目录
[1. 列表初始化](#1. 列表初始化)
[1.1 C++98 支持](#1.1 C++98 支持)
[1.2 C++11 几乎对一切对象皆可用 {} 初始化](#1.2 C++11 几乎对一切对象皆可用 {} 初始化)
[1.3 initializer_list](#1.3 initializer_list)
[2. 右值引用和移动语义](#2. 右值引用和移动语义)
[2.1 左值和右值](#2.1 左值和右值)
[2.2 写法](#2.2 写法)
[2.3 左/右值参数匹配](#2.3 左/右值参数匹配)
[2.4 注意点](#2.4 注意点)
[2.5 用途](#2.5 用途)
[3. 引用折叠](#3. 引用折叠)
[3.1 多次引用](#3.1 多次引用)
[3.2 右值引用模板](#3.2 右值引用模板)
[4. 完美转发](#4. 完美转发)
[4.1 万能引用的缺陷](#4.1 万能引用的缺陷)
[4.2 万能引用和完美转发的应用](#4.2 万能引用和完美转发的应用)
[5. 可变模板参数](#5. 可变模板参数)
[5.1 可变参数](#5.1 可变参数)
[5.2 可变模板参数](#5.2 可变模板参数)
[5.3 本质](#5.3 本质)
[5.4 取出参数值](#5.4 取出参数值)
[6. Emplace_back](#6. Emplace_back)
[6.1 和 push_back 的区别](#6.1 和 push_back 的区别)
[7. Lambda 表达式](#7. Lambda 表达式)
[7.1 捕捉列表](#7.1 捕捉列表)
[7.2 原理](#7.2 原理)
[8. 类的新功能](#8. 类的新功能)
[9. 关键字](#9. 关键字)
[10. 包装器](#10. 包装器)
[10.1 普通实现](#10.1 普通实现)
[10.2 成员函数](#10.2 成员函数)
[10.3 使用](#10.3 使用)
[11. Bind](#11. Bind)
1. 列表初始化
1.1 C++98 支持
-
构造函数 :
date(int year = 1, int month = 1, int day = 1)-
int a = 2; -
date d3 = 2026; -
单参数构造函数支持隐式类型转换。
-
由于我们的
date类给了缺省值,因此date d3 = 2026可以看成是单参数构造。
-
1.2 C++11 几乎对一切对象皆可用 {} 初始化
-
单参数
-
int a = { 2 }; -
date d3 = { 2026 }; -
可以使用。
-
-
多参数
-
date d1 = { 2026, 1, 6 }; -
构造临时对象,再拷贝构造 -> 优化:直接构造。
-
const date& d2 = { 2026, 1, 6 }; -
常引用,直接构造。
-
可以去掉中间的赋值符号。
-
date d1{ 2026, 1, 6 }; -
因此,有两种写法:
-
date d1( 2026, 1, 6 );// C++98 就有的构造函数调用 -
date d1{ 2026, 1, 6 };// C++11 的{}初始化
-
-
1.3 initializer_list
-
vector<int> v = { 1, 2, 3, 4 }; -
vector是没有 4 个参数的构造函数的。 -
本质上是先
{ 1, 2, 3, 4 }构造出了一个initializer_list类型,再不断push_back进vector里。 -
auto il = { 1, 2, 3, 4 }; -
这样子,
il默认是initializer_list类型。 -
auto il = { 1, 2, 3, 4 }; -
int arr[] = { 1, 2, 3, 4 }; -
两个非常相似,并且地址接近,因此
initializer_list存在栈上。

-
三种写法:
-
vector<int> v0 = { 1, 2, 3, 4 }; -
vector<int> v1{ 1, 2, 3, 4 }; -
vector<int> v2({ 1, 2, 3, 4 });
-
-
V0:构造+拷贝构造,优化成构造。
-
V1:直接构造。
-
V2:构造临时对象+构造,优化成直接构造。
2. 右值引用和移动语义
2.1 左值和右值
-
s[0] = 'b'; -
int* p = new int(0); -
s[0]和*p为左值。 -
左值 :表示数据的表达式。
const左值不能赋值,但都能取地址。 -
右值:也是表示数据的表达式,都不能赋值,不能取地址(与左值的区别)。
-
常见右值:
-
10 -
x+y -
string("111") -
fmin(a, b)(传值返回的函数)
-
2.2 写法
-
int&& rr1 = 10; -
同样,
const引用也可以引用右值:const int& rr2 = 10; -
因此,函数用
const引用的传参既可以传左值也可以传右值。 -
右值引用也可以引用
move的左值。-
int b = 1; -
int&& rr1 = move(b);
-
-
右值引用变量(如
rr1)本身是左值,只能被左值引用。
2.3 左/右值参数匹配
-
C++98:用
const引用。cppvoid func(const int& a) { cout << "const左值" << endl; } -
C++11:左值引用、
const左值引用、右值引用可以构成重载,传到最匹配的函数。cppvoid func(int& a) { cout << "左值" << endl; } void func(const int& a) { cout << "const左值" << endl; } void func(int&& a) { cout << "右值" << endl; } -
func(a1); func(a3); -
func(a2); -
func(1);
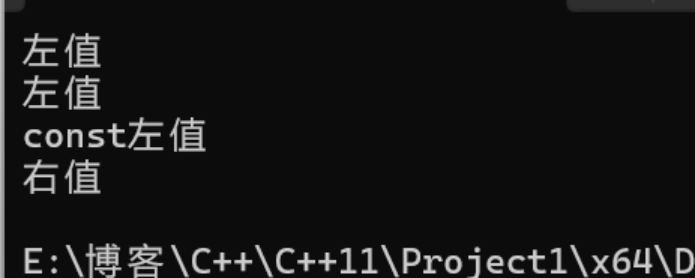
- 由于右值引用的参数
a3本身是左值,因此func(a3)匹配的是左值引用版本。
2.4 注意点
-
右值引用变量为左值
-
我们传右值引用的
s3过去是不会被错杀的,s3不会被swap,内容还在。 -
调用了普通的拷贝构造。


-
-
move左值对象构造-
string s1 = "asd"; -
string s2 = move(s1); -
当
s1加上move成为右值后,就会调用右值的构造,直接交换。 -
此时,
s1变为空。

- 因此,加上
move要慎重。
-
2.5 用途
-
延长声明周期
-
string s1 = "abc"; -
const string& ss1 = s1 + s1; -
string&& ss2 = s1 + s1; -
本来
s1+s1是个临时对象,声明周期就在一行。 -
但是被引用后声明周期就随着引用延长。
-
-
传引用返回析构问题
-
在函数中,传引用返回可以提高效率,但是一些时候无法传引用返回。
-
右值引用可以解决部分问题。
cppbit::string func() { bit::string s2 = "abc"; return s2; } bit::string ret = func();-
首先,在上面的函数中:
-
如果没有任何优化,那么会
s2构造临时对象,再拷贝构造给ret。 -
初步优化:省掉临时对象,直接
s2拷贝构造ret。 -
更加优化:
s2就是ret,不用构造(也是 vs2022 的做法)。
-
-
在这种情况下,传值返回没问题,会被优化得一次构造也不多。
-
但是,下面的情况就不行了:
-
bit::string ret; -
ret = func();
-
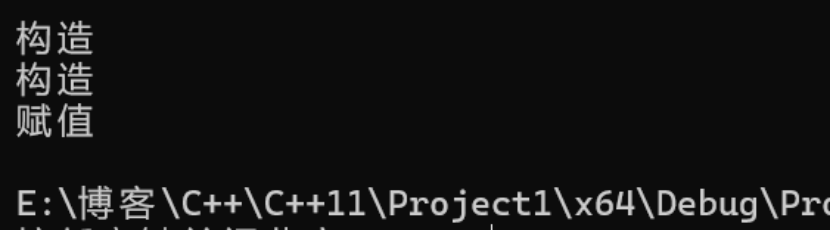
-
只会省掉临时对象,会让
s2对ret拷贝构造,浪费一次赋值。 -
但是,如果我们写了右值赋值和构造:
- 由于右值大多是临时变量,声明周期短,因此可以直接交换,因此拷贝、构造代价很低。
cppstring(string&& s) :_str(nullptr) , _size(0) , _capacity(0) { swap(s); cout << "右值" << endl; } string& operator=(string&& tmp) { swap(tmp); cout << "右值赋值" << endl; return *this; }

-
-
右值引用和编译器优化的结合
-
编译器优化和移动构造、赋值的目的都是优化程序。
-
但是,编译器优化是不可控的,而移动构造可控。
-
因此移动构造可以在编译器完全不优化的情况下让程序深拷贝减少。
-
在这时,编译器优化可以减少深拷贝的次数。
-
因此,两者相结合,编译器优化就变成了锦上添花而不是雪中送炭。
-
-
适用情况
-
但是,并不是所有的情况都必须移动赋值。
-
移动赋值对于深拷贝的类可以优化,但是对于如日期类、
pair<int,int>等,则优化不明显。 -
原因:
-
对象较小,拷贝开销小。
-
交换和拷贝代价一样。
-
-
在
string类等,交换指针比拷贝指针指向的所有内容快很多;但是对于日期类等,交换就是交换三个int,本身就是一种拷贝。
-
-
代码的优化(老旧编译器)
-
如果编译器较老,不支持移动构造,怎么优化?
cppstring addstring(string a, string b) { string r = a + b; return r; } string ret = addstring("111", "222"); -
方案 :可以将
ret作为参数,函数所有操作都直接对ret进行,减少拷贝。cppvoid addstring(string a, string b, string& r) { r = a + b; } string ret; addstring("111", "222", ret); -
但这样可读性较低。
-
-
右值类型
-
纯右值 :
42,str1+str2,普通的右值。 -
将亡值 :
move(x),(int&&)x,转换出来的右值。
-
-
总结:左值引用和右值引用的共同目的都是减少拷贝,提高效率。
- 左值引用还能修改参数和返回值,方便使用(如
[]的重载)。
- 左值引用还能修改参数和返回值,方便使用(如
3. 引用折叠
3.1 多次引用
-
首先,C++ 直接写
int& && a = b;会报错。 -
但是,在
typedef定义之后,就可以了。cpptypedef int& T1; typedef int&& T2; T1&& a = b; T2&& a2 = 1; -
但是,这样写会折叠掉一层。
-
规则:
-
T1 &,T1 &&,T2 &相当于&(左值引用)。 -
T2 &&相当于右值引用。 -
即:只要有
&就为左值,全为&&才为右值。
-
3.2 右值引用模板
-
左值模板
cpptemplate <class T> void func1(T& x) { }-
这个函数,无论用左值引用当模板还是右值引用当模板,都只能传左值。
-
因为它的模板里为
&,而上面说过,只要有&就为左值。cppint n = 1; func1<int&>(n); func1<int&&>(n);
-
-
右值模板
cpptemplate <class T> void func2(T&& x) { }-
这个时候,函数既能传左值也能传右值,传值全听模板的。
cppint n = 1; func2<int&>(n); func2<int&&>(1); -
并且也可以自动推导。
cppint n = 1; func2(n); // 推导为 int& func2(1); // 推导为 int&& const int cn = 1; func2(cn); // 推导为 const int& func2(move(cn)); // 推导为 const int&& -
因此,传什么会自动推导出来,这个就叫万能引用。
-
4. 完美转发
4.1 万能引用的缺陷
-
int p = 0; -
int& r = p; -
int&& r2 = 1; -
首先,不管左值还是右值,
r和r2本身都是左值(因为移动构造要交换右值里的数据,因此右值引用的变量本身是左值,这样才能合法地动它的数据)。 -
但,这就埋下了一个大坑。
-
这就导致在函数
func2里,x的值都被"洗白"成左值引用了 (int&),接下去就不能调用对应的函数进行优化了。cppvoid test(int& a) { cout << "普通左值引用" << endl; } void test(int&& a) { cout << "普通右值引用" << endl; } void test(const int& a) { cout << "const左值引用" << endl; } void test(const int&& a) { cout << "const右值引用" << endl; } template <class T> void func2(T&& x) { test(x); }
- 即无论
func2传什么,都无法调用右值引用的函数。
- 即无论
-
对于这个问题,就有了完美转发 ,即让下一个函数(
test函数)知道它是左值还是右值。cpp
template <class T> void func2(T&& x) { test(forward<T>(x)); }- 这样,编译器就知道这个东西是左值还是右值引用了。

4.2 万能引用和完美转发的应用
-
vector<string> v; -
string s1 = "222"; -
v.push_back("111"); -
v.push_back(s1); -
在 C++98 的语境下(没有移动构造),无论是尾插右值还是左值效率都一样,都需要构造+拷贝构造。
-
但是,如果有了移动构造,尾插
"111"的拷贝构造就可以调用移动构造,直接交换,提高效率。
移动构造的实现
-
重载
push_backcppvoid push_back(const T& val) { insert(end(), val); } void push_back(T&& val) { insert(end(), forward<T>(val)); }- 由于复用了
insert,所以需要forward<T>(val)转发。
- 由于复用了
-
构造
cpplist_node(const T& data = T()) :_data(data) , _next(nullptr) , _prev(nullptr) { } list_node(T&& data) :_data(data) , _next(nullptr) , _prev(nullptr) { } -
写法优化
-
由于
push_back等函数语句一模一样,只是传的类型不一样,因此就可以用模板。- 当传普通引用时会走默认构造,传右值时会走
forward<X>(data)构造。
- 当传普通引用时会走默认构造,传右值时会走
cpptemplate <class X> void push_back(X&& x) { // std::cout << typeid(X).name() << std::endl; insert(end(), forward<X>(x)); } list_node() = default; template <class X> list_node(X&& data) :_data(forward<X>(data)) , _next(nullptr) , _prev(nullptr) { } -
-
本质
-
但这么写,下面语句依旧没调用移动构造:
li.push_back("111");
-
原因 :由于
"111"是右值,类型是char*,而在代码中一路完美转发,给绿灯,因此char*就会调用string的char*构造,反而优化掉了一次移动构造。
-
5. 可变模板参数
5.1 可变参数
-
在
printf里就是参数的数量可变,我们传多个参数一样能打印。 -
这个本质是将参数放到一个数组中,再去遍历。
5.2 可变模板参数
-
C++11 支持函数以及模板的个数可变。
cpptemplate <class ...Args> void print(Args... args) { cout << sizeof...(args) << endl; }-
打印参数个数。
cppprint(); print(1); print("aaa", 1.2);
-
5.3 本质
-
由可变模板生成多个模板实例,再实例化出对应函数。
cppprint(); print(1); print("aaa", 1.2); -
过程:
-
实例化出 0、1、2 个参数的函数模板。
-
实例化出
print()、print(int)、print(char*, double)。
-
5.4 取出参数值
-
这里,要打印参数,只能通过类似于递归的形式。
cppvoid showlist() { } template <class T, class ...Args> void showlist(T x, Args&&... args) { cout << x << endl; showlist(args...); } template <class ...Args> void print(Args&&... args) { showlist(args...); } -
如果递归有递归出口,那么能否当参数 0 个时
return?cpptemplate <class T, class ...Args> void showlist(T x, Args&&... args) { if (sizeof...(args) == 0) return; cout << x << endl; showlist(args...); } template <class ...Args> void print(Args&&... args) { showlist(args...); } -
答案是不行,因为模板是编译时就确定的。
-
而编译时,编译器根本不会因为
return;这个运行时的指令而停止编译这个模板,这两者毫不相关。 -
或者用
getarg函数不断拿出参数。cpptemplate <class T> const T& getarg(const T& x) { cout << x << endl; return x; } template <class ...Args> void arguments(Args... args) { } template <class ...Args> void print(Args... args) { arguments(getarg(args)...); }-
print("aaa", 1.2, 3); -
在这个函数下,就相当于
arguments(getarg("aaa"), getarg(1.2), getarg(3)); -
最后再
arguments("aaa", 1.2, 3);传到空函数里。 -
因此
getarg函数可以瞎传值,但不能不传值。
-
6. Emplace_back
6.1 和 push_back 的区别
-
左值
cpplist<bit::string> li; bit::string s1 = "aaa"; li.push_back(s1); li.emplace_back(s1);
- 没有区别,都是拷贝构造。
-
右值
-
move的右值cppbit::string s1 = "aaa"; bit::string s2 = "aaa"; // li.push_back(s1); // li.emplace_back(s1); li.push_back(move(s1)); li.emplace_back(move(s1));- 同样没区别,都是移动构造。
-
字符串
li.push_back("aaa"); li.emplace_back("aaa");
-
此时有细微的差别。
-
push_back走了构造 + 移动赋值。 -
emplace_back仅走了构造。 -
原因 :
push_back是写死必须要传string的,因此我们传的char*就会遇上"红灯",走构造函数,转为string再向上传。
-
而
emplace_back则是一直保持着模板:class ... Args再不断复用函数,完美转发,一路绿灯。 -
因此到最后直接构造函数构造。
- 但是两者效率都很高。
-
-
-
类类型
cpplist<pair<bit::string, int>> li; li.push_back({ "a", 1 }); li.emplace_back("b", 2);-
由于
push_back只支持一个参数,因此要用{}框起来,先转为pair类型。 -
而
emplace_back支持多个参数,因此不能{}框起来,否则就是一个参数了。

-
此时和刚才一样,
string的自定义类在push_back走了构造+移动,在emplace_back走了构造,直接构造到list的里面。 -
而对于
int这样的浅拷贝类型,则需要多拷贝一次。 -
要是浅拷贝类型比较大,或者我们的自定义类型没有移动赋值,那么
emplace_back的效率则会高一些。
-
7. Lambda 表达式
-
匿名函数,可定义在函数内部。
-
[ ]捕捉列表,( )参数列表,->返回值类型,{ }函数体。 -
相加表达式:
cpp
auto add = [](int x, int y) -> int { return x + y; };
7.1 捕捉列表
-
Lambda 表达式要使用外面的变量需要捕捉,放到
[ ]里。cppauto mul = [n1, n2]() { return n1 * n2; }; -
n1为传值捕捉,不能修改原值(如++),n2为传引用捕捉,可以修改原值。 -
如果
[ ]里就写=就传值所有变量,&就传引用所有变量。 -
[&, a, b]就代表其它变量传引用,就a、b传值。
7.2 原理
-
编译器自动生成一个仿函数,捕获列表即为成员变量。
-
所以:
cppauto add = [](int x, int y) { return x + y; }; struct add2 { int operator()(const int& a, const int& b) const { return a + b; } }; -
两个本质上相同。
8. 类的新功能
-
类的 6 个默认成员函数变为 8 个(构造、析构、拷贝构造、赋值重载、取地址、
const取地址、移动构造 、移动赋值)。 -
移动构造自动生成规则:没有移动构造、析构、拷贝构造、赋值重载这四个时。
- 生成的移动拷贝:内置类型浅拷贝,自定义类型调用移动构造,没有的话调用拷贝构造。
-
强制生成移动构造后,拷贝构造就不会生成。
9. 关键字
-
default和delete-
Default:强制生成函数。 -
Delete:不期望被拷贝。person(const person& p) = delete;// 删除拷贝构造函数
-
如
iostream等需要避免拷贝(拷贝了,缓冲区就会乱)。
-
10. 包装器
10.1 普通实现
cpp
int add(int x, int y) {
return x + y;
}
function<int(int, int)> f1 = add;- 需要参数、返回值匹配。
10.2 成员函数
cpp
struct mul {
int _a; int _b;
mul(int a, int b)
:_a(a)
,_b(b) { }
int multi(int c) {
return _a * _b * c;
}
};
function<int(mul*, int)> f2 = &mul::multi;-
需要写
this指针,并且函数要指定类域,写上取地址符。 -
function<int(mul, int)> f2 = &mul::multi; -
f2(mul(1, 2), 2);// 或者使用匿名对象
10.3 使用
cpp
map<string, function<int(int, int)>> ma = {
{ "+", [](int x, int y) { return x + y; } },
{ "-", [](int x, int y) { return x - y; } },
{ "*", [](int x, int y) { return x * y; } },
{ "/", [](int x, int y) { return x / y; } }
};map可以存包装器,包装lambda,这样就可以提高运算效率,更加简洁。
11. Bind
-
调整参数的个数、顺序。
cppusing namespace std::placeholders; // using placeholders::_1; // using placeholders::_2; // using placeholders::_3; int func(int a, int b, int c) { return (a - b) * c; } auto f1 = bind(func, 2, _1, _2); cout << f1(1, 5) << endl; -
当函数有参数不用时,就可以用
bind把它绑定,调用新函数。 -
上文,可以将包装器的
this指针绑死。cppfunction<int(mul, int)> f2 = &mul::multi; auto f3 = bind(f2, mul(1, 2), _1);