一、 为什么需要分词器?
想象一下,你要教一个刚来地球的外星人学中文。你直接扔给他一整本《红楼梦》,他肯定会崩溃。更合理的方法是,先教他认识单个的汉字、词语,再理解句子。
对于计算机而言,我们就是那个"外星人"。它只认识数字(0和1)。分词器的核心任务,就是完成文本 → 数字 的关键转换,具体分为三步:
- 切分:将一串连续的文本,切分成有意义的片段(称为"词元"或Token)。
- 映射:为每一个词元,在预先定义的"词典"(词表)里找到一个唯一的ID编号。
- 向量化:最终,一个句子就变成了一串数字ID序列,输入给模型处理。
例如:句子 "我爱自然语言处理!" 可能被切分和映射为:[2593, 4261, 3200, 4892, 3156, 102]
二、 核心挑战:如何"切"才是最好的?
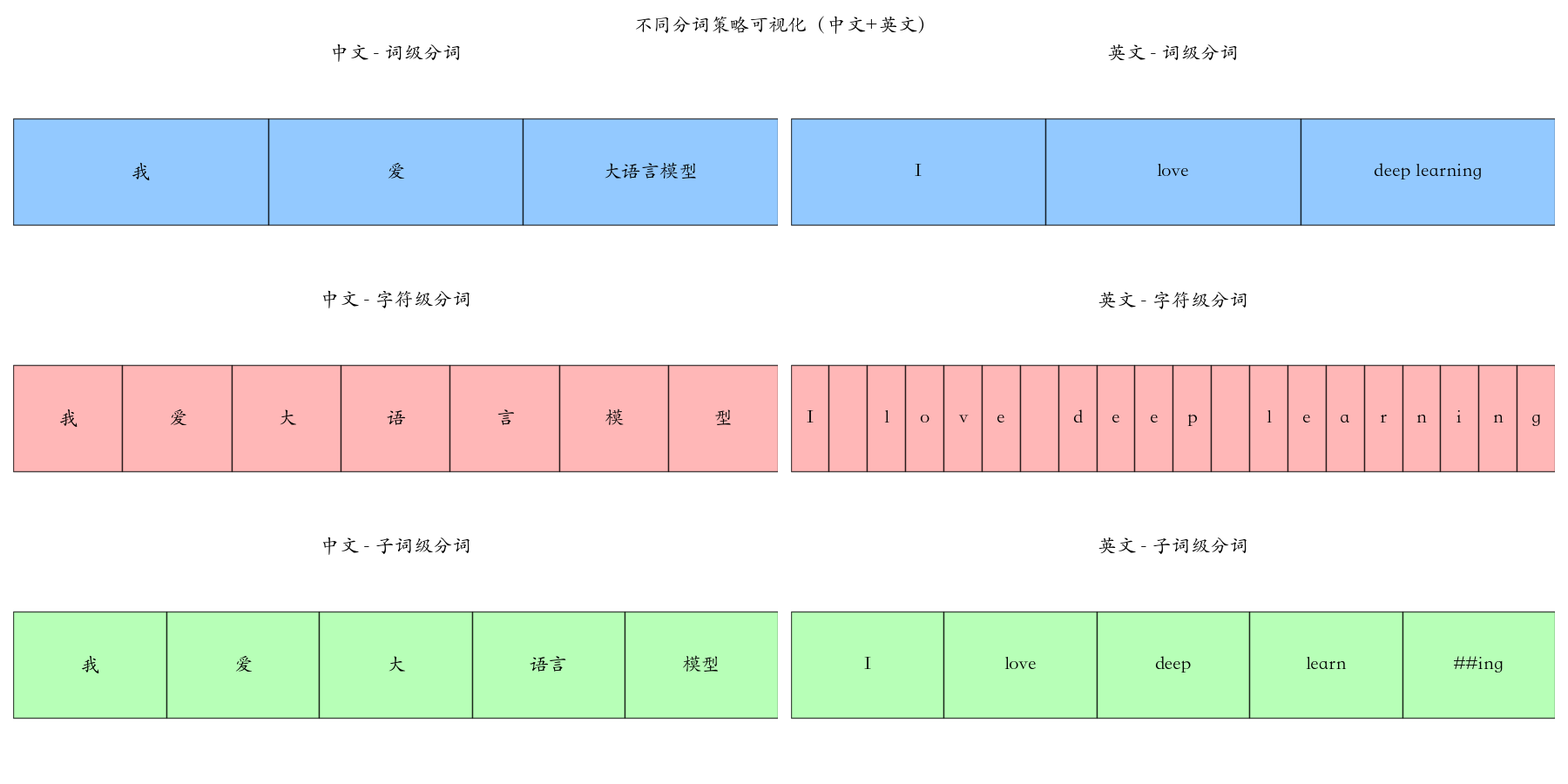
分词的"刀法"没有绝对的对错,核心是在词表大小、语义粒度和泛化能力三者间找到最佳平衡。
2.1 词级分词:依赖一本永远不全的"词典"
该方法试图将文本切分为语言中完整的"词",高度依赖一个预先定义的庞大词典。核心问题:词典的完备性与管理复杂性之间存在根本矛盾。
- 原文:
我爱大语言模型。 - 理想分词:
["我", "爱", "大语言模型", "。"] - 困境 :词典需收录所有可能出现的词(从"人工智能"到"蚌埠住了"),导致词表极度膨胀(可达十万甚至百万级),且永远无法覆盖新出现的词汇(未登录词问题,OOV)。遇到词典没有的词,系统便会失效。
- 原文:
I love deep learning. - 理想分词:
["I", "love", "deep learning", "."] - 困境 :英文丰富的词形变化(如
run/runs/running)会进一步加剧词表膨胀,同样难以处理像"unhate"或"ChatGPTing"这样的新造词。
2.2 字符级分词:回归原点,但过于细碎
此法绕开"词"的定义,直接将文本拆解为最小单元------字符。核心问题:切分过于细碎,语义信息破碎。模型需要从零学习字符如何组合成有意义的词,训练难度和计算成本高。
- 原文:
我爱大语言模型。 - 分词结果:
["我", "爱", "大", "语", "言", "模", "型", "。"] - 特点 :词表极小(几千汉字),理论上能处理任何文本,泛化能力极强。
- 原文:
I love deep learning. - 分词结果:
["I", " ", "l", "o", "v", "e", " ", "d", "e", "e", "p", " ", "l", "e", "a", "r", "n", "i", "n", "g", "."] - 特点:词表极小(数十个字符),但序列长度会变得非常长。
2.3 子词分词:现代大模型的黄金标准("乐高积木"法)
此法取二者之长,将单词拆分为有意义的、可重复使用的子词片段 。常用词保持原样,生僻词则被拆解。核心优势 :子词分词以其平衡之道,用适中的词表有效避免了词级分词的"词典爆炸"和字符级分词的"语义破碎",成为当今大语言模型的基石。
- 原文:
我爱大语言模型。 - 可能的分词结果:
["我", "爱", "大", "语言", "模型", "。"] - 智慧所在 :高频稳定组合(如"语言"、"模型")作为整体保留,常用语素(如"大")独立存在。当遇到新词"多模态大模型"时,可利用已知片段
"多"、"模态"、"大"、"模型"来理解和处理。
- 原文:
I love deep learning. - 可能的分词结果:
["I", "love", "deep", "learn", "##ing", "."] - 智慧所在 :
- 高效复用 :词根
"learn"可用于构建"learns","learned","learner"等一系列相关词汇。 - 强大泛化 :遇到
"unsleeping"这类新词,可分解为已知片段["un", "sleep", "##ing"]来推理其含义。
- 高效复用 :词根
三、主流分词算法------BPE:从字符到子词构建
Byte Pair Encoding,常被称作BPE,其核心思想非常直观且巧妙:从最基础的字符开始,像玩拼图一样,反复合并文本中出现频率最高的"字符对",从而逐步构建出一个由常见片段组成的子词词表。
3.1 BPE 的工作原理:四步构建词表
BPE的训练是一个离线的、迭代的过程,其目标是基于一个大型文本语料库,自动"学习"并生成一个固定大小的子词词表。整个过程可以清晰地分为以下四个步骤:
第1步:初始化 - 拆分到底层
将语料库中每一个单词都拆解成最基础的组成单元(字符),并在每个单词末尾添加一个特殊的结束符(如 </w>),用以标记单词边界。例如:
"low"->["l", "o", "w", "</w>"]"lower"->["l", "o", "w", "e", "r", "</w>"]"newest"->["n", "e", "w", "e", "s", "t", "</w>"]"widest"->["w", "i", "d", "e", "s", "t", "</w>"]
第2步:统计与合并
扫描整个语料库,统计所有相邻符号对 出现的频率。然后,将出现频率最高的那个符号对 合并成一个新的符号,并加入到词表中。假设统计发现,"e" 和 "s" 这个组合出现的次数最多(在 "newest" 和 "widest" 中都出现了)。
- 执行合并:
"e" + "s"->"es" - 更新分词结果:
"newest"->["n", "e", "w", "es", "t", "</w>"]"widest"->["w", "i", "d", "es", "t", "</w>"]
第3步:迭代 - 循环此过程
重复第2步 。在下一轮,系统可能会发现 "es" 和 "t" 经常连在一起,于是将它们合并为 "est"。然后再下一轮,可能将 "l" 和 "o" 合并为 "lo",以此类推。后续迭代示例:
- 合并
"es"和"t"->"est" - 合并
"l"和"o"->"lo" - 合并
"lo"和"w"->"low"
第4步:停止
当合并进行到一定轮数,子词词表的大小增长到我们预先设定的目标值(例如 50,000)时,算法停止。最终,我们获得了一个包含常见字符、子词和完整单词的混合词表。
3.2 编码与解码:如何使用BPE词表
编码(分词) :当有新句子需要处理时,我们使用训练好的BPE词表进行分词。过程是"最长匹配优先":从左到右扫描单词,尽可能匹配词表中最长的子词单元。使用上述学到的词表对 "lowest" 分词:
- 首先匹配最长的已知子词
"low"。 - 剩下
"est",正好也是词表中的子词。 - 因此,
"lowest"被分词为["low", "est", "</w>"]。
解码 :将分词后的序列(如 ["low", "est", "</w>"])直接拼接起来,并去掉单词结束符,即可恢复原始单词 "lowest"。
BPE算法对不同语言的处理方式是一致的,魅力在于其普适性。
- 对于一个未登录词,如
"ChatGPTing",BPE可能基于常见片段将其切分为["Chat", "G", "PT", "ing"]。模型因为认识表示进行时的后缀"ing",从而能推断出这是一个与"ChatGPT"相关的进行中动作。 - BPE处理中文时,通常以单个汉字字符 为初始单元。
- 训练过程 :在大量语料中,如果"语"和"言"频繁相邻出现,它们就会被合并为子词
"语言"。"模"和"型"同理。 - 分词结果 :因此,
"大语言模型"很可能被切分为["大", "语言", "模型"],而非单个汉字。
- 训练过程 :在大量语料中,如果"语"和"言"频繁相邻出现,它们就会被合并为子词
3.3 简单 BPE 代码
python
from collections import defaultdict, Counter
class SimpleBPE:
def __init__(self, vocab_size=1000):
self.vocab_size = vocab_size
self.vocab = {}
self.merges = {}
self.inverse_vocab = {}
def train(self, corpus):
word_freqs = Counter()
splits = {}
for sentence in corpus:
words = sentence.lower().split()
for word in words:
word_freqs[word] += 1
splits[word] = list(word) + ['</w>']
chars = set()
for word in word_freqs.keys():
for char in word:
chars.add(char)
chars.add('</w>')
self.vocab = {char: idx for idx, char in enumerate(sorted(chars))}
self.merges = {}
while len(self.vocab) < self.vocab_size:
pair_freqs = defaultdict(int)
for word, split in splits.items():
freq = word_freqs[word]
for i in range(len(split) - 1):
pair = (split[i], split[i + 1])
pair_freqs[pair] += freq
if not pair_freqs:
break
best_pair = max(pair_freqs, key=pair_freqs.get)
new_token = best_pair[0] + best_pair[1]
self.vocab[new_token] = len(self.vocab)
self.merges[best_pair] = new_token
for word in splits:
split = splits[word]
i = 0
new_split = []
while i < len(split):
if i < len(split) - 1 and split[i] == best_pair[0] and split[i + 1] == best_pair[1]:
new_split.append(new_token)
i += 2
else:
new_split.append(split[i])
i += 1
splits[word] = new_split
self.inverse_vocab = {v: k for k, v in self.vocab.items()}
return self
def encode(self, text):
words = text.lower().split()
tokens = []
for word in words:
split = list(word) + ['</w>']
changed = True
while changed and len(split) > 1:
changed = False
for (a, b), merged in self.merges.items():
i = 0
new_split = []
while i < len(split):
if i < len(split) - 1 and split[i] == a and split[i + 1] == b:
new_split.append(merged)
i += 2
changed = True
else:
new_split.append(split[i])
i += 1
if changed:
split = new_split
break
for token in split:
if token in self.vocab:
tokens.append(self.vocab[token])
return tokens
def decode(self, token_ids):
tokens = [self.inverse_vocab[token_id] for token_id in token_ids]
text = ''
for token in tokens:
if token == '</w>':
text += ' '
else:
text += token
return text.strip()
# 训练语料
corpus = [
"low low low low lower",
"newest newest newest",
"widest widest widest",
"wider wider wider"
]
# 创建并训练分词器
bpe = SimpleBPE(vocab_size=30)
bpe.train(corpus)
# 查看词表
print("词表大小:", len(bpe.vocab))
print("前10个词元:", list(bpe.vocab.keys())[:10])
# 编码测试
text = "lowest lower"
tokens = bpe.encode(text)
print(f"文本: '{text}'")
print(f"Token IDs: {tokens}")
print(f"词元: {[bpe.inverse_vocab[id] for id in tokens]}")
# 解码测试
decoded = bpe.decode(tokens)
print(f"解码: '{decoded}'")
python
词表大小: 27
前10个词元: ['</w>', 'd', 'e', 'i', 'l', 'n', 'o', 'r', 's', 't']
文本: 'lowest lower'
Token IDs: [17, 13, 26]
词元: ['low', 'est</w>', 'lower</w>']
解码: 'lowest</w>lower</w>'四、WordPiece:基于概率的子词合并算法
4.1 算法原理:从频率到概率的优化
WordPiece是BERT、ALBERT等Transformer模型使用的分词算法。虽然训练流程与BPE相似(初始化、统计合并、迭代、停止),但在决定"合并哪个字符对"的关键决策上,WordPiece采用了更智能的策略。
- BPE逻辑:合并出现频率最高的字符对
- WordPiece逻辑:合并能最大程度提升语言模型概率的字符对
WordPiece通过一个简单的分数公式,衡量了两个字符一起出现的"实际频率"与它们"如果独立随机出现"的期望频率之比。比值越高,说明这两个字符的"绑定关系"越强。
合并分数=字符对出现频率第一个字符频率×第二个字符频率\text{合并分数} = \frac{\text{字符对出现频率}}{\text{第一个字符频率} \times \text{第二个字符频率}}合并分数=第一个字符频率×第二个字符频率字符对出现频率
示例:
假设字符"e"单独出现100次,字符"s"单独出现80次,字符对"e"+"s"一起出现60次,那么合并分数 = 60 / (100 × 80) = 0.0075。如果另一个字符对"p"+"l"的分数是0.01,那么WordPiece会优先合并"p"和"l",而不是频率更高的"e"和"s"。
4.2 编码解码与##前缀
WordPiece使用特殊标记来区分子词的位置:无前缀表示单词的开头部分,##前缀表示单词的中间或结尾部分。例如:
"playing"→["play", "##ing"]"unhappily"→["un", "##happy", "##ly"]
这种标记方式有两个重要优势:解码时可以准确知道哪些片段应该直接拼接,同时"##ing"这样的后缀明确表示了进行时等语法功能。
编码过程采用"最长匹配优先"策略:从左到右扫描单词,尽可能匹配词表中最长的子词单元。例如对于"unplaying",先匹配"un",再匹配"play",最后匹配"##ing"。解码则直接拼接所有片段并去除##前缀即可。
4.3 中英文处理示例
在英文处理中,WordPiece倾向于保持常见的词根和后缀关系。例如"natural language processing"可能被分词为["natural", "language", "process", "##ing"],将"processing"拆分为"process"+"##ing"。
处理中文时,WordPiece通常以单个汉字为初始单元,但合并策略依然基于概率分数。例如在训练过程中,如果"语"和"言"频繁共现,它们会被合并为子词"语言"。因此"我爱自然语言处理"可能被切分为["我", "爱", "自然", "语言", "处理"],而不是单个汉字。需要注意的是,中文WordPiece通常不使用##前缀。
4.4 使用预训练的BERT分词器(WordPiece)
python
from transformers import BertTokenizer
# 加载分词器
english_tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
chinese_tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
# 测试用例
test_cases = [
# (语言, 描述, 文本)
("en", "常见英文单词", "I love natural language processing!"),
("cn", "常见中文短语", "我爱自然语言处理"),
("en", "复杂英文单词", "The unhappily embeddings are unbelievably tokenized."),
("cn", "中文长句", "昨天我参加了人工智能研讨会,收获颇丰"),
("en", "专业术语", "Electroencephalography is a complex word."),
("cn", "专业术语", "深度学习模型需要大量训练数据"),
("mix", "混合文本", "我使用Python和TensorFlow进行AI开发"),
]
for lang, desc, text in test_cases:
if lang == "en":
tokenizer = english_tokenizer
elif lang == "cn":
tokenizer = chinese_tokenizer
else:
tokenizer = chinese_tokenizer # 混合文本用中文分词器
tokens = tokenizer.tokenize(text)
print(f"\n[{desc}]")
print(f"原文: {text}")
print(f"分词: {tokens}")
print(f"词元数: {len(tokens)}")
python
[常见英文单词]
原文: I love natural language processing!
分词: ['i', 'love', 'natural', 'language', 'processing', '!']
词元数: 6
[常见中文短语]
原文: 我爱自然语言处理
分词: ['我', '爱', '自', '然', '语', '言', '处', '理']
词元数: 8
[复杂英文单词]
原文: The unhappily embeddings are unbelievably tokenized.
分词: ['the', 'un', '##ha', '##pp', '##ily', 'em', '##bed', '##ding', '##s', 'are', 'un', '##bel', '##ie', '##va', '##bly', 'token', '##ized', '.']
词元数: 18
[中文长句]
原文: 昨天我参加了人工智能研讨会,收获颇丰
分词: ['昨', '天', '我', '参', '加', '了', '人', '工', '智', '能', '研', '讨', '会', ',', '收', '获', '颇', '丰']
词元数: 18
[专业术语]
原文: Electroencephalography is a complex word.
分词: ['electro', '##ence', '##pha', '##log', '##raphy', 'is', 'a', 'complex', 'word', '.']
词元数: 10
[专业术语]
原文: 深度学习模型需要大量训练数据
分词: ['深', '度', '学', '习', '模', '型', '需', '要', '大', '量', '训', '练', '数', '据']
词元数: 14
[混合文本]
原文: 我使用Python和TensorFlow进行AI开发
分词: ['我', '使', '用', '[UNK]', '和', '[UNK]', '进', '行', '[UNK]', '开', '发']
词元数: 11五、Unigram Language Model:基于概率的"自顶向下"分词法
Unigram Language Model(ULM)采用了一种与BPE和WordPiece截然不同的思路。如果说BPE是"从下往上"的拼图游戏,那么Unigram就是"从上往下"的精雕细琢。
5.1 核心理念:从大到小的优化
Unigram算法的设计思路与BPE完全相反:
- BPE/WordPiece策略:从单个字符开始,逐步合并成更大的子词(自底向上)
- Unigram策略:从一个庞大的初始词表开始,逐步删除最不重要的子词(自顶向下)
想象一下雕刻的过程:BPE是从一块块小石头开始堆砌雕像,而Unigram是从一块完整的大理石开始,凿去多余的部分,最终留下最精华的形态。
5.2 工作原理:概率驱动的"精挑细选"
Unigram的核心是最大化训练数据的整体概率。它通过一个迭代优化的过程,找到最优的词表组合。
5.2.1 概率计算公式
对于任意一个分词结果S=(x1,x2,...,xm)S = (x₁, x₂, ..., xₘ)S=(x1,x2,...,xm),Unigram计算其出现的概率为:
P(S)=∏iP(xi)P(S) = ∏ᵢ P(xᵢ)P(S)=i∏P(xi)
其中:
- P(xi)P(xᵢ)P(xi)表示子词xixᵢxi在整个训练语料中出现的概率
- ∏∏∏表示连乘,即所有子词概率的乘积
5.2.2 训练过程的三个关键步骤
第一步:初始化大词表
Unigram从一个"臃肿"的初始词表开始,初始词表可能包含数万甚至数十万个候选子词。通常包含:
- 所有单个字符(如"a"、"b"、"c"...)
- 高频的2-gram、3-gram组合(如"th"、"ing"、"tion")
- 常见的完整单词(如"the"、"and"、"language")
第二步:概率估计与优化
使用期望最大化(EM)算法进行迭代优化:
- 假设当前词表已知,计算训练数据的所有可能分词方式
- 根据这些分词统计结果,更新每个子词的概率估计
- 重复这个过程,直到概率分布稳定
第三步:逐步剪枝
这是Unigram最关键的步骤------反向删除:
- 计算删除词表中每个子词会导致的"概率损失"
- 删除那个"损失最小"的子词(即最不重要的子词)
- 重复此过程,直到词表大小达到预设值
5.3 示例
示例1:中文分词
假设Unigram的词表包含以下候选子词:
["自然", "语言", "处理", "自然语言", "语言处理", "自", "然", "语", "言", "处", "理"]
对于句子"自然语言处理",Unigram会评估各种可能的分词方式及其概率:
-
分词方案A:"自然", "语言", "处理"
- 概率计算:P("自然") × P("语言") × P("处理") = 0.4
-
分词方案B:"自然语言", "处理"
- 概率计算:P("自然语言") × P("处理") = 0.3
-
分词方案C:"自", "然", "语", "言", "处", "理"
- 概率计算:P("自") × P("然") × P("语") × P("言") × P("处") × P("理") = 0.001
Unigram会选择概率最高的分词方案A:"自然", "语言", "处理"。
示例2:英文分词
假设词表包含:
["un", "happy", "##ly", "unhappy", "happily", "h", "a", "p", "y", "i", "l"]
对于单词"unhappily",可能的切分包括:
- "un", "happy", "##ly" → 概率:0.5
- "unhappy", "##ly" → 概率:0.3
- "u", "n", "h", "a", "p", "p", "i", "l", "y" → 概率:接近0
Unigram会选择概率最高的第一种切分。
六、SentencePiece:统一多语言分词的开源利器
6.1 多语言分词的统一方案
SentencePiece 是 Google 开发的语言无关、端到端分词工具包,核心优势是将文本视为原始 Unicode 字节流,不依赖语言特定预处理规则(如空格分隔),可统一处理中、英、日、韩等多语言及混合文本。
其核心设计逻辑分为两层:
- 算法层面:通过两种核心算法从原始文本中学习有意义的子词片段------默认的 Unigram Language Model(基于概率自顶向下剪枝)、BPE(基于频率自底向上合并),无需提前定义分词规则;
- 空格处理层面 :将空格视为普通字符(通常表示为
▁),例如"Hello world"会先转为"Hello▁world"再分词,既实现了多语言处理逻辑的统一,又能清晰标记单词边界,解码时仅需将▁替换回空格即可。
6.2 使用示例
从运行结果可直观看到 SentencePiece 多语言分词的核心特征,以及实际使用中需注意的细节:
- 多语言处理的统一性
无论中文、英文、日文或混合文本,SentencePiece 均以▁标记空格(如英文▁Python、中文▁满),实现了无语言差别的统一分词逻辑------这也是其核心优势,无需为不同语言定制预处理规则。 - 分词粒度与算法特性
- 示例中设置
model_type='unigram'(SentencePiece 默认算法),该算法基于概率自顶向下剪枝,核心特点是优先保留高频基础单元,对低频长组合做细粒度拆分。 - 英文高频基础词汇(如
language)能保持整体,但低频长词(如programming)会拆分为p+r+o+g+r+a+m+m+i+ng; - 中文/日文因低频组合较多(如"方便""機械学習"),多拆分为单字/短片段,数字"100"也被拆为"1+0+0",这是 Unigram 算法"优先保证基础字符覆盖"的典型表现。
-
未知词(unk)的出现与原因
解码结果中的
⁇对应未知词标记(unk_id=3),如"解答问题""核心技術""词策略"均被标记为 unk,核心原因是:这些低频组合未出现在训练语料中,模型词汇表未收录,因此无法映射为有效 ID,仅子词解码可还原完整文本(子词保留原始字符),ID 解码因 unk 出现信息缺失。 -
关键配置的作用
character_coverage=1.0:确保中日英所有字符被覆盖,未出现字符丢失;hard_vocab_limit=False:兼容语料规模与 vocab_size(300)的匹配,避免训练报错;- 若需优化低频组合拆分/unk 问题,可将
model_type改为bpe(基于频率自底向上合并,更易形成中文词组/数字组合),或扩充训练语料中目标组合的出现频率。
python
import os
import tempfile
import sentencepiece as spm
train_corpus = [
"Hello world 你好世界 こんにちは世界",
"I love coding 我爱编程 プログラミングが好きです",
"Machine learning is interesting 机器学习很有趣 機械学習は面白いです",
"Data analysis is important 数据分析很重要 データ分析は重要です",
"Python is a great language Python是很棒的语言 Pythonは素晴らしい言語です",
"SentencePiece handles multiple languages SentencePiece处理多语言 SentencePieceは多言語に対応しています",
"Natural language processing 自然语言处理 自然言語処理は難しいです",
"AI changes the world AI改变世界 AIは世界を変えます",
"Coding is fun 写代码很有趣 コーディングは楽しいです",
"Deep learning is popular 深度学习很流行 ディープラーニングは人気があります",
"LLM is a large language model 大语言模型是大型语言模型 LLMは大規模言語モデルです",
"GPU accelerates model training GPU加速模型训练 GPUはモデルトレーニングを加速します",
"Data mining extracts valuable information 数据挖掘提取有价值信息 データマイニングは価値のある情報を抽出します",
"Cloud computing is convenient 云计算很便捷 クラウドコンピューティングは便利です",
"Algorithm optimization improves efficiency 算法优化提升效率 アルゴリズムの最適化は効率を向上させます",
"This product is on sale 这个商品正在打折 この商品はセール中です",
"Free shipping for orders over 100 yuan 满100元免运费 100元以上の注文は送料無料です",
"Customer service is online 客服在线 カスタマーサービスはオンラインです",
"Drinking more water is healthy 多喝水有益健康 水をたくさん飲むと健康に良いです",
"Exercise every day keeps fit 每天锻炼保持身材 毎日運動すると体型を維持できます",
"Reading books enriches knowledge 读书丰富知识 本を読むと知識が豊かになります"
]
with tempfile.NamedTemporaryFile(mode='w', delete=False, encoding='utf-8') as temp_f:
temp_f.write('\n'.join(train_corpus))
temp_file_path = temp_f.name
spm.SentencePieceTrainer.train(
input=temp_file_path,
model_prefix='mymodel',
vocab_size=300,
model_type='unigram',
character_coverage=1.0, # 多语言场景必须保持1.0,不能降低
pad_id=0, bos_id=1, eos_id=2, unk_id=3,
hard_vocab_limit=False # 兼容自动调整(冗余空间)
)
os.unlink(temp_file_path)
sp = spm.SentencePieceProcessor()
sp.load('mymodel.model')
# 定义多组测试用例
test_cases = [
"SentencePiece 处理多语言文本很方便 プログラミングが楽しい", # 混合文本
"大语言模型的分词策略很重要 LLM分词效率高", # 纯中+英文缩写
"Python is the best programming language", # 纯英文
"データ分析と機械学習はAIの核心技術です", # 纯日文
"满100元免运费 客服在线解答问题" # 电商场景中文
]
# 遍历测试用例
for i, test_text in enumerate(test_cases, 1):
print(f"\n========== 测试用例 {i} ==========")
tokens = sp.encode(test_text, out_type=str)
token_ids = sp.encode(test_text, out_type=int)
decoded_from_tokens = sp.decode(tokens)
decoded_from_ids = sp.decode(token_ids)
# 打印结果
print("原始测试文本:", test_text)
print("分词结果(子词):", tokens)
print("分词结果(ID):", token_ids)
print("从子词解码:", decoded_from_tokens)
print("从ID解码:", decoded_from_ids)
python
========== 测试用例 1 ==========
原始测试文本: SentencePiece 处理多语言文本很方便 プログラミングが楽しい
分词结果(子词): ['▁SentencePiece', '▁', '处理', '多', '语言', '文', '本', '很', '方', '便', '▁', 'プ', 'ロ', 'グ', 'ラ', 'ミ', 'ン', 'グ', 'が', '楽', 'しい']
分词结果(ID): [48, 4, 100, 49, 45, 131, 133, 36, 3, 78, 4, 93, 168, 111, 39, 165, 44, 111, 46, 208, 54]
从子词解码: SentencePiece 处理多语言文本很方便 プログラミングが楽しい
从ID解码: SentencePiece 处理多语言文本很 ⁇ 便 プログラミングが楽しい
========== 测试用例 2 ==========
原始测试文本: 大语言模型的分词策略很重要 LLM分词效率高
分词结果(子词): ['▁', '大', '语言', '模', '型', '的', '分', '词策略', '很', '重', '要', '▁LLM', '分', '词', '效', '率', '高']
分词结果(ID): [4, 50, 45, 112, 71, 218, 274, 3, 36, 261, 263, 86, 274, 3, 202, 82, 3]
从子词解码: 大语言模型的分词策略很重要 LLM分词效率高
从ID解码: 大语言模型的分 ⁇ 很重要 LLM分 ⁇ 效率 ⁇
========== 测试用例 3 ==========
原始测试文本: Python is the best programming language
分词结果(子词): ['▁Python', '▁', 'is', '▁', 'th', 'e', '▁', 'b', 'es', 't', '▁', 'p', 'r', 'o', 'g', 'r', 'a', 'm', 'm', 'i', 'ng', '▁language']
分词结果(ID): [47, 4, 9, 4, 56, 18, 4, 85, 29, 299, 4, 60, 31, 41, 30, 31, 20, 59, 59, 12, 11, 35]
从子词解码: Python is the best programming language
从ID解码: Python is the best programming language
========== 测试用例 4 ==========
原始测试文本: データ分析と機械学習はAIの核心技術です
分词结果(子词): ['▁', 'デ', 'ー', 'タ', '分析', 'と', '機', '械', '学', '習', 'は', 'A', 'I', 'の', '核心技術', 'で', 'す']
分词结果(ID): [4, 295, 19, 281, 97, 118, 209, 206, 188, 224, 7, 293, 113, 32, 3, 6, 5]
从子词解码: データ分析と機械学習はAIの核心技術です
从ID解码: データ分析と機械学習はAIの ⁇ です
========== 测试用例 5 ==========
原始测试文本: 满100元免运费 客服在线解答问题
分词结果(子词): ['▁', '满', '1', '0', '0', '元', '免', '运', '费', '▁', '客', '服', '在', '线', '解答问题']
分词结果(ID): [4, 250, 287, 296, 296, 96, 177, 232, 230, 4, 189, 203, 99, 221, 3]
从子词解码: 满100元免运费 客服在线解答问题
从ID解码: 满100元免运费 客服在线 ⁇