智能体将语言模型与工具结合起来,创建能够推理任务、决定使用哪些工具并迭代寻找解决方案的系统。
create_agent 提供生产准备的代理实现。
LLM 代理会循环运行工具以实现目标。智能体运行直到满足停止条件------即模型输出最终输出或达到迭代极限。
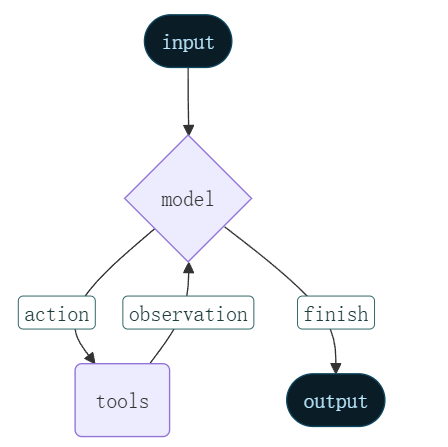
create_agent 利用 LangGraph 构建基于图的智能体运行时。图由节点(步骤)和边(连接)组成,定义了你的智能体如何处理信息。智能体在该图中移动,执行节点如模型节点(调用模型)、工具节点(执行工具)或中间件。
python
from langchain.agents import create_agent
create_agent(
model: str | BaseChatModel, # 使用的语言模型,可传模型名称(如 "qwen-max")或模型实例(如 ChatTongyi())
tools: Sequence[BaseTool | Callable | dict[str, Any]] | None = None, # 智能体可用的工具列表(函数、工具对象或字典)
*,
system_prompt: str | SystemMessage | None = None, # 固定的系统提示(角色设定),若使用 middleware 可不设
middleware: Sequence[AgentMiddleware[StateT_co, ContextT]] = (), # 中间件列表,用于动态修改提示、拦截请求等(如动态生成 system prompt)
response_format: ResponseFormat[ResponseT] | type[ResponseT] | None = None, # 指定期望的输出格式(如 Pydantic 模型)
state_schema: type[AgentState[ResponseT]] | None = None, # 定义智能体内部状态结构(通常可省略,自动推导)
context_schema: type[ContextT] | None = None, # 定义传入上下文的类型(如 TypedDict),用于类型检查和中间件使用
checkpointer: Checkpointer | None = None, # 用于保存/恢复对话状态(支持持久化多轮对话)
store: BaseStore | None = None, # 外部存储(如用于记忆、文档检索等)
interrupt_before: list[str] | None = None, # 在指定节点前暂停执行(用于人工审核)
interrupt_after: list[str] | None = None, # 在指定节点后暂停执行
debug: bool = False, # 是否开启调试模式(打印执行流程)
name: str | None = None, # 智能体名称(用于日志或图可视化)
cache: BaseCache | None = None, # 缓存机制(避免重复调用大模型)
) -> CompiledStateGraph[
AgentState[ResponseT], ContextT, _InputAgentState, _OutputAgentState[ResponseT]
] # 返回一个编译后的状态图(可用于 invoke、stream 等操作)| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
model |
`str | BaseChatModel` | --- |
tools |
`Sequence[BaseTool | Callable | dict] |
system_prompt |
`str | SystemMessage | None` |
middleware |
Sequence[AgentMiddleware] |
() |
中间件列表,用于在运行时动态修改提示、注入上下文等(如根据用户角色生成不同提示) |
response_format |
`ResponseFormat | type | None` |
state_schema |
`type[AgentState] | None` | None |
context_schema |
`type[ContextT] | None` | None |
checkpointer |
`Checkpointer | None` | None |
store |
`BaseStore | None` | None |
interrupt_before |
`list[str] | None` | None |
interrupt_after |
`list[str] | None` | None |
debug |
bool |
False |
是否启用调试模式(打印执行流程、中间状态等) |
name |
`str | None` | None |
cache |
`BaseCache | None` | None |
💡 提示 :在实际使用中,最常用的是 model、tools、middleware 和 context_schema。其他参数多用于高级场景(如持久化、审核、结构化输出等)。
目录
1.模型
1.1.静态模型
静态模型在创建代理时仅配置一次,执行过程中保持不变。这是最常见且最直接的方法。
python
from langchain.agents import create_agent
agent = create_agent("openai:gpt-5", tools=tools)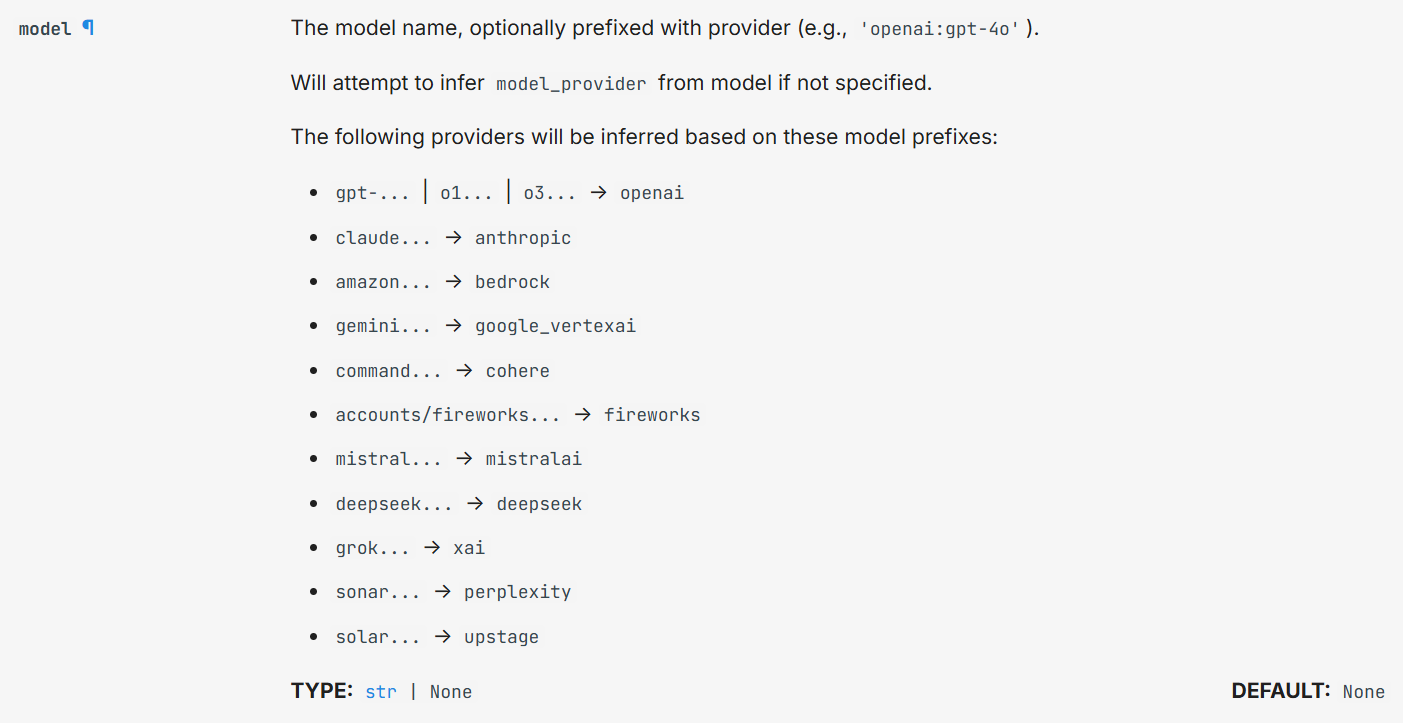
为了更好地控制模型配置,可以直接使用提供者包初始化模型实例。在这个例子中,我们使用 ChatOpenAI。参见聊天模型,了解其他可用的聊天模型类别。
python
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model="gpt-5",
temperature=0.1,
max_tokens=1000,
timeout=30
# ... (other params)
)
agent = create_agent(model, tools=tools)通义千问:
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
model |
str |
"qwen-max" |
指定使用的 Qwen 模型名称。可选值包括: • "qwen-turbo"(快速、便宜) • "qwen-plus"(平衡) • "qwen-max"(最强性能) • "qwen-max-latest"(最新版)等。 |
temperature |
float |
0.7 |
控制输出随机性。值越低越确定(0 表示完全 deterministic),越高越有创造性(通常 0.1~1.0)。 |
top_p |
`float | None` | None |
max_tokens |
`int | None` | None |
streaming |
bool |
False |
是否启用流式响应(用于逐字返回)。若设为 True,需配合 .stream() 方法使用。 |
api_key |
`str | None` | None |
model_kwargs |
`Dict[str, Any] | None` | None |
timeout |
`int | float | None` |
base_url |
`str | None` | None |
callbacks |
`List[CallbackHandler] | None` | None |
verbose |
bool |
False |
是否打印调试信息(已较少使用,建议用 debug=True 或 callbacks 替代)。 |
stop |
`List[str] | str | None` |
frequency_penalty |
`float | None` | None |
presence_penalty |
`float | None` | None |
python
from langchain.agents import create_agent
from langchain_community.chat_models import ChatTongyi
os.environ["DASHSCOPE_API_KEY"] = "sk-"
llm = ChatTongyi(
model="qwen-max",
temperature=0,
streaming=False,
)
agent = create_agent(
model=llm,
# tools=tools, # 工具列表(本例未使用)
# system_prompt=system_prompt, # 传入系统提示
)模型实例让你完全控制配置。当你需要设置具体参数,比如温度 、 温 max_tokens、超时、超时、 用到 base_url 以及其他提供者专属设置时,就用它们。请参阅参考文献,查看模型可用的参数和方法。
ChatTongyi - LangChain 文档 --- ChatTongyi - Docs by LangChain
1.2.动态模型
动态模型的选择在运行时间根据当前情况以及背景。这支持了复杂的路由逻辑和成本优化。
要使用动态模型,使用修改请求中模型的 @wrap_model_call 装饰器创建中间件:
python
from langchain_openai import ChatOpenAI
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
basic_model = ChatOpenAI(model="gpt-4o-mini")
advanced_model = ChatOpenAI(model="gpt-4o")
@wrap_model_call
def dynamic_model_selection(request: ModelRequest, handler) -> ModelResponse:
"""Choose model based on conversation complexity."""
message_count = len(request.state["messages"])
if message_count > 10:
# Use an advanced model for longer conversations
model = advanced_model
else:
model = basic_model
return handler(request.override(model=model))
agent = create_agent(
model=basic_model, # Default model
tools=tools,
middleware=[dynamic_model_selection]
)使用结构化输出时不支持预装模型(bind_tools 已调用的模型)。如果你需要动态选择模型并带结构化输出,确保传递给中间件的模型没有预绑。
2.工具
工具扩展了智能体功能------让他们能够实时获取数据、执行代码、查询外部数据库,并在世界中执行各种作。
@tool()的参数:
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
name |
str |
函数名 | 工具的唯一标识名称。LLM 在决定调用哪个工具时会使用此名称。例如 "web_search"。 |
description |
str |
从函数 docstring 自动生成 | 描述该工具的功能,帮助 LLM 判断何时调用它。建议写得清晰、具体,包含适用场景和输入格式。 |
args_schema |
Type[BaseModel] |
自动从函数签名推断 | 显式指定输入参数的 Pydantic 模型。当函数参数复杂、需字段描述或校验时非常有用。 |
return_direct |
bool |
False |
若设为 True,工具返回的结果将直接作为最终回答,不再交由 LLM 生成回复。适用于"查询即答案"类工具。 |
2.1.创建工具
制作工具最简单的方式是用 @tool 装饰师。默认情况下,函数的文档字符串成为工具的描述,帮助模型了解何时使用:
装饰器将使用函数的文档字符串作为工具的描述 - 因此必须提供文档字符串。
python
from langchain.tools import tool
@tool
def search_database(query: str, limit: int = 10) -> str:
"""
在客户数据库中搜索与查询条件匹配的记录。
该工具模拟一个数据库查询接口,可用于智能体(Agent)在需要查找客户信息时调用。
Args:
query (str): 要搜索的关键词或查询条件,例如客户姓名、邮箱或订单号。
limit (int, optional): 最多返回的结果数量。默认为 10 条。
"""
return f"找到 {limit} 条关于 '{query}' 的结果"类型提示是必需的,因为它们定义了工具的输入模式。文档字符串应具备信息性且简洁,帮助模型理解工具的目的。
也就是这里的注释信息
2.2.自定义工具属性
默认情况下,工具名称来源于函数名称。需要更具体描述时可以优先覆盖:
python
@tool("web_search") # Custom name
def search(query: str) -> str:
"""Search the web for information."""
return f"Results for: {query}"
print(search.name) # web_search自定义工具描述:
覆盖自动生成的工具描述以获得更清晰的模型指导:
python
@tool("calculator", description="Performs arithmetic calculations. Use this for any math problems.")
def calc(expression: str) -> str:
"""Evaluate mathematical expressions."""
return str(eval(expression))2.3.高级模式定义
用 Pydantic 模型或 JSON 模式定义复杂输入:
python
from pydantic import BaseModel, Field
from typing import Literal
from langchain.tools import tool
# 定义天气查询的输入数据结构(用于约束和描述工具参数)
class WeatherInput(BaseModel):
"""天气查询工具的输入参数模型。"""
location: str = Field(
description="城市名称或地理坐标(如 '北京' 或 '39.9042,116.4074')"
)
units: Literal["celsius", "fahrenheit"] = Field(
default="celsius",
description="温度单位偏好:'celsius'(摄氏度)或 'fahrenheit'(华氏度)"
)
include_forecast: bool = Field(
default=False,
description="是否包含未来5天的天气预报"
)
# 使用 @tool 装饰器将函数注册为 LangChain 工具,并绑定输入结构
@tool(args_schema=WeatherInput)
def get_weather(location: str, units: str = "celsius", include_forecast: bool = False) -> str:
"""
获取指定地点的当前天气信息,可选是否包含未来5天预报。
该工具模拟一个天气 API 接口,实际应用中应替换为真实服务(如 OpenWeatherMap、和风天气等)。
参数说明(由 WeatherInput 模型自动校验和描述):
location: 城市名或坐标(必填)
units: 温度单位,默认为 "celsius"
include_forecast: 是否返回5日预报,默认为 False
返回值:
str: 格式化的天气信息字符串
"""
# 模拟当前温度(根据单位选择不同数值)
temp = 22 if units == "celsius" else 72
# 构建当前天气描述
result = f"{location} 当前天气:{temp}°{units[0].upper()}"
# 若请求包含预报,则追加模拟数据
if include_forecast:
result += "\n未来5天:晴"
return result以下参数名称为保留,不能用作工具参数。使用这些名称会导致运行时错误。
|-----------|-----------------------------------|
| config | 保留用于内部传递 RunnableConfig 给工具 |
| runtime | 保留给 ToolRuntime 参数(访问状态、上下文、存储) |
2.4.访问上下文
为什么这很重要: 当工具能够访问代理状态、运行时上下文和长期记忆时,它们最为强大。这使得工具能够做出上下文感知的决策,个性化回应,并在对话中保持信息。
运行时上下文提供了一种方式,可以在运行时将依赖关系(如数据库连接、用户 ID 或配置)注入到工具中,使其更易测试和可复用。
🛠️ ToolRuntime 运行时信息表
| 属性 (Property) | 数据类型 | 说明 (Description) |
|---|---|---|
| State | 可变数据 | 在执行流程中流动的可变状态(例如:消息列表、计数器、自定义字段)3。 |
| Context | 不可变配置 | 静态的上下文配置,如用户 ID、会话详情或应用特定的依赖项12。 |
| Store | 持久化存储 | 用于跨对话保存的长期记忆(Long-term memory)13。 |
| Stream Writer | 流式输出 | 在工具执行过程中,用于流式传输自定义更新或进度的写入器1。 |
| Config | 运行配置 | 当前执行的 RunnableConfig,包含线程 ID 等运行时配置信息3。 |
| Tool Call ID | 字符串 | 当前工具调用的唯一标识 ID,用于追踪特定的调用请求23。 |
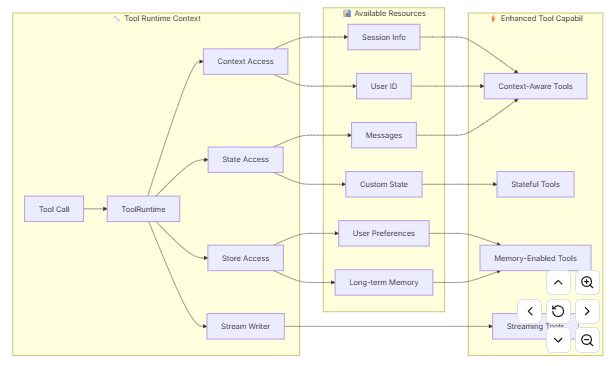
示例:1.访问状态工具:
工具可以通过 ToolRuntime 访问当前的图状态:
python
from langchain.tools import tool, ToolRuntime
# 工具 1:总结当前对话历史
@tool
def summarize_conversation(
runtime: ToolRuntime # ← 此参数由 LangChain 自动注入,大模型在调用时不会看到它
) -> str:
"""
总结截至目前的对话交互情况。
该工具通过 ToolRuntime 访问智能体内部的完整消息历史(state["messages"]),
并统计用户消息、AI 回复和工具调用结果的数量。
注意:`runtime` 参数是 LangChain 在运行时自动传入的,不会暴露给大模型,
因此大模型在决定是否调用此工具时,只会看到函数名和 docstring,而不知道需要传 runtime。
"""
# 获取当前对话中的所有消息
messages = runtime.state["messages"]
# 统计各类消息数量(通过类名判断)
human_msgs = sum(1 for m in messages if m.__class__.__name__ == "HumanMessage")
ai_msgs = sum(1 for m in messages if m.__class__.__name__ == "AIMessage")
tool_msgs = sum(1 for m in messages if m.__class__.__name__ == "ToolMessage")
return f"当前对话包含 {human_msgs} 条用户消息、{ai_msgs} 条 AI 回复和 {tool_msgs} 条工具调用结果。"
# 工具 2:获取用户的个性化偏好设置
@tool
def get_user_preference(
pref_name: str, # ← 此参数对大模型可见,会出现在工具描述中
runtime: ToolRuntime # ← 此参数对大模型不可见,仅由 LangChain 注入
) -> str:
"""
获取指定名称的用户偏好值。
例如,可查询 "language"、"theme" 或 "notification_enabled" 等偏好。
偏好数据存储在智能体的自定义状态字段 `user_preferences` 中。
参数:
pref_name (str): 要查询的偏好项名称(如 "timezone")
返回:
str: 偏好值;若未设置,则返回 "未设置"
"""
# 从智能体状态中读取用户偏好字典(默认为空字典)
preferences = runtime.state.get("user_preferences", {})
# 返回对应偏好值,若不存在则提示"未设置"
return preferences.get(pref_name, "未设置")示例:2.更新状态工具:
python
from langgraph.types import Command
from langchain.messages import RemoveMessage
from langgraph.graph.message import REMOVE_ALL_MESSAGES # 特殊标识符,表示删除所有消息
from langchain.tools import tool, ToolRuntime
# 工具 1:清空整个对话历史
@tool
def clear_conversation() -> Command:
"""
清空当前对话的所有历史消息。
该工具不接受任何用户可见参数(对大模型来说是无参函数)。
调用后,会返回一个 Command 指令,指示 LangGraph 将状态中的 "messages" 字段
替换为一个特殊的删除指令,从而在下一轮状态更新时移除全部消息。
返回值:
Command: 包含状态更新指令的对象,用于触发 LangGraph 内部的状态变更。
"""
return Command(
update={
# 使用 RemoveMessage(id=REMOVE_ALL_MESSAGES) 告诉系统清空所有消息
"messages": [RemoveMessage(id=REMOVE_ALL_MESSAGES)],
}
)
# 工具 2:更新用户姓名(写入智能体状态)
@tool
def update_user_name(
new_name: str, # ← 此参数对大模型可见,会出现在工具描述中
runtime: ToolRuntime # ← 此参数由 LangChain 自动注入,对大模型不可见
) -> Command:
"""
更新智能体状态中记录的用户姓名。
该工具允许用户通过自然语言(如"我叫李明")触发姓名更新。
新姓名将被写入智能体的全局状态字段 "user_name",后续对话可引用。
参数:
new_name (str): 用户希望设置的新姓名
返回值:
Command: 指示将 {"user_name": new_name} 合并到当前状态中。
"""
return Command(
update={
"user_name": new_name # 直接更新状态中的 user_name 字段
}
)示例:3.定义上下文工具
python
# 模拟用户数据库
USER_DATABASE = {
"user123": {
"name": "Alice Johnson",
"account_type": "Premium",
"balance": 5000,
"email": "alice@example.com"
},
"user456": {
"name": "Bob Smith",
"account_type": "Standard",
"balance": 1200,
"email": "bob@example.com"
}
}
# 定义用户上下文(用于传递 user_id)
@dataclass
class UserContext:
user_id: str
# 定义工具:获取当前用户的账户信息
@tool
def get_account_info(runtime: ToolRuntime[UserContext]) -> str:
"""获取当前用户的账户信息(包括姓名、类型和余额)。"""
print("调用工具:get_account_info")
user_id = runtime.context.user_id
if user_id in USER_DATABASE:
user = USER_DATABASE[user_id]
return (
f"账户持有人:{user['name']}\n"
f"账户类型:{user['account_type']}\n"
f"当前余额:${user['balance']}"
)
return "未找到该用户"
# 初始化 Qwen 模型
llm = ChatTongyi(
model="qwen-max",
temperature=0,
streaming=False,
)
# 创建智能体
agent = create_agent(
model=llm,
tools=[get_account_info],
context_schema=UserContext, # 关联上下文类型
# debug=True,
system_prompt="你是一名专业的金融助理,能够安全地查询用户的账户信息。请根据需要调用工具获取数据。"
)
# 调用智能体:传入用户问题 + 用户上下文
result = agent.invoke(
{"messages": [HumanMessage(content="我的当前余额是多少?")]},
context=UserContext(user_id="user123")
)
# 输出结果
print("--- 助手回复 ---")
print(result["messages"][-1].content)
示例:4.Memory (Store) 存储器
通过存储访问跨对话的持久数据。存储通过 runtime.store 访问,允许你保存和检索用户特定或应用特定数据。
工具可以通过 ToolRuntime 访问和更新存储:
python
from typing import Any
from langgraph.store.memory import InMemoryStore
from langchain.agents import create_agent
from langchain.tools import tool, ToolRuntime
# 工具函数:根据用户ID查询用户信息
@tool
def get_user_info(user_id: str, runtime: ToolRuntime) -> str:
"""查询指定用户的详细信息"""
store = runtime.store
user_info = store.get(("users",), user_id)
return str(user_info.value) if user_info else "Unknown user"
# 工具函数:保存用户信息到内存存储
@tool
def save_user_info(user_id: str, user_info: dict[str, Any], runtime: ToolRuntime) -> str:
"""将用户信息持久化到内存存储中"""
store = runtime.store
store.put(("users",), user_id, user_info)
return "Successfully saved user info."
# 创建内存存储,用于在智能体调用之间共享状态
store = InMemoryStore()
# 创建智能体(需确保 model 已定义)
agent = create_agent(
model=llm,
tools=[get_user_info, save_user_info],
store=store
)
# 第一次调用:使用中文提示词保存用户信息
agent.invoke({
"messages": [{"role": "user", "content": "请保存以下用户信息:用户ID为 abc123,姓名是 Foo,年龄 25 岁,邮箱是 foo@langchain.dev"}]
})
print("--- 用户信息查询结果 ---")
result = agent.invoke({
"messages": [{"role": "user", "content": "请查询 ID 为 'abc123' 的用户信息"}]
})
print(result["messages"][-1].content)
# 预期智能体会调用 save_user_info 和 get_user_info 工具,
# 并最终返回类似如下的结果(由模型生成):
# 以下是用户 ID "abc123" 的信息:
# - 姓名:Foo
# - 年龄:25
# - 邮箱:foo@langchain.dev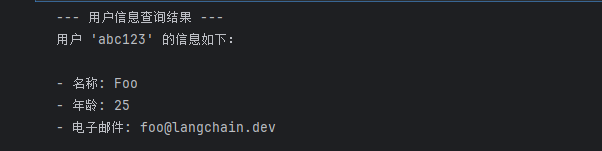
示例:5.Stream writer 流式输出
在工具执行时实时流式传输自定义更新 runtime.stream_writer。这有助于向用户实时反馈工具的工作表现。
哦,这其实就是智能体调用工具的过程打印,可以使用print实现
python
from langchain.tools import tool, ToolRuntime
@tool
def get_weather(city: str, runtime: ToolRuntime) -> str:
"""获取指定城市的天气信息"""
# 获取流式输出写入器,用于在工具执行过程中发送中间更新
writer = runtime.stream_writer
# 在执行过程中流式输出中文提示信息
writer(f"正在查询城市 {city} 的天气数据......")
writer(f"已获取城市 {city} 的天气数据")
# 返回最终结果(也可根据实际需求调用真实天气 API)
return f"{city} 的天气总是阳光明媚!"2.5.StructuredTool
StructuredTool.from_function 类方法提供了比 @tool 装饰器更多的可配置性,而无需太多额外的代码。
python
from langchain_core.tools import StructuredTool
import asyncio
# 同步版本的乘法函数:供同步调用使用
def multiply(a: int, b: int) -> int:
"""将两个整数相乘(同步函数)"""
return a * b
# 异步版本的乘法函数:供异步调用使用
async def amultiply(a: int, b: int) -> int:
"""将两个整数相乘(异步函数)"""
return a * b
# 使用 StructuredTool 封装工具,同时支持同步和异步调用
# - func: 指定同步实现
# - coroutine: 指定异步实现
calculator = StructuredTool.from_function(func=multiply, coroutine=amultiply)
# 同步调用示例:直接执行,无需 await
print(calculator.invoke({"a": 2, "b": 3}))
# 异步调用示例:必须在支持顶层 await 的环境(如 Jupyter/Colab)中运行
result = await calculator.ainvoke({"a": 2, "b": 5}) # 注意:只能在 async cell 中使用 await
print(result)- 同步 :一件事做完,再做下一件(顺序执行,会等待)。
- 异步 :发起一件事后,不用等它完成 ,先去做别的事,等它好了再处理结果(非阻塞、可并发)。
2.6.处理工具错误
如果您正在使用带有智能体的工具,您可能需要一个错误处理策略,以便智能体可以从错误中恢复并继续执行。
一个简单的策略是在工具内部抛出 ToolException ,并使用handle_tool_error指定一个错误处理程序。 当指定了错误处理程序时,异常将被捕获,错误处理程序将决定从工具返回哪个输出。 您可以将 handle_tool_error 设置为 True、字符串值或函数。如果是函数,该函数应该以 ToolException 作为参数,并返回一个值。 请注意,仅仅抛出 ToolException 是不会生效的。您需要首先设置工具的 handle_tool_error,因为其默认值是 False。
python
from langchain_core.tools import StructuredTool, ToolException
# 定义一个可能出错的工具函数
def get_weather(city: str) -> str:
"""获取指定城市的天气信息"""
# 模拟一个错误场景:城市不存在
if city.lower() not in ["北京", "上海", "广州", "深圳"]:
# 抛出 ToolException,这是 LangChain 专门用于工具错误的异常
raise ToolException(f"错误:没有名为 '{city}' 的城市。请尝试 北京、上海、广州 或 深圳。")
# 正常情况返回天气
return f"{city} 今天晴,气温 25°C。"
# 使用 StructuredTool 封装工具,并启用错误处理
# handle_tool_error=True 表示:
# - 如果工具抛出 ToolException,
# - 不会中断整个 Agent 流程,
# - 而是将异常信息作为字符串返回给 LLM 或用户
get_weather_tool = StructuredTool.from_function(
func=get_weather,
handle_tool_error=True, # 关键:启用错误捕获
# handle_tool_error="没找到.gyp" # 我们可以将 handle_tool_error 设置为一个始终返回的字符串。
)
# 测试:调用一个不存在的城市
result = get_weather_tool.invoke({"city": "foobar"})
print("工具返回结果:")
print(result)
# handle_tool_error=True 表示: # - 如果工具抛出 ToolException, # - 不会中断整个 Agent 流程, # - 而是将异常信息作为字符串返回给 LLM 或用户
使用函数处理错误:
python
# 示例:tools_exception_handle_error.py
def _handle_error(error: ToolException) -> str:
return f"工具执行期间发生以下错误:`{error.args[0]}`"
get_weather_tool = StructuredTool.from_function(
func=get_weather,
handle_tool_error=_handle_error,
)
get_weather_tool.invoke({"city": "foobar"})
工具是智能体、链或聊天模型/LLM 用来与世界交互的接口。 一个工具由以下组件组成:
- 工具的名称
- 工具的功能描述
- 工具输入的 JSON 模式
- 要调用的函数
- 工具的结果是否应直接返回给用户(仅对代理相关) 名称、描述和 JSON 模式作为上下文提供给 LLM,允许 LLM 适当地确定如何使用工具。 给定一组可用工具和提示,LLM 可以请求调用一个或多个工具,并提供适当的参数。 通常,在设计供聊天模型或 LLM 使用的工具时,重要的是要牢记以下几点:
- 经过微调以进行工具调用的聊天模型将比未经微调的模型更擅长进行工具调用。
- 未经微调的模型可能根本无法使用工具,特别是如果工具复杂或需要多次调用工具。
- 如果工具具有精心选择的名称、描述和 JSON 模式,则模型的性能将更好。
- 简单的工具通常比更复杂的工具更容易让模型使用。
这里官网提供多种工具调用接口:LangChain overview - Docs by LangChain

2.7.工具包
工具包是一组旨在一起使用以执行特定任务的工具。它们具有便捷的加载方法。
要获取可用的现成工具包完整列表,请访问集成。
所有工具包都公开了一个 get_tools 方法,该方法返回一个工具列表。
通常您应该这样使用它们:
python
# 初始化一个工具包
toolkit = ExampleTookit(...)
# 获取工具列表
tools = toolkit.get_tools()例如,使用SQLDatabase toolkit 读取 langchain.db 数据库表结构:
python
from langchain_community.agent_toolkits.sql.toolkit import SQLDatabaseToolkit
from langchain_community.utilities import SQLDatabase
from langchain_openai import ChatOpenAI
from langchain_community.agent_toolkits.sql.base import create_sql_agent
# from langchain.agents.agent_types import AgentType
db = SQLDatabase.from_uri("sqlite:///langchain.db")
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
print(toolkit.get_tools())[QuerySQLDatabaseTool(description="Input to this tool is a detailed and correct SQL query, output is a result from the database. If the query is not correct, an error message will be returned. If an error is returned, rewrite the query, check the query, and try again. If you encounter an issue with Unknown column 'xxxx' in 'field list', use sql_db_schema to query the correct table fields.", db=<langchain_community.utilities.sql_database.SQLDatabase object at 0x000001B97745AEF0>),
InfoSQLDatabaseTool(description='Input to this tool is a comma-separated list of tables, output is the schema and sample rows for those tables. Be sure that the tables actually exist by calling sql_db_list_tables first! Example Input: table1, table2, table3', db=<langchain_community.utilities.sql_database.SQLDatabase object at 0x000001B97745AEF0>),
**ListSQLDatabaseTool(**db=<langchain_community.utilities.sql_database.SQLDatabase object at 0x000001B97745AEF0>),
QuerySQLCheckerTool(description='Use this tool to double check if your query is correct before executing it. Always use this tool before executing a query with sql_db_query!', db=<langchain_community.utilities.sql_database.SQLDatabase object at 0x000001B97745AEF0>,
llm=ChatTongyi(client=<class 'dashscope.aigc.generation.Generation'>, model_name='qwen-max', model_kwargs={}, dashscope_api_key=SecretStr('**********')), llm_chain=LLMChain(verbose=False, prompt=PromptTemplate(input_variables='dialect', 'query', input_types={}, partial_variables={}, template='\n{query}\nDouble check the {dialect} query above for common mistakes, including:\n- Using NOT IN with NULL values\n- Using UNION when UNION ALL should have been used\n- Using BETWEEN for exclusive ranges\n- Data type mismatch in predicates\n- Properly quoting identifiers\n- Using the correct number of arguments for functions\n- Casting to the correct data type\n- Using the proper columns for joins\n\nIf there are any of the above mistakes, rewrite the query. If there are no mistakes, just reproduce the original query.\n\nOutput the final SQL query only.\n\nSQL Query: '), llm=ChatTongyi(client=<class 'dashscope.aigc.generation.Generation'>, model_name='qwen-max', model_kwargs={}, dashscope_api_key=SecretStr('**********')), output_parser=StrOutputParser(), llm_kwargs={}))]
3.示例
3.1.集成工具调用
在使用第三方工具时,请确保您了解工具的工作原理、权限情况。请阅读其文档,并检查是否需要从安全角度考虑任何事项。请查看安全指南获取更多信息。
让我们尝试一下维基百科集成。
python
!pip install -qU wikipedia
python
# 导入 LangChain 提供的维基百科查询工具和 API 封装器
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
import os
os.environ["HTTP_PROXY"] = "http://127.0.0.1:10808"
os.environ["HTTPS_PROXY"] = "http://127.0.0.1:10808"
# 配置维基百科 API 的行为:
# - top_k_results=1:只返回最相关的 1 个页面
# - doc_content_chars_max=100:每个页面最多截取前 100 个字符的内容
api_wrapper = WikipediaAPIWrapper(top_k_results=1, doc_content_chars_max=100)
# 创建维基百科查询工具实例
tool = WikipediaQueryRun(api_wrapper=api_wrapper)
# 调用工具进行查询(使用 invoke 方法,传入字典格式参数)
# 注意:WikipediaQueryRun 的输入字段名为 "query"
print(tool.invoke({"query": "langchain"}))
# 打印工具的元信息,便于调试或集成到 Agent 中
print(f"Name: {tool.name}") # 工具名称(LLM 调用时使用的标识)
print(f"Description: {tool.description}") # 工具描述(帮助 LLM 理解用途)
print(f"args schema: {tool.args}") # 输入参数结构(旧版属性,实际推荐看 tool.args_schema)
print(f"returns directly?: {tool.return_direct}") # 是否直接返回结果(不经过 LLM 后处理)
3.2.自定义工具调用
我们还可以修改内置工具的名称、描述和参数的 JSON 模式。
在定义参数的 JSON 模式时,重要的是输入保持与函数相同,因此您不应更改它。但您可以轻松为每个输入定义自定义描述。
python
#示例:tools_custom.py
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
from pydantic import BaseModel, Field
class WikiInputs(BaseModel):
"""维基百科工具的输入。"""
query: str = Field(
description="query to look up in Wikipedia, should be 3 or less words"
)
tool = WikipediaQueryRun(
name="wiki-tool",
description="look up things in wikipedia",
args_schema=WikiInputs,
api_wrapper=api_wrapper,
return_direct=True,
)
print(tool.run("langchain"))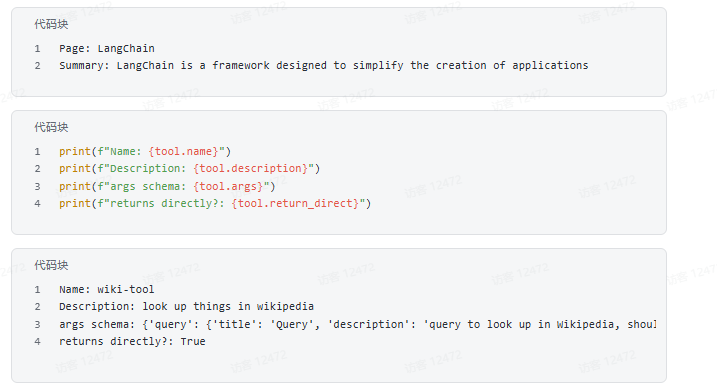
python
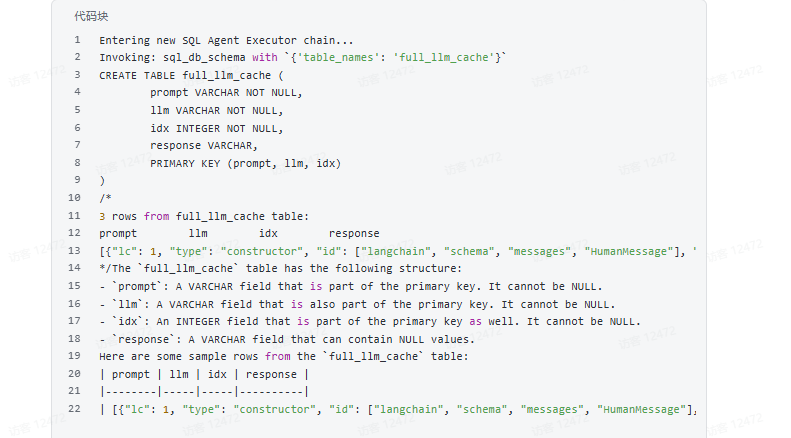
agent_executor = create_sql_agent(
llm=llm,
toolkit=toolkit,
verbose=True,
)
# %%
agent_executor.invoke("Describe the full_llm_cache table")