AAAI 是人工智能领域顶级的国际学术会议,本文精选了美团技术团队被收录的8篇学术论文(附下载链接),覆盖大模型推理、 退火策略、过程奖励模型、强化学习、视觉文本渲染等多个技术领域,希望这些论文能对大家有所帮助或启发。
01 Promoting Efficient Reasoning with Verifiable Stepwise Reward
论文类型:Poster
论文下载 :PDF
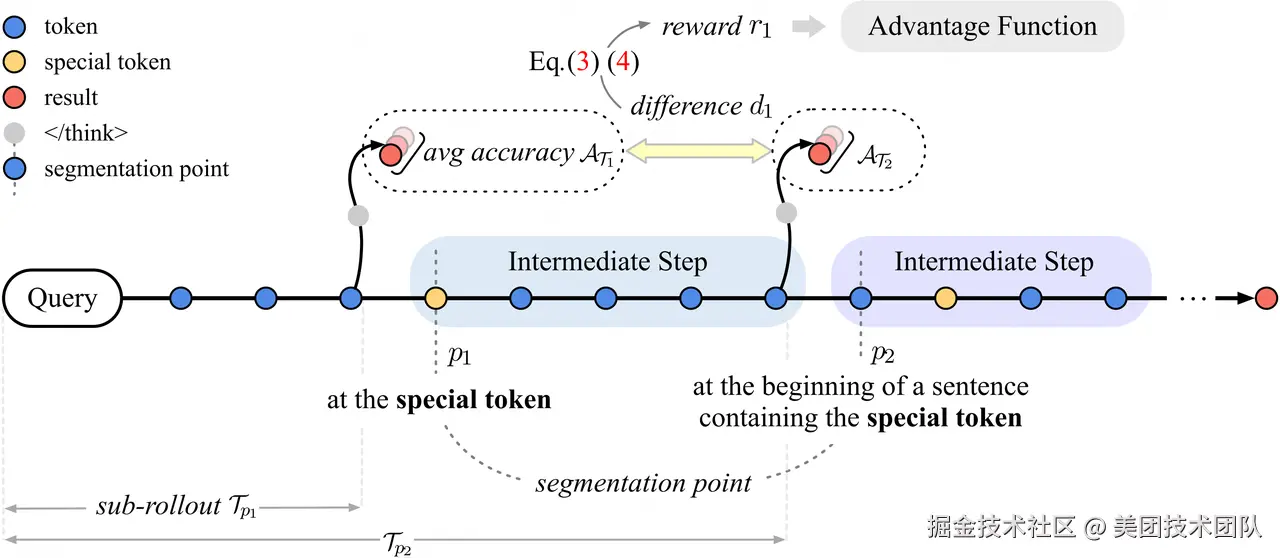
论文简介:大推理模型通过强化学习提升了链式推理能力,但输出冗长,导致推理开销增大和用户体验下降,即「过度思考」问题。针对这一现象,本文提出了可验证的过程奖励机制(VSRM),通过奖励有效步骤、惩戒无效步骤,优化模型推理过程。VSRM首先通过特殊token划分推理步骤,并结合三条规则保证每个步骤的内容可读性。各步骤通过插入token生成子轨迹,模型根据每步前后正确率变化分配步骤级奖励。为避免奖励信号稀疏,引入前瞻窗口机制,通过折扣因子传播未来正确率变化,使奖励更密集。
实验表明,VSRM能大幅缩减输出长度,且在多种数学benchmark和不同模型、算法下保持甚至提升性能。消融实验证明前瞻窗口机制有效,显式长度惩罚对VSRM无益。VSRM机制可与各类强化学习算法无缝结合,有效抑制无效步骤,鼓励有效推理,是解决过度思考问题、提升模型推理效率的有效方法。
02 Scaling and Transferability of Annealing Strategies in Large Language Model Training
论文类型:Long Paper
论文下载 :PDF
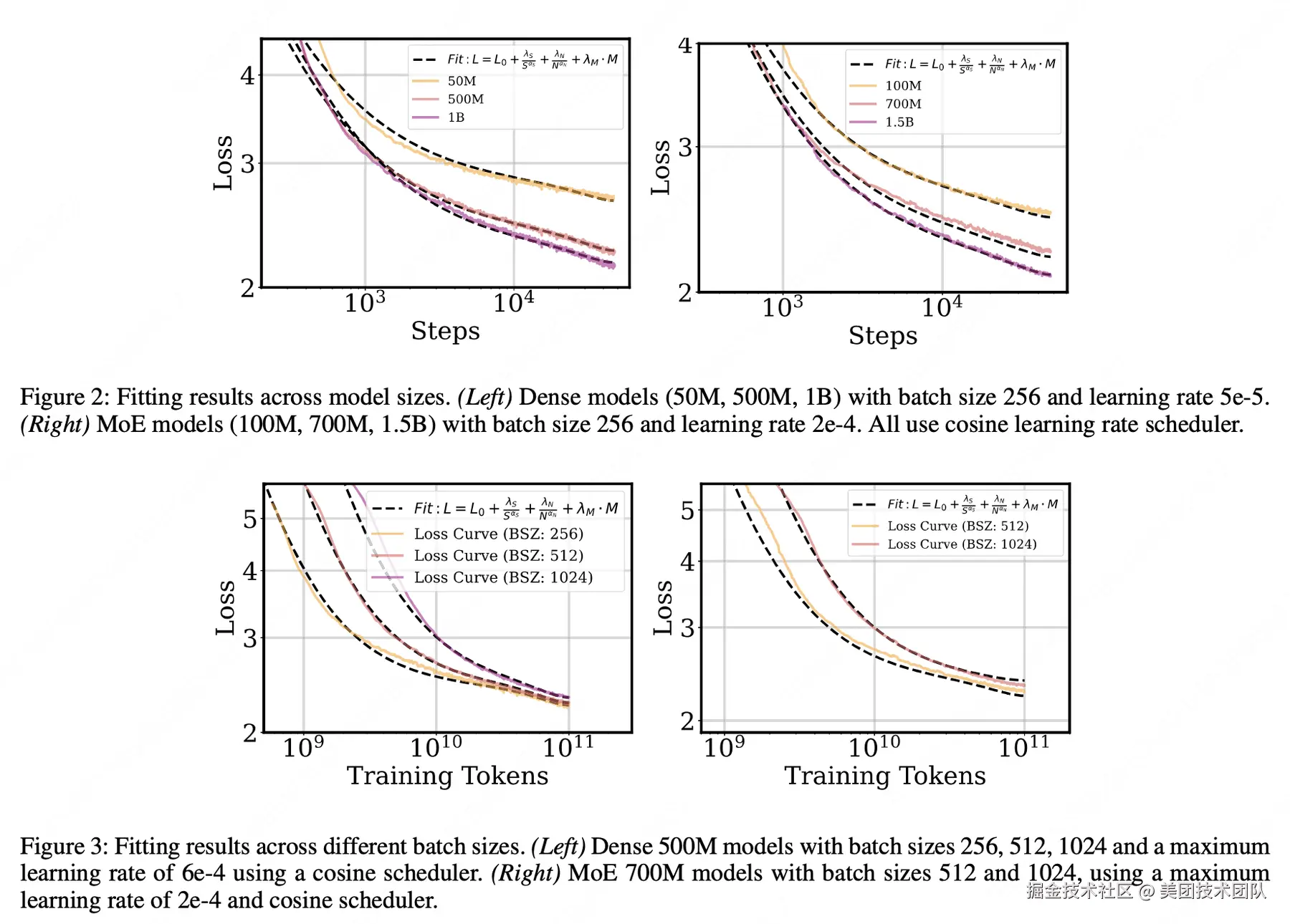
论文简介:本文深入研究了大型语言模型训练过程中退火策略(Annealing Strategies)对模型性能的影响,提出了一个新的缩放法则公式来预测不同训练配置下的损失曲线。研究发现,即使在相同的训练token数量和模型规模下,不同的批次大小(batch size)和学习率调度器也会导致显著不同的训练曲线。为此,作者提出了一个改进的缩放法则公式:
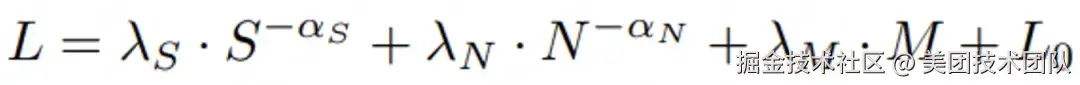
其中S表示学习率对训练步数的积分(前向效应),M表示动量对训练步数的积分(退火动量项),N代表模型规模。
论文的核心贡献包括:(1) 证明在特定情况下,训练步数比训练token数更适合作为追踪损失曲线的指标;(2) 发现最优退火比率(Ropt)随总训练步数增加而减小,遵循幂律关系;(3) 验证了最优退火比率在训练集和验证集上保持一致;(4) 通过在Dense模型和MoE(Mixture-of-Experts)模型上的大量实验,证明小模型可以作为优化大模型训练动态的可靠代理。该研究为大规模语言模型的训练提供了更精确的理论指导,有助于优化训练效率和模型性能。
03 From Mathematical Reasoning to Code: Generalization of Process Reward Models in Test-Time Scaling
论文类型:Long Paper (Oral)
论文下载 :PDF
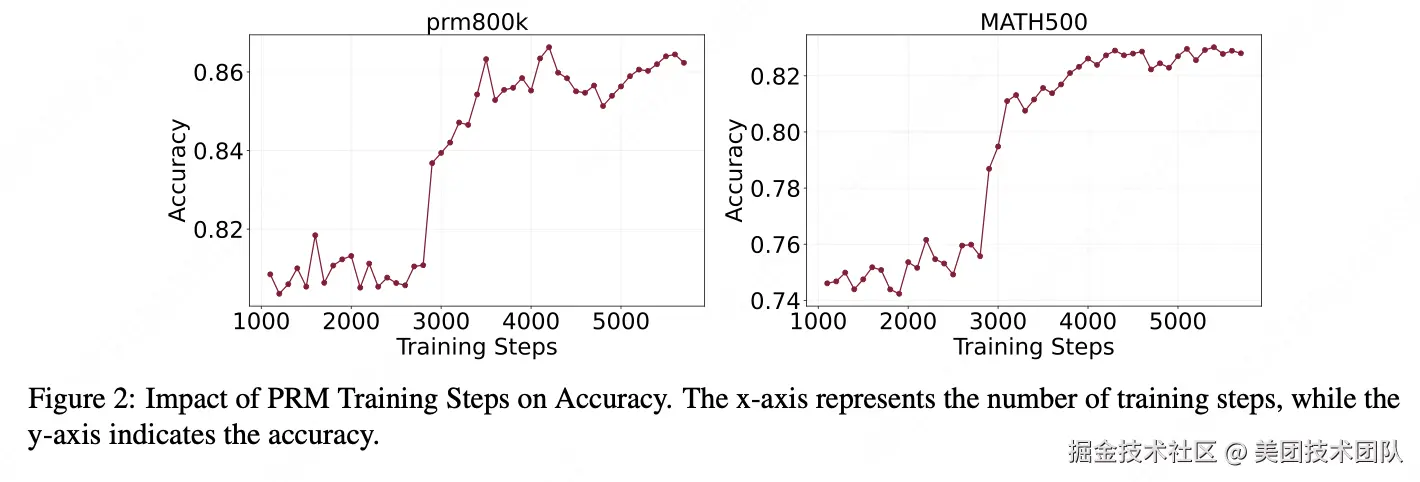
论文简介:本文系统研究了过程奖励模型(Process Reward Models, PRMs)在提升大型语言模型推理能力方面的作用,特别关注其从数学推理到代码生成任务的跨域泛化能力。研究从训练方法、可扩展性和泛化能力等多个维度对PRMs进行了深入分析。
论文的核心发现包括:
- 训练计算资源的影响:研究发现随着PRM模型规模的增大,性能提升呈现边际递减效应,强调了在模型规模和计算成本之间寻找平衡的重要性。同时,训练数据集的多样性显著影响PRM性能,作者提出的ASLAF(自动步骤级标注与过滤)方法在多个基准测试中表现优异。
- 测试时扩展策略:论文评估了Best-of-N采样、束搜索、蒙特卡洛树搜索(MCTS)和多数投票等多种搜索策略。结果表明,在计算资源充足时MCTS效果最佳,而在资源受限情况下Best-of-N采样是实用的替代方案。
- 跨域泛化能力:令人惊讶的是,在数学数据集上训练的PRMs在代码生成任务上的表现与专门针对代码训练的模型相当,展现出强大的跨域适应能力。通过梯度分析,研究还发现PRMs倾向于选择具有相似底层推理模式的响应,这为理解其优化机制提供了新视角。该研究为优化大规模语言模型的训练和部署提供了重要的理论指导和实践参考。
04 Rethinking the Sampling Criteria in Reinforcement Learning for LLM Reasoning: A Competence-Difficulty Alignment Perspective
论文类型:Poster
论文下载 :PDF
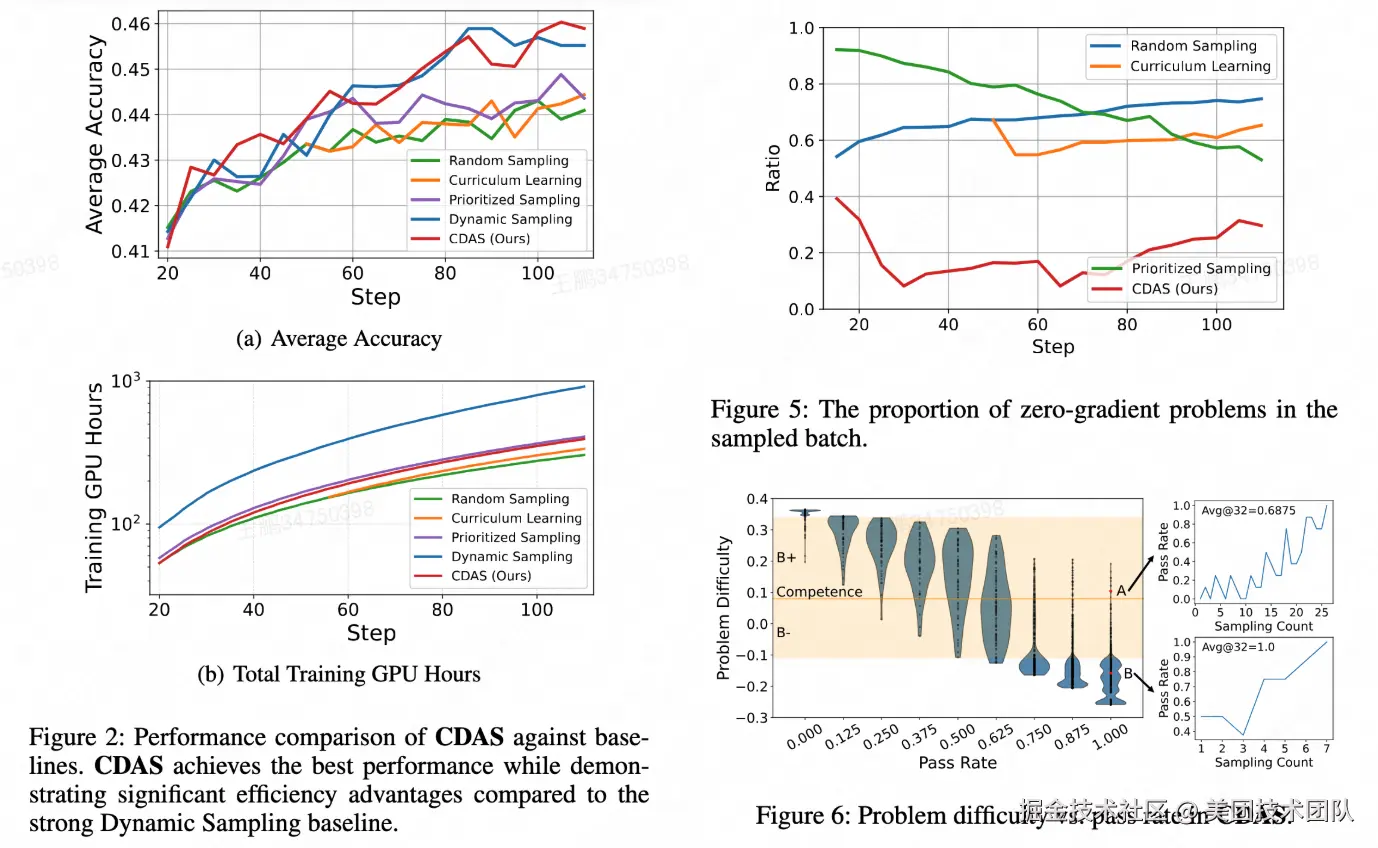
论文简介:本文对强化学习(RL)中的问题采样策略进行了系统性研究,当前主流采样策略大多直接依赖单步通过率(Pass Rate) 作为问题难度指标,存在 1)对问题难度的估计不够稳定;2)无法有效捕捉模型能力与问题难度的对齐关系的问题。
针对这些问题,本文提出了 CDAS(Competence-Difficulty Alignment Sampling):一种将模型能力与问题难度显式建模并对齐的动态采样方法。CDAS 不依赖单步通过率,而是通过累积历史表现差异来构建更稳定的难度估计;同时定义模型能力,并以不动点系统确保两者在训练过程中共同收敛。基于能力---难度差值构建对齐指标,再通过对称采样策略,选取最匹配模型当前能力的问题,从而提升有效梯度比例与训练效率。CDAS 在数学推理和代码生成场景中均通过 RL 训练 验证,结果显示 CDAS 显著提升了采样效率与模型性能,击败了多种主流采样策略。
05 ViType: High-Fidelity Visual Text Rendering via Glyph-Aware Multimodal Diffusion
论文类型:Oral
论文下载 :PDF
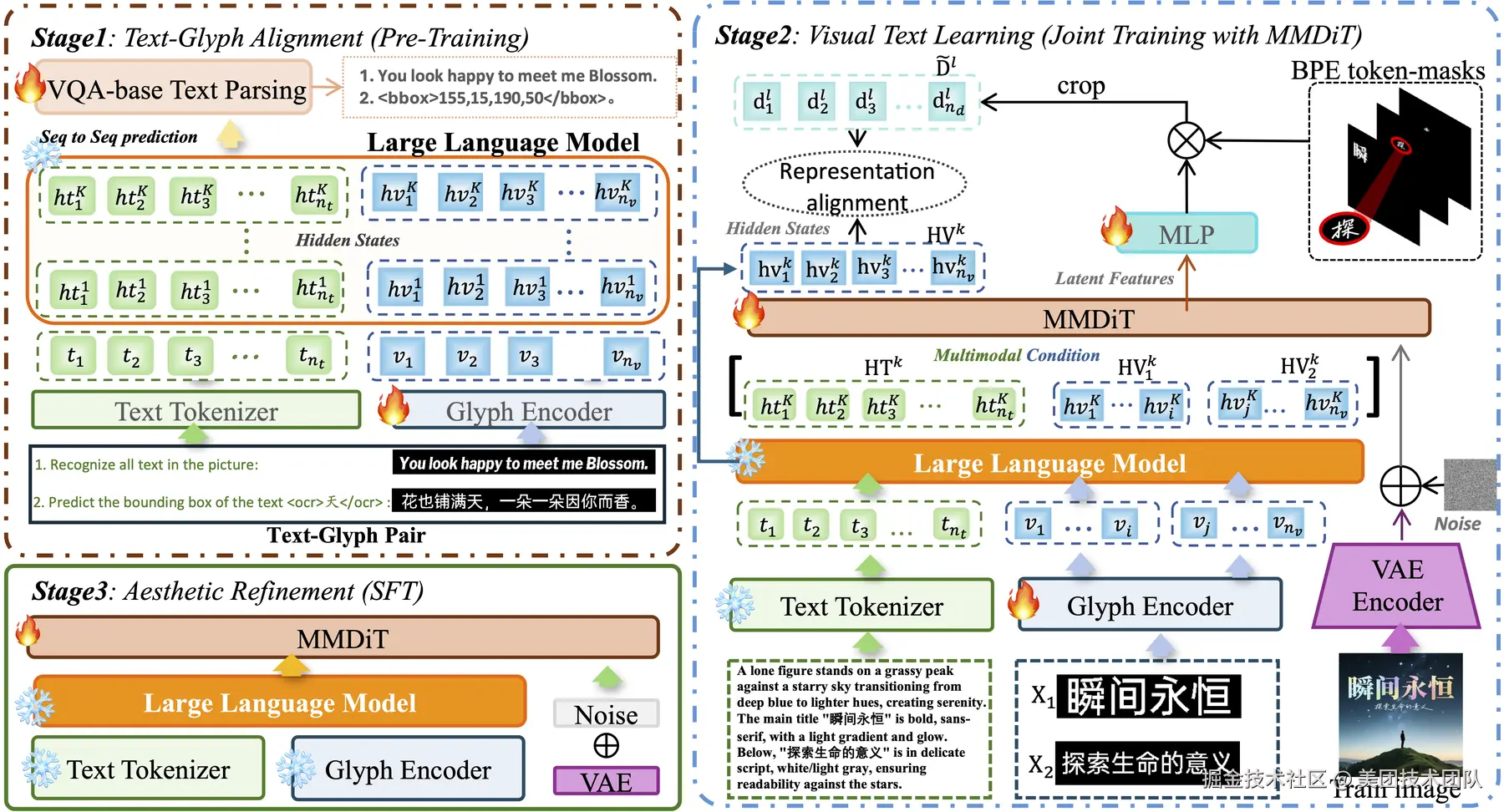
论文简介:随着文生图模型在电商营销等领域的广泛应用,视觉文本渲染的准确性已成为制约生成质量的核心瓶颈。现有模型因缺乏字形级理解能力,难以精确刻画多语言字符结构,导致海报、商品图等商业场景中文字乱码、字形失真等问题频发,严重阻碍了AIGC在智能设计中的实际落地。
针对这一关键挑战,我们提出ViType三阶段对齐增强框架:首先通过视觉问答机制实现文本-字形显式对齐,将字符视觉结构注入大语言模型语义空间;其次创新性地将预对齐字形嵌入与文本token同步输入多模态扩散Transformer,通过联合训练建立跨模态特征协同;最后基于高质量图文对进行美学精调,确保生成图像的版式和谐与视觉美感。该框架使字符准确率提升15%以上,为电商海报、营销物料等高精度视觉内容创作提供了可靠的技术支撑。
06 DSCF: Dual-Source Counterfactual Fusion for High-Dimensional Combinatorial Interventions
论文类型:Poster
论文下载 :PDF
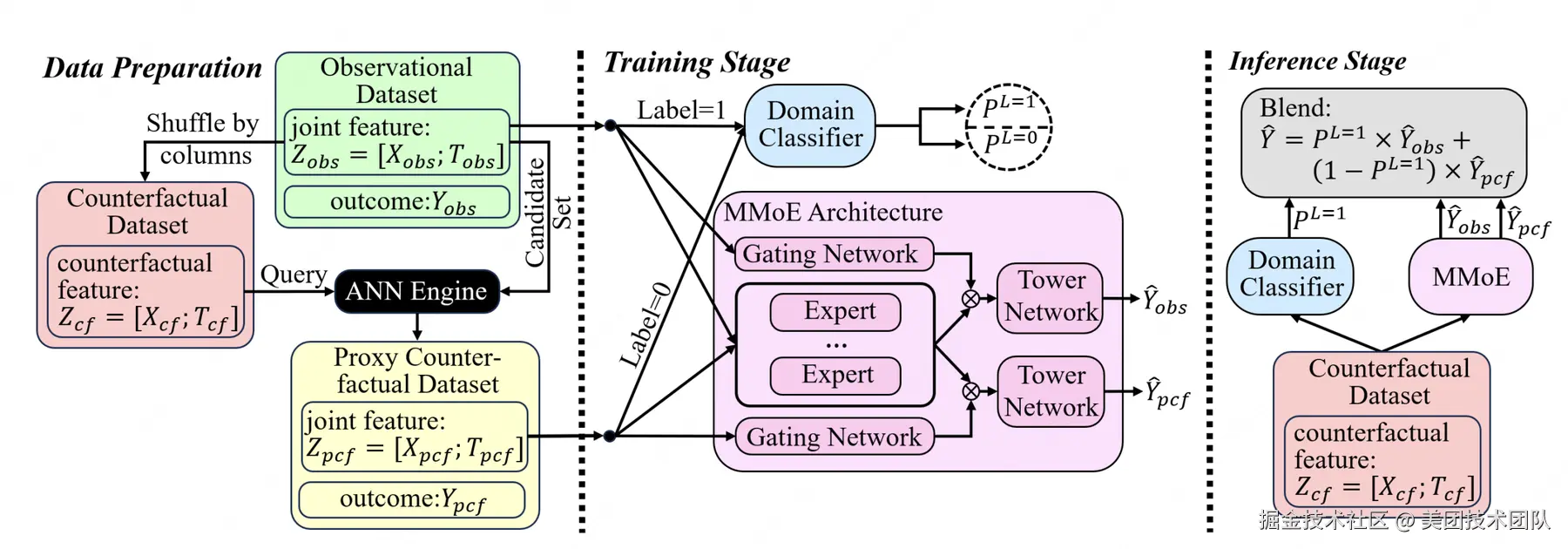
论文简介:在个性化推荐、数字营销和医疗健康等领域,基于观测数据预测反事实结果对科学决策至关重要。在这些应用场景中,决策过程往往涉及高维组合干预策略,例如多渠道资源捆绑投放或产品组合推荐。面向这类场景,无论是历史策略的效果评估还是新策略的优化,都需要模型能够对历史数据中很少出现甚至从未出现过的策略组合效果进行准确预测。此外,观测数据中源于历史分配策略和倾向性投放的选择偏差会进一步加剧数据稀疏问题,从而影响反事实推断的准确性。
为此,本文提出双源反事实融合模型(Dual-Source Counterfactual Fusion,DSCF),该可扩展框架通过双专家混合架构联合建模观测数据和代理反事实样本,并采用领域引导融合机制,在有效平衡偏差消除与信息多样性的同时,还能自适应地泛化到反事实输入场景。在合成和半合成数据集上的大量实验表明,DSCF框架能够显著提升高维组合干预场景下的预测准确性,并在不同情境下展现出优异的鲁棒性表现。
07 Compress-then-Rank: Faster and Better Listwise Reranking with Large Language Models via Ranking-Aware Passage Compression
论文类型:Poster
论文下载 :PDF
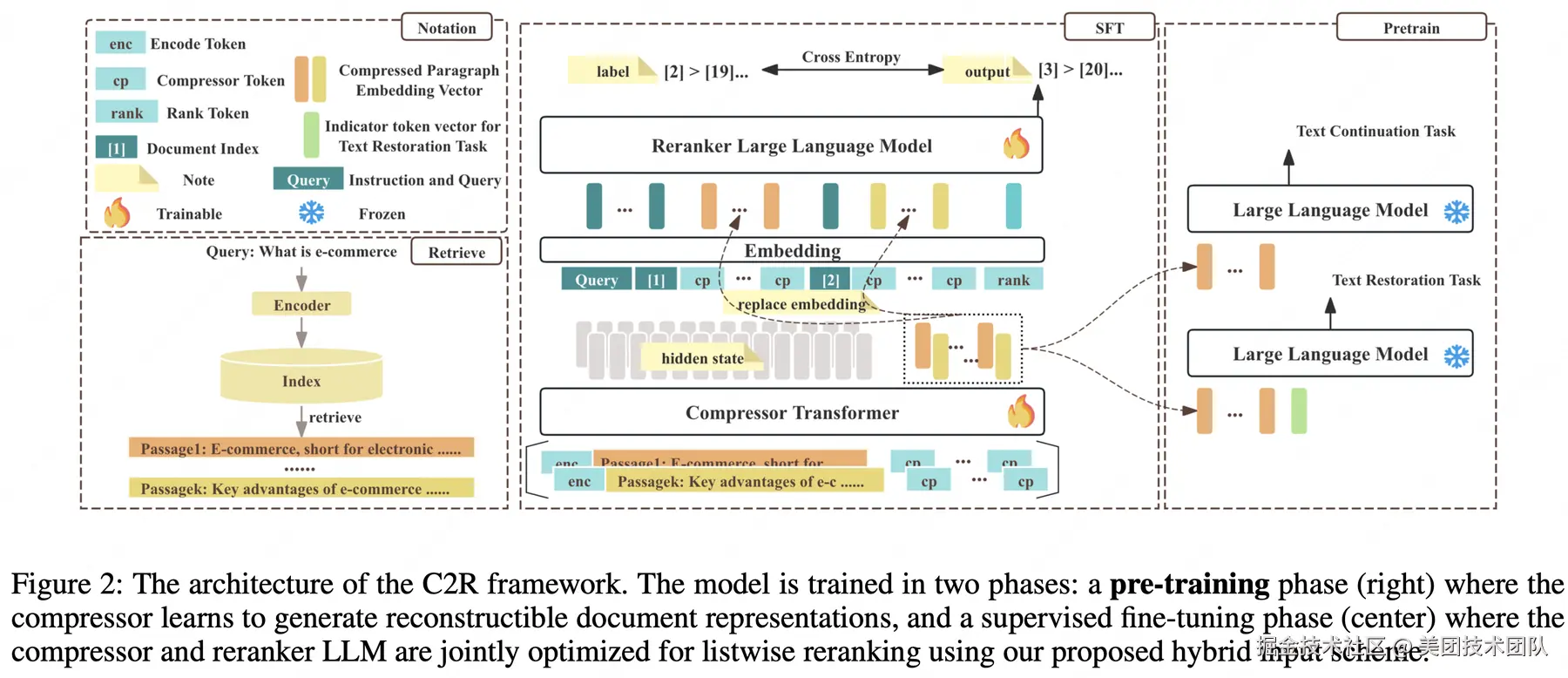
论文简介:基于大型语言模型(LLMs)的列表重排序(listwise reranking)已经成为最先进的方法,在段落重排序任务中不断创下新的性能基准。然而,其实际应用面临两个关键挑战:处理长序列时高昂的计算开销和高延迟,以及由于"迷失在中间"等现象导致的长上下文性能下降。
为了解决这些问题,我们提出了一种高效的框架压缩后排序(Compress-then-Rank, C2R),该框架不是直接对原始段落进行列表重排序,而是对其紧凑的多向量代理进行操作。这些代理可以预先计算并缓存,适用于语料库中的所有段落。C2R 的有效性依赖于三项关键创新。首先,压缩模型通过结合文本恢复和文本延续目标进行预训练,生成高保真的压缩向量序列,从而减轻了单向量方法中常见的语义损失问题。其次,一种新颖的输入方案将每个序数索引的嵌入添加到其对应的压缩向量序列前,这不仅划定了段落边界,还引导重排序 LLM 生成排序列表。最后,压缩模型和重排序模型通过联合优化,使压缩过程对排序目标具有排序感知能力。在主要重排序基准上的广泛实验表明,C2R 在提供显著加速的同时,能够实现与全文重排序方法相当甚至更优的排序性能。
08 Multi-Aspect Cross-modal Quantization for Generative Recommendation
论文类型:Oral
论文下载 :PDF

论文简介:本文提出一种基于多模态融合的生成式推荐框架(MACRec),旨在解决现有生成式推荐方法因模态信息利用不足和跨模态交互缺失导致的性能瓶颈。
针对文本与视觉模态的量化难题,MACRec引入跨模态量化与多角度对齐机制,通过两阶段技术路线实现优化:1)跨模态残差量化:将对比学习融入分层量化过程,生成兼具语义层次性与模态兼容性的物品标识符,显著降低多模态表征冲突;2)跨模态协同对齐:通过显式-隐式协同对齐策略,分别建模文本与视觉模态的共享特征和互补特征,增强生成式推荐的多模态理解能力。在亚马逊电商推荐数据集上的实验结果表明,MACRec相较基准模型在推荐性能上有显著提升;各模态的码本分布更均衡、利用率更低,充分验证了跨模态量化与对齐机制在提升生成式推荐有效性方面的优势。
| 关注「美团技术团队」微信公众号,在公众号菜单栏对话框回复【2024年货】、【2023年货】、【2022年货】、【2021年货】、【2020年货】、【2019年货】、【2018年货】、【2017年货】等关键词,可查看美团技术团队历年技术文章合集。

| 本文系美团技术团队出品,著作权归属美团。欢迎出于分享和交流等非商业目的转载或使用本文内容,敬请注明"内容转载自美团技术团队"。本文未经许可,不得进行商业性转载或者使用。任何商用行为,请发送邮件至 tech@meituan.com 申请授权。