在日常沟通中,我们经常需要根据不同的对象和场景调整语气。向老板汇报工作时需要正式严谨,和同事交流时可以轻松随意,写文案时又需要符合品牌调性。手动调整这些语气不仅耗时,还容易词穷。特别是在需要快速产出多种风格文案的场景下,比如社交媒体运营需要同时准备正式版、幽默版、情感版等多个版本,传统的逐个改写方式效率极低。
基于这样的痛点,我开发了这个 RWKV 并行语气转换工具。它能够接收一段文本,通过 RWKV 大语言模型,一次性并行生成 60 多种不同语气和风格的表达方式,涵盖职场、生活、方言、文学、网络等多个维度,极大提升了内容创作和沟通表达的效率。
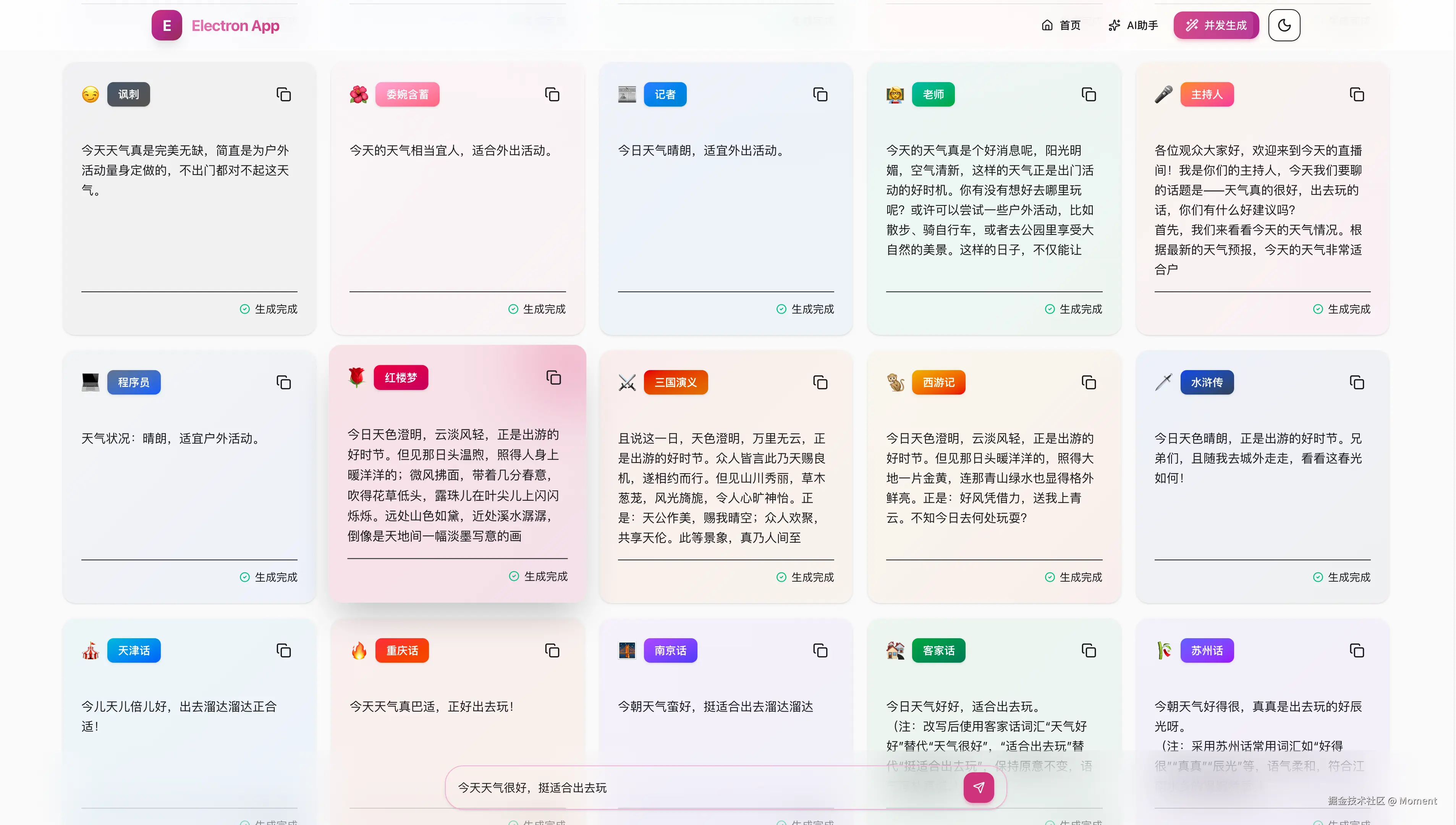
从上图可以看到,工具的界面简洁直观。用户只需在底部输入框中输入原始文本,点击发送按钮,系统就会同时生成多种语气版本。每个卡片代表一种风格,包含风格图标、名称和转换后的内容。所有结果实时流式返回,用户可以立即看到生成进度,并且每个结果都支持一键复制,方便快速使用。
核心特性与技术实现
这个项目最大的特点是并行生成能力。传统的语气转换工具通常是串行处理,即逐个风格依次生成,这样会导致等待时间过长。而本工具通过在后端同时处理多个转换请求,前端采用流式渲染技术,实时展示每个风格的生成进度,整体响应速度大幅提升。
在前端技术选型上,项目采用了 React 19 作为 UI 框架,配合 Rsbuild 作为构建工具。相比传统的 Webpack 或 Vite,Rsbuild 提供了更快的构建速度和更简洁的配置体验。样式层面使用了 Tailwind CSS 4,通过精心设计的渐变色彩和流畅的动画效果,打造出现代化的视觉体验。整个界面采用浅色主题,柔和的紫粉渐变背景配合玻璃态效果,既美观又不影响内容的阅读。
项目完整的技术栈包括:React 19 提供强大的 UI 渲染能力,TypeScript 确保类型安全,Rsbuild 负责快速构建,Tailwind CSS 4 处理样式,Lucide React 提供图标支持,Class Variance Authority 管理组件变体。这套组合既保证了开发效率,也确保了运行时性能。
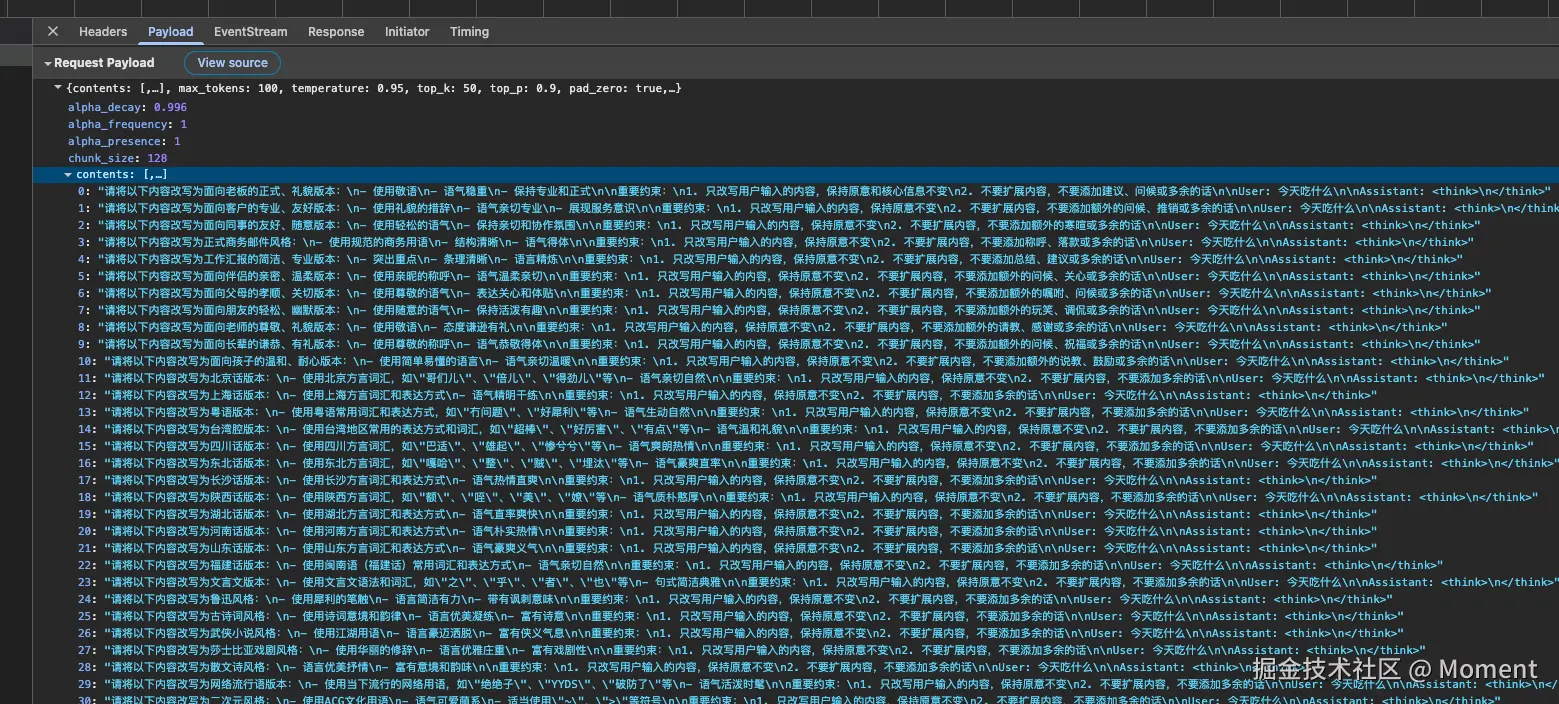
从接口请求参数可以看到,后端接收的核心数据结构相对简单。contents 字段是一个数组,包含了所有需要转换的 prompt 内容。每个 prompt 都是一个完整的指令,包含了风格要求和用户输入的原始文本。系统会根据这些 prompt 并行调用 RWKV 模型进行生成,同时还支持多种参数调优,比如 temperature、top_k、top_p 等,以获得更好的生成效果。
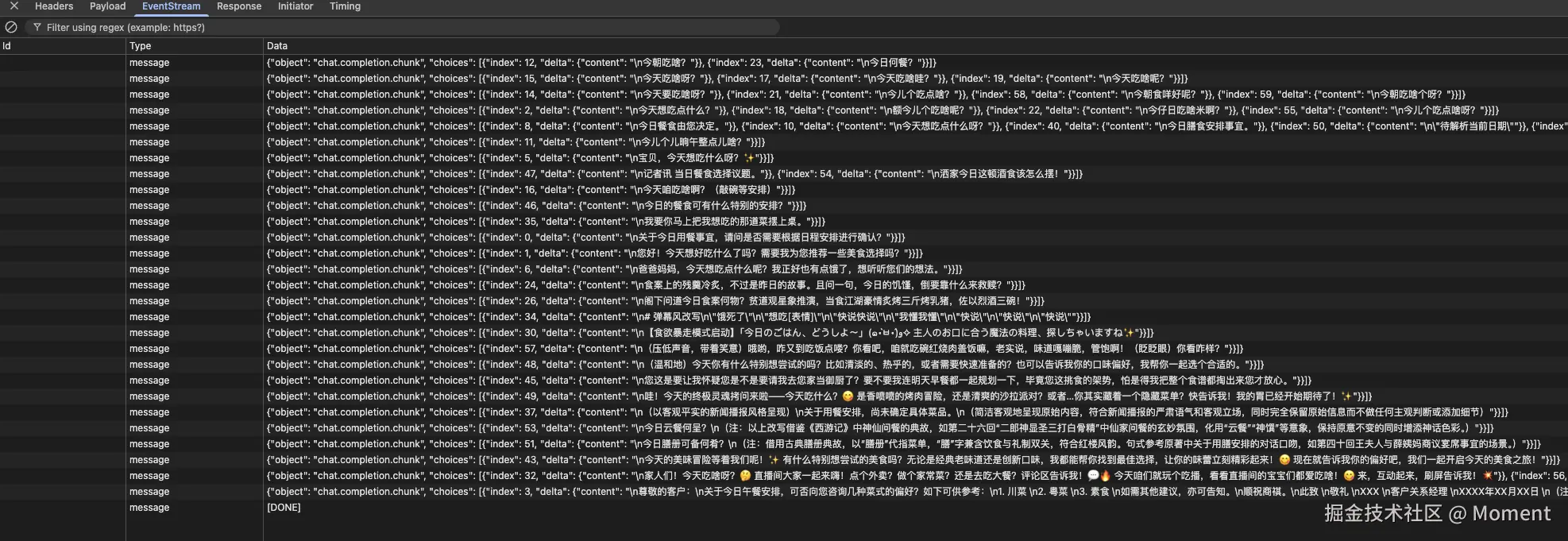
响应数据采用了 Server-Sent Events(SSE)的流式传输方式。每个数据块都是一个 JSON 对象,包含了 choices 数组,其中每个 choice 对应一个风格的生成结果。通过 index 字段标识具体是哪个风格,delta 中的 content 字段则包含了本次推送的文本片段。前端接收到这些数据后,会实时更新对应卡片的内容,用户可以看到文字逐字生成的效果,体验非常流畅。
并发生成的核心实现
整个项目的精髓在于如何实现真正的并发生成。先看生成 contents 数组的逻辑:
typescript
function generateStyleContents(userInput: string): string[] {
const configs = getMergedStyleConfigs();
return configs.map((config) => {
if (config.prompt.includes("${{input}}")) {
return config.prompt.replace(/\$\{\{input\}\}/g, userInput);
}
return `${config.prompt}\n\nUser: ${userInput}\n\nAssistant: <think>\n</think>`;
});
}这个函数做的事情很简单:遍历所有风格配置,将每个风格的 prompt 模板中的 ${{input}} 占位符替换为用户的真实输入。generateStyleContents 函数会调用 getMergedStyleConfigs() 获取所有风格配置。假设用户输入"明天要开会",经过这个函数处理后,会得到一个包含 60 个完整 prompt 的数组。每个 prompt 都是独立的,包含了该风格的要求描述、约束条件,以及用户输入。
有了这个数组,接下来就是发送请求了。关键在于,我们把整个 contents 数组一次性发送给后端:
typescript
const response = await fetch(config.apiUrl, {
method: "POST",
headers: {
"Content-Type": "application/json",
Accept: "*/*",
"Accept-Language": "zh-CN,zh;q=0.9",
},
body: JSON.stringify({
contents, // 这里是 60 个 prompt 的数组
max_tokens: 100,
temperature: 0.95,
top_k: 50,
top_p: 0.9,
pad_zero: true,
alpha_presence: 1.0,
alpha_frequency: 1.0,
alpha_decay: 0.996,
chunk_size: 128,
stream: true,
password: config.password,
}),
signal,
});注意看请求体中的 contents 字段,这就是我们刚才通过 generateStyleContents 函数生成的 60 个 prompt。后端收到这个数组后,会同时启动 60 个生成任务,每个任务对应数组中的一个 prompt。数组的索引位置(0, 1, 2, ..., 59)就是每个任务的 ID,这个 ID 会在返回的 index 字段中体现。
流式响应的解析机制
后端采用 Server-Sent Events(SSE)格式返回流式数据。每个数据块的格式大致是这样的:
css
data: {"object":"chat.completion.chunk","choices":[{"index":12,"delta":{"content":"明"}},{"index":23,"delta":{"content":"今"}},{"index":5,"delta":{"content":"后"}}]}
data: {"object":"chat.completion.chunk","choices":[{"index":12,"delta":{"content":"天"}},{"index":23,"delta":{"content":"天"}}]}
data: [DONE]看到了吗?每个 choice 对象都有一个 index 字段。这个 index 就是对应 contents 数组中的位置。比如 index 为 12 的 choice,对应的就是 contents[12] 这个 prompt 的生成结果。前端正是靠这个 index,知道把返回的文本片段更新到哪个风格卡片上。
解析流式数据的代码使用了 fetch API 的流式读取能力:
typescript
const reader = response.body?.getReader();
const decoder = new TextDecoder();
let buffer = "";
while (true) {
const { done, value } = await reader.read();
if (done) break;
buffer += decoder.decode(value, { stream: true });
const lines = buffer.split("\n");
buffer = lines.pop() || "";
for (const line of lines) {
const trimmedLine = line.trim();
if (!trimmedLine || !trimmedLine.startsWith("data: ")) continue;
const data = trimmedLine.slice(6);
if (data === "[DONE]") {
// 所有任务完成
const completedResults = initialResults.map((result) => ({
...result,
isComplete: true,
}));
onUpdate(completedResults);
continue;
}
try {
const json = JSON.parse(data);
if (json.choices && Array.isArray(json.choices)) {
json.choices.forEach((choice: any) => {
const index = choice.index;
const deltaContent = choice.delta?.content || "";
if (deltaContent && initialResults[index]) {
// 根据 index 找到对应的结果对象,追加文本片段
initialResults[index].content += deltaContent;
}
});
onUpdate([...initialResults]);
}
} catch (e) {
console.warn("解析 JSON 失败:", e);
}
}
}这段代码的核心逻辑是:
- 使用
TextDecoder逐块解码二进制流,通过response.body?.getReader()获取流读取器 - 按行分割数据,因为每行是一个完整的
SSE消息 - 提取
"data: "后面的JSON数据 - 解析出
choices数组,遍历每个choice - 通过
choice.index找到对应的结果对象,将choice.delta.content追加上去 - 调用
onUpdate触发界面更新
这种增量更新的方式非常高效。不同风格的生成速度可能不一样,有的快有的慢,但每个风格的更新是完全独立的,互不干扰。用户可以实时看到每个卡片的内容逐字增加,体验非常流畅。
为什么这种方式能实现真并发
传统的做法是循环调用 API,每次生成一种风格,等这个风格生成完了再生成下一个。如果有 60 种风格,每个风格平均生成 2 秒,那总共需要 120 秒。这种串行的方式效率极低。
而我们这种方式,是把 60 个 prompt 打包成一个数组,一次性发送给后端。后端收到后,会并发地处理这 60 个任务。虽然每个任务还是需要 2 秒,但因为是并发执行,所以总耗时只有 2 秒多一点(加上一些网络延迟和任务调度开销)。
关键点在于:
contents数组的长度决定了并发数量- 后端通过
index标识每个任务的结果 - 前端通过
index将结果精确地更新到对应位置
这样就实现了真正的并行生成,效率提升了几十倍。
部署和使用
项目的部署很简单。如果你熟悉 Node.js,直接 npm install 安装依赖,npm run dev 启动开发服务器就能用。构建生产版本也就是一个 npm run build 的事。
如果你更喜欢用 Docker,项目也提供了完整的 Docker 支持。docker compose up --build -d 一条命令搞定,不用操心环境配置的问题。
API 配置
API 配置就两个参数:服务地址和密码。项目根目录下有个 .env 文件,里面写好了默认值。如果你有自己的 RWKV 后端服务,改一下这个文件就行,改完重启一下开发服务器。
bash
PUBLIC_RWKV_API_URL=http://192.168.0.12:8000/v1/chat/completions
PUBLIC_RWKV_PASSWORD=rwkv7_7.2b_webgen就这么简单。
60 种风格是怎么设计出来的
60 种风格不是拍脑袋想出来的,而是根据实际使用场景一点点积累起来的。最开始只有十几种,后来发现不够用,就不断补充。
职场类是最早做的一批。面向老板、面向客户、面向同事,这三个场景的语气差异非常大。跟老板汇报工作,得用"敬请指示"、"恭候佳音"这种正式表达。跟客户沟通,得强调"为您服务"、"满足您的需求"。跟同事交流,就可以"咱们商量一下"、"一起搞定"。
文学类是后来加的。有用户反馈说想要古风文案,于是就做了红楼梦、三国演义、水浒传这些经典名著的风格。还有诗词歌赋、文言文这些。效果还不错,生成出来的内容确实有那个味道。
方言类比较有意思。东北话、四川话、广东话、上海话,每种方言都有自己的特色词汇。东北话喜欢说"咋整"、"贼拉",四川话爱用"哦豁"、"巴适",广东话常说"饮茶"、"搞掂"。这些方言风格在做地方性推广时特别有用,能快速拉近和用户的距离。
网络用语风格是必须有的。现在的年轻人说话都是"yyds"、"绝绝子"、"EMO 了"这些梗。如果做社交媒体运营,不用这些网络语言,内容就会显得很生硬。所以专门做了几个网络用语风格,紧跟最新的流行趋势。
除了这些大类,还有一些更细分的场景风格。比如道歉、感谢、邀请、拒绝、催促等。这些在日常沟通中经常用到,但很多人不知道怎么表达得既礼貌又不失分寸。有了这些风格,直接套用就行。
实时看到生成进度
因为是流式响应,所以你可以实时看到每个风格的生成进度。不同风格的生成速度可能不一样,有的快有的慢,但每个都是独立更新的,互不影响。
这种体验比传统的"转圈等待"好太多了。你能看到文字一个个蹦出来,知道 AI 确实在工作,而不是卡住了。而且因为是并发的,所以很多风格会同时在生成,界面上到处都在更新内容,看起来特别有动感。
每个卡片右上角有个复制按钮,点一下就复制到剪贴板了。如果对结果不满意,底部有个"重新生成"按钮,会用同样的输入再跑一遍。
后端 API 要求
后端 API 需要支持以下特性:
- 接收一个
contents数组,数组里有多少个prompt就要并发处理多少个任务 - 返回
SSE格式的流式数据,每个choice必须包含index字段用于标识对应的任务 - 所有任务完成后发送
"data: [DONE]"标记
推荐使用 RWKV Lightning 作为后端服务(github.com/RWKV-Vibe/r...
写在最后
这个工具的核心价值就是一个字:快。
传统方式要生成 60 种风格,得等 2 分钟。现在并发生成,只要 2 秒钟。效率提升了 60 倍,这才是真正有用的工具。
当然,60 种风格只是开始。随着使用场景的增加,肯定还会有更多风格加进来。好在添加新风格很简单,改几行配置就行。
如果你有什么想法或建议,欢迎提 Issue 或 PR。这个工具会持续优化,让更多人受益。
项目地址:rwkv-parallel-tone
后端服务:RWKV Lightning