目录
[1. 多模态表征与统一语义空间](#1. 多模态表征与统一语义空间)
[2. 多模态融合机制](#2. 多模态融合机制)
[3. 联合训练与任务设计](#3. 联合训练与任务设计)
[1. 模态扩展与通用性提升](#1. 模态扩展与通用性提升)
[2. 可解释性与安全性研究](#2. 可解释性与安全性研究)
[二、混合专家模型(Mixture of Experts, MoE)](#二、混合专家模型(Mixture of Experts, MoE))
[(二)MoE 的核心技术组成](#(二)MoE 的核心技术组成)
[1. 专家网络群(Experts)](#1. 专家网络群(Experts))
[2. 门控网络(Gating Network)](#2. 门控网络(Gating Network))
[3. 稀疏激活(Sparse Activation)](#3. 稀疏激活(Sparse Activation))
[(三)MoE 的代表性架构与典型论文](#(三)MoE 的代表性架构与典型论文)
[1. Sparsely-Gated Mixture-of-Experts(基础 MoE)](#1. Sparsely-Gated Mixture-of-Experts(基础 MoE))
[2. Switch Transformer](#2. Switch Transformer)
[3. GLaM(Google Mixture of Experts)](#3. GLaM(Google Mixture of Experts))
[4. LIMoE(Multimodal MoE)](#4. LIMoE(Multimodal MoE))
[5. 其他进阶研究](#5. 其他进阶研究)
[(五)MoE 的优势与适用场景](#(五)MoE 的优势与适用场景)
[三、大小模型云端协同(Cloud‑Edge Model Collaboration)](#三、大小模型云端协同(Cloud‑Edge Model Collaboration))
[1. 云端大模型层(Cloud Large Model)](#1. 云端大模型层(Cloud Large Model))
[2. 边缘小模型层(Edge Small Model)](#2. 边缘小模型层(Edge Small Model))
[1. 分层推理(Hierarchical Inference)](#1. 分层推理(Hierarchical Inference))
[2. 知识蒸馏(Knowledge Distillation)](#2. 知识蒸馏(Knowledge Distillation))
[3. 异步协同与模型管道化](#3. 异步协同与模型管道化)
[4. 数据路由和任务划分策略](#4. 数据路由和任务划分策略)
[1. 协同策略设计复杂](#1. 协同策略设计复杂)
[2. 网络带宽与延迟限制](#2. 网络带宽与延迟限制)
[3. 一致性与版本管理](#3. 一致性与版本管理)
[4. 动态环境适应](#4. 动态环境适应)
干货分享,感谢您的阅读!
在人工智能快速进化的当下,"理解"已不再是文本或语音的孤立能力,而是在多种信息形式间建立联系。人类感知世界通过视觉、听觉、触觉、味觉、嗅觉等多种通道综合形成认知,而现代智能系统正努力模仿这种多样化输入--输出机制。多模态大模型(Multimodal Large Models)正是这一趋势下的产物。它要求模型具备同时处理文本、图像、音频等多种模态数据的能力,以便完成更复杂、更人性化的任务。
概括而言,我们从多模态大模型的基本概念出发,开始探讨混合专家模型(Mixture of Experts,MoE)的设计动机、优势与挑战,并进一步剖析大小模型云端协同的工程实践意义。
一、多模态大模型
(一)什么是多模态大模型
在人工智能领域,模态(Modality) 指信息输入或输出的类型,例如文本、图像、音频、视频等的数据形式。一个系统如果能够同时理解并处理两种或多种不同模态的数据,则称之为 多模态系统(Multimodal System)。
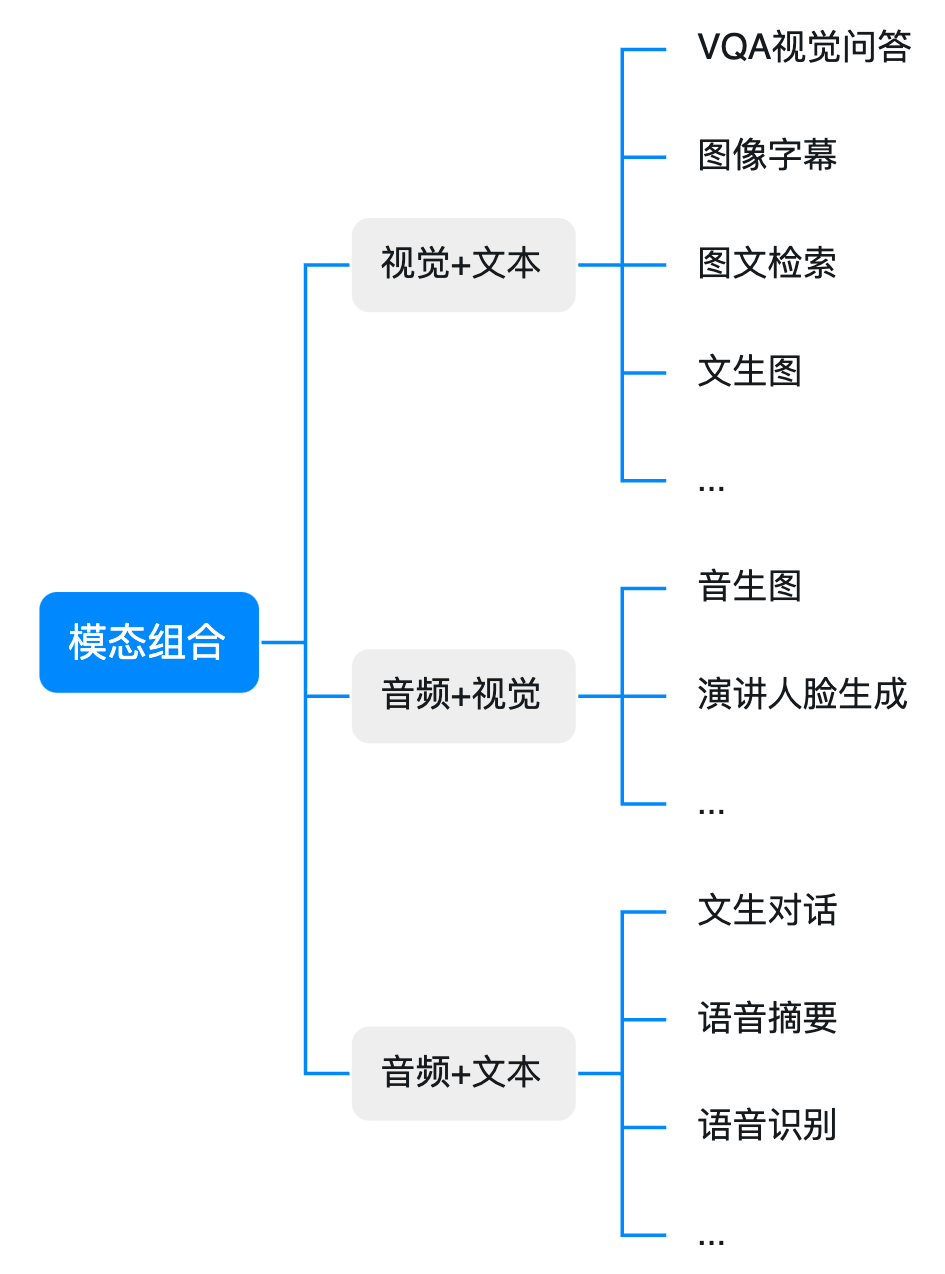
多模态大模型则是这一理念在大规模深度学习架构中的实现:它能在统一的框架下理解、对齐、融合和生成来自不同模态的数据,从而实现更接近人类认知能力的智能表现。

从任务范畴来看,多模态大模型涵盖了如下能力:
-
跨模态匹配与对齐:例如给定一段文字检索对应图像,或根据图像生成描述性文本(跨模态对齐);
-
统一理解与推理:结合不同模态的输入进行复杂推理(如视觉问答、视频理解等);
-
跨模态生成:例如文本生成图像、图像生成文本、视频生成描述或视频内容生成音乐等(生成任务)。
学术界将这类模型统称为 Multimodal Large Language Models(MLLMs) 或广义的多模态大模型,并对其架构、训练、任务与评估展开了深入研究与系统综述(Multimodal Large Language Models: A Survey)arXiv。
在多模态大模型的定义下,传统的单模态模型(只处理文本或只处理图像)不再满足对丰富复杂场景理解的需求;因此,多模态大模型成为推动智能系统向更高级能力迈进的重要技术方向。
(二)多模态大模型的核心技术
构建多模态大模型涉及多个关键技术组件,每一部分都代表着突破性的研究工作:
1. 多模态表征与统一语义空间
不同模态的数据具有不同的结构和分布特性。多模态大模型的首要挑战是如何将它们映射到统一的语义空间,使得模型可以在这一空间中进行跨模态比较与检索。
一种基础方法是 对比学习(Contrastive Learning),代表性工作是 CLIP(Contrastive Language--Image Pre-training)。CLIP 使用大规模的图像-文本对,通过最大化正样本对在共享向量空间内的相似度、最小化负样本对的相似度,实现图像和文本嵌入的对齐(即共同的嵌入空间)百度智能云+1。这一对比学习机制通过 InfoNCE 等损失函数优化,使模型学会在统一空间表示不同模态特征。
除了对比学习外,还有 自监督学习、自编码任务、图像-语言匹配损失(ITM)等多种设计,进一步提升模态对齐精度。
2. 多模态融合机制
完成表征后,多模态大模型需要将各个模态的信息进行深度融合,以便完成下游任务。融合主要有以下几类策略:
-
早期融合(Early Fusion):直接在输入阶段将不同模态嵌入拼接并送入统一编码结构;
-
中期融合(Intermediate Fusion):对各个模态分别编码,再通过自注意力或交叉注意力机制在 Transformer 中交互融合;
-
晚期融合(Late Fusion):对各模态的结果单独处理后,在判断层或任务层整合结果。
如 ViLT、ALBEF 等视觉-文本模型通过交互注意力机制在多个 Transformer 层融合视觉与文本特征,提高理解与推理能力,适用于视觉问答与图像检索等任务百度智能云+1。
3. 联合训练与任务设计
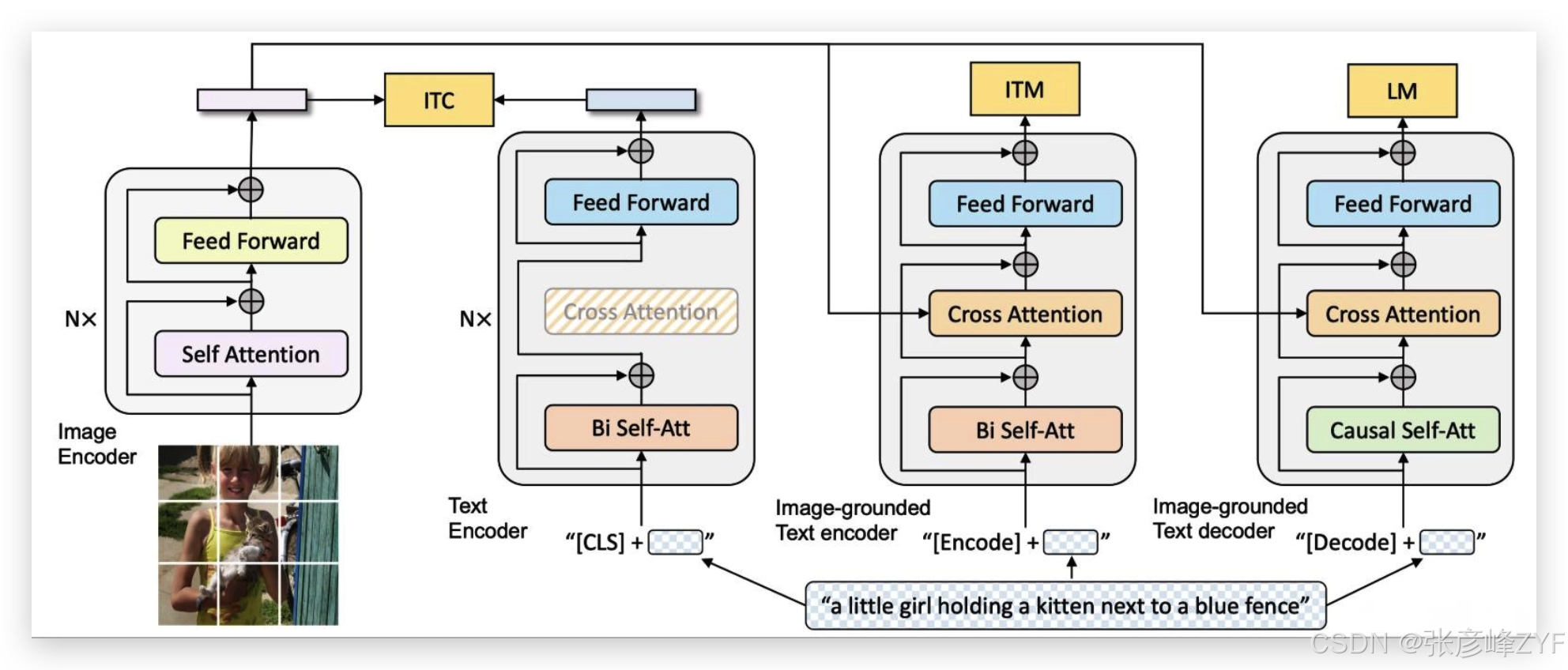
多模态大模型往往通过 联合训练(Joint Training) 同时优化多种任务损失,例如:
-
对比损失(Contrastive Loss):用于学习跨模态对齐;
-
图文匹配损失(ITM):引导模型判断图文是否匹配;
-
生成损失(Language Modeling Loss):使模型能够根据图像生成自然语言描述(图像 captioning);
-
自监督任务:通过掩码或拼图任务恢复输入,提高泛化能力。
BLIP(Bootstrapping Language--Image Pre-training)便是多任务联合训练的典型架构,通过对比学习、图像-文本匹配、生成任务等策略组合学习,使模型同时具备检索能力与生成能力技术栈+1。
(三)典型多模态大模型案例
下表列出了多模态研究中的代表性模型,并简要说明其技术特点与贡献方向:
| 模型 | 主要技术 | 代表性贡献 |
|---|---|---|
| CLIP | 对比学习 + 共享嵌入空间 | 在大规模图像-文本配对语料上实现通用图像理解能力,具备零样本学习能力百度智能云 |
| BLIP / BLIP2 | 多任务联合训练 | 结合对比学习、图文匹配、生成任务,提高理解+生成能力技术栈 |
| ViLT | Transformer 融合结构 | 简化视觉编码架构,通过交互注意力实现高效视觉-语言融合百度智能云 |
| LLaVA / MiniGPT-4 | 语言大模型 + 视觉接口 | 构建可对话的视觉语言大模型,增强复杂场景理解能力(见专业综述)Joseri的小站 |
| GPT-4V 及其变体 | 强通用推理 + 多模态输入 | 在多模态推理任务中表现优异,被视为多模态大语言模型典型代表(见 Oxford Academic survey)OUP Academic |
这些模型在图像分类、跨模态检索、视觉问答、图像描述生成甚至复杂推理等任务中均有优异表现,成为实际工业落地中的重要基础能力。
(四)多模态大模型的研究进展与趋势
近年来,多模态大模型的研究呈现以下发展趋势:
1. 模态扩展与通用性提升
传统多模态模型多聚焦于图像与文本,但最新研究正在拓展更多模态,例如:
-
音频/视频:将语音、视频流等引入统一框架;
-
3D 信息或动作捕捉数据:实现动作理解与 3D 场景感知;
-
跨语言多模态:支持不同语言与视觉信息协同理解。
2025 年的综述论文指出,最新多模态大语言模型已跨越文本与图像,覆盖音频、视频乃至 3D 输出等任务类别,并利用 SSL、MoE、RLHF 等高级技术提升模型能力边界arXiv。
2. 可解释性与安全性研究
随着多模态大模型在实际系统中的应用越来越广泛,其"黑盒"特性也带来可解释性与安全性挑战。最新的调查研究从数据级别、模型架构级别以及训练与推理策略级别提出可解释性的分类与方法,以提高实际部署中的可信度和鲁棒性arXiv。
多模态大模型通过将多种模态数据映射到统一语义空间、融合不同模态信息并支持上层生成或推理任务,实现了跨模态智能的范式转变。从 CLIP 提出的对比学习思想,到 BLIP 的多任务联合训练,再到最新通用多模态大语言模型,这一领域的技术体系日益成熟。当前研究不仅聚焦在更强的任务性能上,还在拓展模态边界、提升可解释性与安全性等方面推进多模态人工智能的发展。
(五)体验多模态大模型
构建和训练一个多模态大模型,涉及多模态表征学习、多模态转化、多模态对齐、多模态融合、协同学习等过程,不仅需要编程能力、深厚的机器学习和深度学习知识,还需要足够的计算资源和资金支持。对于大多数团队和个人来说,直接使用现有的多模态大模型或利用现有的预训练模型并对其进行微调以适应特定任务,是更为现实和高效的途径。
目前,市面上已经有很多商业化或开源的多模态大模型,你可以直接访问网页端使用,也可以直接调用API集成在业务中。例如:
二、混合专家模型(Mixture of Experts, MoE)
(一)混合专家模型的基本定义与背景
混合专家模型(Mixture of Experts, MoE) 是一种源自条件计算(Conditional Computation)思想的神经网络架构,通过多个专家子模型(Expert networks)配合一个门控网络(Gating network)实现稀疏激活 和动态路由。
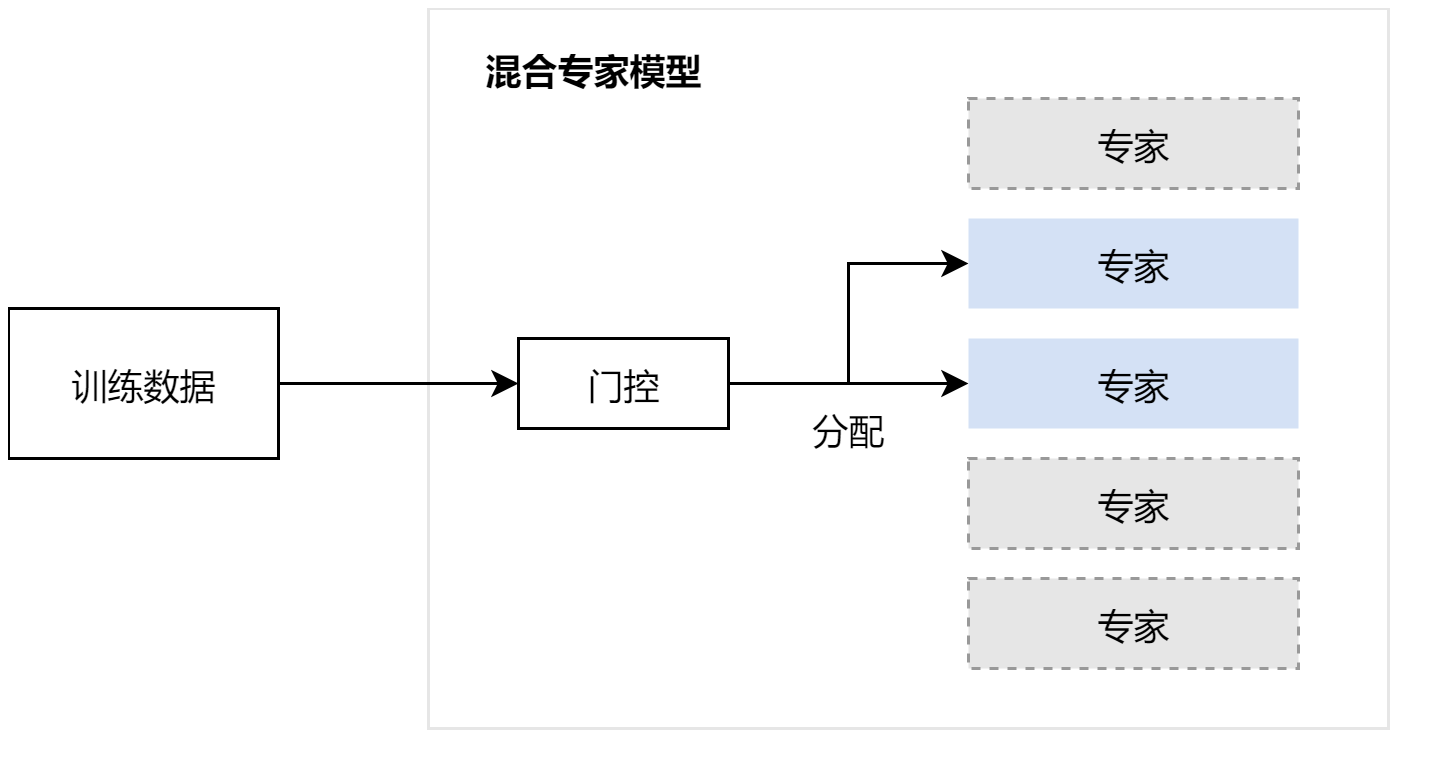
每个输入样本或 token 都由门控网络判断并分配给最适合的专家处理,从而在不显著增加计算负担的前提下扩展模型容量。其根本目标是:通过模块化设计实现大模型的高效扩展与领域专攻能力的提升。该设计早期可追溯至 1991 年针对监督学习的专家组合思想,但在深度学习与大规模 Transformer 应用中迭代发展出更成熟形式。53AI+1
在深度学习时代,MoE 的典型实现是 稀疏门控 MoE(Sparsely-Gated MoE),这种方式只对极少数专家进行激活,而其他专家在当前输入下保持静默,从而在参数量与实际计算成本之间取得最佳平衡。预印本
(二)MoE 的核心技术组成
构建一个混合专家模型,通常涉及三个关键组件:
1. 专家网络群(Experts)
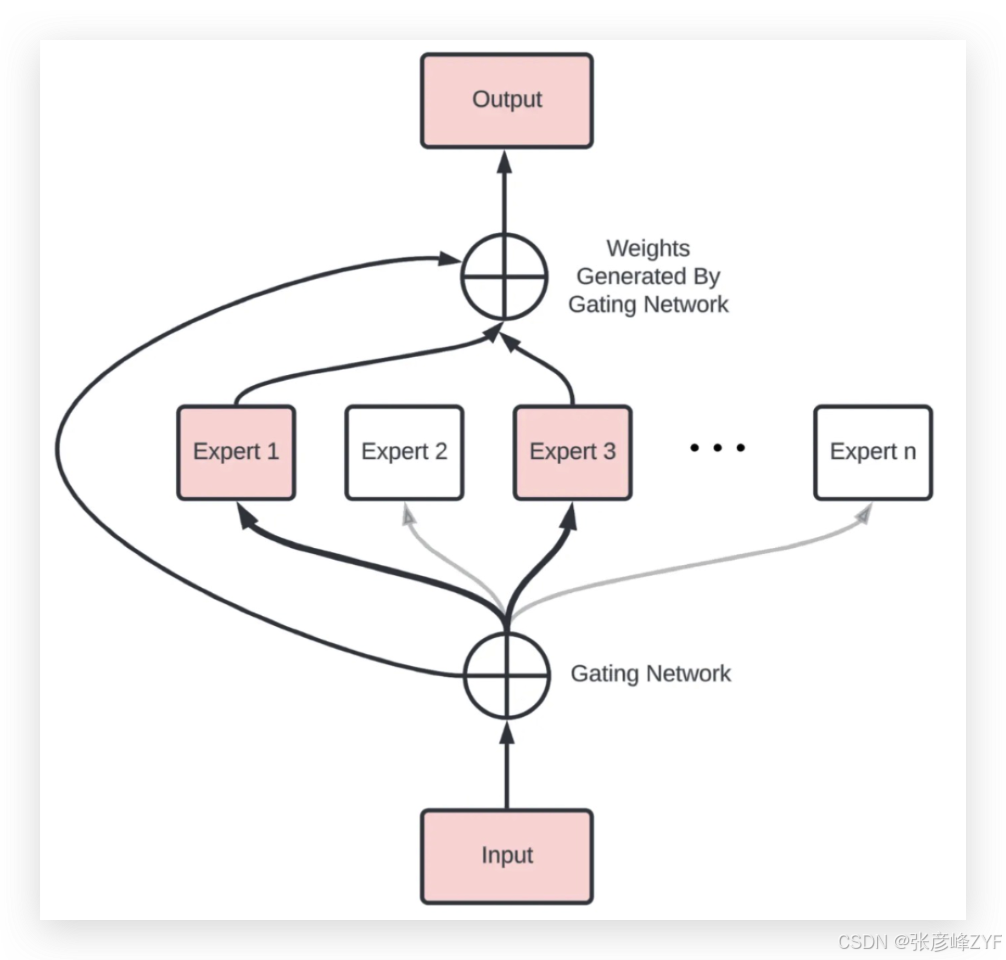
专家群指组成模型的多个子神经网络(Experts),每个专家网络结构通常与 Transformer 中的前馈层(Feed Forward Network)类似,但拥有独立参数。例如,可以设计 32、128 或更多个专家,使整体模型拥有海量参数,但大多数专家在每次输入中不被激活。预印本

这些专家的设计目标是实现任务或特征领域专攻,例如语言理解专家、语义推理专家、数学逻辑专家等,新近研究甚至提出将专家按特征空间分组并结合结构拓扑来增强专家多样性与不变性表示能力(Mixture of Group Experts)等探索。arXiv
2. 门控网络(Gating Network)
门控网络是 MoE 的核心,它根据输入样本的特征向量(例如 token 的中间隐藏表示)计算专家选择权重,在所有专家之间形成稀疏激活策略。
-
常用策略有 Top-k Gating, 即仅激活得分最高的 k 个专家,其余专家的激活权重为零;
-
可以加入噪声提高负载均衡性(Noisy Top-k),避免专家被偏向性地反复选择;
-
动态路由策略(如动态 fan-out 或自适应 k)会根据输入复杂度调整激活专家数量。预印本
门控网络的训练和专家网络同步进行,通过反向传播学习分配规则,使得专家逐渐形成特定细分模式的能力。
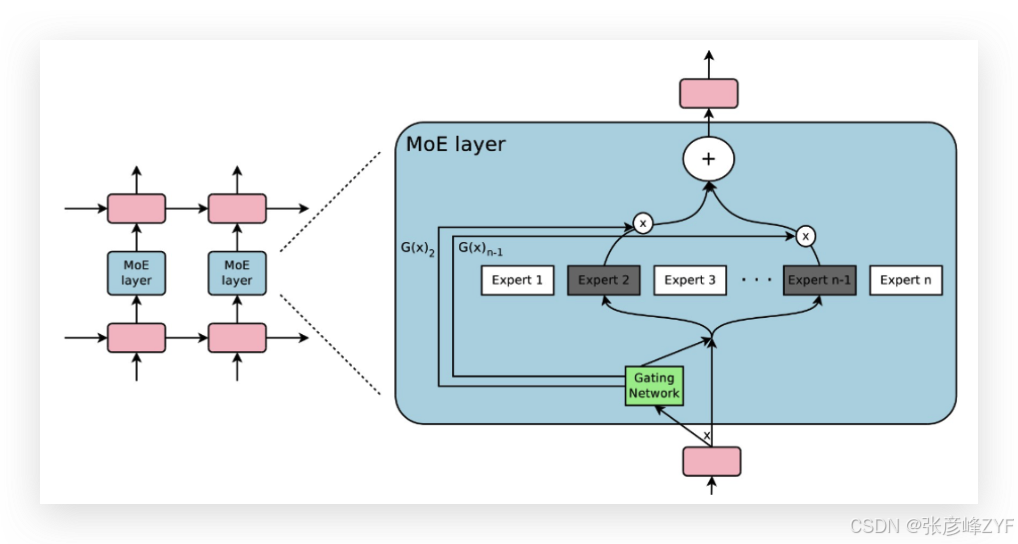
3. 稀疏激活(Sparse Activation)
MoE 的显著优势在于稀疏激活机制:对于每个输入样本,只激活少数专家(例如 Top-1 或 Top-2),从而使模型的有效计算成本与激活专家数量成正比 (而不是与总参数量成正比)。这意味着可以在"拥有极大模型容量"的同时保持"低推理成本"。预印本
例如,在图像或语言任务中,将 Transformer 的前馈层替换为 MoE 层后,可以通过稀疏激活策略将参数规模提升数十倍,而每个 token 实际参与的参数量仍然可控(如常见的 Top-2 激活模式)。Google Research
(三)MoE 的代表性架构与典型论文
1. Sparsely-Gated Mixture-of-Experts(基础 MoE)
论文 :Noam Shazeer 等人《Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer》首次将稀疏条件计算与深度模型结合,通过稀疏门控与上千个专家实现超过 1000 倍的模型容量增长,而实际计算成本几乎未增加。该工作是现代 MoE 的基石之一。arXiv
要点:
-
引入可训练门控网络动态选择专家;
-
模型对每个样本激活仅少数专家;
-
在语言建模和机器翻译任务中显示高效扩展能力。arXiv
2. Switch Transformer
论文 :Fedus 等人 《Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity》提出简化版 MoE 架构"Switch Transformer",在 Transformer 中维持专家数量极大(可达千级别),但每个样本仅激活单个专家,从而进一步降低通信开销与训练复杂性,支持更大规模参数扩展。Reddit
3. GLaM(Google Mixture of Experts)
论文 :Du 等人《GLaM: Efficient Scaling of Language Models with Mixture-of-Experts》展示了在大规模语言预训练中使用 MoE 的成功应用。其架构采用多个专家和路由策略将不同模态/任务分别路由到不同专家,从而在保持整体模型性能的同时减少了实际激活参数量。一只喵博客
4. LIMoE(Multimodal MoE)
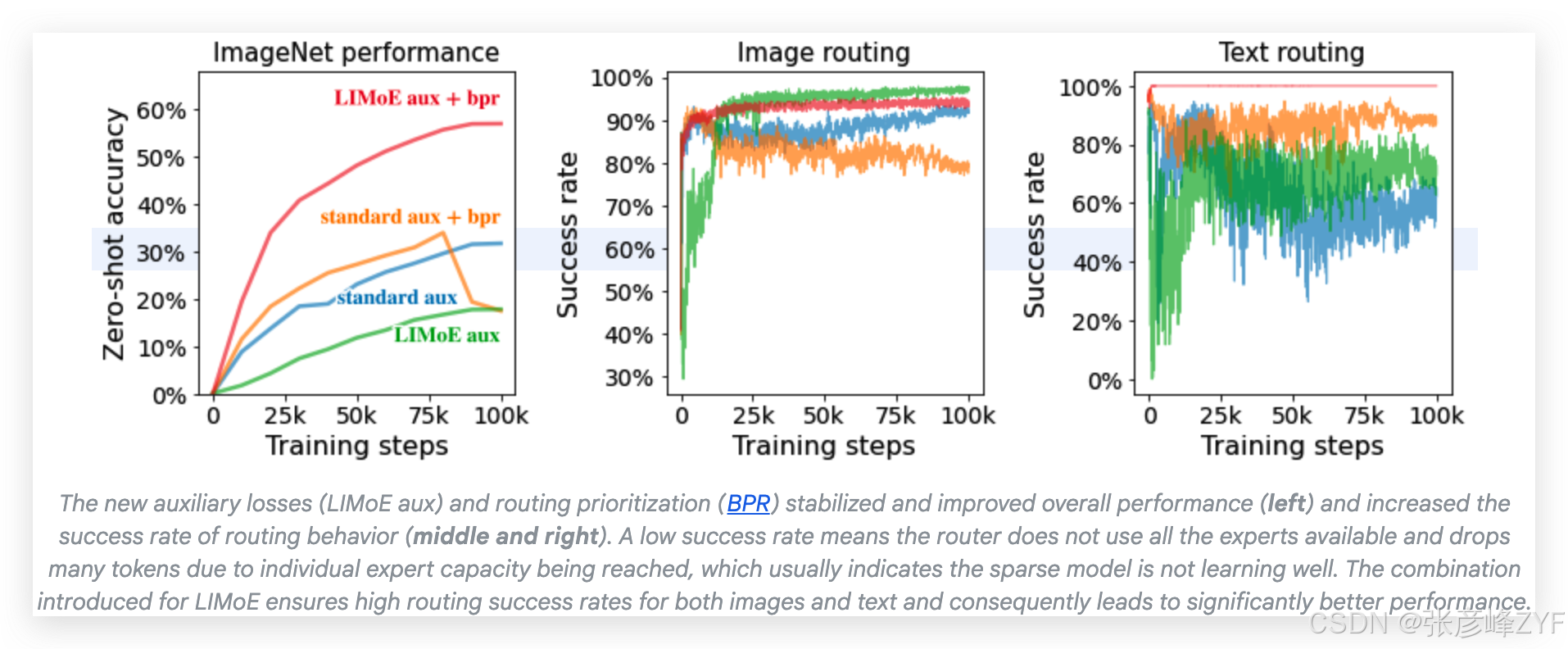
论文 :谷歌《LIMoE: Learning Multiple Modalities with One Sparse Mixture-of-Experts Model》将稀疏 MoE 应用于多模态数据(文本 + 图像),提出了新的辅助损失和路由优先策略,使得不同模态的数据都能得到有效路由,避免模态间路由冲突与专家饱和问题。Google Research
5. 其他进阶研究
-
Soft MoE :采用软分配机制,解决常规 MoE 在稀疏性与可微性之间的矛盾,并在视觉识别任务中取得优异性能表现。arXiv
-
Mixture of Group Experts(MoGE) :通过对路由输入进行结构化分组和正则化增强专家多样性和任务不变性表示能力。arXiv
(四)混合专家模型局限性
尽管混合专家模型在处理复杂任务和提高模型性能方面表现出众,但它们也有一些局限性:
-
计算资源需求高:MoE模型中的每个专家都是一个独立的模型,当专家数量增加时,模型的总参数量也相应增加,导致部署模型可能需要更多的GPU显存资源。
-
过拟合风险:由于参数量大和复杂性,可能比简单模型更容易过拟合训练数据,特别是当数据量不足时。
(五)MoE 的优势与适用场景
1. 显著扩展模型容量 :MoE 通过稀疏激活实现海量参数规模,在多个任务上超过对应密集模型的性能表现,同时控制计算成本。预印本
2. 计算效率与可扩展性增强 :对于训练和推理过程,每个 token 的计算成本仅与激活的专家数量有关,而非与总参数量线性相关,适合分布式与并行训练场景。预印本
3. 任务/模态专业化 :每个专家逐渐形成特定领域的处理能力,如语言推理、代码生成等,这意味着 MoE 结构更适合处理复杂、多任务、多模态学习等场景。Google Research
混合专家模型(MoE)架构通过动态路由稀疏激活机制将海量参数高效组织起来,实现了可扩展且计算高效的大模型实现方式。从基础的稀疏门控 MoE,到更先进的动态路由、多模态专家分配机制,MoE 已成为大语言模型、视觉模型及多模态模型扩展的主流架构之一。其核心优势在于 容量扩展、任务专攻与高效计算之间的战略权衡,仍是当前大模型研究与工程实践的重要方向。预印本
另外国内阿里巴巴开源了 Qwen3 系列的多款混合推理模型。该系列包含六款稠密模型:0.6B、1.7B、4B、8B、14B 和 32B,以及两款 MoE 模型:30B 和 235B。最新开源的旗舰模型 Qwen3-235B-A22B 拥有超过 2350 亿总参数和超过 220 亿激活参数。它在代码、数学和通用任务的基准测试中表现出色。如需体验和使用这款混合专家模型,请访问"百炼"平台的文本模型体验。
三、大小模型云端协同(Cloud‑Edge Model Collaboration)
(一)基本概念与背景
在人工智能系统的设计与部署中,模型大小直接影响系统的计算成本、响应延迟、泛化能力和资源适配性。通常我们将模型按照参数规模、计算复杂度和能力划分为:
-
大模型(Large Models):参数规模从数十亿到数千亿级别,具备复杂推理、高级语义理解及跨模态能力,但训练与推理资源消耗极高,不适合在资源受限环境下本地部署。
-
小模型(Small Models):参数规模小、计算成本低,适合在移动设备、边缘设备等受限环境下运行,但其表示能力和泛化性能较弱。
单一依赖大模型或小模型难以满足高性能、低延迟、低成本和隐私保护等综合系统目标。为此提出了 云端‑边缘协同架构(Cloud‑Edge Collaboration),也称为 大小模型协同(Large‑Small Model Collaboration) ,旨在充分利用云端大模型的强能力和边缘小模型的快速响应能力,构建高效弹性、低延迟、可扩展的 AI 系统。
这类协同架构在边缘计算与深度学习结合的研究中受到广泛关注,并有大量综述性论文论证其设计模式和优势(例如 Huang et al., 2022 对边缘云协同 AI 体系结构进行了系统调研)。
(二)协同架构设计
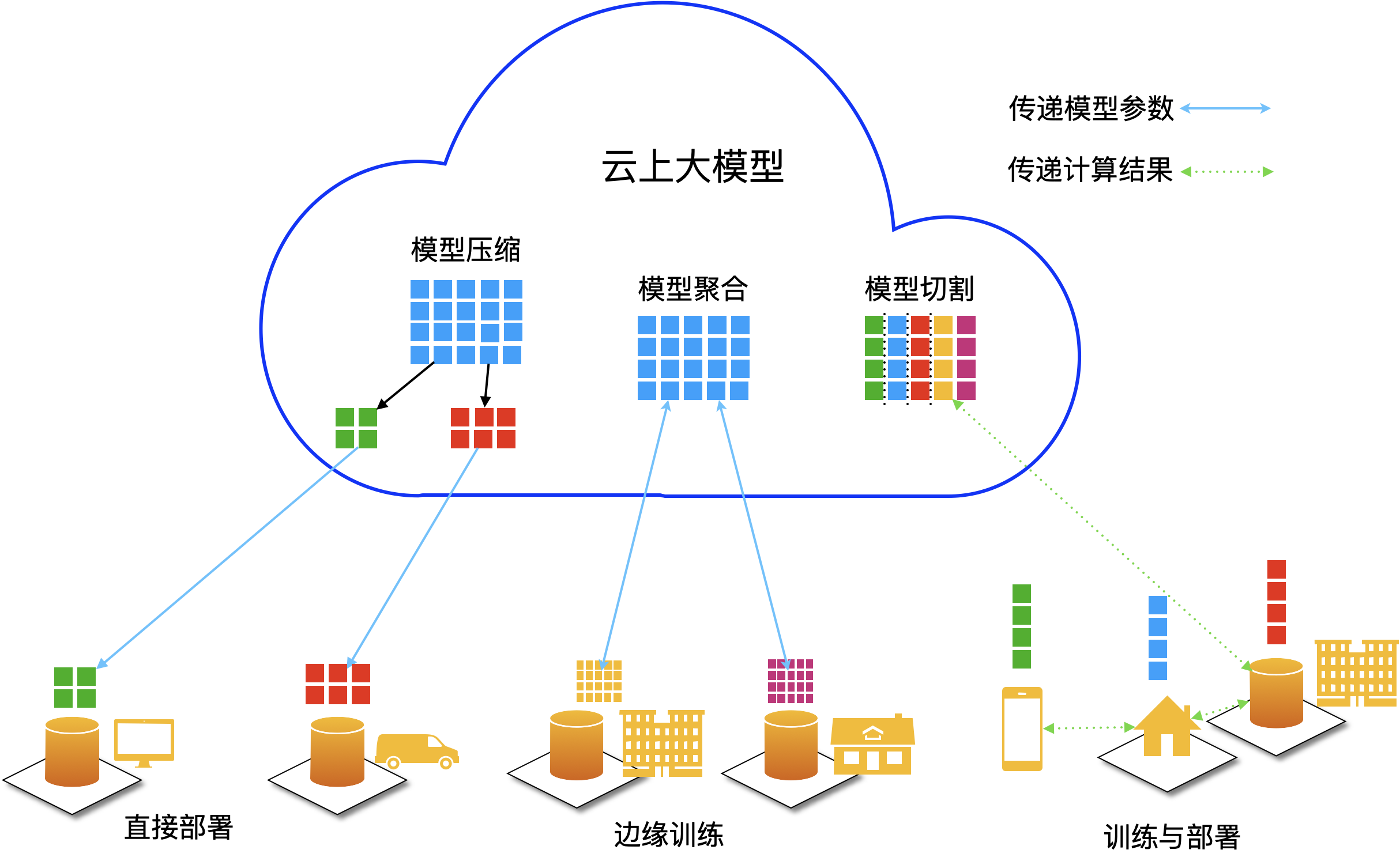
大小模型云端协同的核心目标是将任务合理分配给不同级别的模型,从而在计算效率、响应速度、模型能力与资源利用率之间实现平衡。典型架构可分为以下三层:
1. 云端大模型层(Cloud Large Model)
职责:
-
负责高复杂度、长序列、多模态与全局优化任务。
-
进行周期性模型训练和全局策略更新。
-
汇聚来自各边缘端的数据与反馈,实现整体性能改善。
逻辑说明:
云端大模型通常依托大规模 GPU/TPU 集群,运行高参数、高精度的深度神经网络,可以处理复杂自然语言理解、多模态融合推理等任务。这类模型如 GPT‑4、PaLM、Claude 等,在全局语义和策略推理上表现优异,但推理延时与计算资源消耗较高,因此不适合用于边缘设备上实时响应。
2. 边缘小模型层(Edge Small Model)
职责:
-
在终端设备或边缘服务器上进行快速推理与实时预处理。
-
在网络条件较差或隐私敏感场景下完成初级判断和快速响应。
-
梯度或特征摘要可定期上传云端,以辅助大模型训练与策略调整。
逻辑说明:
边缘小模型通常采用轻量级架构(如 MobileNet、TinyBERT、DistilBERT 等),在本地快速响应用户请求。例如在语音助手、即时推荐、实时监控中,小模型负责快速初筛,大幅降低用户响应延迟。
(三)协同机制与技术实现
大小模型协同的核心在于任务分担机制、模型下发与反馈机制以及协同推理策略。这些机制通常涉及多种优化技术:
1. 分层推理(Hierarchical Inference)
分层推理是一种 先轻后重、优先本地、再云端补充 的协同推理机制:
-
边缘小模型执行本地快速推理,判断结果是否确定:
-
如果信心高或属于低复杂度场景,则直接返回结果;
-
如果信心低或任务复杂,则将输入或抽象表达发送至云端。
-
-
云端大模型执行高级推理或全局优化任务,返回更准确的结果或建议。
-
边缘小模型根据云端回复进行本地结果融合与调整。
这一策略在异构设备普及的 AI 应用中有效减少延时与云端调用压力,同时保证一定精度与鲁棒性(如 Ramesh et al., 2023 探讨了多模态模型蒸馏与协同推理机制)。
2. 知识蒸馏(Knowledge Distillation)
知识蒸馏是一种将大模型知识迁移到小模型的技术,通过教师模型与学生模型之间的软目标与表示对齐,使小模型在保持紧凑规模的同时具备更强能力。典型方案包括:
-
响应蒸馏(Response Distillation):小模型学习大模型的输出概率分布;
-
特征蒸馏(Feature Distillation):小模型模仿大模型隐藏层特征;
-
关系蒸馏(Relational Distillation):保持样本间关系一致。
Hinton 等人在经典论文中提出蒸馏框架,为大小模型协同提供了基础方法(Hinton et al., 2015)。
蒸馏后的小模型可以驻留在边缘设备上执行高频请求,从而显著降低系统延迟和云端计算成本。
3. 异步协同与模型管道化
为了进一步提升效率,大小模型协同通常采用异步推理与管道化调度:
-
边缘小模型先行推理,得到初步结果;
-
同时向云端发起异步请求,云端进行大模型推理;
-
边缘模型在云端结果返回前继续本地任务执行或输出局部响应;
-
云端结果返回后,可进行本地再优化或模型更新。
异步机制减少了用户感知等待时间,同时通过缓存和预测机制进一步优化交互体验。
4. 数据路由和任务划分策略
合理划分任务是云边协同的关键。常见策略包括:
-
基于输入复杂度:如根据文本长度、语义难度等指标判断是否调用云端;
-
基于不确定性估计:边缘模型输出低置信度时自动提升至云端;
-
基于资源动态调整:根据设备负载、网络质量动态调整推理路径。
这些策略通常借鉴置信度估计、贝叶斯推断等方法,在实际应用中显著提高系统效率与可靠性。
(四)协同架构的优势
大小模型云端协同在实际工程与研究中具有显著优势:
- 响应速度低延迟:边缘小模型在本地执行推理,无需每次都依赖网络返回,极大降低了在线响应延迟,对实时性要求高的场景(如语音交互、智能监控)尤为关键。
- 资源利用高效:云端大模型可以集中处理高复杂度任务,并通过蒸馏与策略下放减少重复计算,小模型承担高频低复杂度推理任务,整体资源利用率更高。
- 隐私保护与数据安全:边缘小模型可在本地处理敏感数据,无需传输至云端,实现更高的数据隐私保护,符合 GDPR、CCPA 等法规要求。
- 可持续学习与模型演化:云端大模型可持续聚合边缘反馈数据进行再训练,再将优化后的策略推送至边缘,形成闭环学习与持续更新机制,提升整体系统能力。
(五)协同架构面临的挑战
尽管大小模型云端协同优势明显,但其在工程实施中仍面临挑战:
1. 协同策略设计复杂
任务划分、模型选择与路由策略需要根据具体业务场景进行细致设计,错误的划分可能导致性能下降或资源浪费。
2. 网络带宽与延迟限制
边缘设备与云端的网络连接可能不稳定或带宽受限,在数据传输密集或实时性强的场景中需要设计容错机制。
3. 一致性与版本管理
模型更新与部署需在云端和边缘设备之间保持一致性,否则可能导致推理结果差异或版本冲突。
4. 动态环境适应
不同设备性能差异大、用户操作场景多变,需要动态适配模型大小、推理策略和调度策略,这对系统架构提出更高要求。
(六)应用实例与实践
大小模型云端协同在多个实际场景中得到应用:
-
智能客服与对话机器人:边缘小模型处理标准问答,大模型处理复杂对话生成;
-
电商推荐系统:边缘模型快速筛选候选集,云端模型做全局排序与策略优化;
-
多模态智能终端:边缘模型可处理简单视觉或语音推理,大模型负责多模态融合与高质量生成;
-
智能监控与自动驾驶:边缘视觉模型实现低时延检测,云端模型实现长期行为学习与策略优化。
这些场景中的协同策略显著提升了实时性和用户体验,同时控制了系统成本。
(七)研究进展与论文标注
| 主题 | 代表性工作/论文 | 说明 |
|---|---|---|
| 边缘‑云协同 AI | Huang et al., 2022 | 系统性分析边缘与云协同架构优点与挑战 |
| 知识蒸馏基础 | Hinton et al., 2015 | 提出模型蒸馏框架,为模型协同提供理论基础 |
| 多模态协同蒸馏 | Ramesh et al., 2023 | 探讨多模态知识蒸馏与边缘推理机制优化 |
| 协同推理策略 | Chen et al., 2023 | 提出不确定性估计与动态推理路径选择方法(示例性工作) |
大小模型云端协同是一种 云端大模型与边缘小模型互补合作的智能系统架构,可以在保证高精度、强泛化能力的同时显著提升响应速度、资源利用效率和数据隐私保护能力。其关键在于合理的任务分层设计、蒸馏策略、异步协同机制和动态路由策略。随着模型规模继续增长和边缘计算能力提升,这一架构将成为未来 AI 系统落地的重要趋势。
结语:展望未来
多模态大模型、混合专家架构以及大小模型协同架构构成了当前 AI 系统设计中的三个重要支柱。未来大模型的研究趋势将向以下几个方向发展:
-
更高效的跨模态对齐与融合机制 ;
-
更稳定可控的专家路由策略 ;
-
更加成熟的云端与边缘协同系统架构设计 ;
-
更强的实时推理能力与模型自适应能力 。
这些进展将推动智能系统在医疗、交通、机器人、智慧城市等行业的广泛应用。
参考资料
-
MoTE: Mixture of Ternary Experts for Memory-efficient Large Multimodal Models
https://arxiv.org/abs/2506.14435 arXiv -
EvoMoE: Expert Evolution in Mixture of Experts for Multimodal Large Language Models
https://arxiv.org/abs/2505.23830 arXiv -
Uni-MoE: Scaling Unified Multimodal LLMs with Mixture of Experts
https://arxiv.org/abs/2405.11273 arXiv -
Multimodal Large Language Models: A Survey (ResearchGate PDF)
https://www.researchgate.net/publication/392628889_Multimodal_Large_Language_Models_A_Survey ResearchGate -
Integrating large language models with cross-modal data fusion for ITS
https://www.sciencedirect.com/science/article/abs/pii/S1568494625005897 科学直接 -
LIMoE: Language Image Mixture of Experts (Google Research)
https://research.google/blog/limoe-learning-multiple-modalities-with-one-sparse-mixture-of-experts-model/ Google Research -
MoME: Mixture of Multimodal Experts for Generalist Multimodal LLMs
https://github.com/JiuTian-VL/MoME Bohrium -
MoE-World: Mixture-of-Experts Architecture for World Models (MDPI)
https://www.mdpi.com/2079-9292/14/24/4884 MDPI -
混合专家(MoE)架构综述(53AI)
https://www.53ai.com/news/LargeLanguageModel/2025070825467.html 53ai.com -
混合专家模型学习笔记(博客)
https://blog.cat.ke/2025/04/04/MoE%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0/ blog.cat.ke