为什么每次只改一行数据,却要重算上亿条历史记录?
你在构建实时看板、用户画像或风控特征时,是否也遇到过这样的困境?
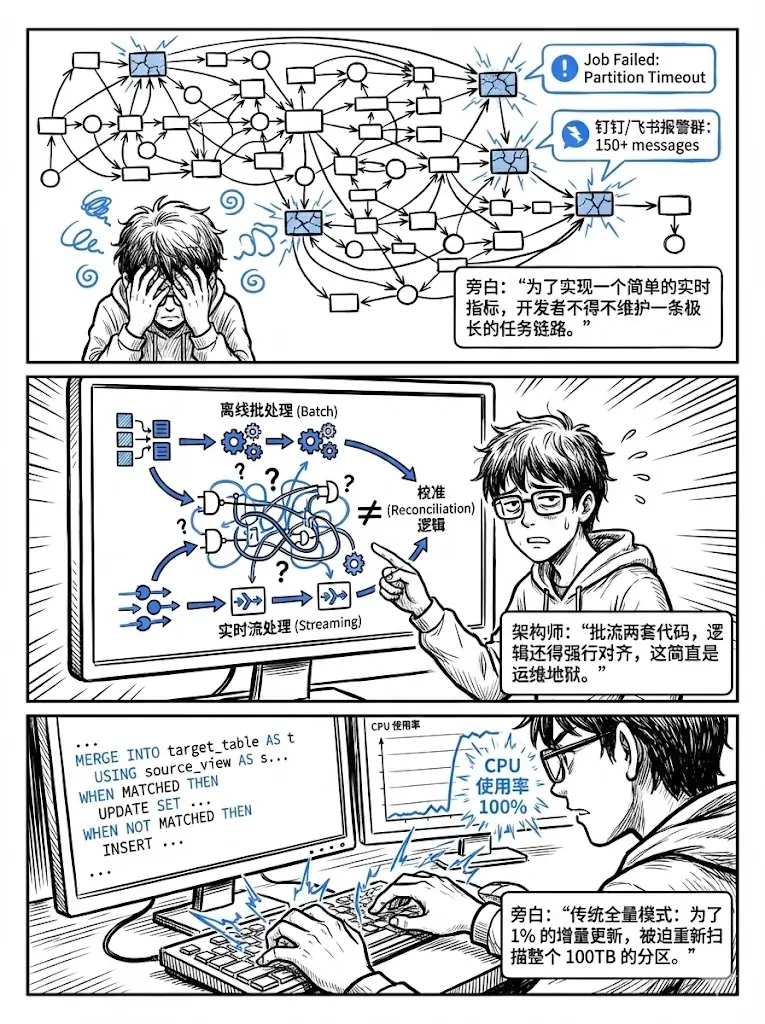
每天新增的订单可能只有几万条,但背后的用户、商品、支付表动辄上亿行。为了刷新一个聚合指标,系统不得不全量扫描、重新 Join、再聚合------哪怕 99% 的数据根本没有变化。
这不仅拖慢了刷新频率,还让计算成本居高不下。
更糟的是,为了"扛住"全量任务,团队往往被迫拆出多层中间表,链路越拉越长,维护越来越难。
增量刷新本应是解药,但并非所有方案都是真正"增量"。
一些系统采用无状态模型:每次只读变更数据,却不保存任何中间结果。听起来轻量,实则代价高昂------复杂查询下,它仍需反复回溯历史数据,甚至比全量更慢。

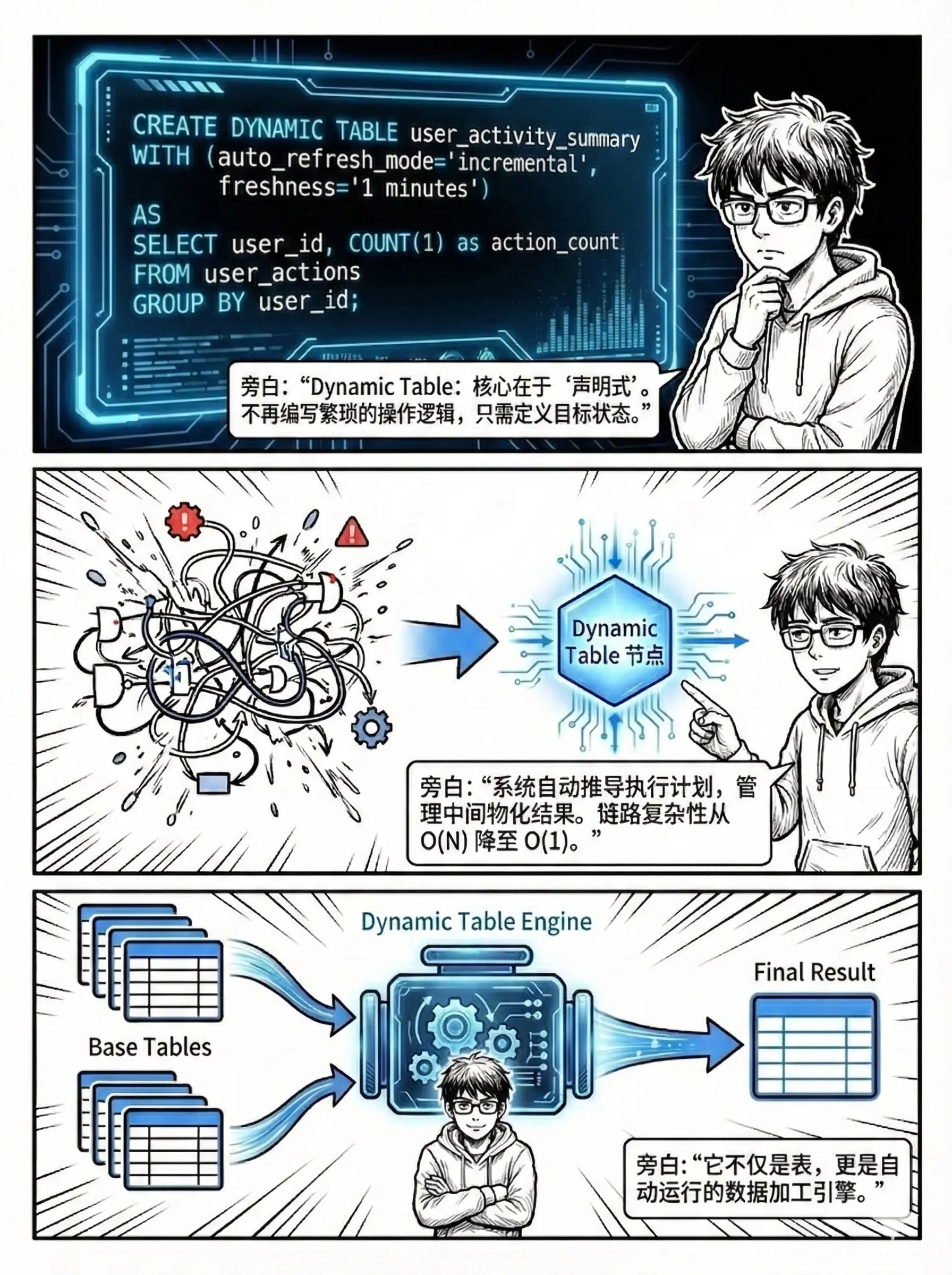
阿里云 Hologres 选择了另一条路径:有状态增量计算。
在首次全量构建时,它同步生成并持久化关键中间状态------比如聚合值、Join 中间产物。
后续刷新,只需将新数据与状态合并,无需触碰原始历史表。
这意味着:
-
刷新延迟从分钟级降至秒级;
-
计算资源消耗大幅下降;
-
即使面对五表 Join 或 COUNT DISTINCT,也能保持高效。

状态确实需要额外存储,但这部分开销是可控的。
在分区表场景中,仅活跃分区保留状态;非活跃分区自动转为全量,避免状态膨胀。
对于非分区表,也可通过 TTL 策略清理过期状态。

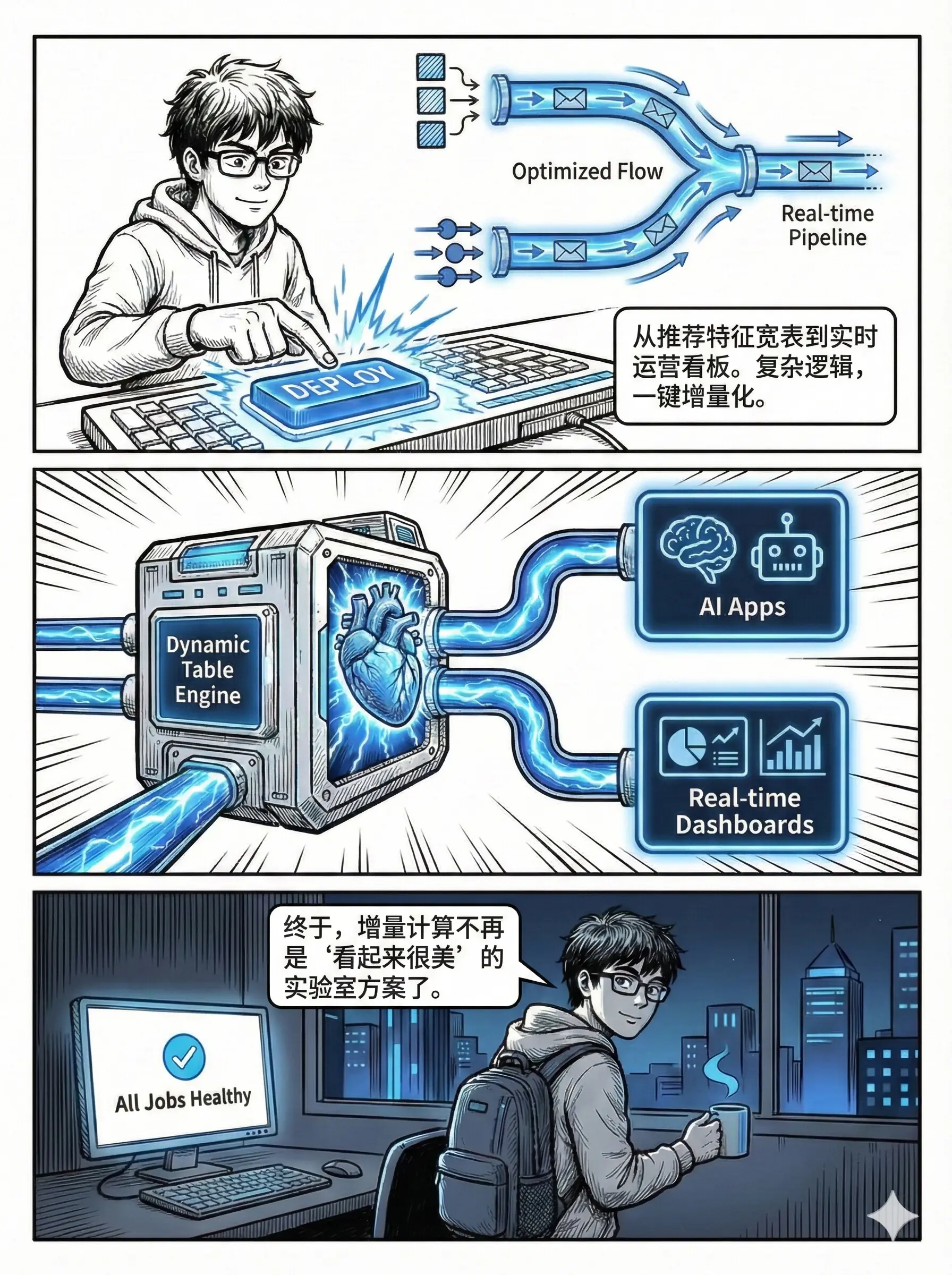
真正的效率,不在于少算一点,而在于只算该算的。
如果你正在设计实时数仓、特征管道或统一指标体系,不妨评估:你的"增量"是否真的避开了历史数据的重复计算?
Hologres Dynamic Table 提供了一种经过验证的答案------用有限的存储换确定性的性能,让实时更新回归本质。