1.环境安装
conda create -y -n llamafactory_lab python=3.10
conda activate llamafactory_lab
git clone https://gh.llkk.cc/https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
git checkout v0.9.3
pip install -e ".[torch-npu,metrics]" -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install torch==2.6.0 torch-npu==2.6.0 torchvision
2.安装校验
使用以下指令对 LLaMA-Factory × 昇腾的安装进行校验:
llamafactory-cli env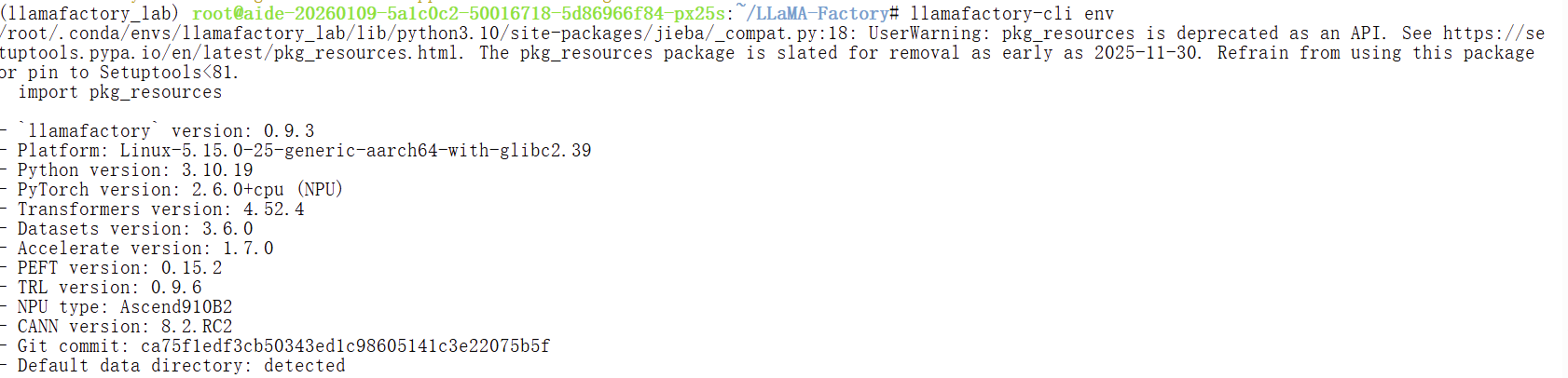
3.微调前的原模型效果呈现
安装依赖
pip install transformers==4.47.1
# 环境变量设置单卡GPU
export ASCEND_RT_VISIBLE_DEVICES=0
# 启动推理
llamafactory-cli chat --model_name_or_path /share/new_models/internlm3/internlm3-8b-instruct --trust_remote_code True输出结果:

4.微调书生模型
安装依赖
pip install transformers==4.47.1
pip install huggingface_hub==0.34.0
# 创建工作目录
mkdir /root/llamafactory_workdir
安装数据集
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download --repo-type dataset --resume-download llamafactory/alpaca_en --local-dir /root/dataset/alpaca_en
huggingface-cli download --repo-type dataset --resume-download llamafactory/alpaca_zh --local-dir /root/dataset/alpaca_zh
创建dataset_info.json文件
mkdir /root/llamafactory_workdir/data
cd /root/llamafactory_workdir/data
touch dataset_info.jsondataset_info.json文件
{
"alpaca_en":{
"file_name": "/root/dataset/alpaca_en/alpaca_data_en_52k.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
},
"alpaca_zh":{
"file_name": "/root/dataset/alpaca_zh/alpaca_data_zh_51k.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
}
}Yaml配置文件
cd /root/llamafactory_workdir
touch internlm3_lora_sft_ds.yaml
internlm3_lora_sft_ds.yaml文件内容
### model
model_name_or_path: /share/new_models/internlm3/internlm3-8b-instruct
trust_remote_code: True
### method
stage: sft
do_train: true
finetuning_type: lora
lora_target: q_proj,v_proj
### dataset
dataset: alpaca_en,alpaca_zh
template: intern2
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
### output
output_dir: saves/internlm3-8b-instruct/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 2
learning_rate: 0.0001
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
fp16: true
### eval
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500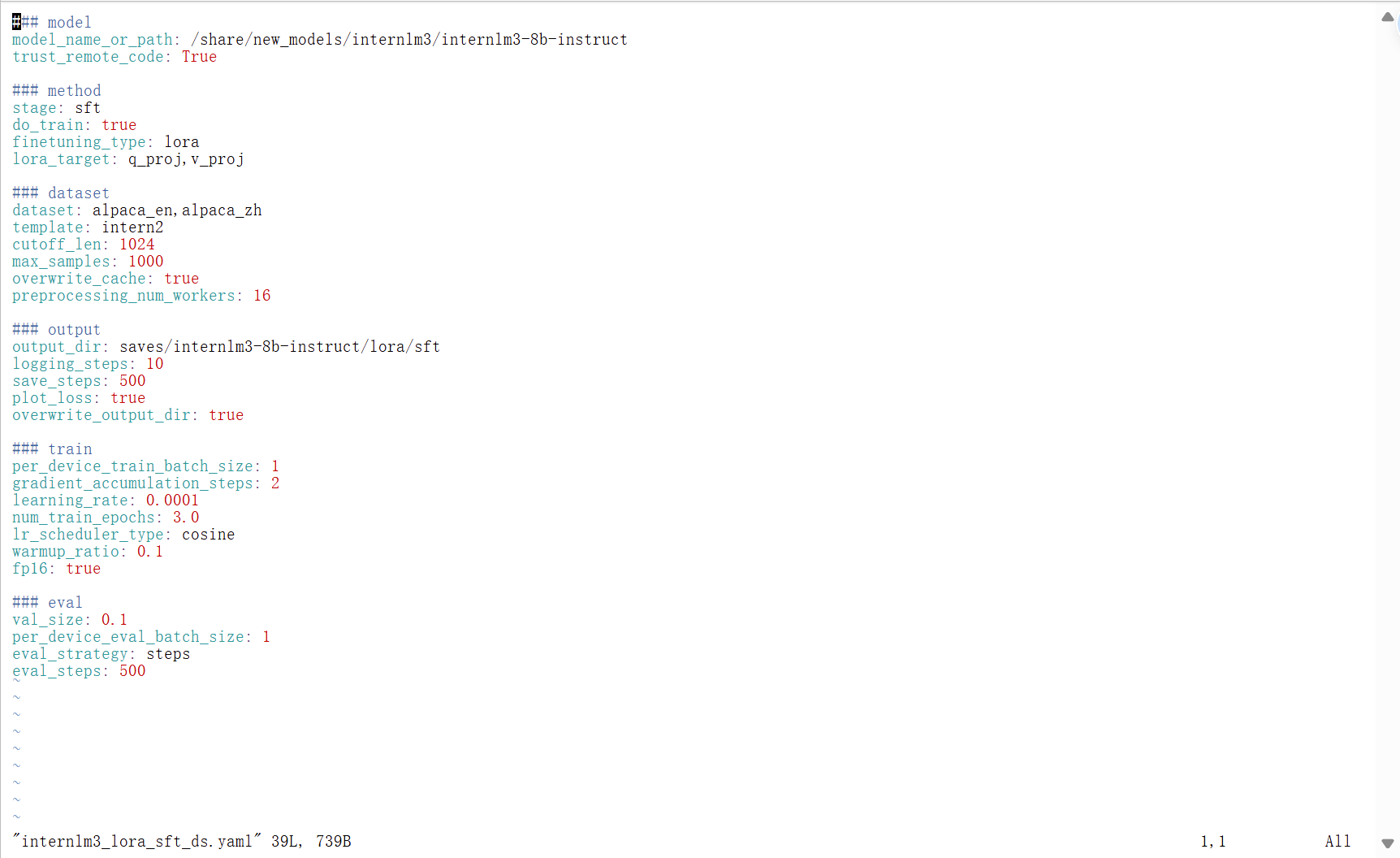
开启微调dong
torchrun --nproc_per_node 1 \
--nnodes 1 \
--node_rank 0 \
--master_addr 127.0.0.1 \
--master_port 7007 \
/root/LLaMA-Factory/src/train.py internlm3_lora_sft_ds.yaml
动态合并LoRA的微调
llamafactory-cli chat --model_name_or_path /share/new_models/internlm3/internlm3-8b-instruct \
--adapter_name_or_path saves/internlm3-8b-instruct/lora/sft \
--template intern \
--finetuning_type lora \
--trust_remote_code True
从推理结果看和源模型的输出有所区别了,那就说明微调完成了
微调完成之后可以将微调的权重和原始的模型合并导出
ASCEND_RT_VISIBLE_DEVICES=0
llamafactory-cli export \
--model_name_or_path /share/new_models/internlm3/internlm3-8b-instruct \
--adapter_name_or_path saves/internlm3-8b-instruct/lora/sft \
--template intern2 \
--finetuning_type lora \
--export_dir saves/internlm3-8b-instruct/lora/megred-model-path \
--export_device auto \
--export_legacy_format False \
--trust_remote_code True