym.make("CartPole-v1")
#(1)CartPole游戏的动作空间是一个离散空间
env.action_space #返回一个Discrete类型的对象:Discrete(2)
env.action_space.n #返回2,总共有2种动作:left or right
env.action_space.sample() # 返回0 or 1,表示从动作空间中均匀的随机采样一个动作:0=push cart left, 1=push cart right
env.action_space.contains(5) #返回False, 检验元素5是否在空间内
#(2)CartPole游戏的状态空间是一个连续空间
env.observation_space # 返回一个Box类型的对象
env.observation_space.low
env.observation_space.high
env.observation_space.sample() # 随机生成一个状态:(小车在轨道上的位置,小车的速度, 杆子的角度,杆子的角速度)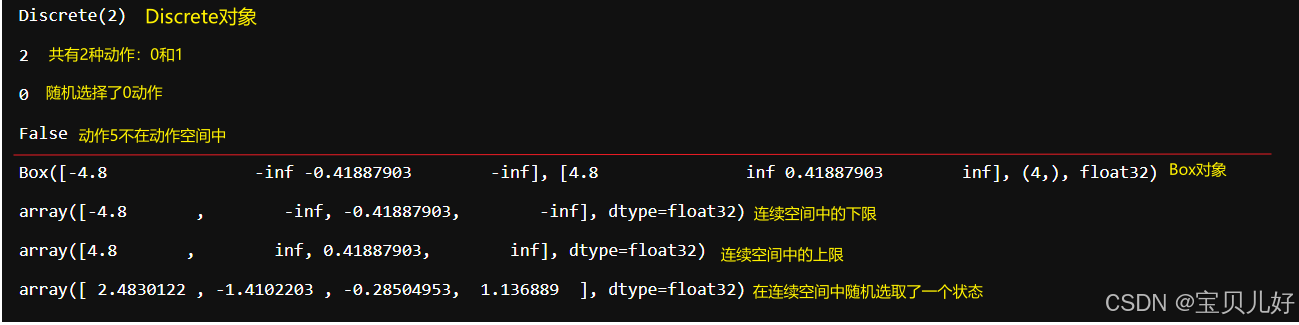 (1)CartPole游戏中的动作空间是一个离散空间,只有2个动作:向左、向右。
(1)CartPole游戏中的动作空间是一个离散空间,只有2个动作:向左、向右。
状态空间 却是一个连续的多维空间,具体是有4个维度。第1个维度是小车在轨道上的位置:-4.8, 4.8 , 第2个维度是小车的速度:(-inf,inf) , 第3个维度是杆子的角度:-0.42, 0.42 , 第4个维度是杆子的角速度:(-inf,inf)。
(2)Discrete对象和Box对象都是gym.Spaces类 的实例对象。气氛都烘托到这里了,那下个小标题就简单介绍一下gym.Spaces类。
7、gym.Spaces类介绍
Gymnasium提供了多种动作空间和状态空间类型,每种类型都有其独特的参数和使用场景。两者本质上使用的都是gym.Spaces 这个类的定义功能,这是Spaces类的官方文档:https://gymnasium.farama.org/api/spaces/composite/#graph 。下面简单介绍一下Gymnasium提供的各种空间类型:
(1)离散空间: Discrete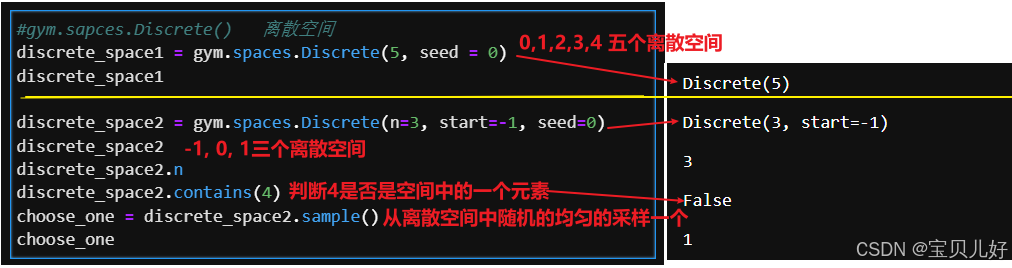 参数 n 表示动作的总数。
参数 n 表示动作的总数。
(2)连续动作空间:Box 参数low表示每个维度的最小值,high表示每个维度的最大值。参数shape表示动作空间维度,dtype表示使用数据类型。
参数low表示每个维度的最小值,high表示每个维度的最大值。参数shape表示动作空间维度,dtype表示使用数据类型。
(3)多重离散空间: MultiDiscrete
多重离散空间是指一个环境中具有多个 离散空间的情况。比如,假设你有一个机器人控制问题,机器人可以在三个维度上采取动作:X轴方向、Y轴方向和Z轴方向。每个维度上的动作空间都是离散的,例如在X轴上可以选择向左、向右或不动,在Y轴和Z轴上也有类似的选择。这样,整个动作空间就被分解为三个离散动作空间的笛卡尔积。多重离散动作空间可以用于描述具有多个维度的离散选择问题,每个维度都有自己的离散动作空间。在这种情况下,agent需要为每个维度选择一个动作,将这些动作组合成一个多维动作向量,然后执行这个向量作为一个整体的动作。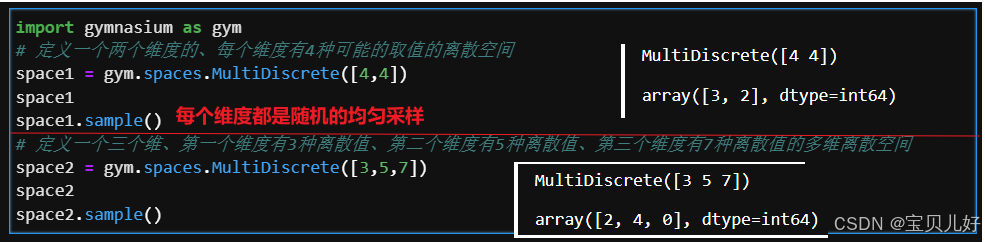
(4)MultiBinary空间
用于多个独立的二元变量动作或状态组合,如多个开关或布尔运算的组合。
(5)Tuple空间
这是一个更加自由的定义动作和状态空间的方式,允许多个不同类型的动作和状态空间组合,如一个动作可以由一个离散动作或状态和一个连续控制或连续空间组合。
(6)Dict 空间
用于表示一个字典格式的空间,可以更自由的灵活定义多维复杂空间结构。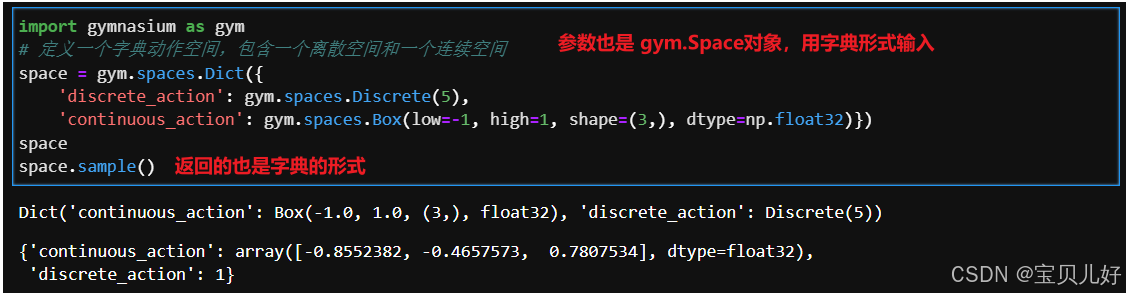
(7)Text 空间
在Gymnasium库中,Text空间专门用于处理文本数据的空间类型。用于自然语言处理相关的强化学习任务,如文字游戏、对话生成等。通常此类多用于状态空间表示。
参数min_length 和参数 max_length 表示文本的最小最大长度,是一个整数,指定空间中允许出现的最小最大字符数。参数charset表示文本的字符集或词汇表。
python
from gymnasium.spaces import Text
# 示例 1:创建一个最大长度为 10,字符集为默认 ASCII 的 Text 空间
text_space = Text(max_length=10)
text_space
text_space.sample()
# 示例 2:创建一个最大长度为 5,自定义字符集为 'abcdef' 的 Text 空间
text_space_custom = Text(max_length=5, charset="abcdef")
text_space_custom
text_space_custom.sample()
# 示例 3:创建一个最大长度为 7,词汇表为 ["hello", "world"] 的 Text 空间
text_space_words = Text(max_length=7, charset=["hello", "world"])
text_space_words
text_space_words.sample()(8)Graph 空间
在gymnasium中,Graph空间用于定义基于图结构的动作或观测空间,适用于节点和边具有离散或连续属性的图状环境(如社交网络、分子结构、交通网络等)。
参数node_space (UnionBox, Discrete):节点特征空间。
参数edge_space (UnionNone, Box, Discrete):边特征空间。
python
from gymnasium.spaces import Graph, Box, Discrete
observation_space = Graph(node_space=Box(low=-100, high=100, shape=(3,)), edge_space=Discrete(3), seed=123)
observation_space.sample(num_nodes=4, num_edges=8)(9)Sequence 空间
在gymnasium.spaces中,Sequence是一个用于表示可变长度序列的空间类型。它通常用于处理如文本、时间序列或列表等具有不同长度的输入数据。
python
from gymnasium.spaces import Sequence, Box
observation_space = Sequence(Box(0, 1), seed=0)
observation_space.sample()二、案例:出租车游戏
前面几个章节讲了很多算法的原理,本章前半部分讲了Gymnasium库中内置游戏的基本操作,万事俱备,我们找一个入门级的小游戏练一下手。出租车调度(Taxi-v3)是Gymnasium中toy级的强化学习例子,非常适合表格型强化学习算法的入门练手,本部分就用这个游戏展示一下Aarsa算法和Q-learning算法。
(一)游戏规则
Taxi-v3游戏的目标是让智能体学会在一个网格状的城市中接送乘客到目的地。
1、游戏介绍
python
#一、导入游戏并初始化、可视化
import gymnasium as gym
env = gym.make('Taxi-v3', render_mode="ansi") #导入游戏
state, state_info = env.reset(seed=1) #重置环境,用随机数种子锁死随机模式,方便复现
state, state_info #查看初始化的状态和状态信息
print(env.render()) #可视化初始状态 (1)这个游戏是一个格子游戏 (grid world),你可以看成是一个5x5的格子 。图中的竖实线是墙 ,意思就是出租车不得通过。图中的竖虚线(两个点)是路,意思是出租车可以通行。
(1)这个游戏是一个格子游戏 (grid world),你可以看成是一个5x5的格子 。图中的竖实线是墙 ,意思就是出租车不得通过。图中的竖虚线(两个点)是路,意思是出租车可以通行。
(2)里面的黄色 实心小长框就是空的出租车 (texi),当出租车搭载1名乘客时,出租车就变成绿色 了,表示出租车已经满座了,不能继续搭载客人了。
当一个游戏回合(episode)开始时,出租车是被随机置于25个格子中的任意一个格子中。
(3)四个角上的格子依次取名 为R ,G ,B ,Y 。初始化游戏时,乘客 的上车位置 和目的地 是从R/G/B/Y这4个位置中随机抽取的2个位置作为乘客的上车位置和目的地。其中乘客的上车位置 被标注成蓝色 、乘客的目的地 被标注成洋红色。
(4)游戏规则是:出租车要先开到乘客的位置,然后搭载(pick up)乘客,然后把乘客送到目的地(drop off)。一旦乘客被drop off,游戏结束,the episode ends。
2、状态空间
在Gymnasium中,这个游戏的状态是以整数0--499 进行编码的。也就是说,这个游戏的状态空间是有500个离散值 的离散空间,这500个空间被编码为从0到499之间的整数。
(1)为什么把状态空间分成500个子空间?
从仿真环境角度看,其实这个游戏的状态空间可以用一个四元组来表示:(出租车行,出租车列,乘客位置,目的地),其中:
出租车行(taxi_row):出租车当前所在的网格行,从左上角依次以0-4进行编号,以便于编程。
出租车列(taxi_col):出租车当前所在的网格列,从左上角0-4依次编号。
乘客位置(pass_loc):表示乘客当前所在的网格位置。如果乘客还未上车,那就是R/G/B/Y四个位置中的一个,这四个位置的编号是:R(0)、G(1)、Y(2)、B(3) ;如果乘客已经上车了,那就是in taxi(编号为4) 。所以乘客位置有5种可能性。
目的地(dest_idx):表示乘客需要达到的目的地,有四种可能性:R/G/B/Y,也是R(0),G(1),Y(2),B(3),和乘客位置编码相同(当然了,必须相同啊,没必要不同啊)。
从这个四元组我们可以快速的计算出这个游戏在理论上 有多少个状态:5x5x5x4=500种。所以这个游戏完整的 状态空间是有500个。然而在实际中,有些状态是不存在的,比如:乘客将永远不会有相同的乘车点和目的地(因为任务已"完成")。但是由于建模的复杂性,我们通常关注完整的状态空间。下面我们用代码查看一下这个游戏的状态空间和动作空间: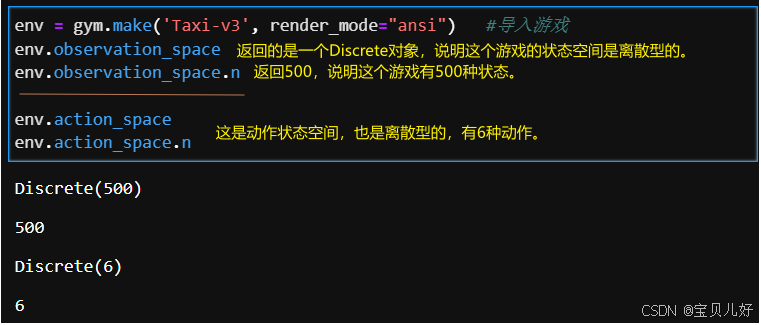
(2)两种状态编码之间的一一映射关系:
以前面初始化的状态为例,我们可以用env.unwrapped.decode(state) 对整数数值进行解码,解码成四元组: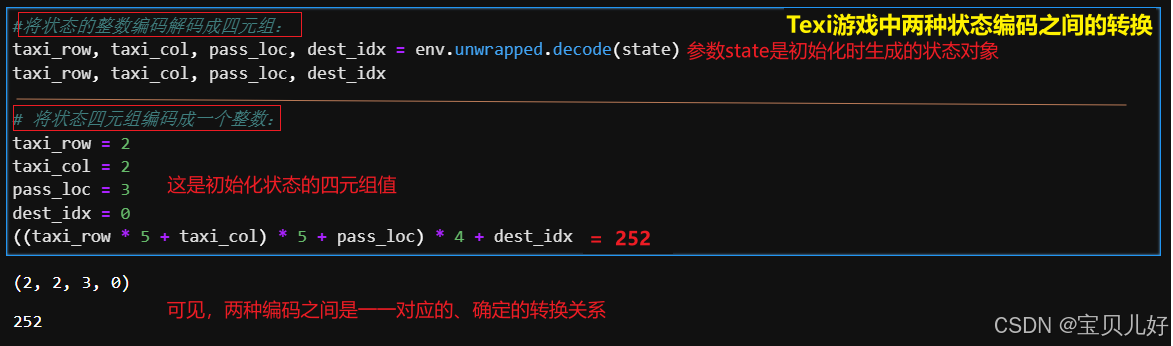 从仿真环境中我们也可以看到初始化的状态的四元组是:(taxi_row=2, taxi_col=2, pass_loc=3, dest_idx=0),表示出租车在第2行第2列,乘客在位置B等候,乘客的目的地是R。利用公式 ((taxi_row × 5 + taxi_col) × 5 + pass_loc) × 4 + dest_idx 对系统状态编码, 得到的就是整数值的编码。
从仿真环境中我们也可以看到初始化的状态的四元组是:(taxi_row=2, taxi_col=2, pass_loc=3, dest_idx=0),表示出租车在第2行第2列,乘客在位置B等候,乘客的目的地是R。利用公式 ((taxi_row × 5 + taxi_col) × 5 + pass_loc) × 4 + dest_idx 对系统状态编码, 得到的就是整数值的编码。
python
#将状态的整数编码解码成四元组:
taxi_row, taxi_col, pass_loc, dest_idx = env.unwrapped.decode(state)
taxi_row, taxi_col, pass_loc, dest_idx
# 将状态四元组编码成一个整数:
taxi_row = 2
taxi_col = 2
pass_loc = 3
dest_idx = 0
((taxi_row * 5 + taxi_col) * 5 + pass_loc) * 4 + dest_idx 3、动作空间
这个游戏有6个离散的确定性动作,其编码及含义如下:
0:向南移动(south),出租车向南移动一格,如果当前位置在网格最底部,则无法移动。
1:向北移动(north),出租车向北移动一格,如果当前位置在网格最顶部,则无法移动。
2:向东移动(east),出租车向东移动一格,如果当前位置在网格最右侧,则无法移动。
3:向西移动(west),出租车向西移动一格,如果当前位置在网格最左侧,则无法移动。
4:乘客上车(pick up),如果出租车位置和乘客位置相同,且乘客尚未被接走,则执行该动作可以接走乘客。
5:乘客下车(drop off),如果出租车当前位置与目的地相同,且乘客已经被接走,则执行该动作可以放下乘客并完成任务。
4、奖惩制度
终极目标是:agent要根据当前状态选择适当的动作,以获取最多的奖励。
(1)小车只要走一步就奖励-1分。稍稍惩罚避免无效移动,鼓励从出发地到目的地走最短的路。
(2)出租车成功接到乘客并送到目的地,奖励20分。正向鼓励智能体完成任务。
(3)非法执行载客(pick up)/落客(drop off)奖励-10分。比如在没有乘客的情况下drop off乘客等这种非法动作,就惩罚10分,让智能体更加智能。
5、让agent走一步
python
env = gym.make('Taxi-v3', render_mode="ansi") #导入游戏
state, state_info = env.reset(seed=1) #初始化游戏
state, state_info #这是初始化的状态
print(env.render()) #这是初始化的可视化状态
taxi_row, taxi_col, pass_loc, dest_idx = env.unwrapped.decode(state) #解码成四元组,方便查看
taxi_row, taxi_col, pass_loc, dest_idx #状态四元组(2,2,3,0)
#让agent向南走一步:
observation, reward, terminated, truncated, info = env.step(0) # 0是向南走的编码 状态迁移到:(3,2,3,0)---352
observation, reward, terminated, truncated, info #状态迁移到352
print(env.render()) #可视化迁移后的状态
taxi_row, taxi_col, pass_loc, dest_idx = env.unwrapped.decode(observation) #:解码成四元组,查看迁移后的状态
taxi_row, taxi_col, pass_loc, dest_idx #(3,2,3,0) 完全正确!
(二)用Q-learning算法训练agent
因为这个例子用Q-learning效果最好,Sarar一言难尽,所以这里我先展示Q-learning算法:
python
#第一步:导库
import gymnasium as gym
import numpy as np
import pickle
#第二步:初始化游戏环境、Q表、设置必要的训练参数
env = gym.make("Taxi-v3", render_mode="ansi") #生成环境
#初始化环境,得到m,n,供生成Q表
s0,s0_info = env.reset()
m = env.observation_space.n #500 状态空间
n = env.action_space.n #6 动作空间
Q_table = np.zeros([m, n]) # 初始化Q-table
#设置必要的超参数
gamma = 0.97 #折扣率
max_episode = 1000 #分幕式训练中的最大幕数
max_steps = 100 #每一幕的最长步数
alpha = 0.7 #学习率
epsilon = 0.3 #贪婪系数
##第三步:写动作函数:用探索和利用的方式选择动作
def choose_action(Qtable, state):
p = np.random.rand() #生成[0, 1)区间内的均匀分布的随机数p
if p > epsilon: #如果p大于贪婪阈值0.3,就随机探索动作,由于一开始智能体还很笨,所以先多多探索,少一点利用
a = env.action_space.sample() #随机探索
else: #如果p小于贪婪阈值0.3,就利用,因为一直随机会降低训练速度,比如训练1000轮了没一轮打到游戏结束的。
Q_row = Qtable[state, :] #把这个状态的Q全部取出来
maxQ = np.max(Q_row) #把最大的Q取出来
action_list = np.where(Q_row == maxQ)[0] #找到所有和最大Q相等的q的索引
a = np.random.choice(action_list) #从中随机取一个索引,就是下一步的最优动作
return a
#第四步:用Q-learning算法训练模型
def fit_model(max_episode, max_steps): #max_episode表示训练多少轮游戏, max_steps表示每轮游戏最多走几步。
for episode in range(max_episode): #训练max_episode轮游戏
s, _ = env.reset() #每轮游戏都要重新随机初始化游戏
for step in range(max_steps): #每轮游戏限制最多走max_steps步,如果max_steps步还没完成任务,就强制结束本轮游戏
a = choose_action(Q_table, s) #以0.7的概率进行探索,生成动作
s_new, r, terminated, truncated, _ = env.step(a) #走一步
#用Q-learning公式更新Q表:
if not terminated or truncated: #如果还没达到终止/中断状态
Q_table[s, a] += alpha*(r + gamma*np.max(Q_table[s_new,:]) - Q_table[s,a]) #但是更新Q时,却选择的是新状态下的最优动作
else: #如果已经达到终止状态了
Q_table[s, a] += alpha*(r - Q_table[s,a])
break
s = s_new
agent = fit_model(max_episode=max_episode, max_steps=max_steps)
#训练完毕,保存Q表:
with open('Qtabel.pkl','wb') as file:
pickle.dump(Q_table,file)
python
#第五步:测试agent的学习效果
import gymnasium as gym
import numpy as np
import pickle
#加载Q表
with open('Qtabel.pkl', 'rb') as file:
Q_table = pickle.load(file)
#开始测试
env = gym.make("Taxi-v3", render_mode="ansi") #生成环境
s,_ = env.reset()
print("初始状态是:\n", env.render())
i = 0
while True:
a = np.argmax(Q_table[s,:])
s, r, terminated, truncated, _ = env.step(a)
i = i+1
print(f"第{i}步:\n", env.render())
if terminated or truncated:
break大概用了2-3秒就训练完毕了,测试效果也非常好。目前这个案例,网上几乎所有人都是按照Q-learning算法来训练的,我想大概是又快效果又好吧。
(三)用Sarsa算法训练agent 
python
import gymnasium as gym
import numpy as np
env = gym.make("Taxi-v3", render_mode="ansi")
s0,s0_info = env.reset()
m = env.observation_space.n
n = env.action_space.n
Q_table = np.zeros([m, n])
max_episode = 2000
max_steps = 100
gamma = 0.999
alpha = 0.4
epsilon = 0.9 #以0.9的概率选择最大q值得动作!!!
#第三步:写动作函数:用探索和利用的方式选择动作
def choose_action(Qtable, state):
p = np.random.rand()
if p > epsilon:
a = env.action_space.sample()
else:
Q_row = Qtable[state, :]
maxQ = np.max(Q_row)
action_list = np.where(Q_row == maxQ)[0]
a = np.random.choice(action_list)
return a
#第四步:用Sarsa算法训练模型
def fit_model(max_episode, max_steps):
for episode in range(max_episode):
s, _ = env.reset()
for step in range(max_steps):
a = choose_action(Q_table, s)
s_new, r, terminated, truncated, _ = env.step(a)
a_next = choose_action(Q_table, s_new)
#用Sarsa公式更新Q表:
if not terminated or truncated:
Q_table[s, a] = Q_table[s,a] + alpha*(r + gamma*Q_table[s_new,a_next] - Q_table[s,a])
a_next = choose_action(Q_table, s_new)
else:
Q_table[s, a] = Q_table[s,a] + alpha*(r - Q_table[s,a])
break
s = s_new
agent = fit_model(max_episode=max_episode, max_steps=max_steps)
python
#第五步:测试agent的学习效果
from IPython.display import clear_output #这次搞一个动图,看着舒服一点
import time
s,_ = env.reset()
clear_output(wait=True)
print("初始状态是:\n", env.render())
time.sleep(3)
i = 0
reward = 0
for _ in range(50):
a = np.argmax(Q_table[s,:])
s, r, terminated, truncated, _ = env.step(a)
i = i+1
reward += r
clear_output(wait=True)
print(f" 第{i}步:\n", env.render())
time.sleep(1)
if terminated or truncated:
break
if i == 50:
print(f"已经达到最大步数,本轮游戏失败,系统奖励{reward}分")
else:
print(f"本轮游戏成功,系统奖励{reward}分")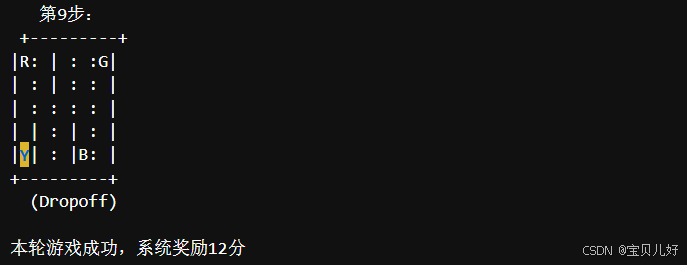
Sarsa算法的超参数非常难调,我试调整了很多很多次,最后这次效果凑合能拿出手。个人认为,sarsa算法更适合随机性比较强的场景。本例其实随机性不是很强 ,所以更新Q表时只要用下一时刻最大的q更新 就是当前时刻的最好的q估计,而sarsa的更新是用下一时刻的随机值更新的,这就导致当前时刻的q值估计的偏差太大,而且这种偏差随着训练次数的增加,还会被放大,最终导致训练难以收敛、效果差!