大家好,我是一名CV工程师。
相信大家在开发中不可避免的会用到Java线程池。但是大多数人在使用线程池的都是在网上找个demo直接复制过来就使用。对于线程池的参数不知道如何设定,甚至有些Executors工厂类提供的线程池创建方法都不太了解。
导致线程池在出现问题或者报错的时候都不知道问题出现的原因,更别说下手解决。或者凑巧线程池可以正常工作,但是也为后面的代码性能以及服务器性能都带来无穷的隐患。
这篇文章就为大家详细讲解下:Executors工厂类提供了哪些创建线程池的方法以及这些方法的作用和线程池的工作原理以及我们在实际项目中如何合理的自定义线程池参数。
Executors工厂类提供的线程池
1. FixdThreadPool(固定大小线程池)
- 创建方式
java
ExecutorService executor = Executors.newFixedThreadPool(5); // 核心线程数=最大线程数
//内部实现
new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());- 适用场景
-
- 任务量稳定且执行时间短的场景(如Http请求处理、批量数据处理)。
- 需要限制并发线程数以避免资源耗尽。
- 代码示例
ini
ExecutorService executor = Executors.newFixedThreadPool(5);
for (int i = 0; i < 10; i++) {
executor.execute(() -> {
// do something
System.out.println(Thread.currentThread().getName() + " 执行任务");
});
}
executor.shutdown();2. CachedThreadPool(弹性线程池)
- 创建方式
ini
ExecutorService executor = Executors.newCachedThreadPool();
//内部实现
new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());- 适用场景
-
- 大量短期异步任务(如日志记录、临时请求处理)。
- 任务数量波动大且线程空闲时间较短。
- 代码示例
ini
ExecutorService executor = Executors.newCachedThreadPool();
executor.submit(() -> {
// 执行IO密集型任务(如文件下载)
//do something
});
executor.shutdown();3. SingleThreadExecutor(单线程池)
- 创建方式
ini
ExecutorService executor = Executors.newSingleThreadExecutor();- 适用场景
-
- 需要任务顺序执行的场景(如订单状态机、数据库事务队列)。
- 避免并发问题(如共享资源操作)。
- 代码示例
scss
ExecutorService executor = Executors.newSingleThreadExecutor();
executor.execute(() -> System.out.println("任务1"));
executor.execute(() -> System.out.println("任务2")); // 按提交顺序执行
executor.shutdown();4. ScheduledThreadPool(定时任务线程池)
- 创建方式
ini
ScheduledExecutorService executor = Executors.newScheduledThreadPool(2);- 适用场景
-
- 需要任务顺序执行的场景(如订单状态机、数据库事务队列)。
- 避免并发问题(如共享资源操作)。
- 代码示例
ini
ScheduledExecutorService executor = Executors.newScheduledThreadPool(2);
// 延迟1秒后执行,每隔2秒重复执行
executor.scheduleAtFixedRate(() ->
System.out.println("定时任务"), 1, 2, TimeUnit.SECONDS);5. 手动配置ThreadPoolExecutor
- 创建方式
通过自定义参数实现更精细的控制:
java
ThreadPoolExecutor executor = new ThreadPoolExecutor(
5, // (corePoolSize)核心线程数,线程池中用来工作的核心的线程数量
10, // (maximumPoolSize)最大线程数,线程池允许创建的最大线程数
60, // (keepAliveTime)空闲线程(最大线程数-核心线程数)存活时间
TimeUnit.SECONDS,//keepAliveTime的时间单位
new LinkedBlockingQueue<>(100), // 任务队列,是一个阻塞队列,当线程数已达到核心线程数,会将任务存储在阻塞队列中。
Executors.defaultThreadFactory(), // 线程工厂,线程池内部创建线程所用的工厂。
new ThreadPoolExecutor.AbortPolicy() // 拒绝策略,当队列已满并且线程数量达到最大线程数量时,会调用该方法处理该任务。
);- 适用场景
-
- 需要自定义线程池参数(如队列容量、拒绝策略)。
- 高并发且任务类型复杂(如混合型任务)。
- 参数详解
-
- 核心线程数:长期存活线程数量。
- 最大线程数:队列满时允许创建的最大线程数。
- 拒绝策略:
-
-
- AbortPolicy:默认策略,直接抛出异常。
- CallerRunsPolicy:由提交任务的线程执行任务。
- DiscardOldestPolicy:丢弃队列中最旧的任务。
- DiscardPolicy:静默丢弃新任务。
-
- 代码示例
ini
ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 10, 60, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(100));
executor.execute(() -> {
// 执行计算密集型任务(如数据分析)
});
executor.shutdown();适用场景总结
| 线程池类型 | 适用场景 | 关键特性 |
|---|---|---|
| FixedThreadPool | 固定并发量、短期任务(如Web服务器请求) | 线程数固定,队列无界 |
| CachedThreadPool | 突发性短期任务(如日志处理) | 线程数弹性,自动回收空闲线程 |
| SingleThreadExecutor | 需顺序执行的任务(如单线程事务处理) | 单线程串行执行 |
| ScheduledThreadPool | 定时或周期性任务(如缓存刷新、监控报警) | 支持延迟和周期性任务 |
| 自定义ThreadPoolExecutor | 复杂场景(如混合型任务、需精细控制参数) | 可调队列容量、拒绝策略、线程生命周期管理 |
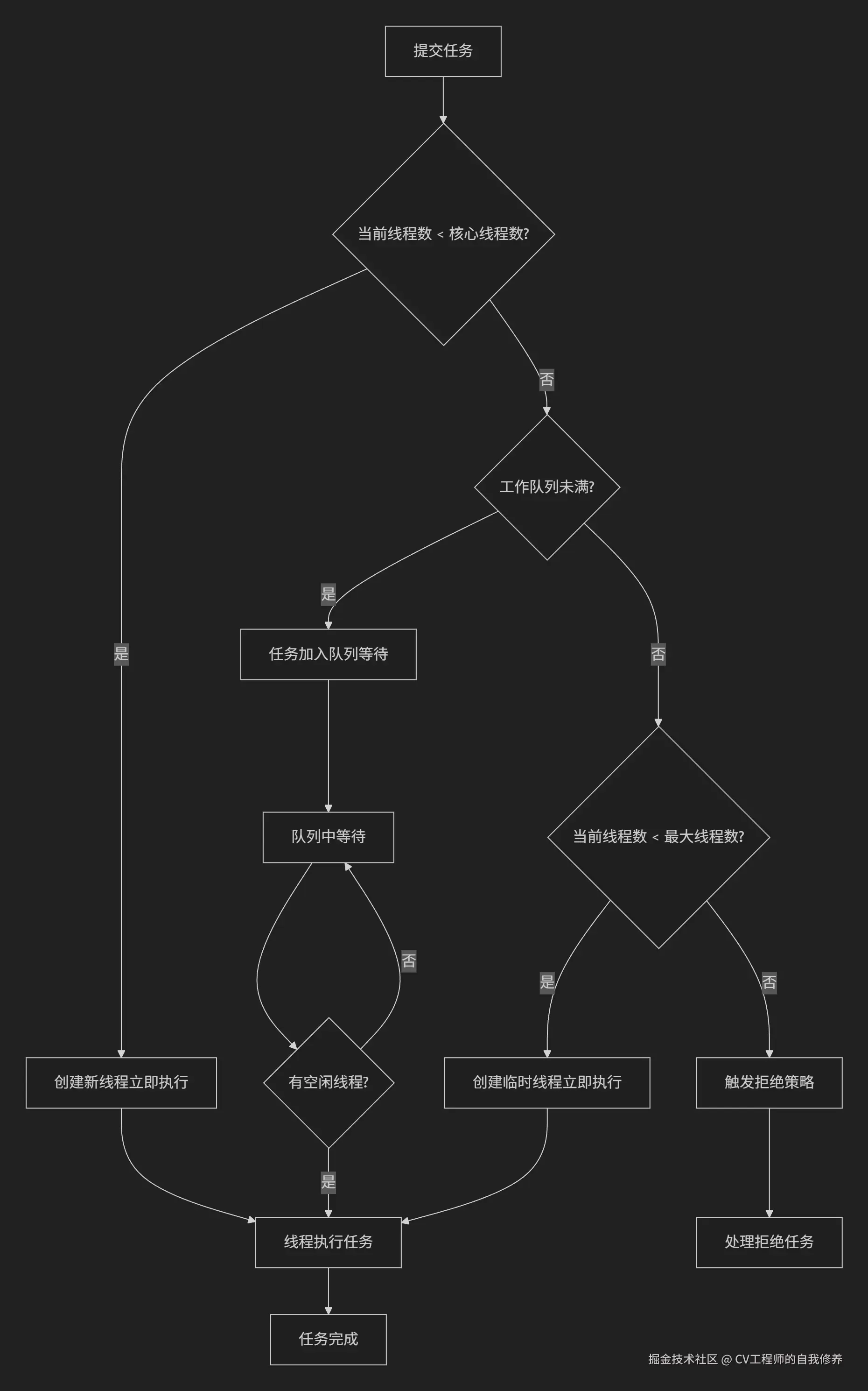
线程池运行过程
- 线程池运行流程图
- 线程池刚创建出来的样子
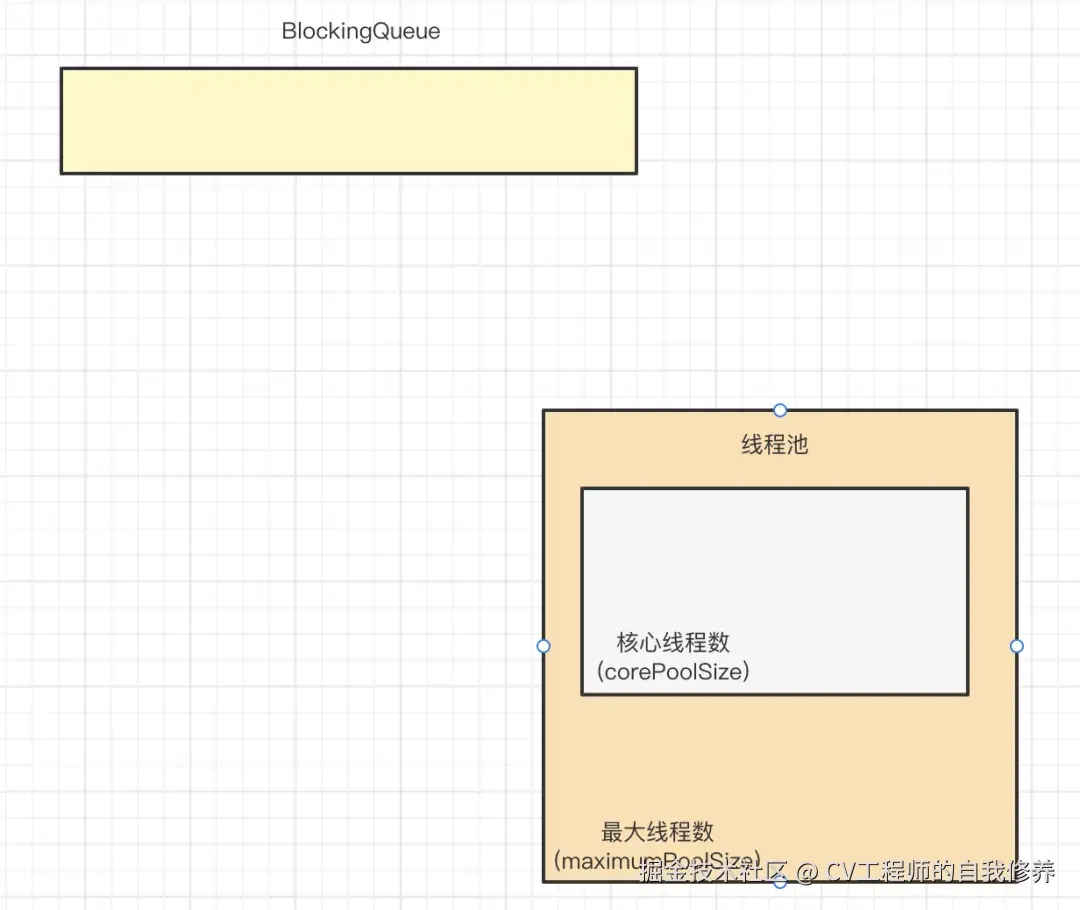
刚创建出来的线程池只有一个队列实例,此时并没有任何线程,但是如果你想要在提交任务之前创建好核心线程数,可以调用prestartAllCoreThreads方法实现,默认是没有线程的。
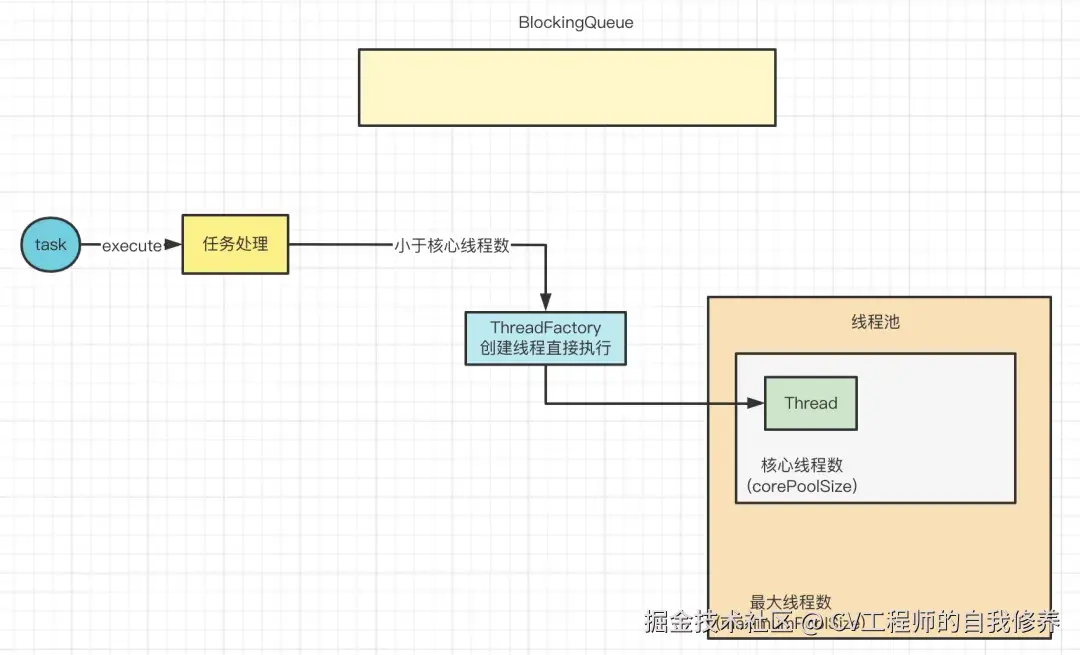
- 当主线程通过execute方法提交了一个任务。
首先会去判断当前线程池的线程数是否小于核心线程数,也就是线程池构造时传入的参数corePoolSize。
如果小于,那么就直接通过ThreadFactory创建一个线程来执行这个任务,如图
当任务执行完之后,线程不会退出,而是会从阻塞队列中获取任务,如图: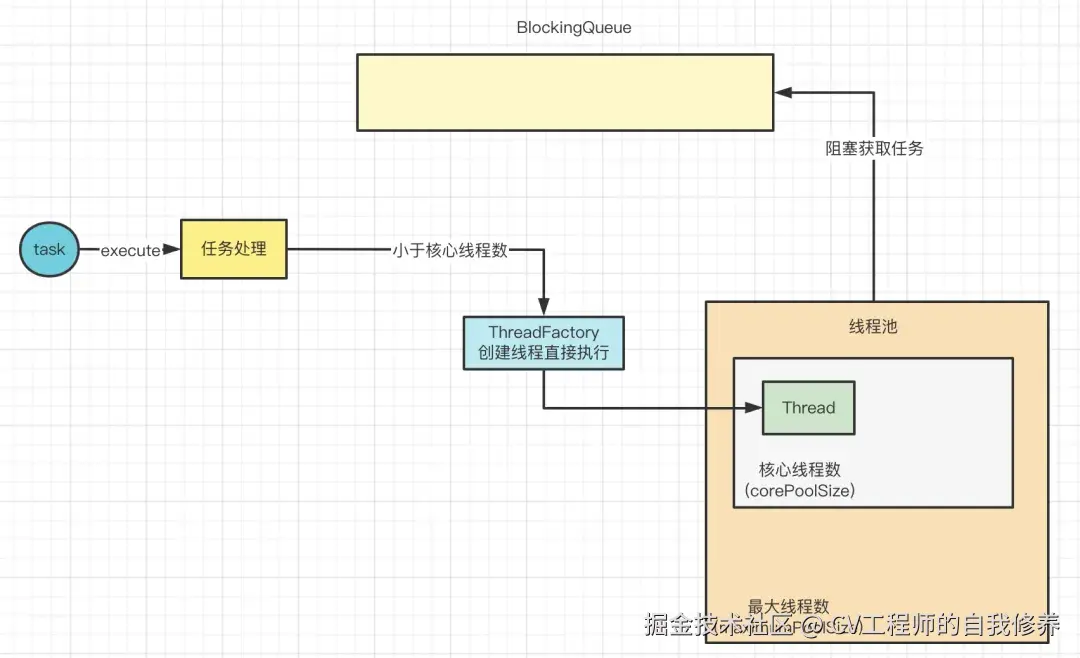
接下来如果又提交了一个任务,也会按照上述步骤,去判断是否小于核心线程数,如果小于,还是会创建线程来执行任务,执行完之后也会从阻塞队列中获取任务。这里有个细节,就是提交任务的时候,就算有线程池里的线程凑够阻塞队列中获取不到任务(意思就是有空闲线程),如果线程池里的线程数还是小于核心线程数,那么依然会继续创建线程,而不是复用已有的线程。
如果线程池里的线程数不在小于核心线程数呢?那么此时就会尝试将任务放入阻塞队列中,入队成功之后,如图:
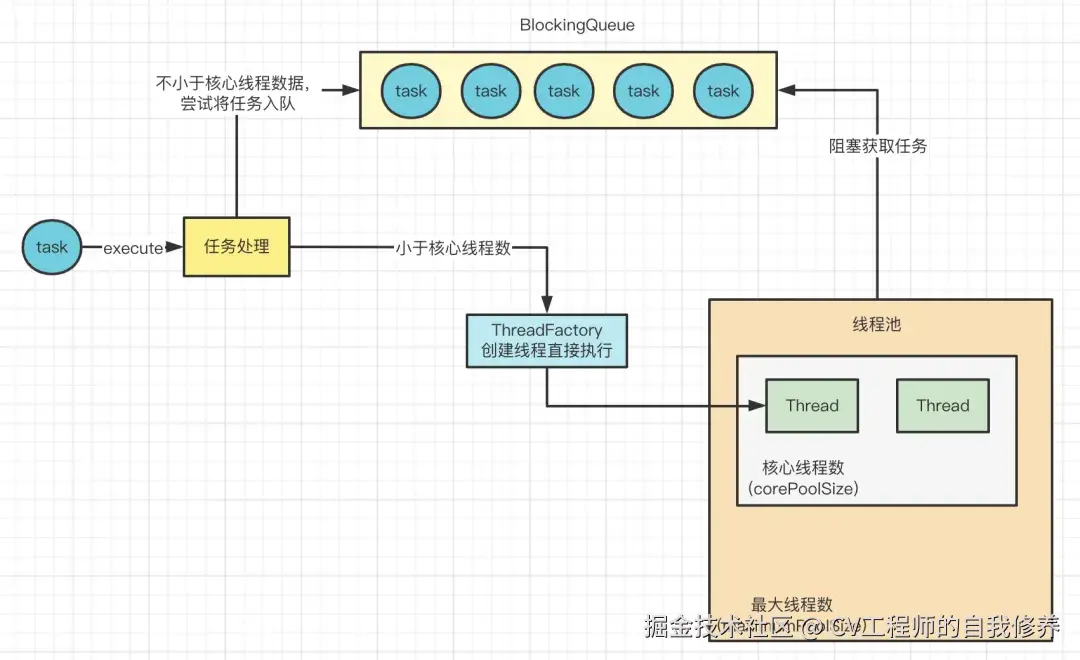
这样在阻塞的线程就可以获取到任务了。
但是,随着任务越来越多,队列已经满了,任务就放入失败了。此时就会判断当前线程池里的线程数是否小于最大线程数,也就是创建线程池的时候的maximumPoolSize参数。
如果小于最大线程数,那么也会创建非核心线程来执行提交的任务,如图:
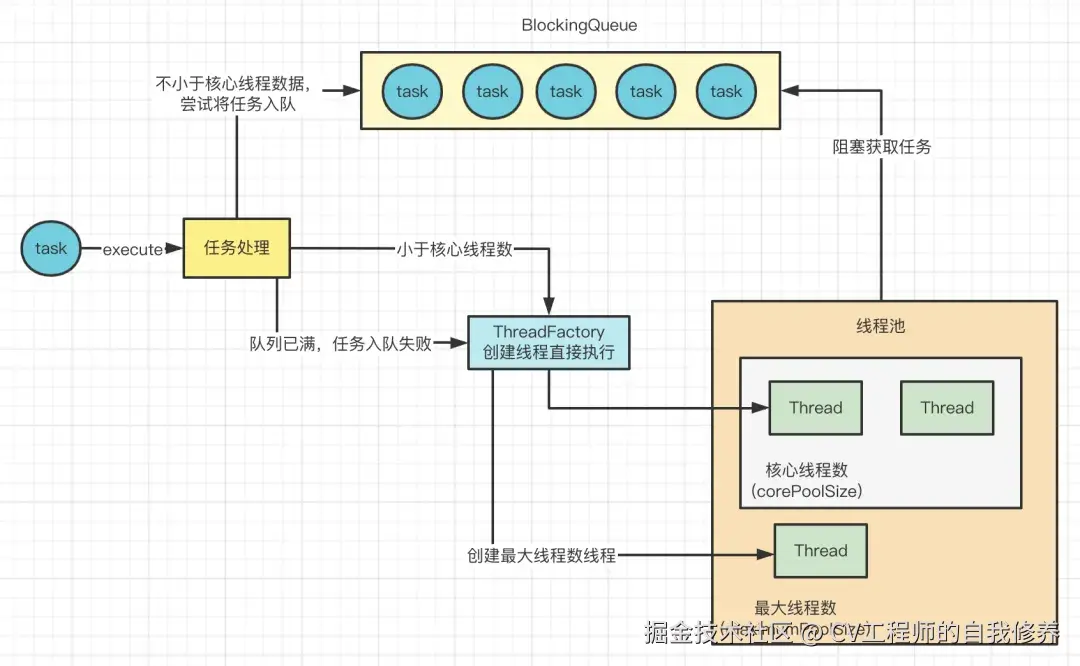
所以,就算队列中有任务,新创建的线程还是优先处理这个提交的任务,而不是从队列中获取已有得到任务执行,从这可以看出,先提交的任务不一定先执行。
如果线程数已经达到了最大线程数量,此时就会执行拒绝策略,也就是创建线程池的时候,传入的参数RejectedExecutionHandler对象。
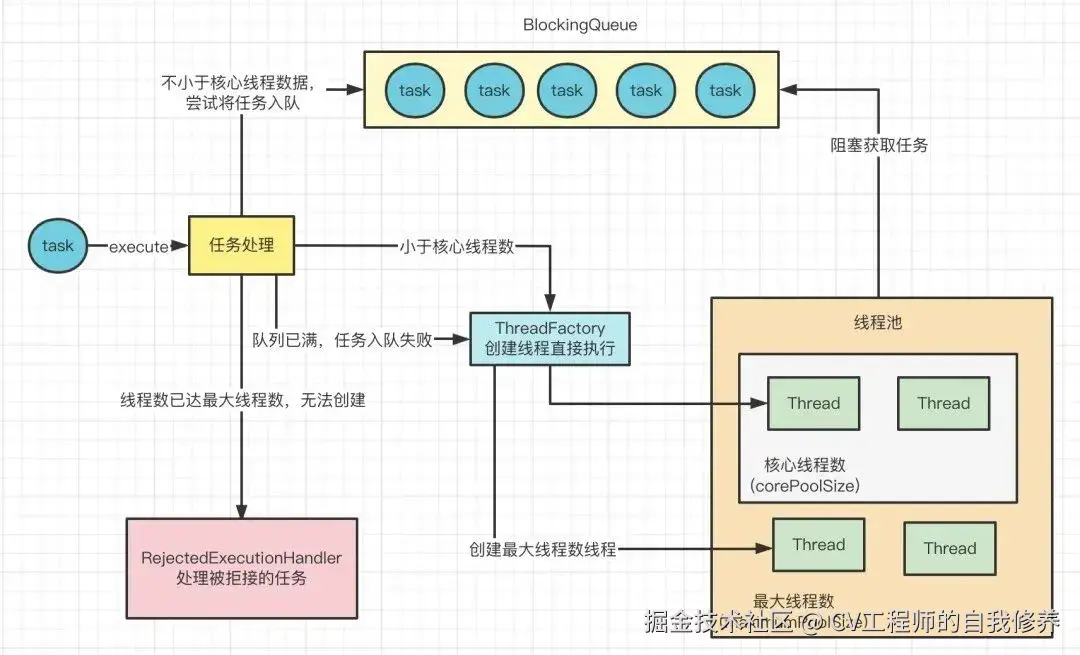
execute方法代码是如何实现的

-
- workerCountOf(c)<corePoolSize:这行代码就是判断是否小于核心线程数,是的话就通过addWorker方法,addWorker就是添加线程来执行任务。
- workQueue.offer(command):这行代码就表示尝试往阻塞队列中添加任务
- 添加失败之后就会再次调用addWorker方法尝试添加非核心线程来执行任务
- 如果还是添加非核心线程失败了,那么就会调用reject(command)来拒绝这个任务。
execute执行流程

实际项目中如何合理的自定义线程池
- 核心线程数
线程数的设置主要取决于业务时I/O密集型还是CPU密集型。
CPU密集型是指任务主要使用来进行大量的计算,没有什么导致线程阻塞。一般这种场景的线程数设置为CPU核心数+1;
IO密集型,当执行任务需要大量的IO,比如磁盘IO,网络IO,可能会存在大量的阻塞,所以在IO密集型任务中使用多线程可以大大地加速任务的处理。一般线程数设置为 2*CPU核心数。
Java中用来获取CPU核心数的方法是:
scss
Runtime.getRuntime().availableProcessors();- 线程工厂
一般建议自定义线程工厂,构建线程的时候设置线程的名称,这样就在查日志的时候就方便知道是哪个线程执行的代码。
- 有界队列
一般需要设置有界队列的大小,比如LinkedBlockingQueue在构造的时候就可以传入参数,来限制队列中任务数据的大小,这样就不会因为无限往队列中扔任务导致系统的oom。
任务队列类型与特性
类型
一、SynchronousQueue(同步有界队列)
-
- 特性: 不存储任何元素,每个插入操作必须等待另一个线程执行一处操作,否则回阻塞。
- 作用: 强制线程池直接创建新线程处理任务,而非缓冲任务。
- 使用场景: 适用于高吞吐量、短任务频繁的场景(如缓存型线程池 CachedThreadPool)。
- 注意事项: 需设置较大的maximumPoolSize,否则容易触发拒策略。
二、ArrayBlockingQueue(有界队列)
-
- 特性: 基于数组的固定容量队列,按FIFO(先进先出)原则顺序。
- 作用: 限制任务队列长度,防止资源耗尽,强制在队列满时触发非核心线程创建。
- 使用场景: 适用于负载较重且需严格控制内存的服务器。
- 使用建议: 需平衡corePoolSize、maximumPoolSize 和队列容量,避免频繁触发拒绝策略。
三、LinkedBlockingQueue(无界/有界队列)
-
- 特性: 基于链表的队列,默认无界(容量为 Integer.MAX_VALUE),也可以设置为有界。
- 作用: 优先缓冲任务,仅在核心线程繁忙时将任务加入队列。
- 使用场景:
-
-
- 无界模式: 适用于任务量波动大且允许内存增长的场景(如 FixedThreadPool)。
- 有界模式: 需手动设置容量,类似ArrayBlockingQueue但吞吐量更高。
-
-
- 风险提示: 无界队列可能导致内存溢出(OOM),需谨慎使用。
四、PriorityBlockingQueue(优先级队列)
-
- 特性: 无界队列,支持按任务优先级排序(需实现Comparable接口)
- 作用: 确保优先级高的任务优先执行,适用于任务有明确优先级的场景。
- 使用场景: 实时任务调度(如支付系统中的紧急交易处理)。
- 示例:
arduino
// 自定义任务优先级
BlockingQueue<Runnable> queue = new PriorityBlockingQueue<>(11, Comparator.comparingInt(Task::getPriority));
new ThreadPoolExecutor(5, 10, 60L, TimeUnit.SECONDS, queue);任务队列选择与线程池行为的关系
线程池的任务处理流程由队列类型和线程数参数共同决定:
- 核心线程未满:直接创建线程执行任务。
- 核心线程已满:
-
- SynchronousQueue :直接创建非核心线程,直至达到
maximumPoolSize。 - 有界队列(Array/Linked) :任务入队,队列满时创建非核心线程****。
- 无界队列(LinkedBlockingQueue) :任务无限入队,不会触发非核心线程创建****。
- SynchronousQueue :直接创建非核心线程,直至达到
- 队列与线程均满 :触发拒绝策略(如
AbortPolicy抛异常或CallerRunsPolicy由提交线程执行)。
典型应用场景推荐
| 队列类型 | 适用场景 |
|---|---|
| SynchronousQueue | 高并发短任务(如实时API请求)或需快速响应的缓存型线程池 |
| ArrayBlockingQueue | 资源受限的稳定负载系统(如数据库连接池) |
| LinkedBlockingQueue | 批处理任务(如日志异步写入)或需平滑处理流量峰谷的场景 |
| PriorityBlockingQueue | 任务需分级处理(如电商秒杀系统中的VIP优先下单) |
调优建议
- 避免无界队列 :防止内存溢出,可通过
setMaximumPoolSize动态调整线程数****。 - 监控队列堆积 :使用
getQueue().size()实时监控任务积压情况****。 - 结合拒绝策略 :队列满时,
CallerRunsPolicy可降低系统负载,但可能阻塞主线程****。
关注我,后续为大家带来线程池的各种提交任务的方式以及怎么选择。