文章目录
-
- [一、RL 只是 ML 的 "强化版"](#一、RL 只是 ML 的 “强化版”)
- [二、智能体 vs 环境](#二、智能体 vs 环境)
- 三、强化学习的环境:随机世界
- 四、强化学习的目标不是单次奖励最高,而是长期总奖励期望最大
- [五、强化学习 vs 有监督学习:核心区别到底在哪?](#五、强化学习 vs 有监督学习:核心区别到底在哪?)
- 六、复盘一下
已经接触 RL 有一段时间了,做过一些 Demo 和 paper,今天想重新复盘一下 RL 的全部内容,主要用于以后回顾起来更方便些。
一、RL 只是 ML 的 "强化版"
我们都会有: "当初要是xxx就好了""早知道xxx" 这样的后悔。
人生就是由一连串的 选择(决策) 组成的,每一次选择都会带来不同的"后果",而我们会根据这些后果调整下一次的选择------这其实就是最朴素的"强化学习思维"。
在ML里,有两类核心任务:
- 预测任务:比如用历史数据预测明天的天气、用照片识别这是猫还是狗。核心是"根据已知数据猜答案",猜完就结束,不会影响未来。
- 决策任务 :比如让机器人自己学会走路、让 AI 下围棋赢人类、让无人车安全导航。核心是 **"通过一次次试错,学会做能带来长期好处的选择" **,也就是 序贯决策 ------强化学习的核心。
强化学习 = 机器通过与环境交互试错,学会做最优决策的过程
二、智能体 vs 环境
强化学习里,只有两个核心角色:智能体(Agent) 和 环境(Environment) 。
它们的关系,就像"玩家"和"游戏世界"的关系。
1. 核心角色定义
- 智能体(Agent) :做决策的"主角",可以是机器人、AI 围棋程序、无人车。它的目标是通过做动作,最大化自己能拿到的"好处"。
- 环境(Environment):智能体生存的"世界",可以是棋盘、道路、机器人的运动空间。环境会根据智能体的动作,给出反馈并改变自己的状态。
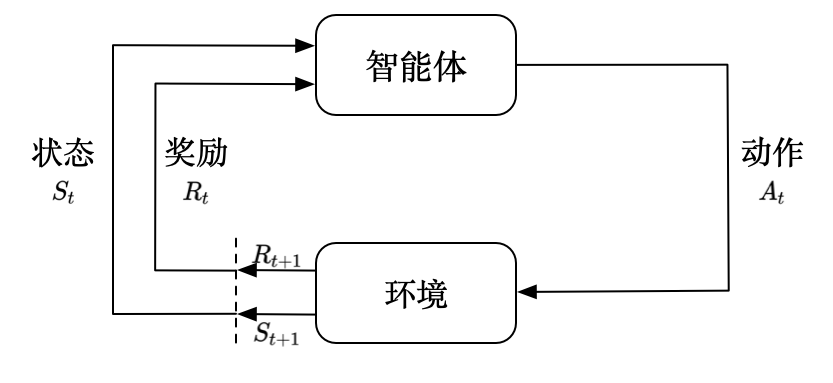
2. 智能体与环境的交互流程
它们的交互是一个循环往复的过程,就像打游戏时的"操作-反馈"循环:
- 智能体感知环境的当前状态(State, S):比如围棋智能体看到当前棋盘的棋子分布,无人车看到前方有没有红绿灯。
- 智能体根据状态,做出一个动作(Action, A):比如围棋智能体决定在"星位"落子,无人车决定"减速刹车"。
- 环境接收动作后,会发生两件事:
- 转移到新状态(S'):比如棋盘上多了一颗棋子,无人车从"高速行驶"变成"低速刹车"。
- 给智能体一个奖励(Reward, R) :这个奖励是标量数值(可以是正、负、零),用来评价动作的好坏。比如围棋赢了奖励 +100,输了奖励 -100;无人车安全通过路口奖励 +10,撞到行人奖励 -1000。
- 智能体拿到新状态和奖励,继续做下一次决策......循环往复,直到任务结束(比如围棋下完、无人车到达目的地)。
3. 智能体的三大核心能力
想让智能体学会决策,它必须具备三个"技能",这也是衡量智能体"聪明程度"的关键:
| 能力 | 通俗解释 | 生活例子 |
|---|---|---|
| 感知 | 看懂环境的"当前情况" | 你看导航知道自己现在在哪个路口 |
| 决策 | 根据当前情况选动作 | 看到红灯,你决定踩刹车 |
| 奖励感知 | 知道自己的动作好不好 | 踩刹车没闯红灯,得到"安全"的正向反馈 |
这里还要提一个关键概念:策略(Policy, π) 。策略就是智能体的"决策手册",定义了"在什么状态下该做什么动作",写成数学公式就是:
π ( A ∣ S ) = P ( A t = A ∣ S t = S ) \pi(A|S) = P(A_t = A | S_t = S) π(A∣S)=P(At=A∣St=S)
这个公式的意思是:在状态 S 下,智能体选择动作 A 的概率。比如在"棋盘星位有空位"的状态下,围棋 AI 有 80% 的概率选择落子(动作 A)。
不同智能体的核心区别,就是策略不一样------高手 AI 的策略能做出"长期最优"的选择,菜鸟 AI 只会"捡眼前小便宜"。
三、强化学习的环境:随机世界
Q: 环境为什么不能是"一成不变"的?
A: 真实世界是动态的、随机的。比如你开车时,下一秒会不会有行人横穿马路是不确定的;机器人走路时,地面的摩擦力可能随时变化。
在数学上,这种"会变的环境"用 随机过程 来刻画。而强化学习的环境,是一个被智能体动作影响的随机过程------环境下一个状态,不仅和当前状态有关,还和智能体刚做的动作有关。
用公式表示环境的状态转移概率 :
P ( S ′ ∣ S , A ) = P ( S t + 1 = S ′ ∣ S t = S , A t = A ) P(S'|S,A) = P(S_{t+1}=S' | S_t=S, A_t=A) P(S′∣S,A)=P(St+1=S′∣St=S,At=A)
这个公式的意思是:在当前状态 S 下,智能体做了动作 A 后,环境转移到新状态 S' 的概率。
举个例子:机器人在"平坦地面"(S)做"向前走一步"(A)的动作,有 90% 的概率转移到"前进 1 米"的新状态(S'),还有 10% 的概率因为地面打滑,停在原地(另一个 S')。
正因为环境是随机的,所以智能体做决策时,不能只看眼前的奖励,还要考虑未来的不确定性------这也是 RL 的难点之一。
四、强化学习的目标不是单次奖励最高,而是长期总奖励期望最大
玩游戏时,你会为了"捡一个金币"而冲进敌人的包围圈吗?大概率不会------因为捡金币的小奖励,抵不上被打死的大损失。
强化学习的智能体,目标和你一样:最大化整个交互过程的累积奖励期望。
这里要明确三个概念:
- 即时奖励(R):每一步动作得到的反馈,比如捡金币 +1。
- 回报(Return, G) :从当前步到任务结束的所有奖励总和,公式为:
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . = ∑ k = 0 ∞ γ k R t + k + 1 G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ... = \sum_{k=0}^\infty \gamma^k R_{t+k+1} Gt=Rt+1+γRt+2+γ2Rt+3+...=k=0∑∞γkRt+k+1
其中 γ \gamma γ 是折扣因子 ( 0 ≤ γ ≤ 1 0 \leq \gamma \leq 1 0≤γ≤1),用来表示"未来奖励的重要程度": γ \gamma γ 越接近 1,说明智能体越看重长远利益;越接近 0,越看重眼前利益。 - 价值(Value, V) :回报的数学期望。因为环境是随机的,同样的策略下,每次交互的回报可能不一样,所以我们关注"平均回报",公式为:
V π ( S ) = E π G t ∣ S t = S V^\pi(S) = \mathbb{E}_\piG_t \| S_t = S Vπ(S)=EπGt∣St=S
这个公式的意思是:在策略 π 下,智能体处于状态 S 时,未来能拿到的平均总回报。
强化学习的终极目标,就是找到一个最优策略 π ∗ \pi^* π∗ ,让智能体在任意状态下的价值都最大:
π ∗ = arg max π V π ( S ) \pi^* = \arg\max_\pi V^\pi(S) π∗=argπmaxVπ(S)
简单来说:最优策略 = 能带来最大长期利益的决策方式。
五、强化学习 vs 有监督学习:核心区别到底在哪?
看到这里,你可能会问:"不都是机器学习吗?强化学习和我们常听的'图像识别'(有监督学习)有啥不一样?"
我们用一张表总结核心区别:
| 对比维度 | 有监督学习 | 强化学习 |
|---|---|---|
| 核心任务 | 预测:根据输入猜标签 | 决策:通过试错选最优动作 |
| 数据来源 | 固定的、人工标注的数据集 | 智能体与环境交互产生,数据分布会变 |
| 优化目标 | 最小化"预测误差"的期望 | 最大化"长期总奖励"的期望 |
| 关键特点 | 单轮任务,不影响未来 | 序贯决策,当前动作影响未来状态 |
这里要强调一个 RL 的核心难点:数据分布是动态变化的。
在有监督学习中,训练数据是固定的------比如你用 10 万张猫的照片训练,数据分布不会变。但在 RL 中,智能体的策略变了,和环境交互产生的数据就会变。
这个"数据分布随策略变化"的特性,用 RL 里的概念叫 占用度量(Occupancy Measure)------它衡量"在策略 π 下,智能体遇到某个状态-动作对的概率"。
两个策略的占用度量相同,就说明它们的决策行为完全一样;策略变了,占用度量也会跟着变。这也是 RL 比有监督学习难的关键原因。
六、复盘一下
- RL 是做什么的? 解决序贯决策问题,让机器通过与环境交互试错,学会做最优选择。
- 核心角色是什么? 智能体(做决策)和环境(给反馈),二者循环交互。
- 智能体的目标是什么? 不是单次奖励最高,而是长期总奖励的期望最大。
- 和有监督学习的核心区别? RL 是"通过改变策略调整数据分布"来优化目标,有监督学习是"在固定数据分布上优化模型"。