检索增强生成(Retrieval-augmented Generation)
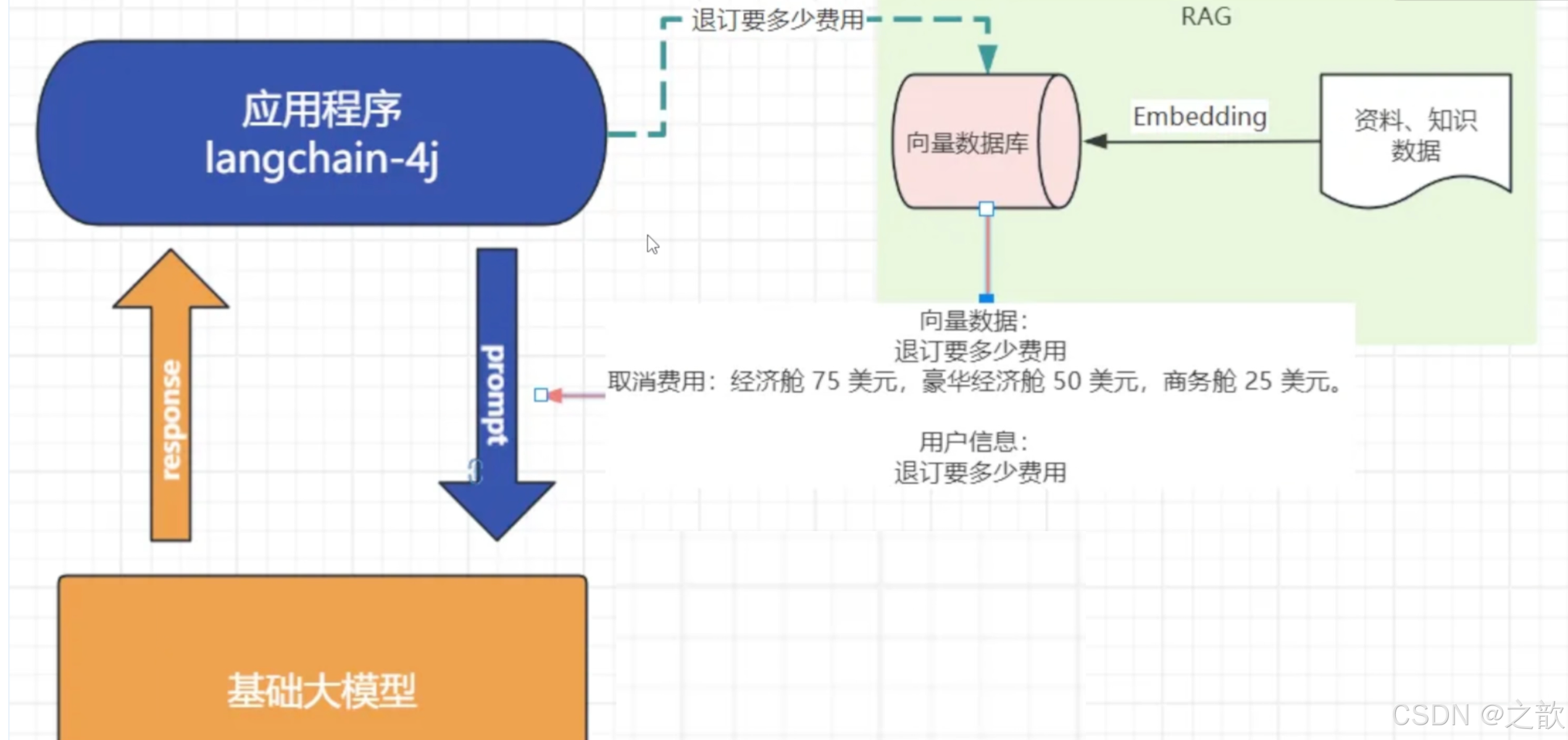
对于基础大模型来说,他只具备通用信息,他的参数都是拿公网进行训练,并且有一定的时间延迟,无法得知一些具体业务数据和实时数据,这些数据往往在各种文件中(比如txt、 word、html、数据库。)
虽然function-call、SystemMessage可以用来解决一部分问题但是它只能少量,并且针对的场景不一样
如果你要提供大量的业务领域信息,就需要给他外接一个知识库:
比如
-
我问他退订要多少费用
-
这些资料可能都由产品或者需求编写在了文档中:
a. 所以需要现在需求信息存到向量数据库(这个过程叫Embedding,涉及到文档读取、分词,就是在我们每一次跟大模型对话的时候呢
-
去向量数据库中查询"退订费用相关信息"
-
将查询到的数据和对话信息再请求大模型
-
此时会响应退订需要多少费用
概念向量:
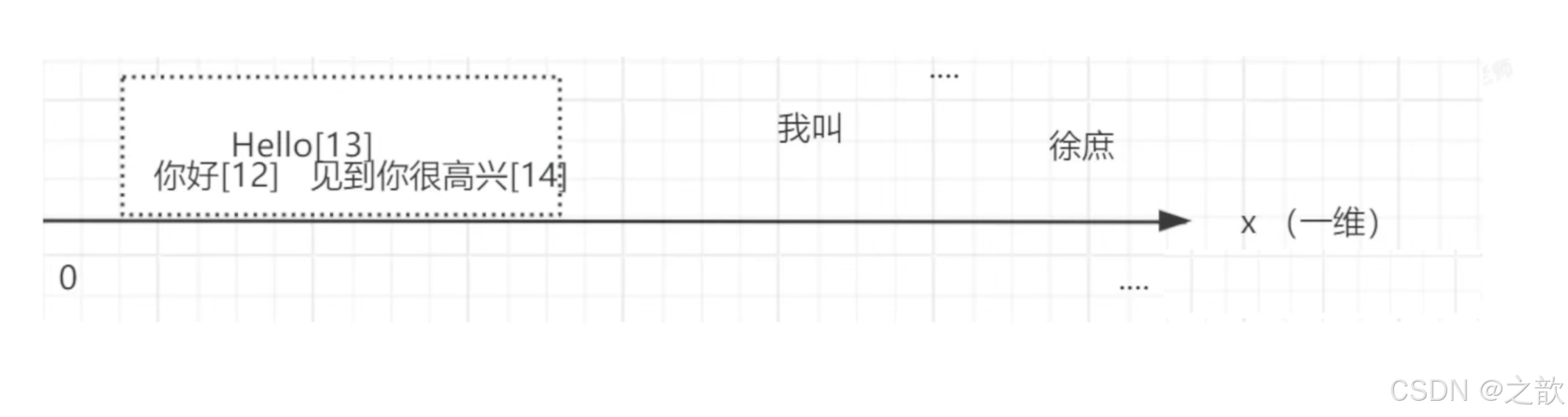
向量通常用来做相似性搜索,比如语义的一维向量,可以表示词语或短语的语义相似性。例如, "你好"、"hello" 和"见到你很高兴"可以通过一维向量来表示它们的语义接近程度。
然而,对于更复杂的对象,比如小狗,无法仅通过一个维度来进行相似性搜索。这时,我们需要提取多个特征,如颜色、大小、品种等,将每个特征表示为向量的一个维度,从而形成一个多维向量。例如,一只棕色的小型泰迪犬可以表示为一个多维向量[棕色,小型,泰迪犬]。
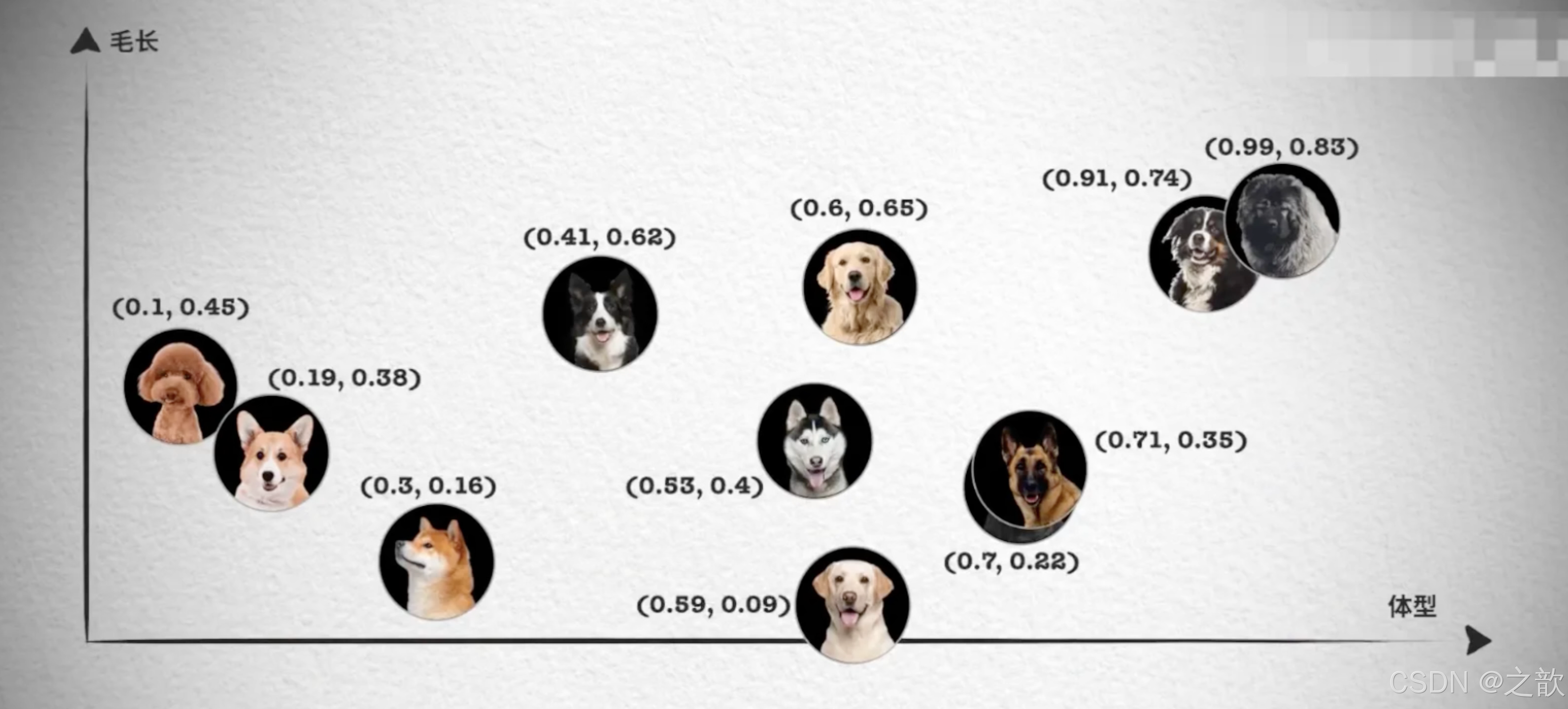
如果需要检索见过更加精准,我们肯定还需要更多维度的向量,组成更多维度的空间,在多维向量空间中,相似性检索变得更加复杂。我们需要使用一些算法,如余弦相似度或欧几里得距离,来计算向量之间的相似性。向量数据库会帮我实现。

文本向量化
通过向量模型即可向量化,这里我们学到了一种新的模型,叫"向量模型"专门用来做文本向量化的。
大语言模型不能做向量化,所以需要单独找一个向量模型
-
向量模型的本质目标,就是把语义相似的内容用"相近"的向量表示,把"不相关"内容尽量拉远。
-
所以好的向量模型能够更好的识别语义,进行向量化。
向量数据库
对于向量模型生成出来的向量,我们可以持久化到向量数据库,并且能利用向量数据库来计算两个向量之间的相似度,或者根据一个向量查找跟这个向量最相似的向量。
在SpringAi中,VectorStore 表示向量数据库,目前支持的向量数据库有 • Azure Vector Search - The Azure vector store。
-
Apache Cassandra - The Apache Cassandra vector store。
-
Chroma Vector Store - The Chroma vector store。
-
Elasticsearch Vector Store - The Elasticsearch vector store。 可以"以向量+关键词"方式做混合检索。深度优化更多针对文本,不是专门"向量搜索引擎"。向量存储和检索容量有限制,查询延迟高于 Milvus.
-
GemFire Vector Store - The GemFire vector store.
-
MariaDB Vector Store - The MariaDB vector store.
-
Milvus Vector Store - The Milvus vector store.
-
Neo4j Vector Store - The Neo4j vector store。可以结合结构化图谱查询与向量检索,大规模嵌入检萦(如干万一亿级高维向量)性能明显落后于 Milvus • OpenSearch Vector Store - The OpenSearch vector store。
-
Oracle Vector Store - The Oracle Database vector store。
-
PgVector Store - The PostgreSQL/PGVector vector store。
-
Pinecone Vector Store - PineCone vector store。
-
Odrant Vector Store - Odrant vector store!
-
Redis Vector Store -The Redis vector store。 低门槛实现小规模向量检索。对于高维大规模向量(如几百万到上亿条),性能和存储效率不如专用向量库。
其中有我们熟悉的几个数据库都可以用来存储向量,比如Elasticsearch、MongoDb、Neo4j、
-
SimpleVectorstore - A simple implementation of persistent vector storage, good tor educational purposes.
其中有我们熟悉的几个数据库都可以用来存储向量,比如Elasticsearch、MongoDb、Neo4j、 Pgsql, Redis。
我会讲解2种:
- SimpleVectorStore 教学版向量数据库
- Milvus Vector Store Milvus(国产团队)、文档友好、社区国内活跃、性能最佳、市场占用率大。实战中使用的向量数据库
匹配检索
在这个示例中,我分别存储了预订航班和取消预订 2段说明到向量数据库中然后通过"退票要多少钱"进行查询

SearchRequest
可以利用searchRequest设置检索请求:
-
query 代表要检索的内容
-
topK 设置检素结果的前N条
-
通常我们查询所有结果查出来,因为查询结果最终要发给人模型,查询过多的结果会:
-
1.过多的token意味着更长延迟,更多的费用,并且过多上下文会超限;
-
2.研究表明过多的内容会降低LLM 的召回性能;
-
-
-
similarityThreshold 设置相似度阈值,可以通关设置分数限制召回内容相似度。从而过滤掉废料。(中文语料要适当降低分数),所以应遵循始终以"业务召回效果"为主,而不是追求网上常说的高分阈值。
Spring AI RAG 使用方式与核心原理详解
项目路径 :
09rag
Spring AI 版本 : 1.0.0
最后更新: 2025年1月
📋 目录
- 概述
- [RAG 使用方式](#RAG 使用方式)
- 核心原理
- [RAG vs Function-Call vs SystemMessage](#RAG vs Function-Call vs SystemMessage)
- 项目代码分析
- 最佳实践
- 常见问题
概述
什么是 RAG?
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种将外部知识库与大型语言模型(LLM)结合的技术。它通过以下步骤工作:
- 检索(Retrieval):从知识库中检索与用户查询相关的文档片段
- 增强(Augmentation):将检索到的文档作为上下文注入到 Prompt 中
- 生成(Generation):基于增强后的上下文生成回答
RAG 的核心价值
- ✅ 知识更新:可以随时更新知识库,无需重新训练模型
- ✅ 准确性提升:基于真实文档回答,减少幻觉(Hallucination)
- ✅ 可追溯性:可以追溯到答案的来源文档
- ✅ 领域适应:可以快速适配特定领域(如企业知识库、产品文档)
RAG 应用场景
- 企业知识库问答:基于内部文档回答员工问题
- 产品文档助手:回答产品使用、配置相关问题
- 法律文档分析:基于法律条文回答法律问题
- 医疗知识问答:基于医学文献回答医疗问题
- 客服系统:基于服务条款、FAQ 回答客户问题
RAG 使用方式
1. 基础使用流程
RAG 的使用通常包括以下步骤:
文档读取 → 文档分割 → 向量化 → 向量存储 → 相似度检索 → 上下文增强 → 生成回答2. 文档处理(ELT:Extract, Load, Transform)
2.1 文档读取(Extract)
Spring AI 提供了多种文档读取器:
文本文件读取:
java
@Autowired
@Value("classpath:rag/terms-of-service.txt")
Resource resource;
TextReader textReader = new TextReader(resource);
textReader.getCustomMetadata().put("filename", resource.getFilename());
List<Document> documents = textReader.read();Markdown 文件读取:
java
@Value("classpath:rag/document.md")
Resource resource;
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(false) // 分割线是否创建新文档
.withIncludeCodeBlock(false) // 代码块是否创建新文档
.withIncludeBlockquote(false) // 引用是否创建新文档
.withAdditionalMetadata("filename", resource.getFilename())
.build();
MarkdownDocumentReader reader = new MarkdownDocumentReader(resource, config);
List<Document> documents = reader.read();PDF 文件读取:
java
// 按页读取
PagePdfDocumentReader pdfReader = new PagePdfDocumentReader(
resource,
PdfDocumentReaderConfig.builder().build()
);
List<Document> documents = pdfReader.read();
// 按段落读取(需要 PDF 有目录结构)
ParagraphPdfDocumentReader pdfReader = new ParagraphPdfDocumentReader(
resource,
PdfDocumentReaderConfig.builder()
.withReversedParagraphPosition(true) // 坐标系反转
.withPageTopMargin(0) // 上边距
.withPageExtractedTextFormatter(
ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(0) // 删除前 N 行
.build()
)
.build()
);
List<Document> documents = pdfReader.read();2.2 文档分割(Transform)
文档分割是将长文档切分成较小的片段,以便:
- 提高检索精度:小片段更容易匹配到相关查询
- 控制上下文长度:避免超出模型的上下文窗口限制
- 提高向量化质量:较小的文本块向量化效果更好
Token 分割器:
java
// 标准 Token 分割器
TokenTextSplitter splitter = new TokenTextSplitter();
List<Document> splitDocuments = splitter.apply(documents);
// 中文 Token 分割器(支持中文分词)
ChineseTokenTextSplitter chineseSplitter = new ChineseTokenTextSplitter(
80, // chunkSize: 每个分块的目标 token 数
10, // chunkOverlap: 分块之间的重叠 token 数
5, // minChunkSize: 最小分块 token 数
10000, // maxChunkSize: 最大分块 token 数
true // keepSeparator: 是否保留分隔符
);
List<Document> splitDocuments = chineseSplitter.apply(documents);分割策略建议:
- ✅ 不要过度追求按主题分割:企业级知识库文档多样,按 Token 数分割更实用
- ✅ 合理设置 chunkSize:通常 100-500 tokens,根据模型上下文窗口调整
- ✅ 设置适当的重叠:10-20% 的重叠可以保持上下文连贯性
2.3 元数据增强(Enrichment)
元数据增强可以为文档添加额外的信息,提高检索精度:
关键词提取:
java
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(chatModel, 5);
List<Document> enrichedDocuments = enricher.apply(documents);
// 可以自定义关键词提取模板
KeywordMetadataEnricher.KEYWORDS_TEMPLATE = """
给我按照我提供的内容{context_str},生成%s个关键字;
允许的关键字有这些:
['退票','预定']
只允许在这个关键字范围进行选择。
""";摘要生成:
java
SummaryMetadataEnricher enricher = new SummaryMetadataEnricher(
chatModel,
List.of(
SummaryMetadataEnricher.SummaryType.PREVIOUS, // 前一个分块的摘要
SummaryMetadataEnricher.SummaryType.CURRENT, // 当前分块的摘要
SummaryMetadataEnricher.SummaryType.NEXT // 下一个分块的摘要
)
);
List<Document> enrichedDocuments = enricher.apply(documents);2.4 向量化(Embedding)
向量化是将文本转换为数值向量,用于相似度计算:
java
@Autowired
DashScopeEmbeddingModel embeddingModel;
// 向量化单个文本
float[] embedding = embeddingModel.embed("我叫徐庶");
System.out.println("向量维度: " + embedding.length);
System.out.println("向量值: " + Arrays.toString(embedding));向量化模型配置:
properties
# application.properties
spring.ai.dashscope.api-key=${ALI_AI_KEY}
spring.ai.dashscope.embedding.options.model=text-embedding-v42.5 向量存储(Load)
向量存储用于保存文档向量,支持相似度检索:
java
@Bean
public VectorStore vectorStore(DashScopeEmbeddingModel embeddingModel) {
return SimpleVectorStore.builder(embeddingModel).build();
}
// 存储文档(内部会自动向量化)
@Autowired
VectorStore vectorStore;
vectorStore.add(documents);3. RAG 检索与生成
3.1 简单 RAG(QuestionAnswerAdvisor)
最简单的 RAG 使用方式:
java
@Autowired
DashScopeChatModel chatModel;
@Autowired
VectorStore vectorStore;
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(SimpleLoggerAdvisor.builder().build())
.build();
String answer = chatClient.prompt()
.user("退票需要多少费用?")
.advisors(
SimpleLoggerAdvisor.builder().build(),
QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(
SearchRequest.builder()
.topK(5) // 返回前 5 个最相似的文档
.similarityThreshold(0.6) // 相似度阈值,低于此值的文档会被过滤
.build()
)
.build()
)
.call()
.content();
System.out.println(answer);工作流程:
- 用户查询:"退票需要多少费用?"
- 向量化查询:将查询转换为向量
- 相似度检索:在 VectorStore 中检索最相似的文档片段(topK=5)
- 过滤低相似度文档:相似度 < 0.6 的文档被过滤
- 上下文增强:将检索到的文档注入到 Prompt
- 生成回答:基于增强后的上下文生成回答
3.2 高级 RAG(RetrievalAugmentationAdvisor)
高级 RAG 提供了更多定制选项:
java
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
// 文档检索器
.documentRetriever(
VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.0)
.topK(5)
// .filterExpression() // 基于元数据过滤
.vectorStore(vectorStore)
.build()
)
// 查询增强器:处理检索为空的情况
.queryAugmenter(
ContextualQueryAugmenter.builder()
.allowEmptyContext(false) // 检索为空时,false 返回提示,true 正常回答
.emptyContextPromptTemplate(
PromptTemplate.builder()
.template("用户查询位于知识库之外。礼貌地告知用户您无法回答")
.build()
)
.build()
)
// 查询转换器:重写查询
.queryTransformers(
RewriteQueryTransformer.builder()
.chatClientBuilder(ChatClient.builder(chatModel))
.targetSearchSystem("航空票务助手")
.build()
)
// 查询转换器:翻译查询
.queryTransformers(
TranslationQueryTransformer.builder()
.chatClientBuilder(ChatClient.builder(chatModel))
.targetLanguage("english")
.build()
)
// 文档后处理器:检索后对文档进行处理
.documentPostProcessors((query, documents) -> {
System.out.println("Original query: " + query.text());
System.out.println("Retrieved documents: " + documents.size());
// 可以在这里对文档进行过滤、排序等操作
return documents;
})
.build();
String answer = chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.user("我今天心情不好,不想去玩了,你能不能告诉我退票需要多少钱?")
.call()
.content();高级特性说明:
-
查询重写(RewriteQueryTransformer):
- 将用户自然语言查询重写为更适合检索的查询
- 例如:"我今天心情不好,不想去玩了" → "退票费用"
-
查询翻译(TranslationQueryTransformer):
- 将查询翻译为其他语言,适用于多语言知识库
-
文档后处理(documentPostProcessors):
- 在检索后对文档进行进一步处理
- 可以过滤、排序、去重等
-
空上下文处理(allowEmptyContext):
false:检索为空时返回提示信息true:检索为空时正常回答(可能产生幻觉)
3.3 重排序(Rerank)
重排序可以提高检索精度,将检索到的文档按相关性重新排序:
java
@Autowired
DashScopeRerankModel rerankModel;
RetrievalRerankAdvisor retrievalRerankAdvisor = new RetrievalRerankAdvisor(
vectorStore,
rerankModel,
SearchRequest.builder()
.topK(200) // 先检索 200 个文档
.build()
);
String answer = chatClient.prompt()
.user("退费费用?")
.advisors(retrievalRerankAdvisor)
.call()
.content();重排序工作流程:
- 向量检索:从 VectorStore 检索 topK=200 个文档
- 重排序:使用 Rerank 模型对 200 个文档重新排序
- 选择 Top N:选择重排序后的前 N 个文档
- 上下文增强:将选中的文档注入到 Prompt
- 生成回答:基于增强后的上下文生成回答
4. 元数据过滤
基于元数据过滤可以提高检索精度:
java
// 存储时添加元数据
Document doc = Document.builder()
.text("退票政策...")
.metadata(Map.of("category", "退票", "filename", "terms-of-service.txt"))
.build();
// 检索时使用元数据过滤
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.eq("category", "退票") // 只检索 category="退票" 的文档
.and()
.eq("filename", "terms-of-service.txt") // 并且 filename="terms-of-service.txt"
.build();
SearchRequest searchRequest = SearchRequest.builder()
.topK(5)
.similarityThreshold(0.6)
.filterExpression(filterExpression) // 应用元数据过滤
.build();
QuestionAnswerAdvisor advisor = QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(searchRequest)
.build();元数据过滤的优势:
- ✅ 提高精度:只检索特定类别的文档
- ✅ 减少噪音:过滤掉不相关的文档
- ✅ 支持复杂查询:可以组合多个过滤条件
- ✅ 提高性能:减少需要处理的文档数量
支持的过滤操作:
eq: 等于ne: 不等于gt: 大于gte: 大于等于lt: 小于lte: 小于等于in: 在列表中nin: 不在列表中and: 逻辑与or: 逻辑或not: 逻辑非
5. RAG 评估(Evaluation)
RAG 评估用于评估 RAG 系统的质量,包括相关性、准确性等:
java
@Autowired
DashScopeChatModel chatModel;
@Autowired
VectorStore vectorStore;
// 构建 RAG Advisor
RetrievalAugmentationAdvisor advisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.build())
.build();
// 执行查询
String query = "退票需要多少费用?";
ChatResponse chatResponse = ChatClient.builder(chatModel)
.build()
.prompt(query)
.advisors(advisor)
.call()
.chatResponse();
// 构建评估请求
EvaluationRequest evaluationRequest = new EvaluationRequest(
query, // 原始用户查询
chatResponse.getMetadata().get(RetrievalAugmentationAdvisor.DOCUMENT_CONTEXT), // 检索到的上下文
chatResponse.getResult().getOutput().getText() // AI 生成的答案
);
// 执行相关性评估
RelevancyEvaluator evaluator = new RelevancyEvaluator(
ChatClient.builder(chatModel)
);
EvaluationResponse evaluationResponse = evaluator.evaluate(evaluationRequest);
System.out.println("评估结果: " + evaluationResponse);评估指标:
- 相关性(Relevancy):答案与查询的相关程度
- 准确性(Accuracy):答案的准确性
- 完整性(Completeness):答案的完整程度
- 一致性(Consistency):答案与上下文的一致性
核心原理
1. 向量相似度检索原理
1.1 向量化(Embedding)
向量化是将文本转换为高维向量空间中的点:
文本: "退票需要多少费用?"
↓ Embedding Model
向量: [0.123, -0.456, 0.789, ..., 0.234] (维度: 1024)向量化的特点:
- 语义相似性:语义相似的文本在向量空间中距离较近
- 高维空间:通常使用 512、1024 或更高维度
- 稠密向量:每个维度都有数值,不是稀疏向量
1.2 相似度计算
常用的相似度计算方法:
余弦相似度(Cosine Similarity):
similarity = cos(θ) = (A · B) / (||A|| × ||B||)点积相似度(Dot Product):
similarity = A · B = Σ(Ai × Bi)欧氏距离(Euclidean Distance):
distance = √Σ(Ai - Bi)²
similarity = 1 / (1 + distance)1.3 向量检索
向量检索是在高维向量空间中快速找到最相似的向量:
暴力搜索(Brute Force):
- 计算查询向量与所有文档向量的相似度
- 时间复杂度:O(n),n 为文档数量
- 适用于小规模数据(< 10万)
近似最近邻(ANN):
- 使用索引结构加速检索
- 时间复杂度:O(log n)
- 适用于大规模数据(> 10万)
- 常用算法:HNSW、IVF、LSH 等
2. RAG 工作流程详解
2.1 完整流程图
用户查询
↓
向量化查询
↓
向量相似度检索
↓
过滤低相似度文档
↓
元数据过滤(可选)
↓
重排序(可选)
↓
文档后处理(可选)
↓
构建增强 Prompt
↓
AI 生成回答
↓
返回答案2.2 Prompt 构建
RAG 会将检索到的文档注入到 Prompt 中:
System: 你是一个智能助手,基于以下文档回答问题。
Context:
文档1: 退票政策规定,经济舱取消费用为 75 美元...
文档2: 取消预订需要在航班起飞前 48 小时...
文档3: 退款将在 7 个工作日内处理...
User: 退票需要多少费用?
Assistant: 根据文档内容,退票费用取决于舱位等级...Prompt 模板:
java
String template = """
基于以下文档回答问题:
{context}
问题:{question}
如果文档中没有相关信息,请说"根据提供的文档,我无法回答这个问题"。
""";3. 向量存储原理
3.1 SimpleVectorStore
SimpleVectorStore 是 Spring AI 提供的内存向量存储:
特点:
- 存储在内存中,速度快
- 适合小规模数据(< 10万文档)
- 重启后数据丢失
- 支持持久化到文件
实现原理:
java
// 内部数据结构
Map<String, List<Float>> vectors; // 文档ID -> 向量
Map<String, Document> documents; // 文档ID -> 文档内容3.2 持久化向量存储
生产环境建议使用持久化向量存储:
选项 1:PostgreSQL + pgvector
java
@Bean
public VectorStore vectorStore(PgVectorStore pgVectorStore) {
return pgVectorStore;
}选项 2:Milvus
java
@Bean
public VectorStore vectorStore(MilvusVectorStore milvusVectorStore) {
return milvusVectorStore;
}选项 3:Pinecone
java
@Bean
public VectorStore vectorStore(PineconeVectorStore pineconeVectorStore) {
return pineconeVectorStore;
}4. 文档分割原理
4.1 Token 分割
Token 分割器将文本按 Token 数量分割:
原始文档(1000 tokens)
↓ TokenTextSplitter(chunkSize=200, overlap=20)
分块1: tokens 0-200
分块2: tokens 180-380 (重叠 20 tokens)
分块3: tokens 360-560
...重叠的作用:
- 保持上下文连贯性
- 避免重要信息被分割
- 提高检索召回率
4.2 中文分词
ChineseTokenTextSplitter 支持中文分词:
java
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(
80, // chunkSize
10, // chunkOverlap
5, // minChunkSize
10000, // maxChunkSize
true // keepSeparator
);中文分词的优势:
- 更准确的中文 Token 计数
- 更好的语义分割
- 支持中文标点符号处理
5. Advisor 底层实现原理
5.1 Advisor 执行流程
RAG Advisor 在 ChatClient 的调用链中执行:
ChatClient.prompt().user().call()
↓
Advisor.doBefore() // 检索文档
↓
构建增强 Prompt(包含检索到的文档)
↓
ChatModel.call(Prompt) // AI 生成回答
↓
Advisor.doAfter() // 后处理
↓
返回结果5.2 QuestionAnswerAdvisor 实现
QuestionAnswerAdvisor 的底层实现:
java
// 伪代码展示核心逻辑
public ChatClientRequest before(ChatClientRequest request, AdvisorChain chain) {
// 1. 提取用户查询
String query = extractUserQuery(request);
// 2. 向量化查询
float[] queryVector = embeddingModel.embed(query);
// 3. 向量检索
List<Document> documents = vectorStore.similaritySearch(
queryVector,
searchRequest
);
// 4. 构建增强 Prompt
String context = buildContext(documents);
Prompt enhancedPrompt = buildEnhancedPrompt(request, context);
// 5. 返回增强后的请求
return request.mutate().prompt(enhancedPrompt).build();
}5.3 RetrievalAugmentationAdvisor 实现
RetrievalAugmentationAdvisor 提供了更灵活的扩展点:
java
// 伪代码展示核心逻辑
public ChatClientRequest before(ChatClientRequest request, AdvisorChain chain) {
// 1. 查询转换(Query Transformers)
Query query = applyQueryTransformers(originalQuery);
// 2. 文档检索
List<Document> documents = documentRetriever.retrieve(query);
// 3. 文档后处理
documents = applyDocumentPostProcessors(query, documents);
// 4. 查询增强(处理空上下文)
if (documents.isEmpty() && !allowEmptyContext) {
return buildEmptyContextResponse();
}
// 5. 构建增强 Prompt
Prompt enhancedPrompt = buildEnhancedPrompt(request, documents);
return request.mutate().prompt(enhancedPrompt).build();
}5.4 上下文注入机制
检索到的文档会被注入到 Prompt 中:
java
// 上下文构建模板
String contextTemplate = """
基于以下文档回答问题:
{context}
问题:{question}
""";
// 构建上下文字符串
StringBuilder context = new StringBuilder();
for (Document doc : documents) {
context.append("文档").append(i).append(": ").append(doc.getText()).append("\n\n");
}
// 替换模板变量
String prompt = contextTemplate
.replace("{context}", context.toString())
.replace("{question}", query);RAG vs Function-Call vs SystemMessage
对比表
| 特性 | RAG | Function-Call | SystemMessage |
|---|---|---|---|
| 知识来源 | 外部知识库 | 工具/API | 预定义提示词 |
| 知识更新 | 动态更新 | 需要修改代码 | 需要修改提示词 |
| 知识规模 | 大规模(GB级) | 小规模(工具) | 小规模(提示词) |
| 准确性 | 高(基于文档) | 高(基于工具) | 中(基于模型知识) |
| 可追溯性 | ✅ 可追溯 | ✅ 可追溯 | ❌ 不可追溯 |
| 适用场景 | 知识问答 | 工具调用 | 角色设定 |
| 实现复杂度 | 中 | 中 | 低 |
| 性能开销 | 中(检索+生成) | 低(工具调用) | 低(仅生成) |
使用场景建议
使用 RAG 的场景
✅ 企业知识库问答 :需要基于大量文档回答
✅ 产品文档助手 :需要查询产品文档
✅ 法律文档分析 :需要基于法律条文回答
✅ 客服系统:需要基于服务条款回答
使用 Function-Call 的场景
✅ 实时数据查询 :需要查询数据库、API
✅ 工具调用 :需要执行操作(发送邮件、创建订单等)
✅ 计算任务 :需要执行计算、转换等
✅ 系统集成:需要调用外部系统
使用 SystemMessage 的场景
✅ 角色设定 :定义 AI 的角色和性格
✅ 行为约束 :定义 AI 的行为规则
✅ 格式要求 :定义输出格式
✅ 简单知识:少量固定的知识
组合使用
在实际应用中,可以组合使用这三种方式:
java
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultSystem("""
你是一个智能客服助手,请以友好的语气回答用户问题。
""")
.defaultAdvisors(
QuestionAnswerAdvisor.builder(vectorStore).build(), // RAG
new SimpleLoggerAdvisor()
)
.defaultTools(toolService) // Function-Call
.build();组合优势:
- RAG 提供知识库支持
- Function-Call 提供工具能力
- SystemMessage 定义角色和行为
项目代码分析
1. ChatClientRagTest
位置 :09rag/src/test/java/com/xushu/springai/rag/ChatClientRagTest.java
功能:演示 RAG 的基本使用和高级特性
关键方法:
-
testRag():简单 RAG 使用
- 使用 `Questi
-
testRag():简单 RAG 使用
- 使用
QuestionAnswerAdvisor - 配置
topK=5,similarityThreshold=0.6
- 使用
-
testRag2():元数据过滤
- 演示如何使用
filterExpression过滤文档
- 演示如何使用
-
testRag3():高级 RAG
- 使用
RetrievalAugmentationAdvisor - 配置查询重写、翻译、后处理等
- 使用
2. RerankTest
位置 :09rag/src/test/java/com/xushu/springai/rag/RerankTest.java
功能:演示重排序的使用
关键点:
- 先检索大量文档(topK=200)
- 使用 Rerank 模型重新排序
- 选择最相关的文档
3. RagEvalTest
位置 :09rag/src/test/java/com/xushu/springai/rag/eval/RagEvalTest.java
功能:演示 RAG 评估
关键点:
- 使用
RelevancyEvaluator评估答案相关性 - 评估查询、上下文、答案三者之间的关系
- 评估请求包含:原始查询、检索到的上下文、AI 生成的答案
评估流程:
- 执行 RAG 查询,获取答案和上下文
- 构建
EvaluationRequest,包含查询、上下文、答案 - 使用
RelevancyEvaluator评估相关性 - 输出评估结果(评分、理由等)
4. ReaderTest
位置 :09rag/src/test/java/com/xushu/springai/rag/ELT/ReaderTest.java
功能:演示各种文档读取器的使用
关键方法:
-
testReaderText():文本文件读取
- 使用
TextReader读取纯文本文件 - 适用于简单的文本文档
- 使用
-
testReaderMD():Markdown 文件读取
- 使用
MarkdownDocumentReader读取 Markdown 文件 - 配置选项:
withHorizontalRuleCreateDocument: 分割线是否创建新文档withIncludeCodeBlock: 代码块是否创建新文档withIncludeBlockquote: 引用是否创建新文档withAdditionalMetadata: 添加元数据
- 使用
-
testReaderPdf():PDF 按页读取
- 使用
PagePdfDocumentReader按页读取 PDF - 每页创建一个 Document
- 使用
-
testReaderParagraphPdf():PDF 按段落读取
- 使用
ParagraphPdfDocumentReader按段落读取 PDF - 需要 PDF 有目录结构
- 配置选项:
withReversedParagraphPosition: 坐标系反转(不同 PDF 工具可能使用不同坐标系)withPageTopMargin: 上边距withPageExtractedTextFormatter: 文本格式化(删除前 N 行等)
- 使用
5. SplitterTest
位置 :09rag/src/test/java/com/xushu/springai/rag/ELT/SplitterTest.java
功能:演示文档分割和元数据增强
关键方法:
-
testTokenTextSplitter():标准 Token 分割
- 使用
TokenTextSplitter按 Token 数分割 - 适用于英文文档
- 使用
-
testChineseTokenTextSplitter():中文 Token 分割
- 使用
ChineseTokenTextSplitter支持中文分词 - 更准确的中文 Token 计数
- 使用
-
testKeywordMetadataEnricher():关键词元数据增强
- 使用
KeywordMetadataEnricher为文档提取关键词 - 关键词可以用于元数据过滤
- 可以自定义关键词提取模板和允许的关键词列表
- 使用
-
testSummaryMetadataEnricher():摘要元数据增强
- 使用
SummaryMetadataEnricher为文档生成摘要 - 支持三种摘要类型:
PREVIOUS: 前一个分块的摘要CURRENT: 当前分块的摘要NEXT: 下一个分块的摘要
- 摘要可以用于提高检索精度
- 使用
重要提示:
- ✅ 不要过度追求按主题分割:企业级知识库文档多样,按 Token 数分割更实用
- ✅ 只要 token 数合理就行:不需要严格按照主题分割
6. VectorStoreTest
位置 :09rag/src/test/java/com/xushu/springai/rag/VectorStoreTest.java
功能:演示向量存储的基本操作
关键点:
- 创建
SimpleVectorStoreBean - 添加文档(内部自动向量化)
- 相似度检索
- 查看检索结果的相似度分数
检索结果:
- 每个检索到的文档都包含相似度分数(score)
- 分数范围通常在 0-1 之间
- 分数越高,表示与查询越相似
7. EmbaddingTest
位置 :09rag/src/test/java/com/xushu/springai/rag/EmbaddingTest.java
功能:演示向量化的基本操作
关键点:
- 向量化单个文本
- 查看向量维度
- 理解向量化的结果
最佳实践
1. 文档处理最佳实践
1.1 文档分割
✅ 推荐做法:
java
// 使用合适的 chunkSize
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(
200, // chunkSize: 根据模型上下文窗口调整
20, // chunkOverlap: 10% 重叠
50, // minChunkSize: 避免过小的分块
500, // maxChunkSize: 避免过大的分块
true // keepSeparator: 保留分隔符
);❌ 不推荐:
- chunkSize 过大(> 1000):可能超出模型上下文窗口
- chunkSize 过小(< 50):可能丢失上下文信息
- 无重叠:可能导致重要信息被分割
1.2 元数据管理
✅ 推荐做法:
java
Document doc = Document.builder()
.text("退票政策...")
.metadata(Map.of(
"category", "退票",
"filename", "terms-of-service.txt",
"version", "1.0",
"updateDate", "2025-01-01"
))
.build();元数据字段建议:
category: 文档类别filename: 文件名version: 版本号updateDate: 更新日期author: 作者tags: 标签列表
2. 检索最佳实践
2.1 相似度阈值
✅ 推荐做法:
java
SearchRequest.builder()
.topK(5)
.similarityThreshold(0.6) // 根据实际效果调整
.build();阈值选择:
- 0.7-0.9:高精度,低召回率(严格匹配)
- 0.5-0.7:平衡精度和召回率(推荐)
- 0.3-0.5:低精度,高召回率(宽松匹配)
2.2 TopK 选择
✅ 推荐做法:
java
SearchRequest.builder()
.topK(5) // 根据模型上下文窗口和文档长度调整
.build();TopK 选择建议:
- 小文档(< 500 tokens):topK = 5-10
- 中等文档(500-1000 tokens):topK = 3-5
- 大文档(> 1000 tokens):topK = 1-3
3. 性能优化
3.1 向量存储选择
小规模(< 10万文档):
java
SimpleVectorStore.builder(embeddingModel).build();大规模(> 10万文档):
java
// 使用 PostgreSQL + pgvector
PgVectorStore.builder(embeddingModel, dataSource).build();
// 或使用 Milvus
MilvusVectorStore.builder(embeddingModel, milvusClient).build();3.2 缓存机制
java
@Cacheable("rag-cache")
public String answer(String query) {
// RAG 查询逻辑
}3.3 异步处理
java
@Async
public CompletableFuture<String> answerAsync(String query) {
// 异步执行 RAG 查询
}4. 错误处理
java
try {
String answer = chatClient.prompt()
.user(query)
.advisors(ragAdvisor)
.call()
.content();
return answer;
} catch (Exception e) {
log.error("RAG 查询失败: query={}", query, e);
return "抱歉,我无法回答这个问题。请稍后再试。";
}错误处理策略:
- 向量化失败:重试或使用备用模型
- 检索失败:返回友好提示
- 生成失败:记录日志,返回默认回复
- 超时处理:设置合理的超时时间
5. 监控和日志
java
@Slf4j
public class RagService {
public String answer(String query) {
long startTime = System.currentTimeMillis();
try {
// 执行 RAG 查询
String answer = chatClient.prompt()
.user(query)
.advisors(ragAdvisor)
.call()
.content();
long duration = System.currentTimeMillis() - startTime;
log.info("RAG 查询成功: query={}, duration={}ms", query, duration);
return answer;
} catch (Exception e) {
log.error("RAG 查询失败: query={}", query, e);
throw e;
}
}
}监控指标:
- 查询响应时间
- 检索文档数量
- 相似度分布
- 错误率
- 缓存命中率
常见问题
Q1: RAG 检索不到相关文档怎么办?
可能原因:
- 相似度阈值设置过高
- 查询与文档语义不匹配
- 文档分割不合理
- 向量化模型不适合
解决方案:
java
// 1. 降低相似度阈值
SearchRequest.builder()
.similarityThreshold(0.3) // 从 0.6 降低到 0.3
.build();
// 2. 增加 TopK
SearchRequest.builder()
.topK(10) // 从 5 增加到 10
.build();
// 3. 使用查询重写
RewriteQueryTransformer.builder()
.chatClientBuilder(ChatClient.builder(chatModel))
.targetSearchSystem("航空票务助手")
.build();Q2: RAG 回答不准确怎么办?
可能原因:
- 检索到的文档不相关
- 上下文信息不足
- 模型理解有误
解决方案:
java
// 1. 使用重排序
RetrievalRerankAdvisor retrievalRerankAdvisor = new RetrievalRerankAdvisor(
vectorStore,
rerankModel,
SearchRequest.builder().topK(200).build()
);
// 2. 增加检索文档数量
SearchRequest.builder()
.topK(10) // 增加检索数量
.build();
// 3. 使用元数据过滤
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.eq("category", "退票")
.build();Q3: RAG 响应速度慢怎么办?
优化方案:
java
// 1. 使用缓存
@Cacheable(value = "rag-cache", key = "#query")
public String answer(String query) {
// RAG 查询
}
// 2. 异步处理
@Async
public CompletableFuture<String> answerAsync(String query) {
// 异步 RAG 查询
}
// 3. 使用更快的向量存储
// SimpleVectorStore(内存)比数据库向量存储快
SimpleVectorStore.builder(embeddingModel).build();Q4: 如何处理多语言知识库?
解决方案:
java
// 使用查询翻译
TranslationQueryTransformer.builder()
.chatClientBuilder(ChatClient.builder(chatModel))
.targetLanguage("english") // 翻译为英文检索
.build();Q5: 如何更新知识库?
增量更新:
java
// 添加新文档
vectorStore.add(newDocuments);
// 删除旧文档
vectorStore.delete(List.of(documentId));
// 更新文档
vectorStore.add(updatedDocuments); // 会覆盖旧文档Q6: 如何评估 RAG 效果?
评估方法:
java
// 使用 RelevancyEvaluator
RelevancyEvaluator evaluator = new RelevancyEvaluator(
ChatClient.builder(chatModel)
);
EvaluationRequest request = new EvaluationRequest(
query,
context,
answer
);
EvaluationResponse response = evaluator.evaluate(request);
System.out.println("相关性评分: " + response.getScore());Q7: chunkSize 如何选择?
选择建议:
- 小文档(< 1000 tokens):chunkSize = 200-300
- 中等文档(1000-5000 tokens):chunkSize = 300-500
- 大文档(> 5000 tokens):chunkSize = 500-1000
考虑因素:
- 模型上下文窗口大小
- 文档平均长度
- 检索精度要求
Q8: 相似度阈值如何设置?
设置建议:
- 高精度场景:0.7-0.9(严格匹配)
- 平衡场景:0.5-0.7(推荐)
- 高召回场景:0.3-0.5(宽松匹配)
调整方法:
- 从 0.6 开始测试
- 根据实际效果调整
- 记录不同阈值下的准确率
总结
RAG 的核心优势
- 知识更新灵活:无需重新训练模型,只需更新知识库
- 准确性高:基于真实文档回答,减少幻觉
- 可追溯性强:可以追溯到答案来源
- 领域适应快:快速适配新领域
RAG 的适用场景
✅ 适合使用 RAG:
- 企业知识库问答
- 产品文档助手
- 法律文档分析
- 客服系统
❌ 不适合使用 RAG:
- 需要实时数据的场景(应使用 Function-Call)
- 需要执行操作的场景(应使用 Function-Call)
- 简单对话场景(直接使用 ChatModel)
RAG 最佳实践总结
-
文档处理:
- 合理设置 chunkSize(200-500 tokens)
- 设置适当的重叠(10-20%)
- 添加有意义的元数据
-
检索优化:
- 合理设置相似度阈值(0.5-0.7)
- 根据文档大小调整 topK
- 使用重排序提高精度
-
性能优化:
- 小规模使用 SimpleVectorStore
- 大规模使用持久化向量存储
- 添加缓存机制
-
错误处理:
- 完善的异常处理
- 友好的错误提示
- 详细的日志记录
参考资料
- Spring AI 官方文档
- RAG 论文:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- 向量数据库对比
- Embedding 模型对比
测试
java
\# ali百炼
spring.ai.dashscope.api-key=sk-xxxx
spring.ai.dashscope.embedding.options.model= text-embedding-v4
logging.level.org.springframework.ai=debug
java
package com.xushu.springai.rag;
import com.alibaba.cloud.ai.dashscope.embedding.DashScopeEmbeddingModel;
import org.junit.jupiter.api.Test;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.boot.test.context.TestConfiguration;
import org.springframework.context.annotation.Bean;
import java.util.List;
@SpringBootTest
public class VectorStoreTest {
@TestConfiguration
static class TestConfig {
/**
* 使用 DashScopeEmbeddingModel 构建 VectorStore
* 注意:如果使用 OllamaEmbeddingModel,需要先确保 Ollama 服务运行
* 并且已经下载了对应的 embedding 模型(如 nomic-embed-text)
*
* 下载 Ollama embedding 模型命令:
* ollama pull nomic-embed-text
*/
@Bean
public VectorStore vectorStore(DashScopeEmbeddingModel embeddingModel) {
return SimpleVectorStore.builder(embeddingModel).build();
}
}
@Test
public void testVectorStore(@Autowired VectorStore vectorStore) {
Document doc = Document.builder()
.text("""
预订航班:
- 通过我们的网站或移动应用程序预订。
- 预订时需要全额付款。
- 确保个人信息(姓名、ID 等)的准确性,因为更正可能会产生 25 的费用。
""")
.build();
Document doc2 = Document.builder()
.text("""
取消预订:
- 最晚在航班起飞前 48 小时取消。
- 取消费用:经济舱 75 美元,豪华经济舱 50 美元,商务舱 25 美元。
- 退款将在 7 个工作日内处理。
""")
.build();
// 存储向量(内部会自动向量化)
vectorStore.add(List.of(doc, doc2));
SearchRequest searchRequest = SearchRequest.builder()
.query("退票")
.topK(2)
.similarityThreshold(0.5)
.build();
List<Document> documents = vectorStore.similaritySearch(searchRequest);
for (Document document : documents) {
System.out.println(document.getText());
System.out.println(document.getScore());
}
}
}结果输出: