大模型推理服务在规模化落地过程中,面对流量突发、模型切换与节点故障等场景,如何实现秒级扩缩容与快速恢复,成为决定在线推理服务快速响应和长稳运行的关键挑战。
在 Qwen3-235B-A22B 等超大模型的推理服务实践中,百度智能云混合云团队基于 vLLM 框架,在扩容和容灾场景下,将推理服务拉起时间压缩到「几秒级」------模型权重可在约 2 秒内完成加载,采用预留的守护实例后,不到 5 秒即可对外提供服务。即便在集群没有空闲资源的情况下,也能将传统需要近 10 分钟的冷启动流程显著缩短到 2 分钟以内。
本文我们基于 vLLM 推理框架,结合 Qwen3-235B-A22B 的实践案例,对大模型推理服务的冷启动路径进行拆解与分析,并介绍我们在模型权重加载、编译缓存、CUDA graph 捕获以及实例调度等关键环节上的优化思路。
1. 大模型推理冷启动开销分析
传统的 Kubernetes 水平 Pod 自动扩缩方案,本质仍停留在 Pod 层级的资源调度与生命周期管理。在这一模式下,平台只能通过镜像预铺、节点预热等手段缩短容器启动时间,却无法深入推理引擎内部,对模型权重加载、GPU 内核 JIT 编译、CUDA Graph 捕获等关键启动流程进行优化。这就导致在 Kubernetes 体系内,即便完成资源调度后,从 0 拉起一个大模型推理服务仍需经历完整的冷启动流程,整体耗时近 10 分钟,且该延迟会随模型参数规模扩大而进一步加剧,难以支撑大模型推理服务对快速扩缩容与快速恢复的现实需求。
完全冷启动一个 Qwen3-235B-A22B 模型的推理服务的流程及各步骤耗时统计如下:
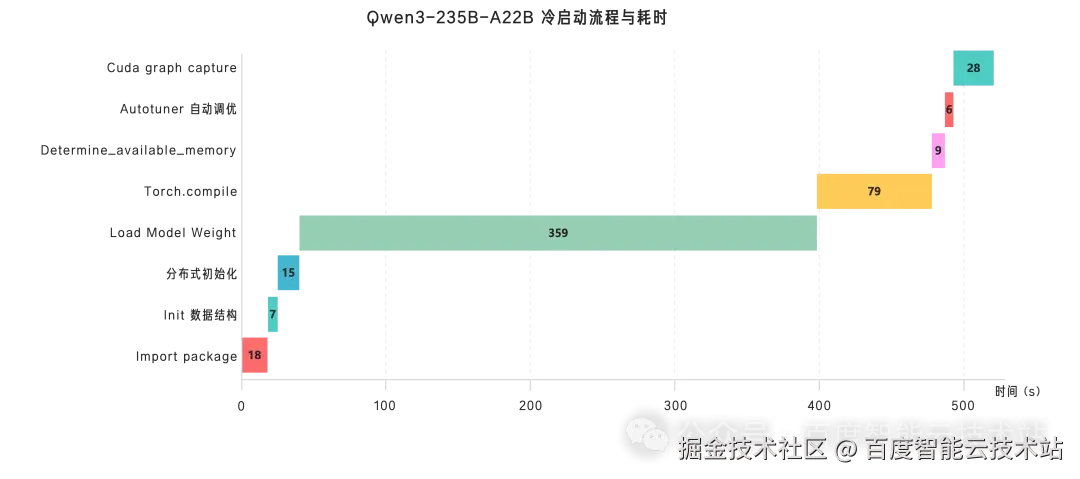
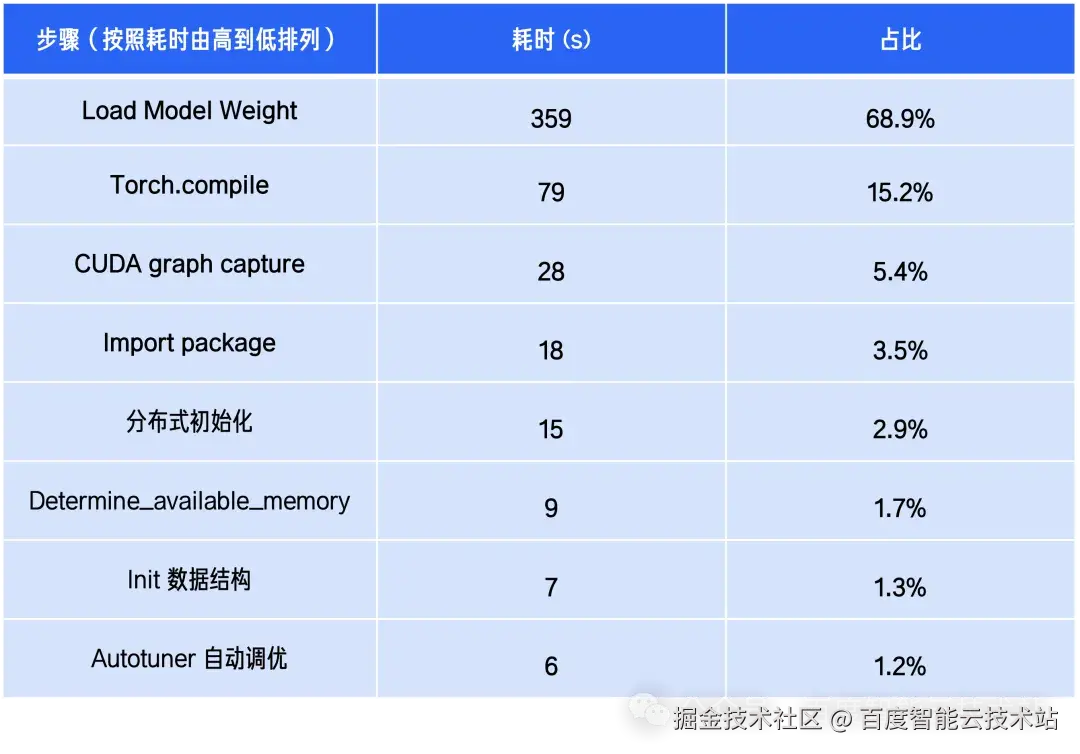
可以看出:大模型推理服务的冷启动流程中:Load Model Weight(模型权重加载)、torch.compile 编译、CUDA Graph 捕获以及 import package 占据了主要耗时。这些流程是大模型推理引擎在保障推理性能与吞吐能力时所必需的基础能力:
- Load Model Weight:是将 .safetensors 的模型权重从磁盘加载到显存中的对应位置,其决定了推理计算是否能够在显存中高效展开;
- torch.compile 编译:通过 JIT 编译将模型代码转换为高效执行的计算图,显著降低了推理过程中的调度与解释开销;
- CUDA graph capture:通过消除 CPU-GPU 同步开销和内核启动延迟,使得显著提升深度学习推理和训练的性能;
- import packages:服务启动时将依赖库文件从磁盘加载到内存并完成初始化,为后续推理流程建立基础运行环境。
因此,大模型推理服务优化的核心目标:就是在不牺牲推理性能的基础上降低冷启动耗时,保证大模型推理服务的快速扩缩容与快速容灾。
2. 推理服务启动流程优化
基于上述目标,我们首先聚焦启动流程中最耗时的关键环节,开展针对性优化与耗时削减:通过跨实例模型权重加载加速、跨实例中间状态复用、延迟 CUDA graph 捕获、基于 Fork 的多进程初始化加速等核心手段,优化推理服务启动路径。
在此基础上,我们进一步利用集群空闲资源,引入守护实例机制,将启动流程所需的 CUDA 上下文持久化保留在 GPU 显存中。这一设计可大幅压缩启动流程中各项初始化、编译以及 CUDA graph 捕获的耗时,再结合模型权重加载加速,实现启动全流程的加速闭环,最终显著提升扩容及故障恢复场景下的响应效率。
2.1. 跨实例的模型权重加载加速
在大模型推理服务扩容过程中,模型权重加载是冷启动中最主要的耗时来源之一。传统加载方式需要从磁盘读取数据,经由 CPU 内存再拷贝到 GPU 显存。特别是磁盘到 CPU 内存的读取速度较低,严重限制了整体加载效率。此外,不同扩容场景下,权重传输所面临的硬件条件并不相同:既可能发生在同一台机器的 GPU 之间,也可能发生在跨节点的 GPU 集群之间。
因此,我们根据机内与机间的不同拓扑条件,分别采用了 NVLink 与 RDMA 等高速网络技术作为权重加载的底层方案,从已有节点直接将权重同步到目标 GPU,整个过程中只需一次 NVLink 或 RDMA 传输,避免了传统「磁盘 → 内存 → 显存」的低效路径。
整体流程如下图所示:
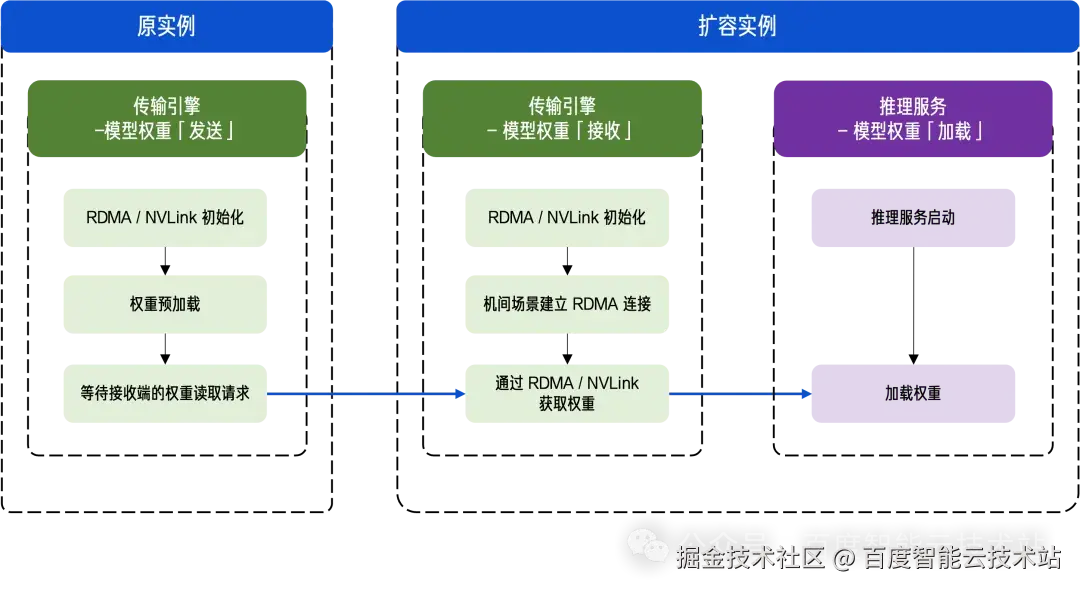
原实例的传输引擎发送端与扩容实例的接收端直接建立连接,通过高性能 RDMA / NVLink 进行模型权重的高速传输(机内场景用 NVLink,机间场景用 RDMA),新扩容的推理服务则从传输引擎直接加载权重。
- 机内场景中:发送端将切分后的权重存储在 GPU 显存中,当接收端发起读取请求后,权重会通过 NVLink 以极高带宽直接从发送端同步至接收端 GPU;
- 机间场景中:发送端会提前将权重存储在 CPU 内存中,并按照接收端各 GPU 的 Rank 进行切分,并等待接收端发起读取请求;接收端会为每个 GPU 启动独立的 RDMA 连接,并为其分配一张独立网卡,与发送端建立连接后并行发起读取请求,充分利用多张网卡的高带宽并行传输能力,高速拉取权重。
在实际测试中,我们能够在 约 2 秒内 将 Qwen3-235B-A22B 的 348 GB 权重完整传输到新机器上。
2.2. 跨实例的中间状态复用
在推理服务冷启动过程中,会有大量中间状态的缓存文件。这些中间状态往往与模型结构、推理引擎实现以及运行环境强相关,其生成过程通常伴随着 GPU 内核的 JIT 编译,耗时显著。在扩容场景下,合理有效的复用这些中间状态文件,可以极大的降低冷启动中编译相关流程的时间开销,从而加速推理服务部署。
从复用方式上看,这类跨实例的中间状态包含两类:
第一类是「拿来即可用」的中间状态,这类状态与具体运行参数无强绑定关系,只要模型与引擎版本一致,即可直接复用。例如:
- model_infos:在读取模型权重文件中的 config.json 后,根据该配置文件生成的一份与推理引擎特性相关的配置支持情况的 JSON 文件;
- deep_gemm:当模型首次执行特定配置的矩阵乘法时,deep_gemm 的 JIT 编译器会在运行时动态生成一个为当前计算任务高度定制化的 cuda 代码,然后调用 nvcc 将其编译为高效 kernel,deep_gemm 目录中就缓存了这个高效 kernel 的实现。
对于这类中间状态,我们在集群层面通过公共存储,或在扩容节点上通过 RDMA 进行快速迁移复制,使新节点能够直接复用已有结果,避免重复编译。
第二类中间状态则是根据参数与环境生成的哈希值去判断是否可复用,主要包括 torch_compile_cache、backbone、inductor_cache、triton_cache 等。如果缺乏有效的命中机制,这部分缓存往往会在扩容时被全部重新编译,成为启动过程中的主要瓶颈。
对此,我们优化了 hash 命中的逻辑,采用一致性哈希来保证扩容场景的推理引擎可以 100% 命中快速迁移过来的中间状态。
通过上述机制,推理服务在扩容或节点恢复时,可以根据实际需要,自适应地复用已有编译成果,从而显著缩短服务拉起时间。
2.3. 延迟 CUDA graph 捕获 (Lazy CUDA graph)
当前大模型推理框架在引擎初始化阶段会捕获大量 CUDA graphs,显著减慢了启动时间,根据模型大小和 GPU 类型,这个过程一般会超过 10 秒。更重要的是,实际运行中很可能不会用到所有预捕获的 graphs,造成了时间和内存的双重浪费。
lazy CUDA Graph 的核心思想是分阶段捕获 CUDA graphs:
- 初始化阶段:只捕获最小必要的 CUDA graphs(通常是最大 size 的 graph),用于正确初始化 GPU 现存池,避免 OOM 和显存碎片问题;
- 第一条请求阶段:当第一条实际推理请求到达时,一次性捕获所有剩余需要的 graphs;
- 后续请求阶段:直接使用已缓存的 graphs 进行推理。

引入 Lazy CUDA graph 机制,推理服务可以在不牺牲最终推理性能的前提下,大幅缩短初始化阶段的启动时间:通过延迟捕获,vLLM 可以将初始化时的 torch.compile + CUDA graph capture 由 10~60s 减少到 1~2s,大幅提升了用户体验,尤其在快速扩缩容以及模型热切换等场景中,快速启动意味着更快的服务响应时间、更低的冷启动成本,且可以避免客户妥协性能(如配置 --enforce-eager 参数);同时,通过分阶段捕获,确保内存池正确初始化后再进行完整捕获,既避免了OOM 风险,又保证了内存使用的高效性。
这种分阶段的捕获策略,使推理引擎在开发测试、自动扩缩容以及生产环境中都具备更强的适应性。
2.4. 基于 Fork 的多进程初始化加速
在导入 package 过程中,vLLM 默认采用 spawn 的方式创建子进程。spawn 会启动一个全新的进程环境,子进程与父进程之间不共享任何上下文状态。
这种方式的优势在于安全性:一旦父进程中已经创建了 CUDA 上下文,子进程直接复用上下文可能导致不可预期的错误,因此通过 spawn 启动一个「干净」的进程,是推理框架中最稳妥的默认选择。基于这一机制,vLLM 的服务启动进程 api_server 会先 spawn 一个 engine_core 子进程,而 engine_core 又会根据张量并行(TP)的切分数,来 spawn 对应数量的 GPU worker 子进程。
然而,在对 vLLM v0.11.0 官方镜像的启动流程进行验证后,我们发现,在 GPU worker 子进程创建之前,系统尚未初始化任何 CUDA 上下文。这意味着,在该阶段使用 fork 方式创建子进程,并不会引入 CUDA 上下文复用带来的风险。
基于这一判断,我们在确保 CUDA 上下文尚未创建的前提下,将部分子进程的创建方式由 spawn 调整为 fork。相较于 spawn,fork 会直接继承父进程的执行状态,已加载的 Python 包与初始化结果无需重复执行,从而显著减少进程启动阶段的额外开销。
2.5. 守护实例预铺
在线上业务中,推理集群往往需要承受流量的波峰与波谷,并且对于 LLM 服务而言,瞬时到来的流量峰值使用的是何种模型完全不可预知,临时拉起巨大参数量的推理引擎又需要数分钟。
因此,我们提出了守护实例预铺的方案:在系统中预先保有不同模型的推理服务实例,当需要扩容时快速唤醒实例并启动推理引擎对外提供服务。当然,保留完整的推理服务会占用大量的集群资源,因此我们在守护实例中主动释放模型权重与 KV cache,GPU 中仅保留核心的 CUDA 上下文,以平衡资源占用与快速响应的需求。
- 当流量到来需要扩容时,系统精准唤醒目标模型的守护实例,依托 HBM 中预留存的 CUDA 上下文,可瞬间完成各种初始化操作;再借助「模型权重加载加速」(见本文 2.1 节)机制,通过 RDMA 协议将权重快速加载至显存,模型权重加载完成后,再次借助保留的 CUDA 上下文快速完成编译、CUDA graph 捕获等后续流程。基于该方案,在 Qwen3-235B-A22B 模型的实际测试中,整个扩容启动流程耗时仅 6s;
- 当流量回落时,实例会主动清理模型权重、KV cache 等信息,重新进入守护状态,该状态切换过程耗时仅 1-2s。
依托这种「快速唤醒、快速静默」的机制,推理集群可在避免大量占用集群资源的前提下,实现大模型服务的快速弹性扩缩容。
3. 最佳实践
围绕大模型推理冷启动中的关键耗时路径,我们从模型权重加载、编译缓存、CUDA Graph 捕获以及进程初始化等多个层面进行了系统性优化。其中,跨实例权重传输加载加速、跨实例的中间状态复用、以及多进程初始化优化,构成了推理服务快速拉起的基础能力;而守护实例预铺与 Lazy CUDA Graph,则为不同资源条件和业务需求提供了可选的性能加速手段。
基于此,我们针对覆盖资源充足、资源受限以及对首请求时延敏感等不同业务场景,落地了三种优化方案。
-
场景一:面向用户体验敏感的核心服务、以及需要多模型快速切换的场景时,在集群有空闲资源的前提下,启用守护实例预铺:充分利用显存资源,在集群内的空闲机器上预先启动多个模型守护实例以达到快速启动的效果,同时将无法传输或缓存的 CUDA 上下文进行预铺,从而解决 CUDA graph capture 等流程的开销。此时,推理服务的启动时间最短,用户体验最佳;
-
场景二:面向对首请求延迟要求较低的容灾恢复场景或对服务响应速度不高的扩容场景(比如后台批处理、开发测试环境等),在集群没有空闲资源的情况下,关闭守护实例预铺,启用延迟 CUDA Graph 捕获。此时,集群虽无空闲资源,但由于将 CUDA graph 延迟捕获,启动速度仍然较快,且资源利用率较高;
-
场景三:面向启动频率较低、工作负载相对固定的扩容场景时,在集群没有空闲资源的情况下,关闭守护实例预铺与延迟 CUDA Graph 捕获。此时,通过跨实例权重传输加载加速、中间状态复用以及基于 Fork 的多进程初始化加速手段,相较于冷启动而言,已经可以大幅提升启动效率。
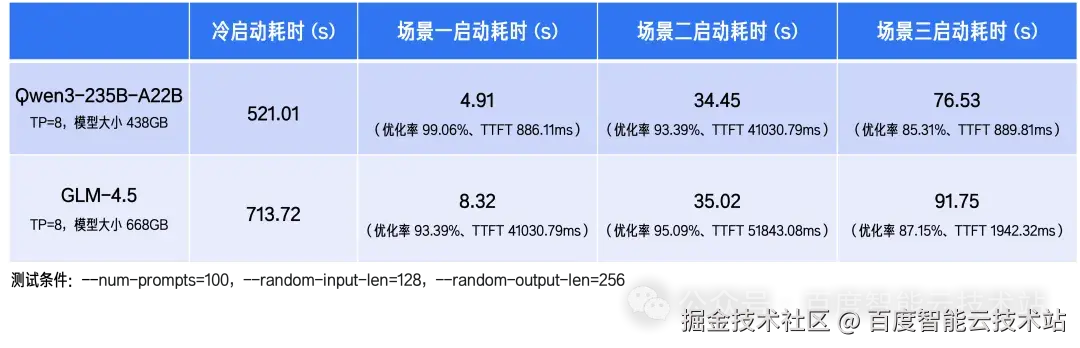
以 Qwen3-235B-A22B 与 GLM-4.5 模型为例,下表中列出了三种不同方案下的推理服务启动效果:
4. 结语
面对大模型推理服务在动态负载、资源效率与节点容灾上的多重挑战,我们从推理引擎启动路径出发,构建了一套覆盖多种业务场景的弹性扩缩容方案。该方案通过模型权重加载加速、中间状态复用、延迟 CUDA Graph 捕获、守护实例预铺等关键机制,对传统冷启动流程进行系统性重构,使推理服务能够在不同资源条件下实现快速拉起与稳定恢复。
在此基础上,我们针对资源充足与资源受限等典型场景,形成了可组合、可按需选择的扩容策略,在保障高可用与推理性能的同时,有效降低了扩缩容过程中的时间与资源成本。这套实践不仅解决了大模型推理在弹性层面的工程难题,也为构建兼具性能、稳定性与成本可控性的推理基础设施提供了可落地的参考路径。
接下来,百度百舸将完成上述能力在昆仑芯 XPU 的落地与验证,并将进一步结合超节点等多样化硬件形态,以及 vLLM、SGLang 等主流推理框架,持续完善推理引擎启动路径与算力特性的协同优化,逐步探索多模态推理框架的落地实践,覆盖更广泛的集群与业务场景。