核心结论
BERT 和 GPT 都是基于 Transformer 架构的大语言模型核心代表,但二者是 Transformer 的 "两个极端用法",BERT 是 "左半边"(仅用自注意力的双向编码),GPT 是 "右半边"(仅用自注意力的单向解码),后续的大模型(比如 GPT-3/4、文心一言)基本都是融合二者思路的升级,本质是 Transformer 的不同应用分支。
1. 核心能力:"看懂" 文本,而非 "生成" 文本
BERT 的核心作用是理解自然语言的语义和上下文,比如判断两句话是不是一个意思、给句子做情感分析、给文章做关键词提取、做机器翻译的 "理解端",它本身不会主动写句子、编内容(比如让 BERT 写一篇小作文,它做不到)。
2. 最关键的 "双向":看上下文不偏科
这是 BERT 的最大创新,举个例子理解 "双向":比如一句话 **"我今天吃了苹果,这个____很甜".
- 传统的语言模型(比如 BERT 之前的 ELMo、RNN)是单向的:只能从左到右看("我今天吃了苹果,这个")来猜空格,看不到右边的 "很甜";
- BERT 的双向:能同时看左边(我今天吃了苹果,这个)和右边(很甜)的所有信息,精准猜到空格是 "苹果",因为它能同时利用前后文的上下文信息理解语义。
3. 训练方式:专门练 "猜词" 和 "判句"
BERT 的训练很简单,就两个核心任务,都是让它练 "理解能力":
++① 掩码语言模型(MLM):随机把句子里 15% 的词换成 "MASK"(掩码),让 BERT 猜这个词是什么(就是上面的空格例子),练双向上下文理解;++
++② 下一句预测(NSP):给 BERT 两句话,让它判断第二句话是不是第一句话的下一句(比如 "我去超市买东西" 和 "今天天气很好",BERT 能判断出不是),练句子之间的逻辑关系理解。++
4. 一句话总结 BERT:
谷歌造的、基于 Transformer 的 **"语言理解专家",擅长吃透文本的上下文语义,是后续所有理解类 NLP 任务(情感分析、文本分类、命名实体识别)的 "基础底座",但无生成能力 **。
论文
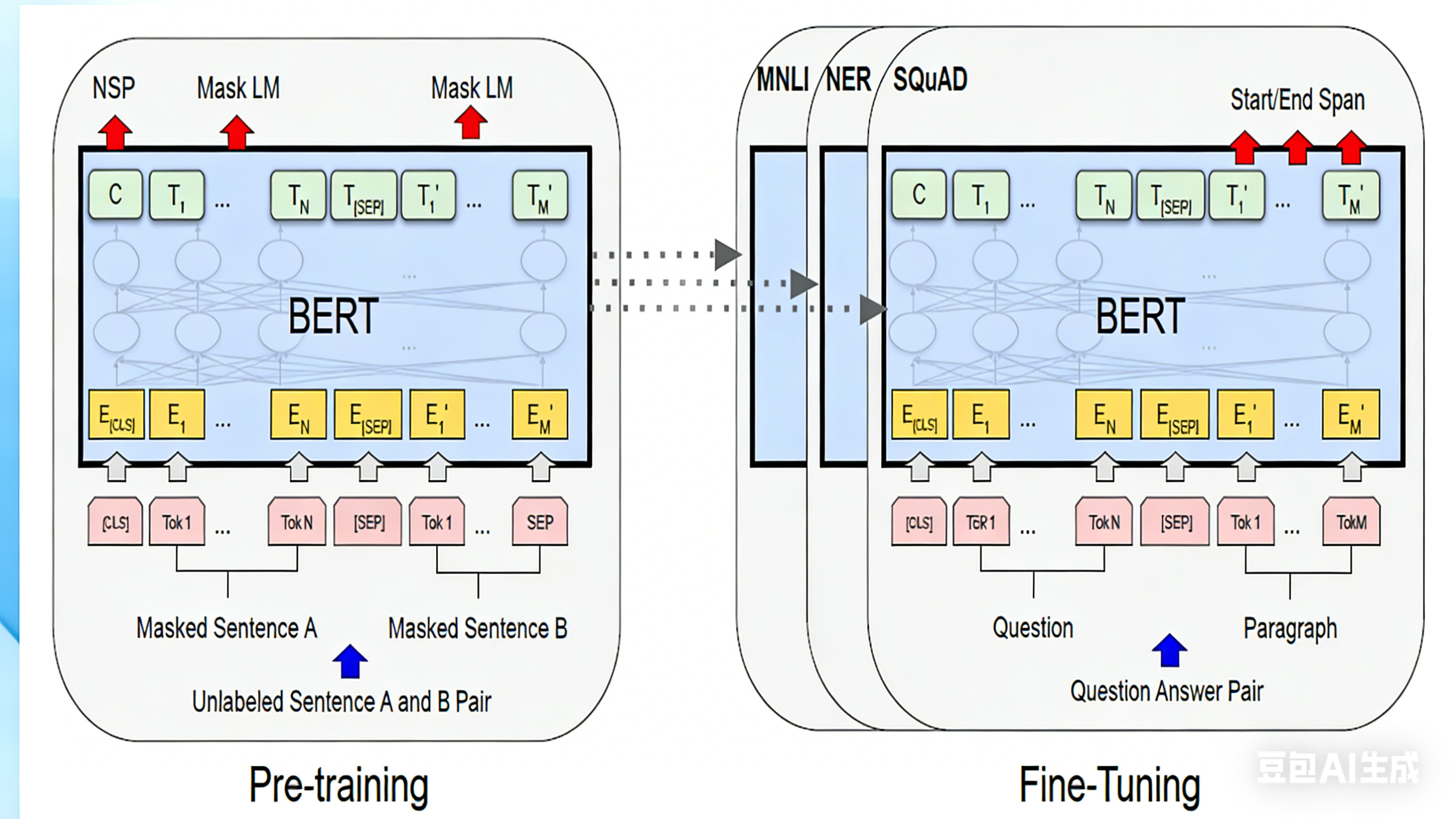
这个图展示的是BERT 的 "预训练→微调" 完整流程------ 左边是 "练基础能力" 的预训练阶段,右边是 "用基础能力做具体任务" 的微调阶段,我拆成两部分给你白话解析:
一、左边:预训练阶段(练 "通用理解能力")
这是 BERT 先在海量无标注数据上 "打底子" 的过程,核心练两个技能(就是之前说的 Mask LM 和 NSP):
- 输入部分
- 喂给 BERT 的是未标注的句子对(Sentence A + Sentence B),比如随便找两句话 "我爱吃苹果" 和 "它很甜";
- 输入的 token(文本最小单元)格式固定:
[CLS]:开头的特殊 token,用来代表 "整个句子对的语义"(后面 NSP 任务就靠它);Tok1~TokN:句子 A 的单词 / 字;[SEP]:特殊 token,用来分隔句子 A 和句子 B;Tok1'~TokM':句子 B 的单词 / 字;
- 这些 token 会先转成 "嵌入向量(图里的黄色 E 块)"------ 相当于把文字翻译成计算机能懂的数字表示。
-
BERT 模块 图里中间的 "BERT"+ 圆圈 + 交叉线,就是 BERT 的核心(Transformer 编码器),负责用双向自注意力吃透这些 token 的上下文语义(比如 "它" 指的是 "苹果")。
-
预训练任务(练技能)
- Mask LM(掩码语言模型) :图里红色箭头指的 token,是被随机盖住的 "掩码词"(比如把 "苹果" 换成
[MASK]),BERT 要根据前后文猜出这个词 ------ 练的是 "双向理解上下文" 的能力; - NSP(下一句预测) :红色箭头指的
[CLS],BERT 要通过它的输出,判断 "句子 B 是不是句子 A 的真实下一句"(比如 "我爱吃苹果"+"它很甜" 是真下一句,"我爱吃苹果"+"今天下雨了" 是假的)------ 练的是 "理解句子间逻辑" 的能力。
二、右边:微调阶段(把 "通用能力" 用到具体任务)
预训练好的 BERT 已经有了 "理解语言" 的底子,现在要针对不同的实际任务(比如问答、分类)"微调",核心是复用 BERT 的编码器,只改输入格式 + 输出层:
- 输入部分 不再是随便的句子对,而是具体任务的输入格式,比如图里展示的是 "问答任务(SQuAD)":
- 输入是 "问题(Question)+ 段落(Paragraph)";
- token 格式还是
[CLS] + 问题token + [SEP] + 段落token(和预训练格式对齐,保证 BERT 能看懂)。
-
BERT 模块和预训练用的是同一个 BERT 编码器(参数直接复用)------ 相当于让 "有基础理解能力" 的 BERT,直接理解任务输入的语义。
-
**微调任务(做具体事)**根据不同任务,在 BERT 输出后接不同的 "小模块",实现不同功能:
- 比如SQuAD(问答):红色箭头指的 "Start/End Span",是让 BERT 从段落里找 "答案的起始位置" 和 "结束位置"(比如问题 "苹果是什么味?",段落里 "它很甜" 的 "很" 是 Start,"甜" 是 End);
- 比如MNLI(文本蕴含):判断 "两句话是不是有逻辑关系"(复用 NSP 的思路);
- 比如NER(命名实体识别):从文本里找 "人名、地名" 等实体 ------ 这些任务都不用重新训练 BERT,只需要在预训练好的模型上加个简单的输出层,用少量标注数据调优就行。
关键总结
这个图的核心是体现 BERT 的 "预训练 - 微调" 优势:先在海量无标注数据 上练出 "通用语言理解能力"(预训练),再用少量标注数据适配各种具体任务(微调)------ 这也是 BERT 能让 NLP 任务精度暴涨的关键逻辑。