最近学习了一下Blackwell相关的架构,本文整理一下,最大的感受是看到GPU越来越NPU。首先约定一下后续的符号,假设TensorCore处理的D = A x B + D,A和B为bf16,D为fp32。
TMEM
Blackwell中引入了Tensor Memory供TensorCore进行读写,简称为TMEM,是一块片上内存,大小为256KB,和RMEM大小一致,之前RMEM作为TensorCore输入输出的场景都换成了TMEM,也就是说TensorCore不再依赖RMEM,RMEM可以完全交给cuda core,这样cuda core和TensorCore的并行度更好,另外因为减少了TensorCore的读写端口,RMEM设计上可能也会简单一些。
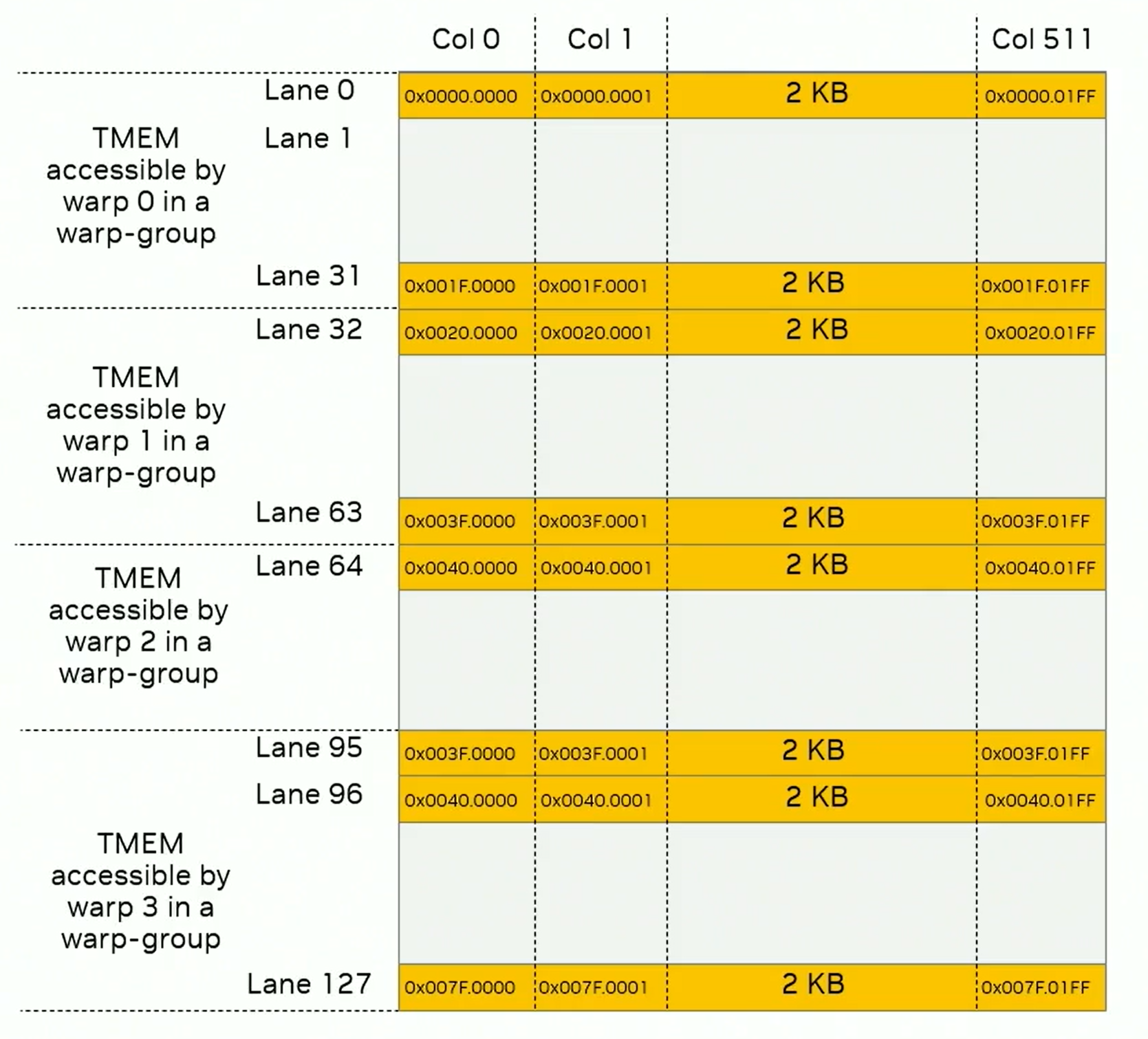
图 1
如图1所示,TMEM为二维,一共128行(官方称为lane),512列,每个cell为4B。TMEM的地址为32位,低16位表示col,高16为表示lane。warp的访问pattern受到限制,一个SM的TMEM需要一个warp group才可以完整访问,每个warp只能访问32 lane。
allocation
TMEM的alloc是动态的,以列为单位,因此一次alloc会分配这些列对应的128 lane。alloc和dealloc必须是以一个单独warp粒度的执行,并且分配和释放需要为同一个warp。
cpp
tcgen05.alloc.cta_group.sync.aligned{.shared::cta}.b32 [dst], nCols;
.cta_group = { .cta_group::1, .cta_group::2 }nCols即这次要求的列数,最小为32,必须为2的幂次,如果空间不足这里会阻塞,分配成功后得到的TMEM地址会写入到SMEM dst的位置,cta_group下边再介绍。
数据拷贝
与TMEM的数据拷贝主要通过tcgen05.ld,tcgen05.st,tcgen05.cp。其中ld将数据从TMEM拷贝到寄存器,st将数据从寄存器拷贝到TMEM,cp将数据从SMEM拷贝到TMEM。接下来我们主要关注ld。
cpp
tcgen05.ld.sync.aligned.shape1.num{.pack}.b32 r, [taddr];
.shape1 = { .16x64b, .16x128b, .16x256b, .32x32b }
.num = { .x1, .x2, .x4, .x8, .x16, .x32, .x64, .x128 }tcgen05.ld是一个warp粒度同步执行的指令,taddr为TMEM的基地址,warp中所有线程必须指定同样的基地址。ld支持多种格式的拷贝,由shape1和num指定,.num表示shape1在列方向上被重复执行的次数。
shape1格式为lanes x bits,以.32x32b为例,就是32lane,每个lane load 32b,如图2,展示了.32x32b,.num为x1和x2的场景。
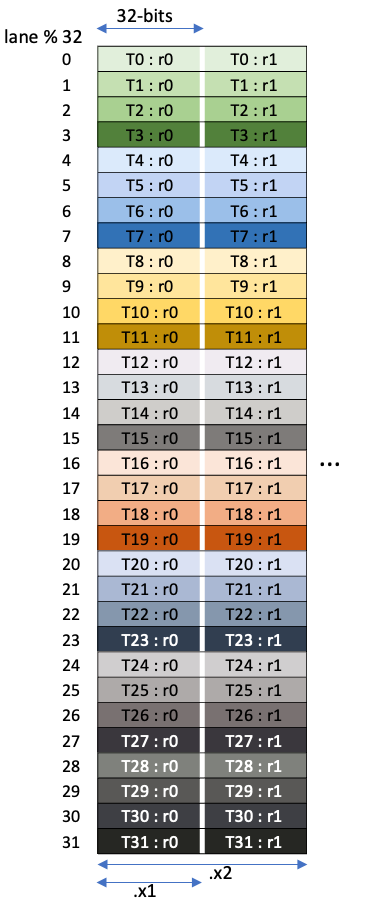
图 2
UMMA
Blackwell引入了第五代TensorCore,即PTX中的tcgen05相关指令。Hopper中的wgmma为sm_90a,因此Blackwell架构中无法使用,需要重新开发。后续将tcgen05.mma简称为umma。
由于Hopper的输出是在RMEM,因此需要warp group同步发起wgmma。但是对于umma,A可以在TMEM或者SMEM,B必须在SMEM,C必须在TMEM。因为不再依赖RMEM,所以umma为单线程发射指令,不会再导致warpgroup粒度的同步,相比于Hopper的M64,Blackwell单SM最大支持的M为128,K仍然还是32B,N还是8到256。对于数据类型,还支持fp4,fp6;支持2-SM的umma;另外还原生支持block scaling,不再依赖cuda core。
1-SM
cpp
tcgen05.mma.cta_group.kind [d-tmem], a-desc, b-desc, idesc,
{ disable-output-lane }, enable-input-d {, scale-input-d};
.kind = { .kind::f16, .kind::tf32, .kind::f8f6f4 }
.cta_group = { .cta_group::1, .cta_group::2 }d-tmem表示输出到TMEM的地址,a-desc和b-desc就是上一篇介绍过的descriptor,记录了SA和SB的地址,LBO,SBO,swizzle等信息,用于TensorCore的访问,这里不再赘述。idesc为32位,表示指令的descriptor,如下所示,记录了A,B和D的type和shape,是否transpose等信息。
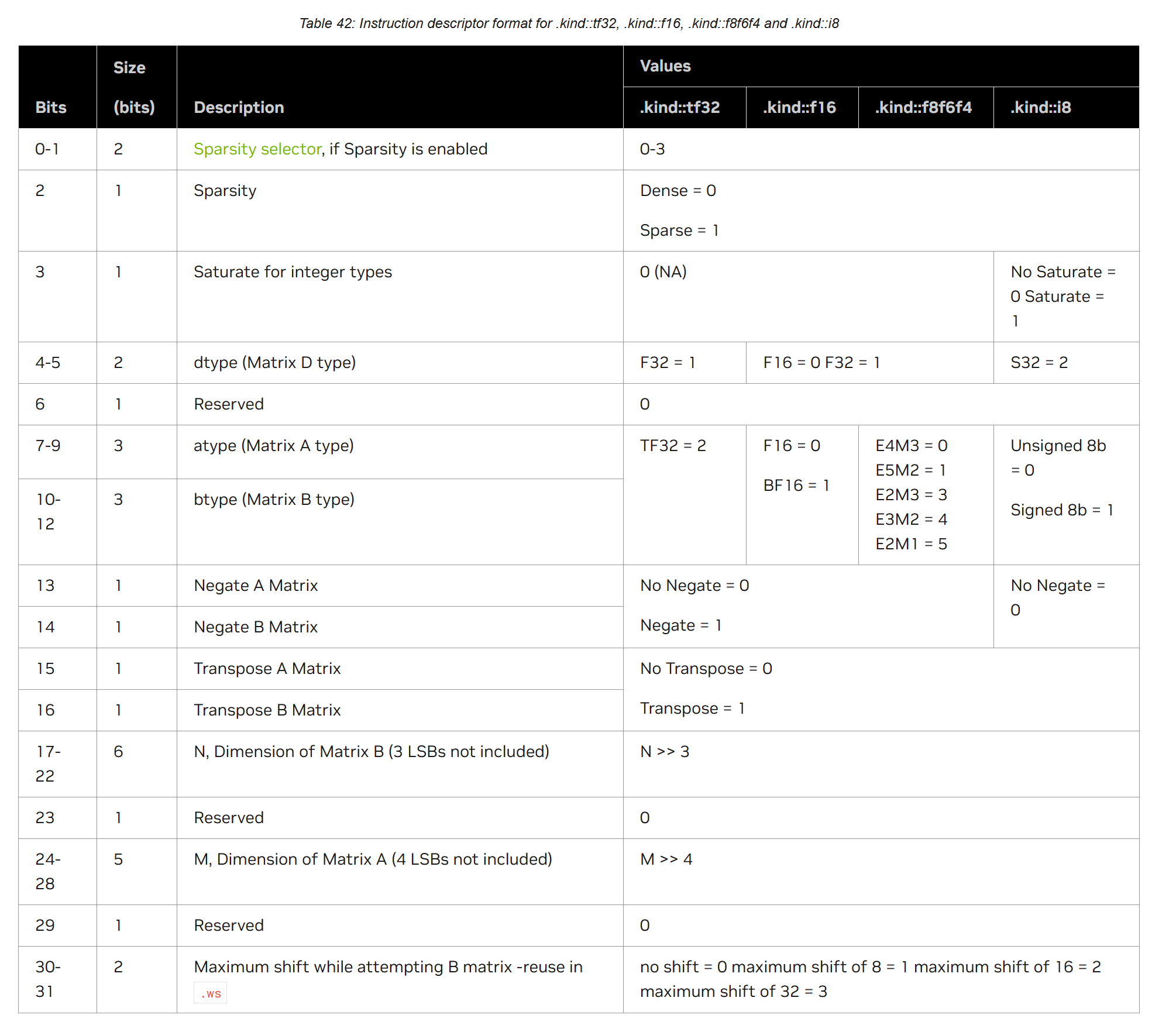
图 3
1-SM场景下cta_group只设置为.cta_group::1,表示单个sm执行一次umma。
enable-input-d表示是否执行累加,设为false的话表示执行D = A x B。
umma的完成使用的是mbarrier机制,如下:
cpp
tcgen05.commit.cta_group.completion_mechanism{.shared::cluster}{.multicast}.b64
[mbar] {, ctaMask};
.completion_mechanism = { .mbarrier::arrive::one }
.cta_group = { .cta_group::1, .cta_group::2 }
.multicast = { .multicast::cluster }tcgen05.commit将前序所有的tcgen05异步指令关联到mbar指定的mbarrier,当这些异步指令完成后,会通过completion_mechanism通知mbarrier,completion_mechanism为.mbarrier::arrive::one,表示一旦完成,会在mbar上触发一个arrive的操作,值为1;multicast::cluster和TMA的multicast一样,对mbarrier的notify可以被广播到由ctaMask指定的cluster内部的其他CTA,这个notify会广播到每个CTA中和mbar偏移相同的地址。
umma执行的结果D以行优先的方式存到TMEM,根据不同的配置输出有不同的格式,以cta_group::1,M 128 为例,输出格式如图4所示,每个warp访问自己对应的32行。
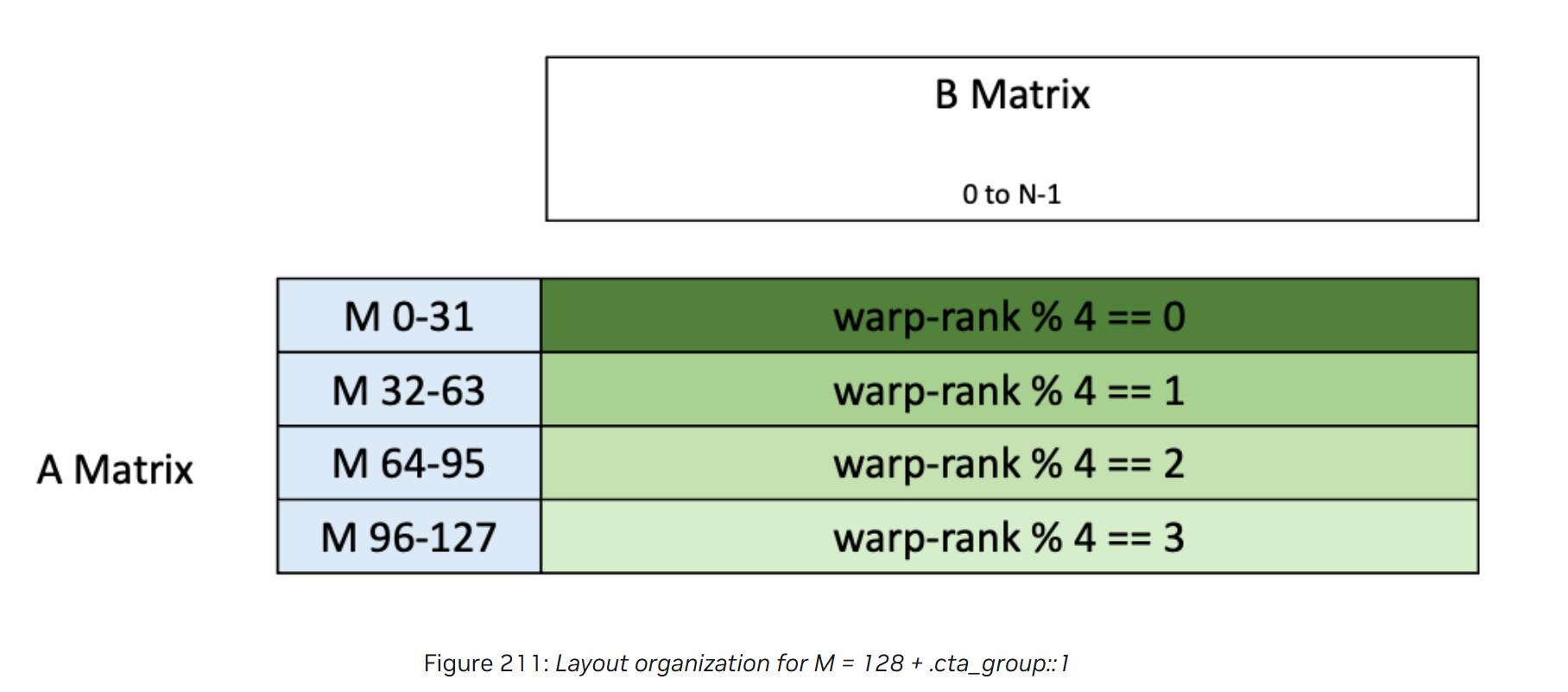
图 4
执行.ld的时候每个warp的地址如图5所示:

图 5
2-SM(CTA Pair)
随着算力的快速提升,瓶颈成为HBM的带宽,因此从Hopper开始gpu kernel的层级引入了cluster的概念,一个cluster会保证同时调度到同一个GPC内部,可以利用到GPC内部的SM to SM Network执行高效的通信和同步,比如在上一章中介绍的TMA的multicast,可以利用cluster内部的广播减少HBM的带宽。到了Blackwell,进一步引入了2-SM的umma,即一个CTA pair协作完成一个umma。
在一个cluster内部,可以通过cluster_ctarank得到当前CTA在cluster中的rank,如果有两个CTA的rank只有最后一位有diff,那么这两个CTA称为CTA pair。在一个CTA pair内部,cluster_ctarank最后一位是0的称为CTA pair内部的偶数CTA,为1的称为奇数CTA。前文有说umma的最大M为128,如果在CTA pair场景,M可以支持到256。
如果Hopper架构下执行M256N256K16,需要两个CTA,每个CTA保存128x16的SA和16x256的SB,而在Blackwell场景,如图6所示,SB在CTA pair上分布式存储,每个CTA存储一半,这样首先可以节省SMEM的存储,可以使用更深的流水线,另外还可以节省SM的带宽。
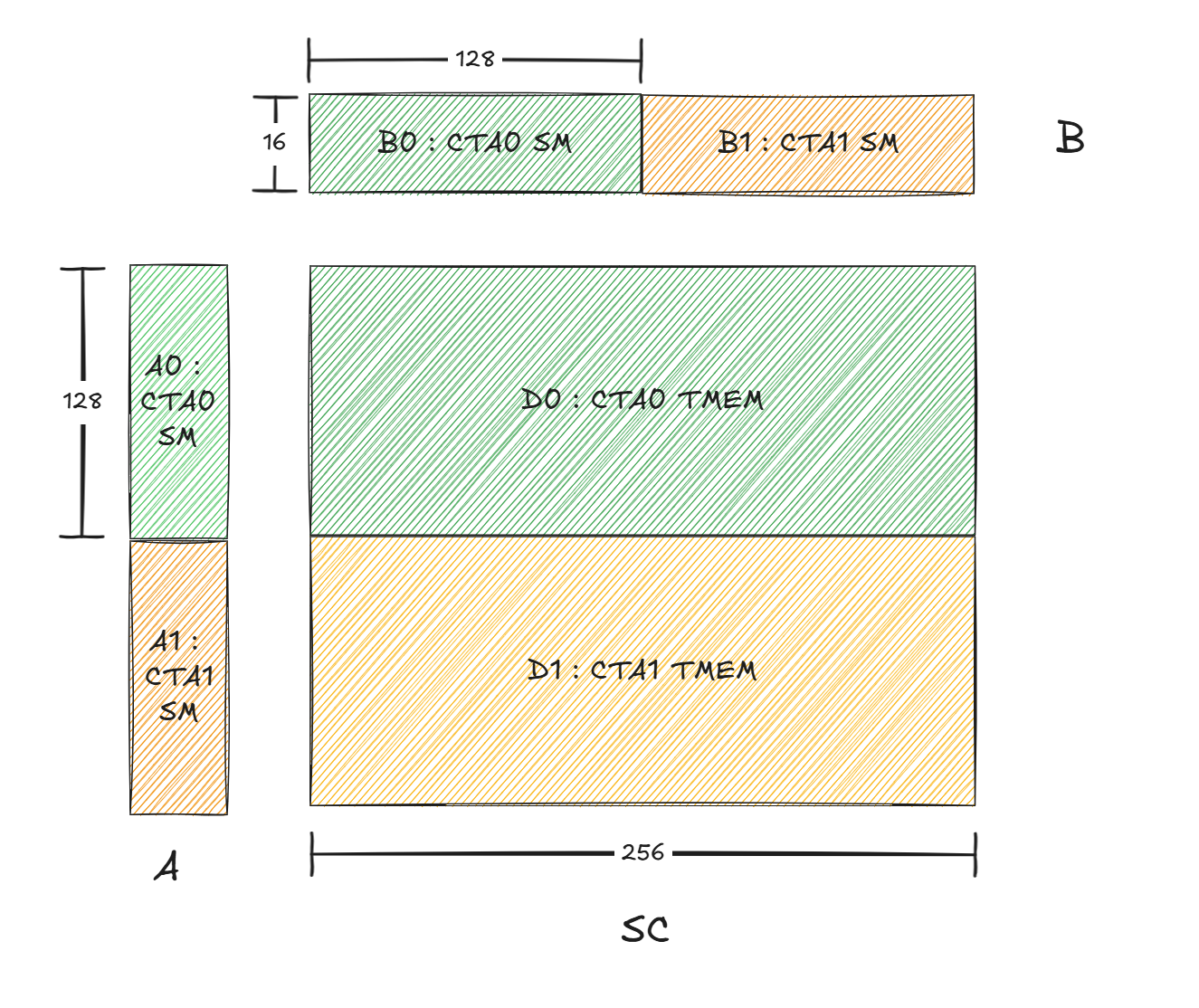
图 6
这时再回到之前说的mma和commit指令中的cta_group,.cta_group::1表示mma由单CTA执行,.cta_group::2表示mma由CTA pair执行,commit中的cta_group设置需要和mma一致,一个kernel中的cta_group只能有一个值,要么全是.cta_group::1,要么全是.cta_group::2。
此时对于TMEM的分配,也需要指定.cta_group::2,1-SM场景下,TMEM的分配由一个warp执行,在CTA pair场景下,分配变为两个warp,CTA pair中每个CTA需要一个warp执行alloc。
此时输出如图7所示:

图 7
通过tcgen05.ld访问TMEM的地址如图8所示
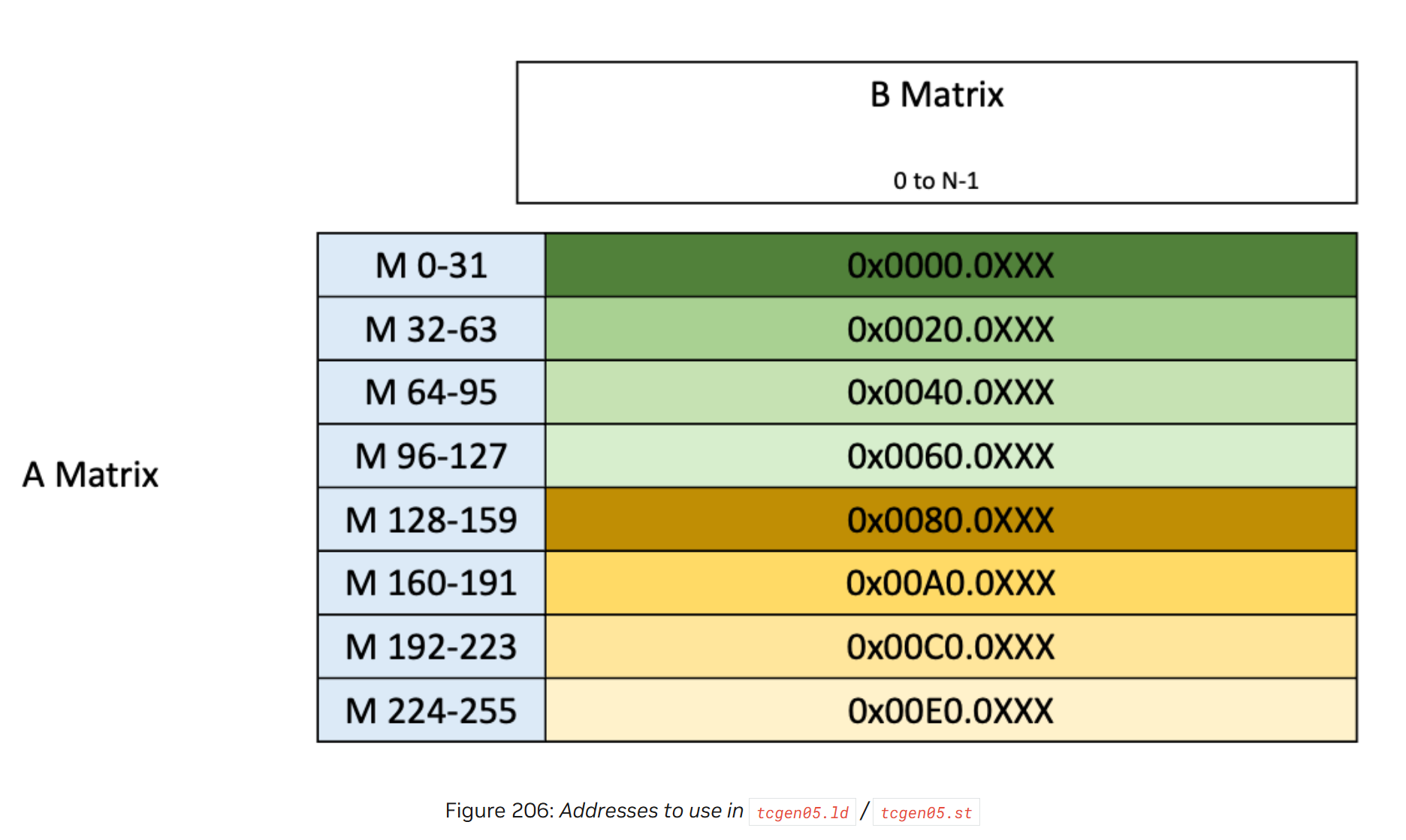
图 8
CTA pair的场景下执行一个Gemm流程如图9所示,假设一个cluster中只有两个CTA,不需要multicast。
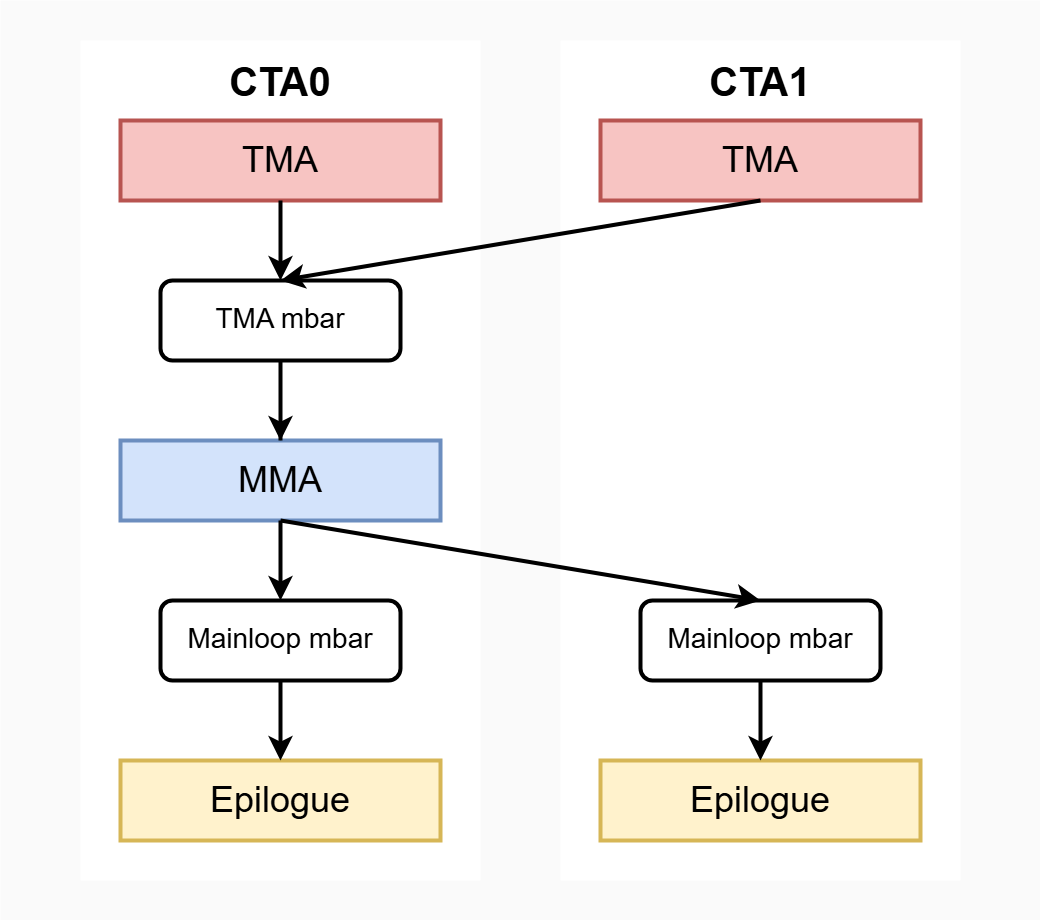
图 9
CTA0执行对A0和B0的TMA,CTA1执行对A1和B1的TMA,由于通过CTA0的线程执行umma,因此这两个TMA都需要通知位于CTA0的TMA mbar,TMA完成之后才能执行umma;当CTA0执行完成umma后,还要分别通知CTA0和CTA1的Mainloop mbar,umma完成之后才能执行Epilogue。
然后我们看下如何执行这两次跨CTA的通知。
回顾一下之前Hopper中介绍的TMA multicast,当时只介绍了用到的.cta_group::1,这次我们看下.cta_group::2的场景。
cpp
// global -> shared::cluster
cp.async.bulk.tensor.dim.dst.src{.load_mode}.completion_mechanism{.multicast}{.cta_group}{.level::cache_hint}
[dstMem], [tensorMap, tensorCoords], [mbar]{, im2colInfo}
{, ctaMask} {, cache-policy}
.dst = { .shared::cluster }
.src = { .global }
.dim = { .1d, .2d, .3d, .4d, .5d }
.completion_mechanism = { .mbarrier::complete_tx::bytes }
.cta_group = { .cta_group::1, .cta_group::2 }
.load_mode = { .tile, .tile::gather4, .im2col, .im2col::w, .im2col::w::128 }
.level::cache_hint = { .L2::cache_hint }
.multicast = { .multicast::cluster }cta_group默认为cta_group::1,表示广播mbarrier的信号到所有的dst CTA,对于开启multicast的场景,mbarrier信号会被广播到ctaMask指定的dst CTA,对于当前不开启multicast的场景,dst CTA就是自己这个CTA。当指定了cta_group::2,那么就会根据mbar的地址,将mbarrier的信号广播到ctaMask指定的dst CTA所在的CTA pairs中对应的奇偶CTA。
这句话很绕,我们看下当前这个具体场景,由于没有开启multicast,如果CTA0的TMA指定的TMA mbar位于CTA0,根据刚刚的规则,dst CTA就是CTA0,dst CTA对应的CTA pairs为CTA0和CTA1,由于mbar位于CTA0,那么就会通知偶数CTA,即CTA0,符合我们的需求;对于CTA1的TMA,指定的也是CTA0的TMA mbar,根据刚刚的规则,dst CTA为CTA1,dst CTA对应的CTA pairs为CTA0和CTA1,由于mbar位于CTA0,那么就会通知偶数CTA,即CTA0,符合我们的需求,这样就做到了两个CTA的TMA都通知CTA0的mbar。
代码如下所示:
cpp
template <int CTA_GROUP = 1>
__device__ inline
void tma_3d_gmem2smem(int dst, const void *tmap_ptr, int x, int y, int z, int mbar_addr) {
asm volatile("cp.async.bulk.tensor.3d.shared::cluster.global.mbarrier::complete_tx::bytes.cta_group::%6 "
"[%0], [%1, {%2, %3, %4}], [%5];"
:: "r"(dst), "l"(tmap_ptr), "r"(x), "r"(y), "r"(z), "r"(mbar_addr), "n"(CTA_GROUP)
: "memory");
}
const int mbar_addr = (tma_mbar_addr + stage_id * 8) & 0xFEFFFFFF;
tma_3d_gmem2smem<CTA_GROUP>(A_smem, &A_tmap, 0, off_m, off_k / 64, mbar_addr);
tma_3d_gmem2smem<CTA_GROUP>(B_smem, &B_tmap, 0, off_n + cta_rank * (BLOCK_N / CTA_GROUP), off_k / 64, mbar_addr);还有一个细节,这里找mbar_addr正常来讲需要通过mapa计算,但是这里cute的技巧是通过直接& 0xFEFFFFFF,这里可以看出cluster中SMEM的编址方式,0xFEFFFFFF的第24位为0,即对应了CTA0,因此cluster的SMEM应该是统一编址,通过低位的地址加高位的CTA id组成,CTA id从第24位开始,低位的地址就是PTX中一直强调的offset,TMA完成后,通过mbar的低位地址加上ctaMask,就可以对所有CTA的位于相同offset的mbar进行信号的广播。
CTA Pair + multicast
可以使用CTA pair + multicast的方法进一步减小访存,如图10所示,一个cluster有16个CTA,0,1组成CTA pair,同理2,3,4,5等,umma的执行由leader CTA执行,即偶数CTA。
A和B中的标号表示这块显存由谁来执行TMA,以CTA0的视角为例,CTA0 load A0然后multicast到CTA4,load B0然后multicast到CTA2,同理对于其他的CTA。
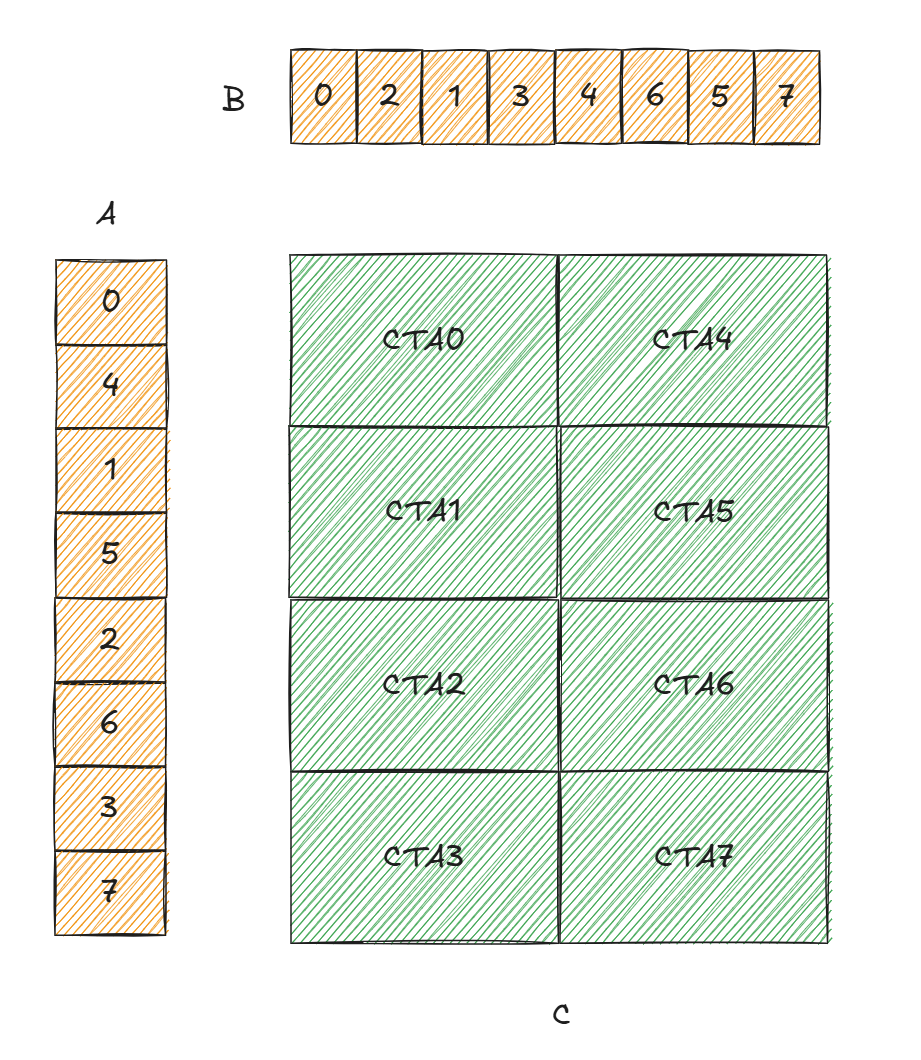
图 10
再来以图10为例看下TMA的cta_group对于开启multicast的行为,cta_group还是默认为1,通过ctaMask指定dst CTA,当cta_group为1的时候,mbarrier的通知信号也会广播到ctaMask对应的每个CTA。当cta_group为2,则根据指定的mbarrier的地址,即在奇数CTA还是偶数CTA,然后比那里ctaMask对应的所有CTA,找到他们所在的CTA pair,然后通知这些CTA pair中的奇数或偶数CTA。 比如对于CTA1,需要load B1,然后multicast到CTA5,因此ctaMask指定1和5,mbarrier指定的地址位于CTA0,因此是偶数CTA,然后根据ctaMask找到所有的CTA pair,即0,1和4,5,偶数CTA为0和4,因此mbarrier信号被广播到0和4。
内存模型
传统的generic proxy访问通过syncthreads等指令就可以保证对SMEM的访存可见性,因为syncthreads隐含了fence,但是由于TMA是async proxy,普通对generic proxy的fence指令保证不了TMA的可见行,因此引入了proxy fence系列指令。同样的,因为引入了tcgen05,个人感觉类比一个新的proxy,因此之前的proxy fence,mbarrier等指令都无法保证可见性了,因此需要新的方法保证可见性。
tcgen05指令分为同步和异步,如.cp,.mma,.ld,.st,这些tcgen05的指令是异步的,默认和同一线程中其他的tcgen05指令不保序(除非组成pipeline)。但是像wait,alloc等指令是同步的,这些默认是保序的。
pipeline
前边有说,tcgen05的异步指令默认不保序,除非形成pipeline,pipeline就是一些指令的组合,形成pipeline的两个指令可以保证执行的顺序就是发射的顺序,如下所示
cpp
tcgen05.mma.cta_group::N -> tcgen05.mma.cta_group::N (same N and accumulator and shape)
tcgen05.copy.cta_group::N -> tcgen05.mma.cta_group::N (same N)
tcgen05.shift.cta_group::N -> tcgen05.mma.cta_group::N (same N)
tcgen05.shift.cta_group::N -> tcgen05.cp.4x256b.cta_group::N (same N)
tcgen05.mma.cta_group::N -> tcgen05.shift.cta_group::N (same N)除了上述的指令组合之外还有一些指令之间会隐式的形成pipeline:
基于mbarrier的隐式pipeline
tcgen05.mma / tcgen05.cp / tcgen05.shift会和后续的tcgen05.commit形成隐式pipiline,如下所示,并且这些指令组合的完成需要使用mbarrier机制。
cpp
tcgen05.mma.cta_group::N -> tcgen05.commit.cta_group::N (same N)
tcgen05.cp.cta_group::N -> tcgen05.commit.cta_group::N (same N)
tcgen05.shift.cta_group::N -> tcgen05.commit.cta_group::N (same N)基于tcgen05.wait的隐式pipeline
除了mbarrier之外,tcgen05.ld / tcgen05.st和tcgen05.wait也会形成隐式pipeline,完成需要由tcgen05.wait机制保证,如下:
cpp
tcgen05.ld -> tcgen05.wait::ld
tcgen05.st -> tcgen05.wait::st线程内和线程间的tcgen05指令执行顺序(可见性)
接下来介绍tcgen05.fence指令,PTX原文中对fence的定位是跨线程同步,不过相同线程内部也有场景同样需要fence,因此个人这里写的是保证线程内和线程间的order。
PTX引入了execution ordering instructions概念,比如morally strong的ld / st,barrier,mbarrier等用于建立运行时执行顺序的指令,使用tcgen05.fence配合execution ordering instructions可以建立线程内和线程间的order。
这里个人理解还是前文的表述,tcgen05类比一个新的proxy。类似TMA引入的async proxy,如果希望syncthreads可以保证async proxy的可见性,必须在syncthreads之前执行proxy fence。那么一样的,为了使得原有的barrier,mbarrier等指令还可以保证tcgen05指令执行的顺序,必须配合tcgen05.fence(类比proxy fence)。
tcgen05.fence有两个:
- tcgen05.fence::before_thread_sync:before_thread_sync指令之前的异步tcgen05指令 的执行顺序一定在before_thread_sync指令之后的tcgen05和execution ordering instructions之前,类比release语义。
- tcgen05.fence::after_thread_sync:after_thread_sync指令之后的tcgen05指令 的执行顺序一定在after_thread_sync指令之前的tcgen05和execution ordering instructions之后,类比acquire语义。
场景
然后看下不同场景如何通过上述指令保证执行顺序。
单线程,pipeline
单线程内如果形成了pipeline,那么不需要额外的操作就可以保证执行顺序,如下
cpp
// example 1
tcgen05.mma
tcgen05.mma (same shape and accumulator)单线程,非pipeline
如果没有形成pipeline指令,那么需要显式的wait机制。
cpp
// example 2
tcgen05.st
tcgen05.wait::st
tcgen05.ldtcgen05.st和tcgen05.ld不是pipeline指令组合,因此需要显式的执行tcgen05.wait::st保证前序的tcgen05.st完成。
再看下边这个例子,由于tcgen05.mma和tcgen05.ld不是pipeline指令组合,因此需要显式的wait指令保证前序的umma执行完成,umma的完成需要通过mbarrier机制保证,但是mbarrier保证不了tcgen05指令的可见性,因此还需要加上after_thread_sync。
cpp
// example 3
tcgen05.mma [d], ...
tcgen05.commit.mbarrier::arrive::one
mbarrier.try_wait.relaxed.cluster (loop until successful)
tcgen05.fence::after_thread_sync
tcgen05.ld [d], ...不同线程,pipeline
不同线程如果形成了pipeline指令组合,那么不需要wait机制等待完成,但是需要同步机制保证指令下发的顺序。
cpp
//example 4
// tid 0
tcgen05.cp
tcgen05.fence::before_thread_sync
mbarrier.arrive.relaxed.cluster
// tid 1
mbarrier.try_wait.relaxed.cluster // loop till success
tcgen05.fence::after_thread_sync
tcgen05.mmaexample4想要tid1的umma在tid0的cp之后执行,cp和umma是pipeline指令组合,因此不需要等待cp执行完成就可以下发umma指令,但是线程之间需要通过同步机制保证指令下发顺序,example 4用了mbarrier进行同步,tid 0执行mbarrier的arrive,tid 1执行mbarrier的wait,但是还是如前所述,mbarrier原生保证不了tcgen05的order,因此还需要加上fence。
前边有说,运行时同步除了mbarrier外,也可以用barrier,morally strong的ld / st,再看一个ld / st例子,如下:
cpp
// example 5
// tid 0
tcgen05.cp.cta_group::1.128x256b [taddr0], sdesc0;
tcgen05.fence::before_thread_sync;
st.relaxed.b32 [flag], 1;
// tid 1
loop:
ld.relaxed.b32 r, [flag];
setp.eq.u32 p, r, 1;
@!p bra loop;
tcgen05.fence::after_thread_sync;
tcgen05.mma.cta_group.kind [taddr0], adesc, bdesc, idesc, p;tcgen05.cp和umma形成了pipeline,因此不需要wait等待完成,只需要同步机制保证指令下发的顺序,这里用了relax的ld / st,tid 0写入flag为1,tid 1轮询flag直到为1。
不同线程,非pipeline
如果想在非pipeline的组合中保证顺序,除了显式的同步机制外,还需要wait机制保证前序的tcgen05指令的完成执行。
cpp
// example 6
// tid 0
tcgen05.ld
tcgen05.wait::ld
tcgen05.fence::before_thread_sync
mbarrier.arrive.relaxed.cluster
// tid 1
mbarrier.try_wait.relaxed.cluster // loop till success
tcgen05.fence::after_thread_sync
tcgen05.mmaexample 中umma想要等待tcgen05.ld的完成再执行,tcgen05.ld和umma不是pipeline组合,因此需要wait机制等待tcgen05.ld的完成,然后再执行fence + 同步。
Preferred Thread Block Clusters
Hopper中引入了thread block cluster,一定会被同时调度到同一个GPC,但是如图11所示,这有可能导致idle的sm,进一步由于良率问题,不同GPC的sm数量都不一致,问题会更明显,因此Hopper中一般常用2x1的cluster shape。
Blackwell为了解决这个问题引入了Preferred Thread Block Clusters,在一次launch的时候可以指定两个thread block cluster shape,硬件会优先使用preferred shape,如果sm不足,那么剩下的sm会使用fallback shape,如图11所示
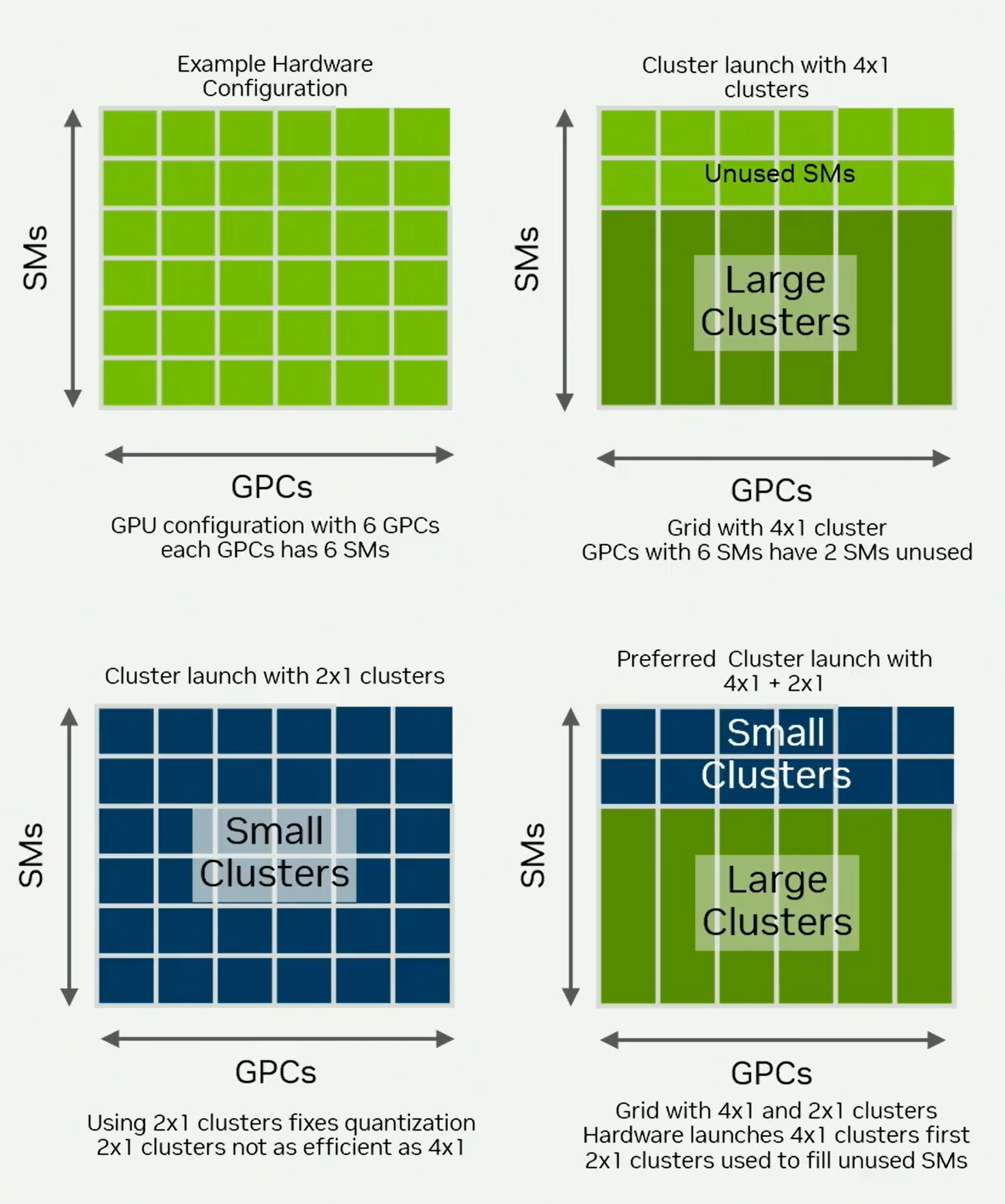
图 11
可以看到cute中的实现,fallback的shape通过cudaLaunchAttributeClusterDimension指定,preferred shape通过cudaLaunchAttributePreferredClusterDimension指定。
cpp
static inline CUTLASS_HOST
LaunchConfig make_cluster_launch_config(
dim3 const grid_dims,
dim3 const cluster_dims,
dim3 const block_dims,
size_t const smem_size = 0,
cudaStream_t cuda_stream = 0,
bool launch_with_pdl = false
, dim3 const fallback_cluster_dims = {0, 0, 0}
) {
LaunchConfig cluster_launch_config;
#if defined(CUTLASS_SM90_CLUSTER_LAUNCH_ENABLED)
auto &launch_config = cluster_launch_config.launch_config;
auto &launch_attribute = cluster_launch_config.launch_attribute;
auto numAttrs = cluster_launch_config.numAttrs;
launch_attribute[0].id = cudaLaunchAttributeClusterDimension;
bool have_fallback = fallback_cluster_dims.x * fallback_cluster_dims.y * fallback_cluster_dims.z > 0;
if (have_fallback) {
launch_attribute[0].val.clusterDim = {fallback_cluster_dims.x, fallback_cluster_dims.y, fallback_cluster_dims.z};
}
else {
launch_attribute[0].val.clusterDim = {cluster_dims.x, cluster_dims.y, cluster_dims.z};
}
#if defined(CUDA_ENABLE_PREFERRED_CLUSTER)
if (have_fallback) {
if (cute::initialize_preferred_cluster_launch(nullptr, grid_dims, cluster_dims, fallback_cluster_dims)) {
launch_attribute[1].id = cudaLaunchAttributePreferredClusterDimension;
launch_attribute[1].val.preferredClusterDim = {cluster_dims.x, cluster_dims.y, cluster_dims.z};
}
}
else {
numAttrs--;
}
#endifCluster Launch Control
Hopper中引入了persistent kernel的概念,launch固定数量的block数,一般等于SM数量,每个block计算多个tileD,以消除CTA开始和结束的开销,但是如图12,当同时有多个kernel运行的时候,这种静态的调度可能存在长尾问题,比如sm2切换出去运行了其他kernel,就会造成202和302的长尾。
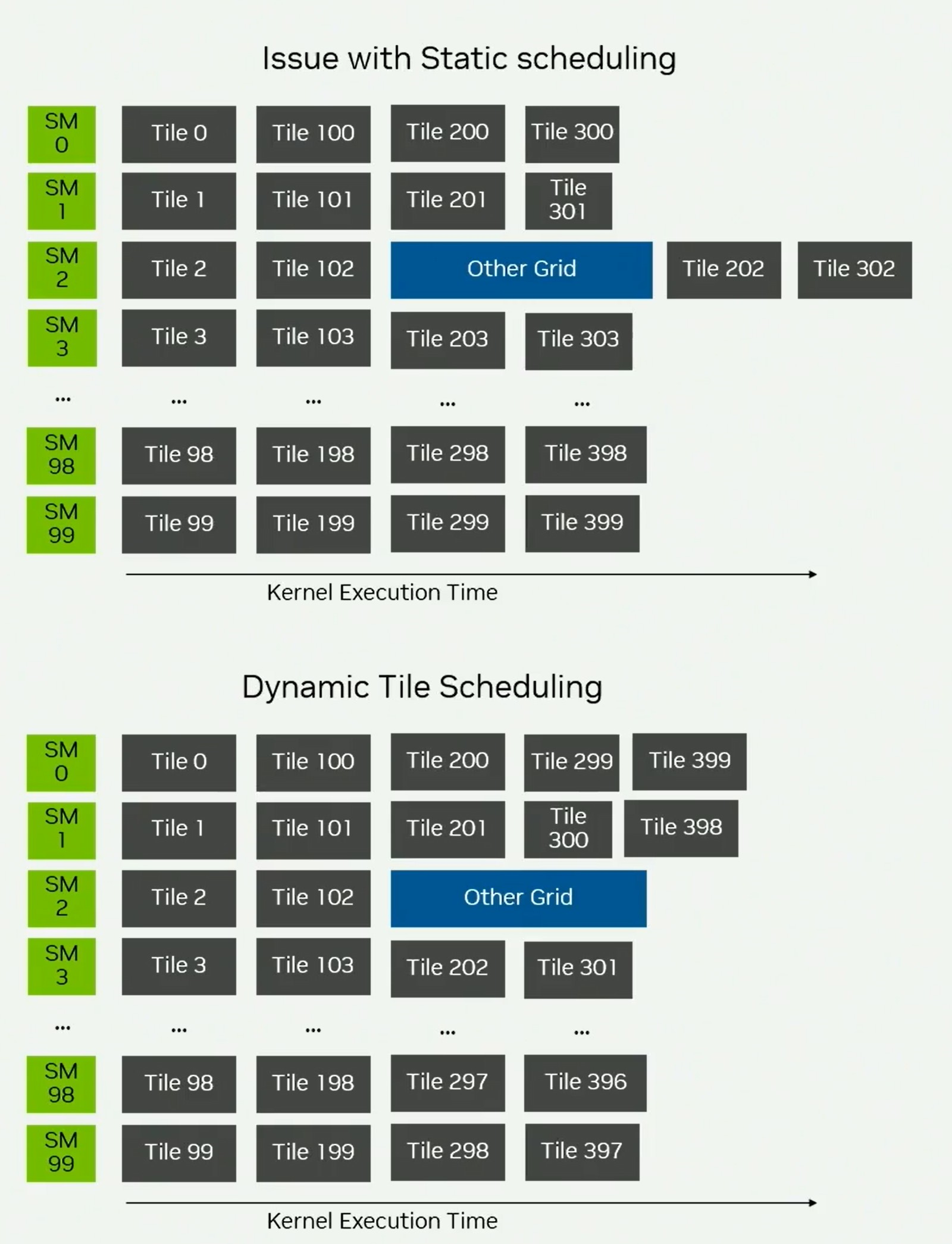
图 12
因此Blackwell引入了动态调度,不再launch固定数量的CTA,而是还是launch D规模大小的CTA,然后通过动态调度竞争tileD。
对于非persistent kernel,CTA个数和tileD个数相等,每个CTA计算一个tileD。
cpp
// Non-persistent kernel
__device__ non_persistent_kernel(...) {
setup_common_data_structures();
dim3 workCoordinates = blockIdx;
coordinate_specific_compute(workCoordinates);
}对于静态的persistent kernel,CTA个数等于sm数量,一个sm计算多个tileD。
cpp
// Static Persistent Kernel
__device__ static_persistent_kernel(...) {
setup_common_data_structures(...);
dim3 workCoordinates = blockIdx;
bool isValidId;
do {
coordinate_specific_compute(workCoordinates);
std::tie(isValidId, workCoordinates) = staticTileScheduler.fetch_next_work();
} while (isValidId);
}对于动态persistent kernel,CTA数量等于tileD的数量,每个SM动态竞争tileD的计算。
cpp
// Dynamic Persistent Kernel
__device__ clc_dynamic_persistent_kernel(...) {
setup_common_data_structures(...);
dim3 workCoordinates = blockIdx;
dim3 newClcID;
bool isValidId;
do {
coordinate_specific_compute(workCoordinates);
std::tie(isValidId, newClcID) = clcTileScheduler.fetch_next_work();
workCoordinates = newClcID;
} while (isValidId);
}首先看下Blackwell引入的新指令。
cpp
clusterlaunchcontrol.try_cancel.async{.space}.completion_mechanism{.multicast::cluster::all}.b128 [addr], [mbar];
.completion_mechanism = { .mbarrier::complete_tx::bytes };
.space = { .shared::cta };
clusterlaunchcontrol.query_cancel.is_canceled.pred.b128 pred, try_cancel_response;
clusterlaunchcontrol.query_cancel.get_first_ctaid.v4.b32.b128 {xdim, ydim, zdim, _}, try_cancel_response;
clusterlaunchcontrol.query_cancel.get_first_ctaid{::dimension}.b32.b128 reg, try_cancel_response;
::dimension = { ::x, ::y, ::z };try_cancel是一个异步指令,可以原子性的请求取消一个未启动的cluster的运行,执行完成之后会写入一个response到SMEM,通过mbarrier机制观测完成,response大小为16B,通过clusterlaunchcontrol.query_cancel解析,如果通过is_canceled.pred.b128解析发现取消成功,那么通过get_first_ctaid可以获得被取消的cluster中的第一个CTA的coord。try_cancel中的multicast可以将response和mbarrier的完成信号广播到当前cluster的所有CTA。如果取消没有成功,那么接下来的try_cancel都是未定义的。
那么整体流程就成为,每个cluster的0号CTA的0号warp作为scheduler warp,一直执行try_cancel获取可取消的cluster,即待处理的tileD,然后交给当前cluster执行。
参考
- https://docs.nvidia.com/cuda/parallel-thread-execution/index.html
- https://www.nvidia.com/en-us/on-demand/session/gtc25-s72720/
- https://gau-nernst.github.io/tcgen05/
- https://newsletter.semianalysis.com/p/nvidia-tensor-core-evolution-from-volta-to-blackwell
- https://docs.nvidia.com/cutlass/latest/media/docs/cpp/blackwell_cluster_launch_control.html