**Hi,大家好,我是半亩花海。**在上节说明了迁移学习的第一类方法:数据分布自适应之后,本文主要将介绍迁移学习的第二类方法------特征选择。该方法基于源域和目标域存在共享特征的假设,通过机器学习选择这些公共特征来构建模型。重点讲解了经典SCL方法及其核心概念Pivot feature(跨领域高频词),并列举了后续扩展研究如联合特征选择与子空间学习等方法。特征选择法通常与分布自适应方法结合,采用稀疏表示实现特征选择,为迁移学习提供了重要技术路径。
一、基本假设
特征选择法的基本假设是:源域和目标域中均含有一部分公共的特征,在这部分公共的特征上,源领域和目标领域的数据分布是一致的。因此,此类方法的目标就是,通过机器学习方法,选择出这部分共享的特征,即可依据这些特征构建模型。
下图形象地表示了特征选择法的主要思路。
 特征选择法示意图
特征选择法示意图
二、核心方法
这个领域比较经典的一个方法是发表在 2006 年的 ECML-PKDD 会议上,作者提出了一个叫做 SCL 的方法 (Structural Correspondence Learning) Blitzer et al., 2006。这个方法的目标就是我们说的,找到两个领域公共的那些特征。作者将这些公共的特征叫做 Pivot feature。找出来这些Pivot feature,就完成了迁移学习的任务。
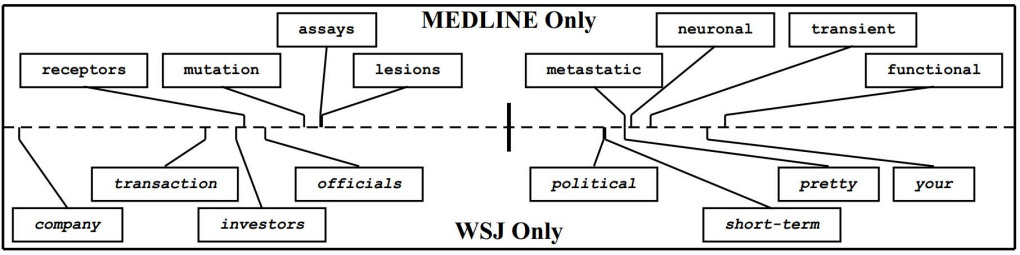 特征选择法中的 Pivot feature 示意图
特征选择法中的 Pivot feature 示意图
上图形象地展示了 Pivot feature 的含义。Pivot feature指的是在文本分类中,在不同领域中出现频次较高的那些词。
三、扩展
SCL 方法是特征选择方面的经典研究工作。基于 SCL,也出现了一些扩展工作。
- Joint feature selection and subspace learning Gu et al., 2011:特征选择 + 子空间学习
- TJM (Transfer Joint Matching) Long et al., 2014b: 在优化目标中同时进行边缘分布自适应和源域样本选择
- FSSL (Feature Selection and Structure Preservation) Li et al., 2016: 特征选择 + 信息不变性
四、小结
- 特征选择法从源域和目标域中选择提取共享的特征,建立统一模型;
- 通常与分布自适应方法进行结合;
- 通常采用稀疏表示
实现特征选择。