1、Kafka消费者原理-Consumer
1.1 Offset的维护
1.1.1 Offset的存储
在partition中,消息是不会删除的,所以才可以追加写入,写入的消息连续有序的。这种特性决定了 kafka可以消费历史消息,而且按照消息的顺序消费指定消息,而不是只能消费队头的消息。正常情况下,我们希望消费没有被消费过的数据,而且是从最先发送(序号小的) 的开始消费(这样才是有序和公平的)。
那么对于一个partition,消费者组怎么才能做到接着上次消费的位置(offset)继续消费呢?肯定要把这个对应关系保存起来,下次消费的时候查找一下。
首先这个对应关系确实是可以查看的。比如消费者组gp-assign-group-1和 ass5part (5个分区)的partition的偏移量关系,可使用如下命令査看:
java
./kafka-consumer-groups.sh "bootstrap-server 192.168.44.161:9093,192.168.44.161:9094,192.168.44.161:9095 ---describe ---group gp-assign-group-1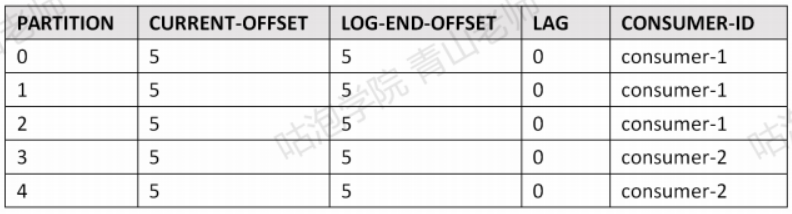
- CURRENT-OFFSET:下一个未使用的offset
- LEO(Log End Offset):下一条等待写入的消息的offset (最新的offset + 1)
- LAG是延迟量
注意:这不是表示一个消费者和一个Topic的关系,而是一个consumer group和topic中的一个partition的关系(offset在partition中连续编号而不是全局连续编号)。
这个对应关系存在哪里?因为所有的消费者都可以使用这个consumer group id,放在本地是做不到统一维护的,肯定要放到服务端。
Kafka早期的版本把消费者组和partition的offset直接维护在ZK中,但是读写的性能消耗太大了。后来就放在一个特殊的topic中,名字叫**_consumer_offsets,默认有 50 个分区**(offsets.topic.num.partitions 默认是 50),每个分区默认一个replication。
java
./kafka・topics・sh ---topic consumer_offsets ---describe ---zookeeper localhost:2181那么这样一个特殊的Topic怎么存储消费者组gp-assign-group-1对于分区的偏移量的?Topic里面是可以存放对象类型的value(经过序列化和反序列化)。这个Topic 里面主要存储两种对象:
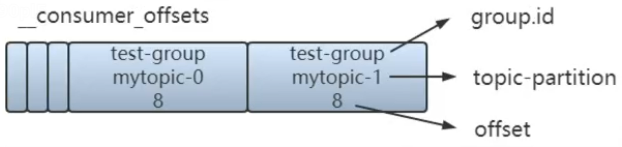
GroupMetadata :保存了消费者组中各个消费者的信息(每个消费者有编号)。
OffsetAndMetadata:保存了消费者组和各个partition的offset位移信息元数据。
java
./kafka-console-consumer.sh ---topic consumer_offsets --bootstrap-server 192.168.44.161:9093,192.168.44.161:9094,192.168.44.161:9095 -formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" ---from-beginning
__consumer_offsets大致的数据结构:
怎么知道一个consumer group的offset会放在这个特殊的Topic的哪个分区呢? 可以通过哈希取模计算得到:
java
Math.abs("gp-assign-group-1".hashCode()) % 50;1.1.2 如果找不到Offset
如果增加了一个新的消费者组去消费---个topic的某个partion,没有offset的记录,这个时候应该从哪里开始消费呢? 由以下参数控制:
java
auto.offset.reset=latest- latest: 从最新的消息(最后发送的)开始消费。
- earliest: 从最早的(最先发送的)消息开始消费。可以消费到历史消息。
- none: 如果consumer group在服务端找不到offset会报错。
1.1.3 Offset的更新
消费者组的offset是保存在Broker的,但是是由消费者上报给 Broker的。并不是消费者组消费了消息,Offset就会更新,消费者必须要有一个commit (提交)的动作。消费者可以自动提交或者手动提交。由以下参数控制:
java
enable.auto.commit=true还可以使用这个参数来控制自动提交的频率:
java
auto.commit.interval.ms=5000如果我们要在消费完消息做完业务逻辑处理之后才commit,就要把这个值改成 false。如果是false,消费者就必须要调用一个方法让Broker更新offset。有两种方式:
- consumer.commitSync()手动同步提交。
- consumer.commitAsync()手动异步提交。
如果不提交或者提交失败,Broker的Offset不会更新,消费者下次消费的时候会收到重复消息。
2.1 消费者和消费策略
2.1.1 分区分配策略
在同一个消费者组中,一个分区只能被一个消费者消费。所以当消费者数量大于分区数量时,多余的消费者是无法消费消息的。那么如果分区数大于消费者数呢,Kafka又是如何分配的?
为了保证系统最大的利用率,Kafka的分配策略一定会遵循一个最基本的原则------平均分配,简单理解,不会有任意两个消费者消费的分区数差大于1。在此基础上,Kafka有3种分区分配方式。以8个partition分配给3个consumer为例:
(1)Range(范围)
C1:P0 P1 P2
C2:P3 P4 P5
C3:P6 P7
(2)RoundRobin(轮询)
C1:P0 P3 P6
C2:P1 P4 P7
C3:P2 P5
(3)sticky(粘滞)
粘滞的分配策略较为复杂,它的核心思想是在分区重新分配时保证最小的移动(类似Redis的一致性hash思想,实现方式不同)。
第一次分配类似轮询,结果如下:
C1:P0 P3 P6
C2:P1 P4 P7
C3:P2 P5
假设此时C2挂掉:
若按照RoundRobin,结果如下:
C1:P0 P2 P4 P6
C3:P1 P3 P5 P7
sticky结果如下(尽量保证P0 P3 P6 P2 P5不动):
C1:P0 P3 P6 P1
C3:P2 P5 P4 P7
在分区分配时是会造成性能损耗的,若采用sticky分配策略可以尽可能减少性能损耗。该思想与Redis的一致性Hash是类似的,只是实现方式不同。
2.1.2 分区重分配Rebalance
什么时候会触发分区重分配Rebalance呢?有两种情况,一种是消费者数量发生变化,一种是分区数量发生变化。Rebalance过程如下:
- 确定协调者coordinator,通常由集群中负载最小的Broker承担。
- 所有consumer向coordinator发送join group请求,确认自己是该组成员。
- coordinator在所有consumer中确定leader(通常是第一个)并由leader确定分区分配结果。
- coordinator向所有consumer发送分区分配结果。