agent-browser:让 AI Agent 像人一样浏览网页(节省93% Token)
为什么是 agent-browser
如果你正在开发 AI Agent,或者尝试用 LLM 来控制浏览器进行自动化操作,那么你大概率遇到过这两个"拦路虎":
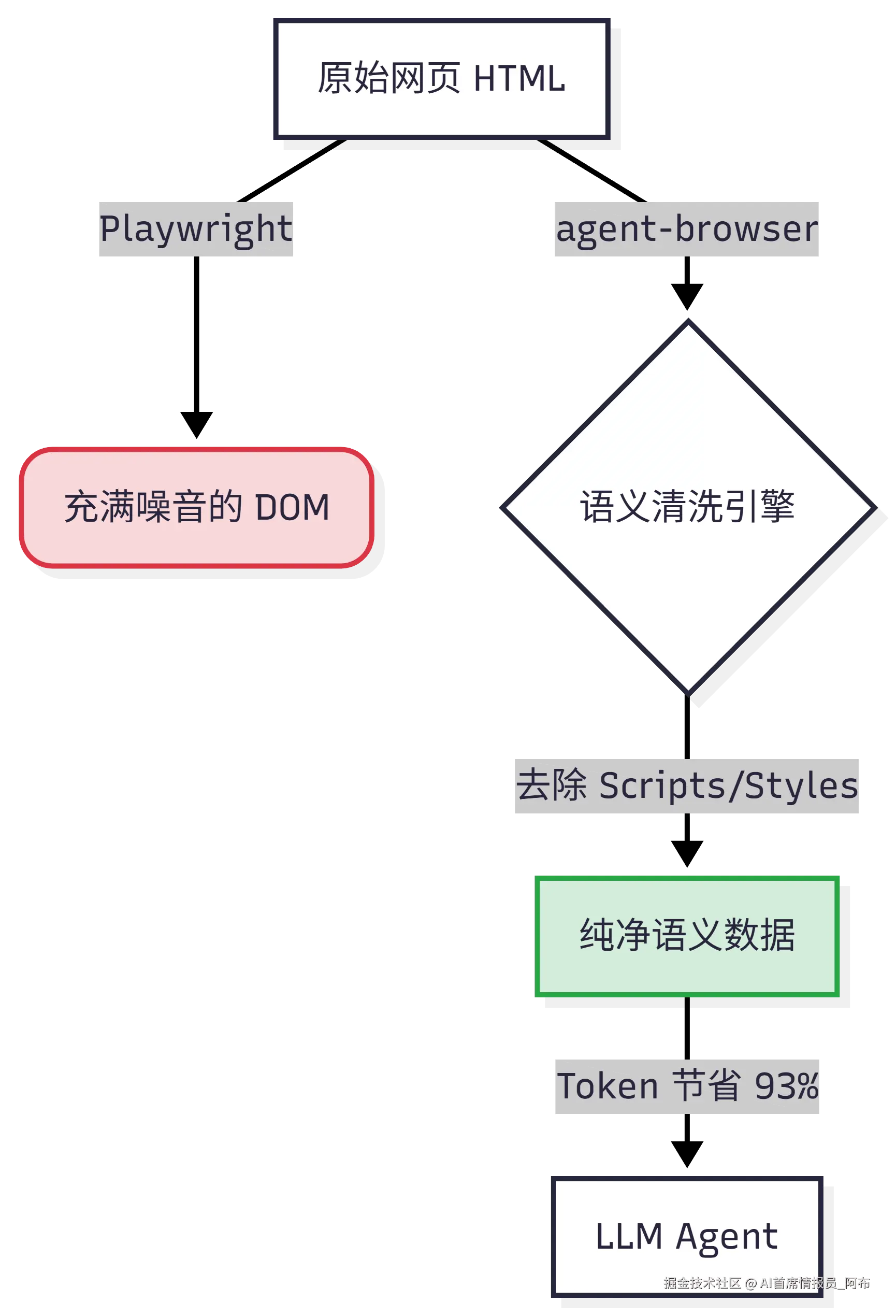
- Token 贵且慢(Context Rot) :一个普通的网页 HTML 动辄几百 KB,直接喂给 LLM,不仅 Token 消耗惊人,而且充满噪音(CSS、Script 标签)。LLM 在处理这种长文本时,极易产生幻觉(Hallucination),我们称之为"上下文腐烂"(Context Rot)。
- 选择器脆弱(Flaky Selectors) :传统的
div > div.content > span选择器脆弱不堪。网页稍微改版,class 名变一下,你的 Agent 就从"自动化"变成了"人工报错机"。
针对这两个核心痛点,Vercel Labs 开源了 agent-browser。
它不是简单的 Playwright 封装,而是专为 LLM 设计的浏览器接口。
核心价值:
- 节省高达 93% 的 Token:它不给 LLM 看原始 HTML,而是经过语义清洗后的精简结构。
- 告别脆弱选择器:支持自然语言交互,Agent 不再依赖死板的 CSS 选择器。
- 开箱即用:零配置,无需繁琐的 MCP 安装,一条命令即可启动。
核心原理:它是如何"像人一样"浏览的?
传统的自动化是为了"测试",所以追求精确的 DOM 匹配。而 agent-browser 是为了"理解",所以它追求语义的提取。
◈1. 拒绝"上下文腐烂"
我们来看一组真实对比。假设我们要访问 Hacker News 首页并提取头条新闻。
传统方式(Playwright page.content()) : 你需要将包含大量 <script>, <style>, <div> 嵌套的原始 HTML 传给 LLM。
- Token 消耗:~15k Tokens
- 噪点:极高(90% 是无用代码)
Agent Browser 方式: 它会利用无障碍树(Accessibility Tree)和语义分析,将页面转化为 LLM "喜欢" 的格式。
json
{
"type": "link",
"name": "Show HN: My new project",
"url": "https://..."
}- Token 消耗:~800 Tokens
- 节省比例 :93%
◈2. 语义化交互(Semantic Interaction)
你不需要再去查 Check State 或者写 await page.click('#submit-btn')。agent-browser 允许你直接说"人话"。
场景:点击登录按钮。
以前(Playwright) :
csharp
// 如果 id 变了,这就挂了
await page.click('#login-button-v2'); 现在(agent-browser) : 它是"快照 + 引用"模式。
- Snapshot : 生成语义树,给每个元素分配短引用(如
@e1,@e2)。 - Action: 基于引用操作。
arduino
agent-browser click @e1你(或者你的 Agent)只需要认准 @e1 这个语义标签,而不需要关心底层的 DOM 结构变化。
Technical Deep Dive:5分钟实战上手
◈1. 安装与启动
它是基于 Rust (CLI) 和 Node.js (Daemon) 构建的,速度极快。
r
# 无需配置 MCP,直接 npx
npm install -g agent-browser
# 验证安装
agent-browser help◈2. 真实场景演示:抓取 Github Trending
假设我们要写一个 Agent,每天早上自动抓取 GitHub Trending 的第一名项目。
第一步:导航 它没有复杂的"启动会话"命令,直接 open 即可自动连接后台 Daemon。
arduino
agent-browser open "https://github.com/trending"第二步:获取语义快照 (Snapshot) 这是最关键的一步。我们不看 HTML,而是请求快照:
r
agent-browser snapshotAgent 看到的简化结果 (JSON) :
perl
[
{ "id": "@e1", "role": "link", "text": "vercel-labs/agent-browser" },
{ "id": "@e2", "role": "text", "text": "Browser automation for AI agents" }
]第三步:提取内容 AI 识别出 @e1 是我们想要的项目,于是执行:
scss
agent-browser get text @e1
# Output: vercel-labs/agent-browser注意,全过程我们没有写任何 CSS 选择器(如 .RepoList-item .f3 a)!因为 snapshot 已经帮我们提取了语义结构。
◈3. 与 Claude / Cursor 集成
这才是它最强大的地方。你可以把 agent-browser 当作一个工具(Tool)挂载给你的 AI Coding Assistant。
如果你使用的是 Cursor,可以直接在 Terminal 中运行它。如果你自己在开发 Agent,可以这样集成:
javascript
import { AgentBrowser } from 'agent-browser';
const browser = new AgentBrowser();
const page = await browser.newPage();
// 给 LLM 的 System Prompt 中加入:
// "You have access to a browser tool. Use browser.interact(instruction) to control it."避坑指南(踩坑案例)
Warning
避坑指南 :虽然 agent-browser 很强,但在实际生产环境中使用,也有一些需要注意的地方。不要盲目乐观。
◈1. 复杂动态页面的等待
问题场景: 在访问类似 React/Vue 构建的重型 SPA(单页应用)时,页面元素是动态加载的。
错误做法: Navigate 之后立即 Query。
bash
agent-browser navigate "https://complex-app.com"
agent-browser query "Get usage stats"
# Error: Element not found (因为还没由于 loading 完)正确做法: 显式等待某个语义元素出现。
bash
agent-browser wait "Usage chart" --timeout 5000
agent-browser snapshot◈2. Form 表单的交互
问题: 有时候 LLM 会一次性填完所有表单,但网页逻辑是"填完一个 Input 触发一个 Validation"。
建议: 对于复杂的 Step-by-Step 表单,建议拆分指令,不要试图用一条 prompt 完成所有交互。
总结:AI 时代的浏览器
我们正在经历从"脚本自动化"到"Agent 自动化"的转型。
- 脚本时代:我们写死每一个步骤,追求 100% 的确定性,维护成本极高。
- Agent 时代:我们给出意图(Intent),由 AI 处理细节,追求的是适应性和理解力。
agent-browser 并不是要替代 Playwright,它是 Playwright 在 AI 时代的翻译官。它把人类看不懂的 DOM,翻译成了 AI 能看懂的语义。
如果你的 Token 账单居高不下,或者你的爬虫脚本三天两头报错,不妨试试这个新工具。