在程序猿的日常工作中,大家都不可避免的和IP查询打交道,因为网络协议,我们要使用它进行风控、反作弊、分析归因等等。但是当你的网站突然人流激增(十分荣幸前几天网站访问迎来了一个小高峰),有了一个高并发,在线调用的API不太够用,我们临时弄了一个ip数据库进行部署,我们弄了IP数据云的库来应对本次"高并发"事件。
这篇文章我想结合我们部门的真实实践,聊一聊:
为什么我们最终选择通过部署IP离线库,来实现批量、高速、无网络依赖的IP查询能力,以及这套方案 我们 是如何落地的。

Q1、 为什么在线IP API在工程实践中会逐渐"吃不消"
在之前的时候,我们也和很多团队一样,直接使用在线IP查询API:
· 调用简单
· 上手成本低
· 不需要维护数据
但随着我们的网站访问越来越多,业务规模上来,问题开始集中暴露:
1.批量查询场景下,性能 控制不了
我们有几个核心场景:
· 实时风控:单节点QPS峰值可达数万
· 离线日志分析:一次性处理上亿条访问日志
· 用户画像任务:IP作为重要特征字段参与建模
在这些场景下,HTTP API的网络开销、本身的限流策略,都会 卡住。
2.网络依赖带来的稳定性风险
技术同事应该都懂这个感受:
你明明只是想查一个IP,却被DNS、链路抖动、第三方接口超时拖慢整个系统。
尤其在以下环境中问题更加明显:
· 内网/半封闭网络
· 对外网访问受控的安全环境
· 灾备或应急切换场景
3.成本问题会被低估
当IP查询调用量上到"亿级/日"之后,API成本不再是一个可以忽略的数字,而且还很难做精细化控制。
Q2 、 如何 把"查询能力"收回到系统内部 ? 部署 IP离线库
正是基于这些现实问题,我们开始系统性评估 IP离线库方案。
简单说一句话总结:
IP离线库,本质上是把IP查询从"外部服务调用",变成"本地数据计算"。
它带来的几个关键变化,对工程体系非常重要。
1.查询速度:从毫秒级到微秒级
在本地内存或mmap文件中完成IP段匹配,性能提升非常明显:
· 单机每秒可处理百万级IP查询
· 批量任务基本只受CPU限制
这对风控系统、日志管道、实时流处理非常友好。
2.完全消除网络依赖
IP查询不再依赖:
· 外部网络
· 第三方服务SLA
· 接口限流策略
在内网环境、专有云、混合云架构中,这一点尤为关键。
3.架构更 清楚 ,可控性更强
· 数据更新频率可控
· 查询逻辑可封装成SDK或服务
· 更容易做多语言、多系统统一能力
Q3 、 如何 部署IP离线库 ? 我们的 核心技术思路
很多同事一听"离线库"就会担心复杂度,其实在工程上并不复杂,关键在于几个点。
1.数据结构与查询方式
成熟的IP离线库,一般都会解决好这些问题:
· IP段高效索引
· 内存友好设计
· 跨语言SDK支持(Java/Go/Python/C++等)
在我们实践中,单次IP查询几乎是纯CPU运算,不涉及IO。
2.数据更新机制
离线不等于"不更新",一个合格的方案应该支持:
· 周期性数据更新(看业务需求,如果你预估网站可能会变得更好,也可以一步到位,加个日更的)
· 热更新或平滑切换
· 版本可回滚
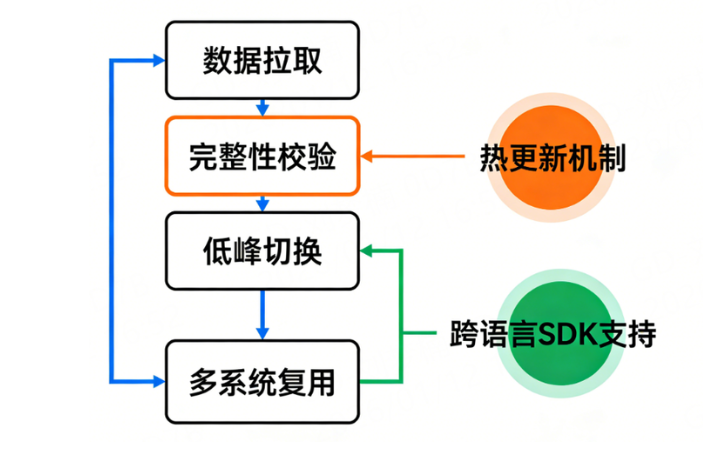
我们通常采用的是:
· 定时拉取实时离线库文件
· 校验完整性
· 在业务低峰期进行切换
3.多业务复用
IP离线库一旦部署好,可以被多个系统复用:
· 风控系统
· 日志分析平台
· 推荐/标签系统
· BI与数据仓库
这是一个典型的一次建设,多处收益的数据基础能力 。
Q4 、我们在选型中关注的几个现实问题
在真正落地时,我们也对市面上的IP离线库做过详细对比,主要关注以下几个维度:
1.定位精度是否适合国内业务
尤其是国内业务,至少需要:
· 省/市级别稳定
· 运营商信息可靠
· 移动网络、宽带网络区分合理
2.数据更新频率与维护成本
· 是否有稳定的数据更新节奏
· 是否需要人工频繁干预
· 更新流程是否自动化
3.工程友好度
包括但不限于:
· SDK是否成熟
· 文档是否工程向
· 是否支持高并发、批量查询场景
Q5 、要不要自己维护IP段数据?
结论很明确:不值得。
IP数据本身涉及:
· 多源数据采集
· 长期校准
· 灰度验证
· 运营商变更跟踪
这不是一个普通业务团队的"主航道能力"。
因此,我们采用的是成熟的第三方IP离线库方案。实际使用比对、测试后,选择了 IP数据云提供的离线IP库,原因很简单:
· 离线数据结构成熟,部署成本低
· 查询性能稳定,适合高并发与批量处理
· 国内IP定位在工程实践中比较可靠
· 更新机制清晰,适合自动化集成
在我们的系统里,它更像是一个底层数据组件,而不是一个"外部服务",当然适合我们不一定适合你们,IP数据云的数据库面向企业较多,如果是小型,可以考虑API,担心api不够还可以选择一些开源,但是这种可能数据不全,更新时间不定等问题。
总结
其实很多基础能力,只有在业务规模真正上来之后,才会意识到它的重要性。IP离线库并不是 什么 "高级玩法",而是规模化系统中非常典型的一块数据基础设施。
当你不再为IP查询的性能、稳定性、成本分心时,技术团队才能把精力真正投入到业务与算法本身。这也是我们在这次技术选型中的丰厚收获。
希望这篇分享,能对正在评估或已经遇到类似问题的同事有所帮助。