环境方面
Transformer代码库(此Transformer非之前的,而是包含了当前四大主流的模块)
github.com/huggingface/transformers

四个领域
我的电脑已经配置好了环境,cuda_11.6,torch 1.13.0+cu116,transformers 4.56.1
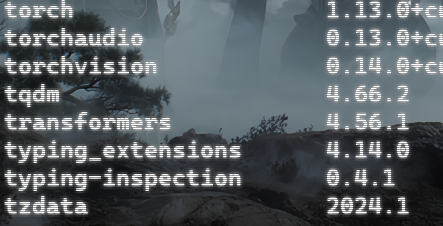
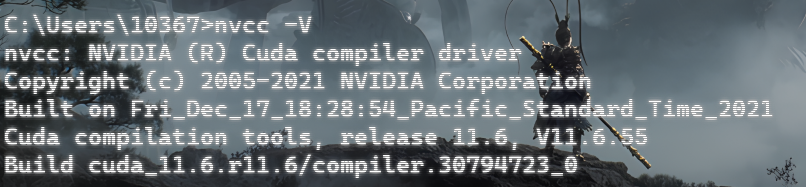
但是我要的是torch2.5.0 transformers4.51.3
步骤 1:查看当前显卡驱动版本
bash
nvidia-smi重点看 2 个信息:
Driver Version:驱动版本(需≥535.86.05 才支持 CUDA12.1, RTX4000 Ada 肯定能升级到这个版本);CUDA Version:驱动支持的最高 CUDA 版本(比如显示 12.2,说明驱动能支持 CUDA12.1)。
步骤 2:卸载旧版本(清理残留,10 分钟)
bash
# 彻底卸载旧版本torch/vision/audio
pip uninstall -y torch torchvision torchaudio
# 卸载transformers旧版本(4.56.1)
pip uninstall -y transformers2.2 卸载系统端的 CUDA 11.6 Toolkit
- 打开 Windows「设置」→ 「应用」→ 「应用和功能」;
- 在搜索框输入「NVIDIA」,找到以下组件并按顺序卸载:
- NVIDIA CUDA Toolkit 11.6
- NVIDIA CUDA Runtime 11.6
- NVIDIA CUDA Documentation 11.6
- NVIDIA CUDA Samples 11.6
- NVIDIA CUDA Visual Studio Integration 11.6
- 卸载完成后,重启电脑(必须重启,清理残留注册表)。
步骤 3:升级显卡驱动到支持 CUDA12.1 的版本(10 分钟)
3.1 下载适配的驱动
- 打开 NVIDIA 官网驱动下载页:https://www.nvidia.com/Download/index.aspx
- 按以下参数选择(精准匹配 RTX4000 Ada):
- Product Type:Professional → Quadro
- Product Series:RTX 4000 Series (Ada Generation)
- Product:NVIDIA RTX 4000 Ada Generation
- Operating System:选你的系统(比如 Windows 10 64-bit / Windows 11 64-bit)
- Driver Type:Studio Driver(工作室驱动,适合深度学习 / AI,稳定性高)
- 点击「SEARCH」→ 点击「DOWNLOAD」下载驱动安装包
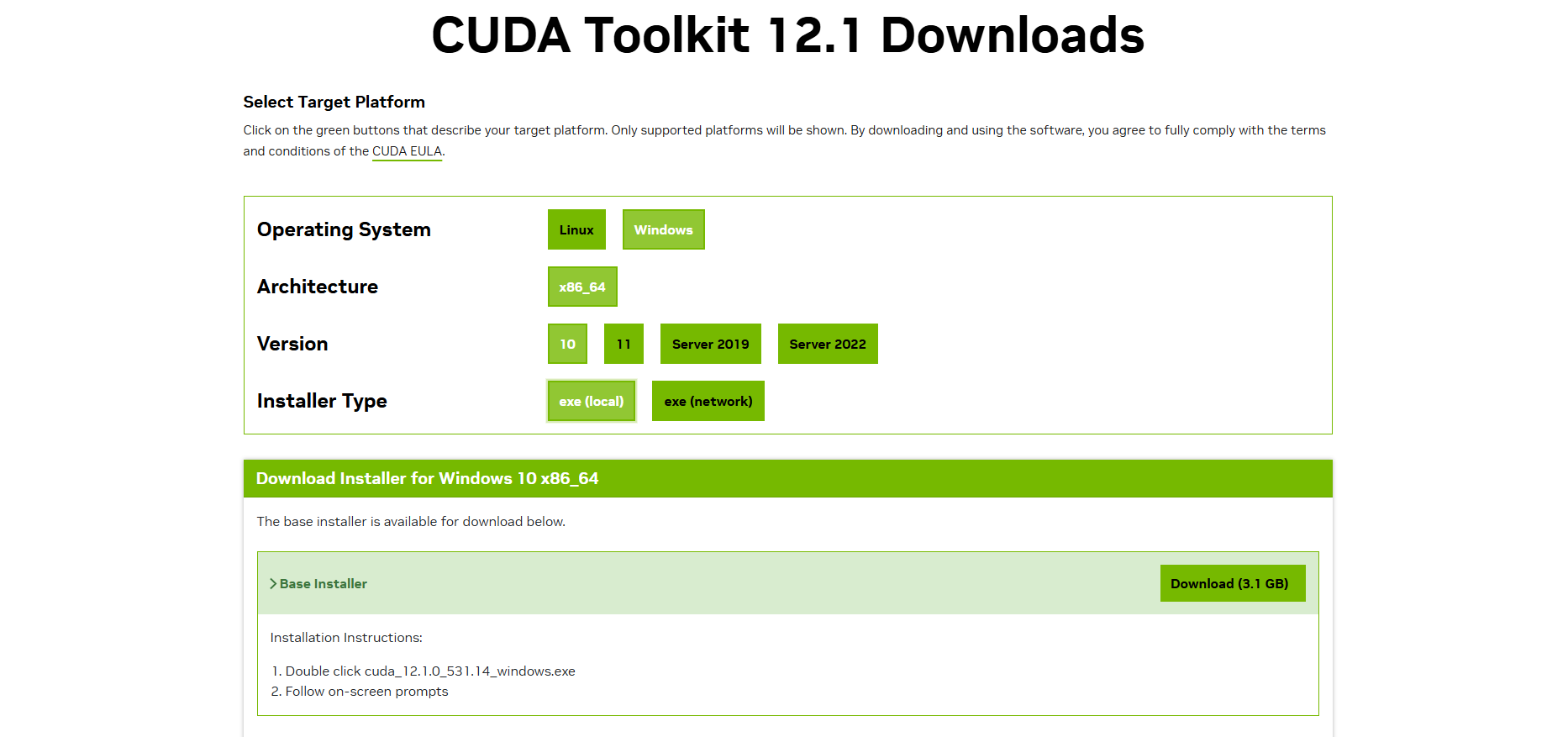
官网下载有点慢,总是最后200就下不去了,改成用迅雷下
安装
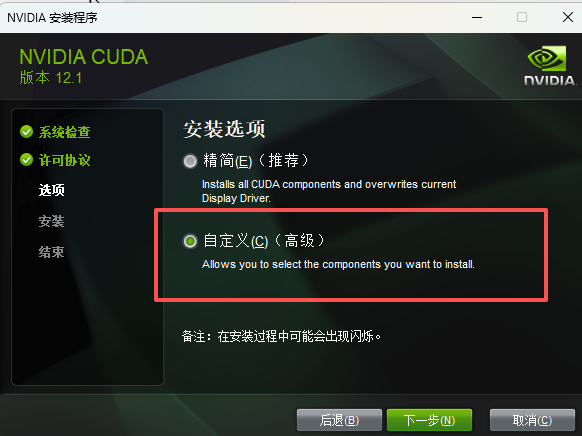
测试一下
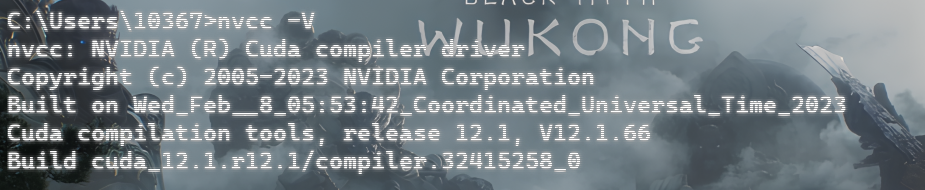
成功之后需要下载torch2.5.0的版本 下面是清华的镜像源++注意GPU++
bash
pip install torch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 --index-url https://download.pytorch.org/whl/cu121 --trusted-host download.pytorch.org --timeout 1000测试一下
bash
python -c "import torch; print(torch.__version__); print(torch.cuda.is_available())"
最后就是下载需要的transformers==4.51.3
bash
pip install transformers==4.51.3 -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com之后测试一下
bash
python -c "import transformers; print('transformers版本:', transformers.__version__)"输出

代码方面
针对于Bert输入首先要先进行分词处理
这段代码基于 Hugging Face 的transformers库,加载预训练的ModernBERT-base掩码语言模型(Masked Language Model,MLM),对包含[MASK]占位符的英文句子("The capital of china is MASK.")进行掩码词预测 (核心是还原被遮挡的单词,比如预测出[MASK]位置应该是Beijing),是 BERT 类模型最经典的基础任务之一。
python
from transformers import AutoTokenizer, AutoModelForMaskedLM
model_id = "answerdotai/ModernBERT-base"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForMaskedLM.from_pretrained(model_id)
text = "The capital of china is [MASK]."
print("input->>", text)
inputs = tokenizer(text, return_tensors="pt")
print("inputs:", inputs, inputs['input_ids'].shape)
outputs = model(**inputs)
# To get predictions for the mask:
masked_index = inputs["input_ids"][0].tolist().index(tokenizer.mask_token_id)
predicted_token_id = outputs.logits[0, masked_index].argmax(axis=-1)
predicted_token = tokenizer.decode(predicted_token_id)
print("Predicted token:", predicted_token)代码解析
python
# 1. 导入核心模块
from transformers import AutoTokenizer, AutoModelForMaskedLMAutoTokenizer:「自动分词器」,根据指定的模型自动匹配对应的分词规则,负责把人类可读的文本转换成模型能识别的数字序列(input_ids);AutoModelForMaskedLM:「自动掩码语言模型类」,专门适配 "掩码预测" 任务的预训练模型加载类,会自动加载对应模型的权重和结构,且输出适配掩码预测的 logits(原始预测分数)。
python
# 2. 定义要加载的预训练模型标识
model_id = "answerdotai/ModernBERT-base"model_id是 Hugging Face Hub 上的模型唯一标识,执行代码时会自动从 Hub 下载该模型的预训练权重和配置(首次运行需要下载,后续会缓存);ModernBERT-base是优化后的 BERT 基础版模型,效果和经典 BERT-base 接近。
python
# 3. 加载模型对应的分词器
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 4. 加载掩码语言模型
model = AutoModelForMaskedLM.from_pretrained(model_id)from_pretrained(model_id):从预训练权重加载,无需手动构建模型结构 / 分词规则,transformers 库会自动匹配;- 加载完成后,
tokenizer负责文本→数字的转换,model负责核心的预测计算。
python
# 5. 定义包含掩码的待预测文本
text = "The capital of china is [MASK]."
# 6. 打印输入文本,方便查看
print("input->>", text)[MASK]是 BERT 类模型的专用掩码标记,代表 "需要预测的位置",是掩码语言模型的核心输入特征。
python
# 7. 分词器处理文本,生成模型可接受的输入格式
inputs = tokenizer(text, return_tensors="pt")tokenizer(text):对文本进行分词、转 input_ids、生成 attention_mask 等;return_tensors="pt":指定返回PyTorch 张量(tensor)(因为装的是 PyTorch 版 transformers),如果是 TensorFlow 则用"tf";inputs是一个字典,核心包含 2 个键:input_ids:文本转换后的数字序列(每个词 / 子词对应一个唯一 ID);attention_mask:注意力掩码(标记哪些位置是有效文本,哪些是填充,模型只关注有效位置)。
python
# 8. 打印输入数据和input_ids的形状
print("inputs:", inputs, inputs['input_ids'].shape)inputs['input_ids'].shape:输出张量维度,比如torch.Size([1, 8]),其中:
1:批次大小(这里只有 1 个句子,所以是 1);8:序列长度(当前文本分词后有 8 个 token)。
python
# 9. 将输入传入模型,得到预测输出
outputs = model(**inputs)**inputs:把inputs字典解包成模型的输入参数(等价于model(input_ids=inputs['input_ids'], attention_mask=inputs['attention_mask']));outputs是模型的输出对象,核心包含logits(原始预测分数):logits的形状为[批次大小, 序列长度, 词汇表大小],每个位置对应词汇表中所有词的预测分数。
python
# 10. 找到[MASK]标记在input_ids中的位置
masked_index = inputs["input_ids"][0].tolist().index(tokenizer.mask_token_id)inputs["input_ids"][0]:取第一个批次(唯一的句子)的 input_ids;.tolist():把张量转成普通列表,方便查找索引;tokenizer.mask_token_id:[MASK]标记对应的数字 ID(比如 BERT 中是 103);index(...):找到[MASK]在序列中的索引位置(比如第 7 位)。
python
# 11. 从logits中取掩码位置分数最高的token ID
predicted_token_id = outputs.logits[0, masked_index].argmax(axis=-1)outputs.logits[0, masked_index]:取第一个批次、掩码位置的所有词汇预测分数;argmax(axis=-1):在词汇表维度取分数最大值对应的 ID(分数最高 = 模型最确定的预测结果)。
python
# 12. 将预测的token ID解码回文本
predicted_token = tokenizer.decode(predicted_token_id)
# 13. 打印预测结果
print("Predicted token:", predicted_token)tokenizer.decode(...):把数字 ID 转回人类可读的文本;- 预期输出:
Predicted token: Beijing(模型会预测出中国的首都是北京)
注意!!!初次运行大概率会保存

解决方式初始在终端运行,之后下载好相关模型就可以了
++SET HF_ENDPOINT=https://hf-mirror.com++

终端进入编译程序的文件,在终端跑起来
里面的主要内容是:基于 Hugging Face 的transformers库,加载经典的bert-base-uncased预训练模型,完成下一句预测(Next Sentence Prediction,NSP) 任务
bert_demo.py
源码如下
python
from transformers import BertTokenizer, BertForNextSentencePrediction
import torch
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertForNextSentencePrediction.from_pretrained('bert-base-uncased')
# tokens = tokenizer.tokenize("All work and no play makes Jack a dull boy!")
# print(tokens)
# sentence_a = "The weather is nice today."
# sentence_b = "I will go for a walk."
sentence_a = "The weather is nice today."
sentence_b = "The stock market crashed in 2008."
encoding = tokenizer.encode_plus(sentence_a, sentence_b, return_tensors='pt')
outputs = model(**encoding)
logits = outputs.logits
prob = torch.softmax(logits, dim=1)
is_next_prob = prob[0][0].item()
not_next_prob = prob[0][1].item()
if is_next_prob > not_next_prob:
print("Sentence B is likely to follow Sentence A (Is Next).")
print("Prediction: Is Next (Probability: %.2f)"%is_next_prob)
else:
print("Sentence B is NOT likely to follow Sentence A (Not Next).")
print("Prediction: Not Next (Probability: %.2f)" % not_next_prob)
它会自动下载