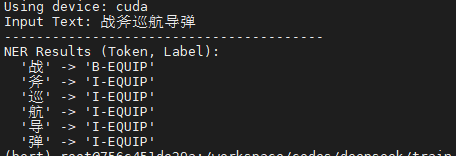
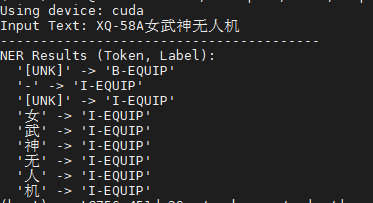
bert-base-chinese-ner预训练模型目录:
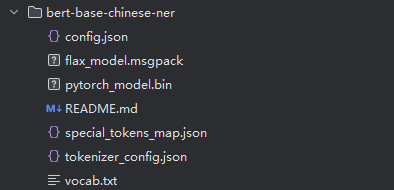
bert-base-chinese-ner预训练模型包含的实体标签类型:
数据标注样式:BIO标签
微调后的模型目录
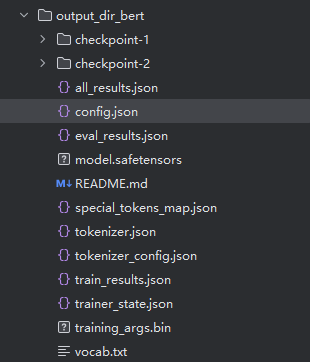
其中:
model.safetensors:微调后的模型权重文件,使用了更安全、更安全的safetensors格式
Config.json: 模型结构配置,和原始模型基本一致,但num_labels和id2label/label2id已更新为你数据集的标签体系。
tokenizer.json + vocab.txt + tokenizer_config.json :Tokenizer文件
config.json 中的 "id2label" 字段通常是在微调(SFT)过程中由训练脚本根据提供的训练数据集的标签体系自动生成或显式指定的。具体行为取决于你使用的训练框架(如 Hugging Face Transformers 的 Trainer)和数据预处理逻辑:
如果你在训练时传入了自定义的标签列表(例如通过 label_list 或 id2label 参数),那么 Trainer 会直接使用该映射,并写入最终保存的 config.json。
如果你未显式提供标签映射,但训练数据中包含完整的 BIO 标签(如 "B-PER", "I-LOC" 等),训练脚本Hugging Face Transformers 的 Trainer通常会在数据预处理阶段自动收集所有唯一标签,按字典序或出现顺序排序后生成 label2id 和 id2label,并更新到模型配置中。
目标:
1)领域微调:
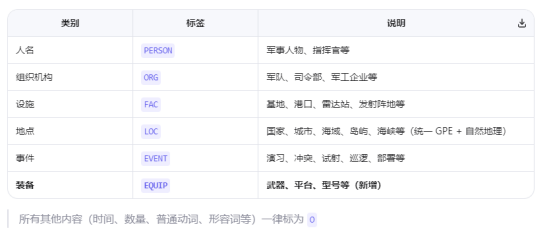
基于bert-base-chines-ner模型,针对:
- PER(人物)
- ORG(组织/机构)
- LOC(地点)
- FAC(设施)
- EVENT(事件)
五类实体做一些军事领域的微调;
2)增量微调:
在已有微调模型基础上,新增一个实体类别EQUIP(军事装备),并补充数据进行一个增量微调,使模型能够识别新类别。
领域微调实验:
实验一:
1)让LLM生成50条标注数据,训练后结果如下:
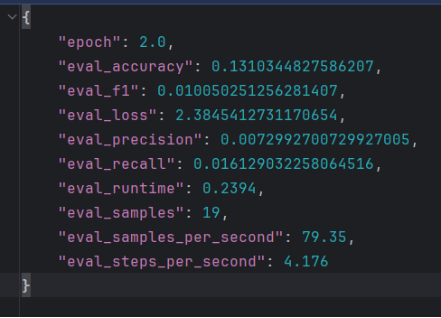
发现f1得分只有0.01,说明没有学习到任何特征,可能的原因是:
1. 数据量严重不足
每类仅 10 条样本,远低于 NER 任务的实用下限。即使是轻量级模型(如 BERT-base),在低资源场景下也需要至少数百条高质量标注样本才能初步泛化。
小样本极易导致模型过拟合到训练集中的表面模式(如固定短语、位置特征),而无法学习到实体类型的语义边界和上下文规律。
2. 数据多样性与颗粒度不足
LLM 生成的数据往往具有"模板化"倾向:
实体形式单一,缺乏真实文本中的变体,颗粒度不够(如"美国前总统拜登"、"Dr. Smith"、"军委副主席张又侠上将"等复合结构)。
句式重复、实体上下文分布狭窄:如很多样本都围绕同一主题(如政治人物)
实验二 :
- 针对数量严重不足问题 :扩充数据集;数据颗粒度提升,每类各50条,共250条标准样本,提高epoch
人物(PER):50条
地点(LOC):50条
组织机构(ORG):50条
设施(FAC):50条
事件(EVENT):50条
针对数据多样性不足问题 :
1、针对每种实体类别,优化提升词,对时效性,数据范围要求细化,给出few-shot样例;按类别分别生成,而不是批量笼统生成
2、尝试了两者数据集切分逻辑;目标都是按照9:1切分,并且能包含6类别;
一种是对单条样本,以最先出现实体类型作为主导类别,将其划分到不同的桶中;
一种是统计单条样本中最频繁的实体类型作为其"主导类型",将其划分到不同的桶中。(这种效果比较好)
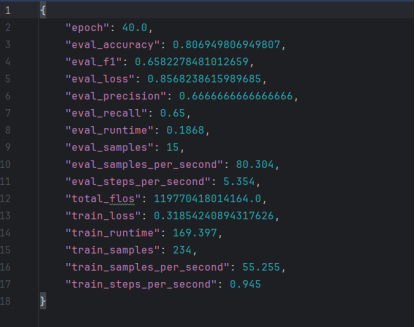
训练结果如下:
增量微调实验:
实验一:
核心思路:
1、准备新训练数据:标注包含 EQUIP 的样本,格式与原数据一致。
注意 :新的数据集必须包含之前的PER/LOC/ORG/FAC/EVENT的数据,并且模型应该加载之前的checkpoint(即已经微调过5类的那个模型)

2、更新标签映射:在原有 11 个标签(B/I × 5 类 + O)基础上,增加 B-EQUIP, I-EQUIP → 总标签数变为 13。
(训练时使用了带有这些标签的数据集,Hugging Face Transformers 的 Trainer训练框架自动构建了该映射并保存到了模型配置中)
3、数据集切分,训练集、验证集、测试集

4、保留原模型结构和参数,只扩展分类头(即最后一层线性层的输出维度)。
5、加载之前的checkpoint,开始训练
实验结果如下:
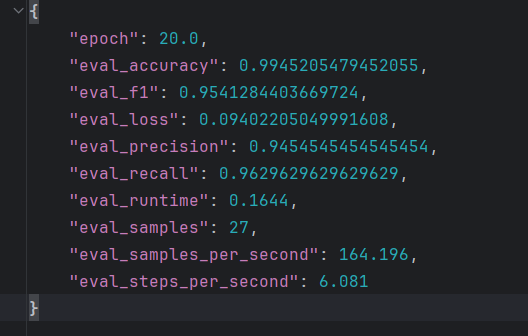
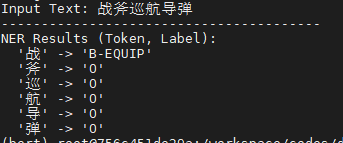
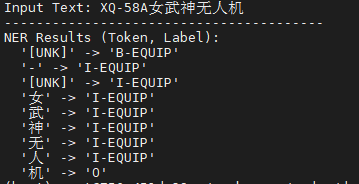
发现:
1)存在明显的实体边界截断问题;某类实体的识别不完整,有些字没有标注全
2)数据语义问题;
山东舰是装备,但是数据中把山东标成地点了;
实验二:
对上述问题,重新人工审核重新标注进行训练;