背景
AutoMQ 是一款基于 S3 构建的下一代"Diskless Kafka",完全兼容 Kafka 协议。其云原生架构通过存算分离和按需弹性,显著提升了运维效率。最核心的突破在于,它利用共享存储消除了昂贵的跨可用区(Cross-AZ)数据传输费用,这能为多可用区集群每月节省数千甚至上万美元的网络成本。
在保持极致性价比的同时,AutoMQ 于 2025 年 12 月发布的版本正式引入了对 AWS FSx 作为 WAL 存储选项的支持,以进一步攻克 Diskless 架构的延迟瓶颈。这一演进使 AutoMQ 能够提供媲美本地磁盘的毫秒级延迟,同时保留零跨可用区流量成本和多可用区容灾能力,在低成本、高可靠与极致性能之间实现了完美平衡。
为了在真实生产环境下验证这些架构优势,我们进行了一系列性能基准测试,重点关注客户端观测到的端到端延迟。
Tips:
- AutoMQ FSxN 能力的正式发布请参考文章:AutoMQ x FSx: 10ms Latency Diskless Kafka on AWS
- AutoMQ FSxN 实现原理介绍请参考文章: How does AutoMQ implement a sub-10ms latency Diskless Kafka?
测试场景和结果
要理解测试结果,我们首先需要拆解延迟的产生环节:
延迟的构成
从业务视角来看,延迟主要源于两个方面:Kafka 客户端的排队延迟以及服务端的处理延迟。在接下来的章节中,我们将对这两个部分进行拆解分析,从而让大家能够清晰地理解 AutoMQ 结合 FSxN 设计对二者的具体影响。
服务端处理延迟
传统的 Kafka 架构服务端的主要延迟消耗在:客户端与服务的跨 AZ 通信,以及副本完成跨 AZ 复制(ACK=ALL)。这两段的跨 AZ 通信都是直接的 RPC 请求,在 AWS 上会产生高额的流量。
AutoMQ 从整体架构上做了一些变化:采用 AWS FSx 作为 WAL 存储,省去副本复制的流量费;同时通过 FSx 中继客户端和服务端的跨 AZ 请求,减少客户端和服务端的跨 AZ 流量费。由于增加了转发逻辑,会带来少量额外的处理延迟,但却极大的减少了流量成本。
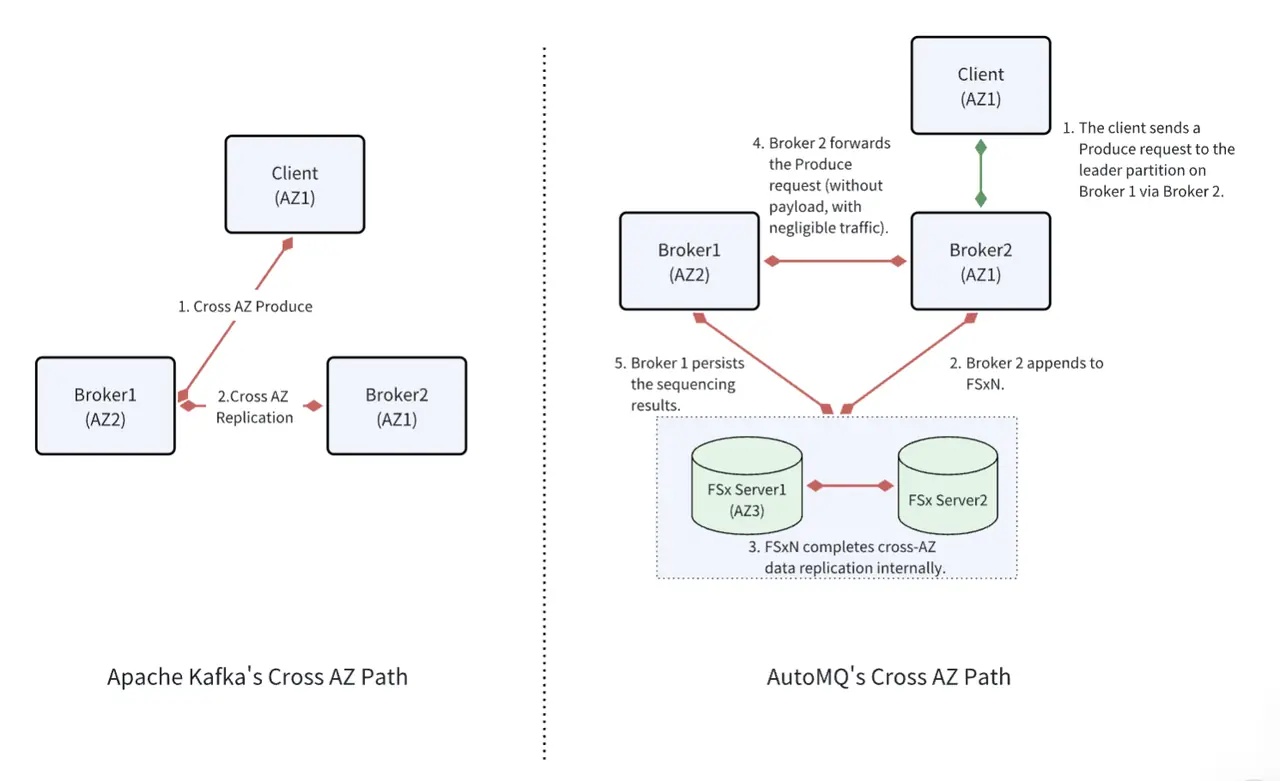
客户端排队延迟
Kafka 生产者采用"先攒批、后发送"的两阶段设计:首先将消息按分区在内存中累积,当达到batch.size 大小或 linger.ms 时间则会将消息放入就绪队列等待发送;网络层在并发限制内,从队列取出批次并发送到服务端。
在追求极致吞吐的场景下,业务常通过调大 linger.ms 主动攒批,但这会导致请求在客户端排队,从而在业务视角表现为更高的延迟;通常可通过 linger.ms 和 batch.size 两个参数在吞吐与延迟之间进行权衡。这一块可以参考之前的文章,里面有详细介绍:Kafka Performance Tuning: Best Practice for linger.ms and batch.size
测试场景选择
为了全面、客观地评估 AutoMQ 在引入 AWS FSxN 后的性能表现,并提供具备实战参考价值的性能数据,我们将测试场景设定为两个维度:极致性能基准(Baseline)与生产稳态模型(Robustness) 。
极致性能基准场景:服务端延迟物理上限测试
在分布式系统中,客户端的排队机制往往会掩盖存储介质真实的 I/O 响应。因此,我们首先通过设置 linger.ms=0 且在低并发压力下进行测试,旨在构建一个"零排队"的理想环境。
- 测试目的: 剥离客户端干扰,直接探测 AutoMQ 结合 FSxN WAL 后的服务端核心处理时延 与网络中继损耗 ,确立该方案的物理性能边界。
生产稳态模型场景:高吞吐下的确定性延迟测试
在真实的生产实践中,流量波动(Burst)、生产者扩缩容以及分区负载不均是常态。为了追求吞吐量与成本的平衡,开发者通常会通过 linger.ms 和 batch.size 进行攒批调优。
- 测试目的: 我们选取了典型的生产配置(如
linger.ms=3),并模拟集群满负载运行 状态。此场景旨在验证在真实业务压力下,AutoMQ 是否能提供高确定性的延迟输出,并观察其在处理海量小包写入(High TPS)时的尾部延迟(P99/P999)表现。
通过这两个维度的对比,我们不仅能展示该方案在理想状态下的爆发力,更能证明其在复杂生产环境下作为核心基础设施的稳定性。
详细测试
测试环境如下:
- 使用 OpenMessaging 基准测试框架,写入总吞吐 300MiB/s,Fanout 比例为 1:4;
- Server: m7g.4xlarge *3;
- WAL Storage: FSx 736MBps、1T SSD、3072IOPS;
- Client: m7g.4xlarge *3;
- 集群水位满载运行;
耗时最短的场景
为了探测系统的物理性能上限,我们构建了一个"零排队"的理想环境,重点调整了影响时延的关键参数:
batch.size=64K、linger.ms=0(默认)- 不开压缩(开启压缩会降低写入吞吐量,带来更低的写入延迟,降低测试场景的挑战)
具体配置如下:
ini
name: Kafka
driverClass: io.openmessaging.benchmark.driver.kafka.KafkaBenchmarkDriver
# Kafka client-specific configuration
replicationFactor: 1
topicConfig: |
min.insync.replicas=2
commonConfig: |
bootstrap.servers=10.0.0.112:9092
producerConfig: |
acks=1
batch.size=65536
client.id=automq_type=producer&automq_az=us-east-1b
consumerConfig: |
auto.offset.reset=earliest
enable.auto.commit=true
client.id=automq_type=consumer&automq_az=us-east-1b- Record Size = 64 KB
- 写入 TPS = 4,800
- 分区总数 = 96
- Producer 数量 = 48
工作负载配置如下:
vbnet
name: Lowest latency case
topics: 1
partitionsPerTopic: 32
messageSize: 65536
payloadFile: "payload/payload-64Kb.data"
subscriptionsPerTopic: 4
consumerPerSubscription: 16
producersPerTopic: 16
producerRate: 1600
consumerBacklogSizeGB: 0运行结果
写入总吞吐图 300MiB/s,读取约 1.2GiB/s;
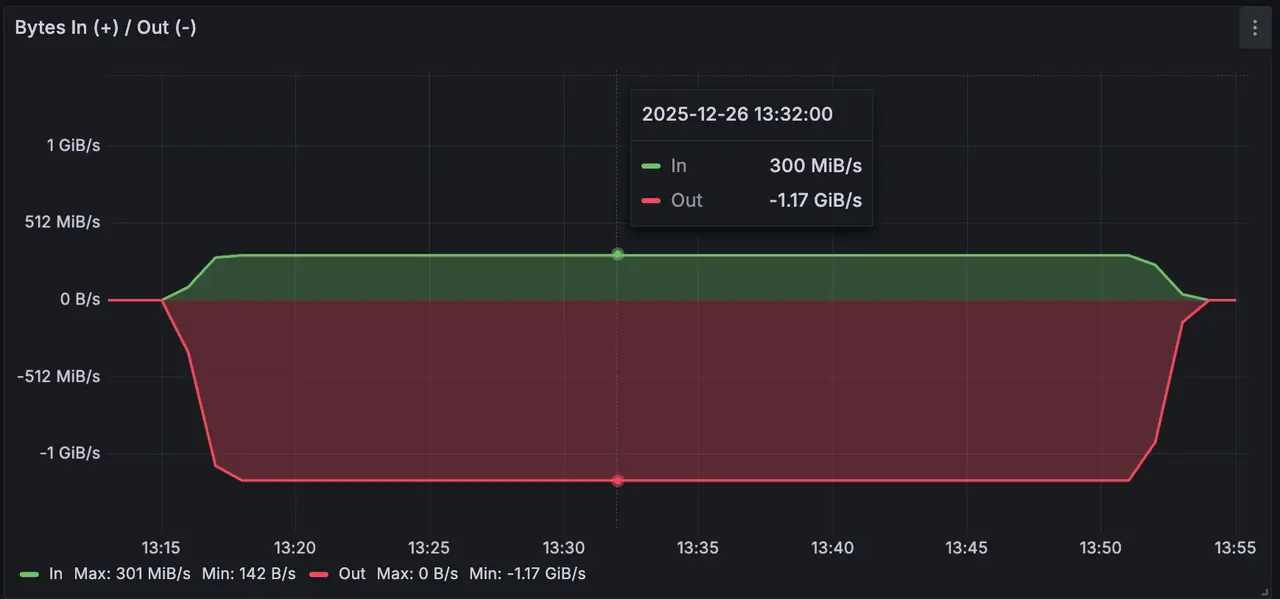
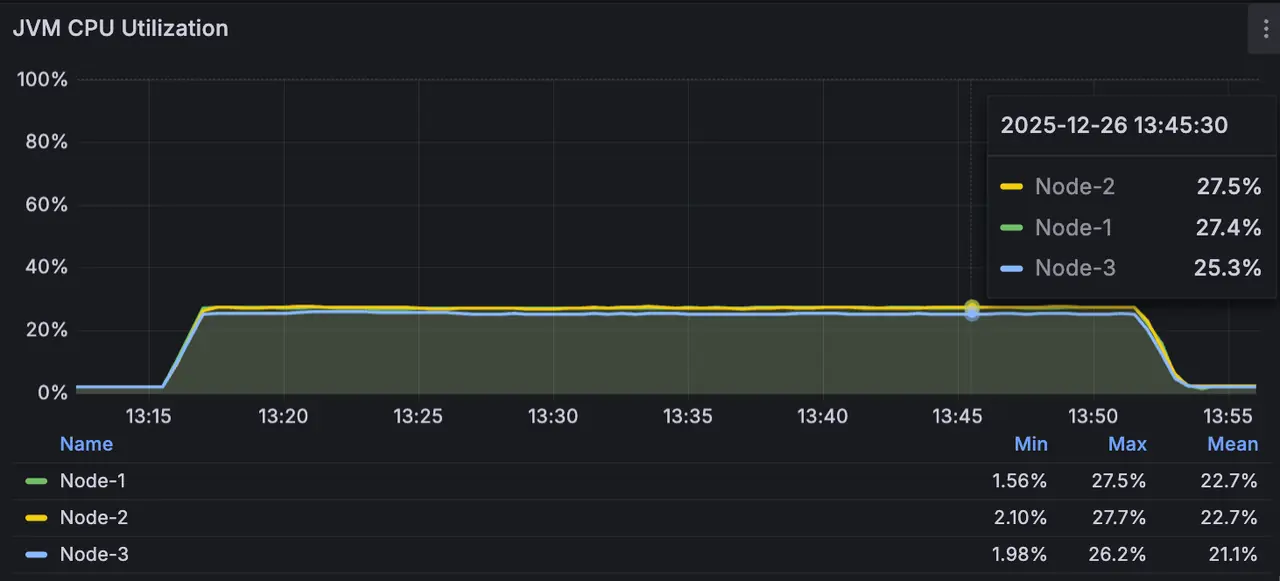
CPU 消耗约 27.5%,内存占用约 10G;
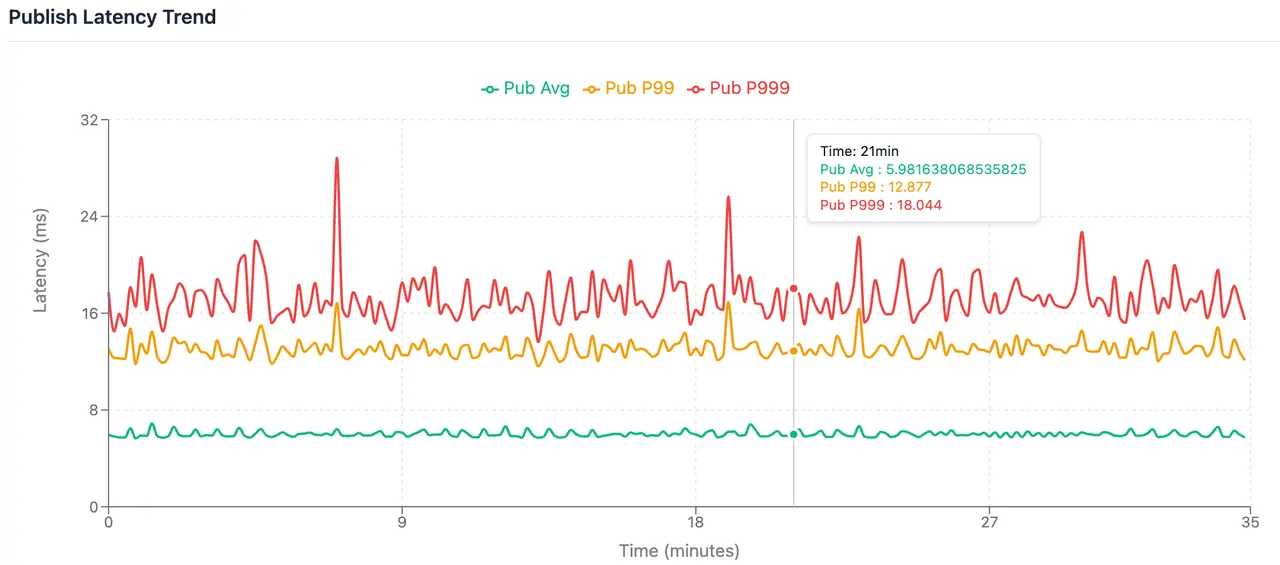
写入平均延迟 6.0ms、P99 13.11ms、P999 17.68ms;
端到端平均延迟 7.79ms、19.0ms、29.0ms;
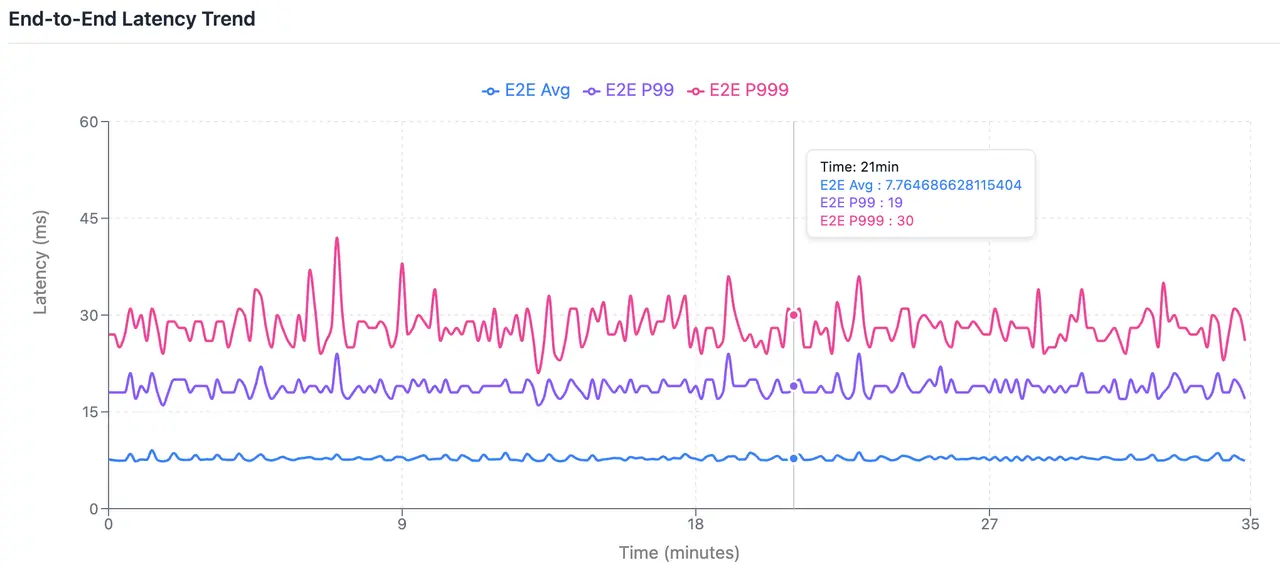

linger.ms=0 即不等待攒批完成,如果当前进行中请求不超过请求最大并发数,则会立即将消息发送到服务端,这种情况下耗时客户端耗时最短。但当随着业务量峰谷的变化,写入吞吐量、TPS 上涨等,可能会受请求并发数限制产生额外的客户端排队,从而影响最终的延迟。
所以,该场景为理想情况下的延迟;虽然耗时更短,但容易受业务量、客户端数量的影响出现起伏,不够稳定。
耗时更加稳定的场景
既然极致性能场景存在波动的风险,那么在追求吞吐量与稳定性平衡的生产环境下,AutoMQ 的表现又会如何呢?接下来让我们观察在开启客户端攒批后的稳态测试结果。
batch.size=64Klinger.ms=3(根据服务端处理耗时估算出客户端攒批的时间)
具体配置如下:
ini
name: Kafka
driverClass: io.openmessaging.benchmark.driver.kafka.KafkaBenchmarkDriver
# Kafka client-specific configuration
replicationFactor: 1
topicConfig: |
min.insync.replicas=2
commonConfig: |
bootstrap.servers=10.0.0.112:9092
producerConfig: |
acks=1
linger.ms=3
batch.size=65536
client.id=automq_type=producer&automq_az=us-east-1b
consumerConfig: |
auto.offset.reset=earliest
enable.auto.commit=true
client.id=automq_type=consumer&automq_az=us-east-1b更小的消息会带来更多的写入消耗,为了更有通用性,我们将 recordsize 设置了更小,以使结果在更多的场景适用。
- record.size = 1K
- 写入 TPS = 307200
- 分区总数 = 96
- Producer = 15
具体工作负载配置如下:
vbnet
name: 1 Robust latency case
topics: 1
partitionsPerTopic: 32
messageSize: 1024
payloadFile: "payload/payload-1Kb.data"
subscriptionsPerTopic: 4
consumerPerSubscription: 5
producersPerTopic: 5
producerRate: 102400
consumerBacklogSizeGB: 0运行结果
写入总吞吐图 300MiB/s,读取约 1.2GiB/s;
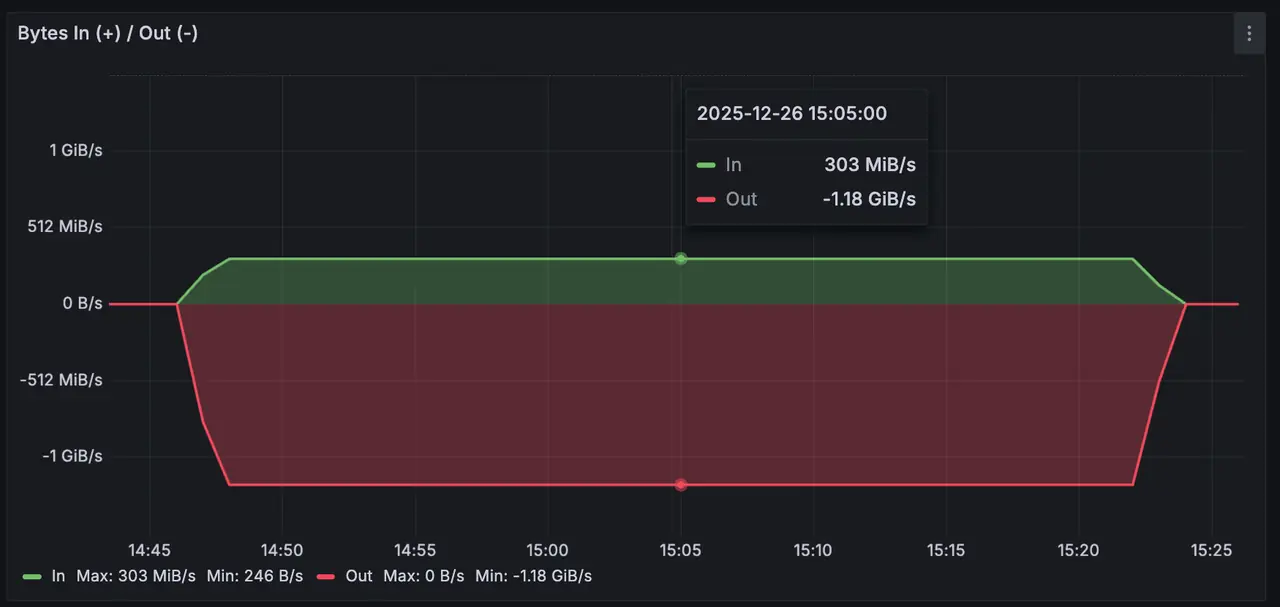
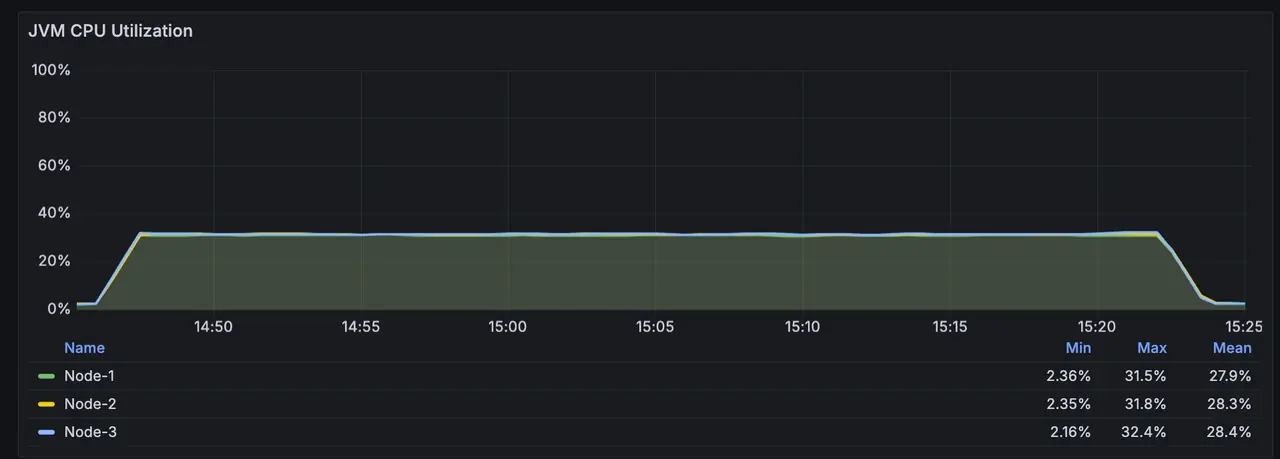
CPU 消耗约 31.5%,内存占用约 14G;
写入平均延迟 7.89ms、P99 16.30ms、P999 30.26ms;
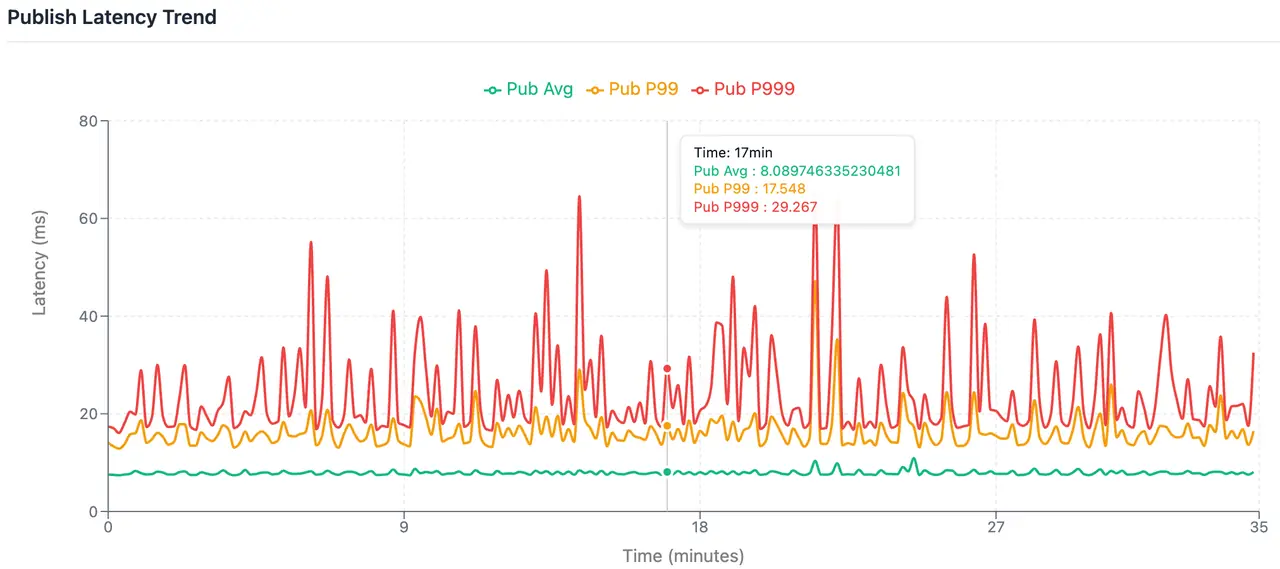
端到端平均延迟 9.88ms、22.0ms、38.0ms;
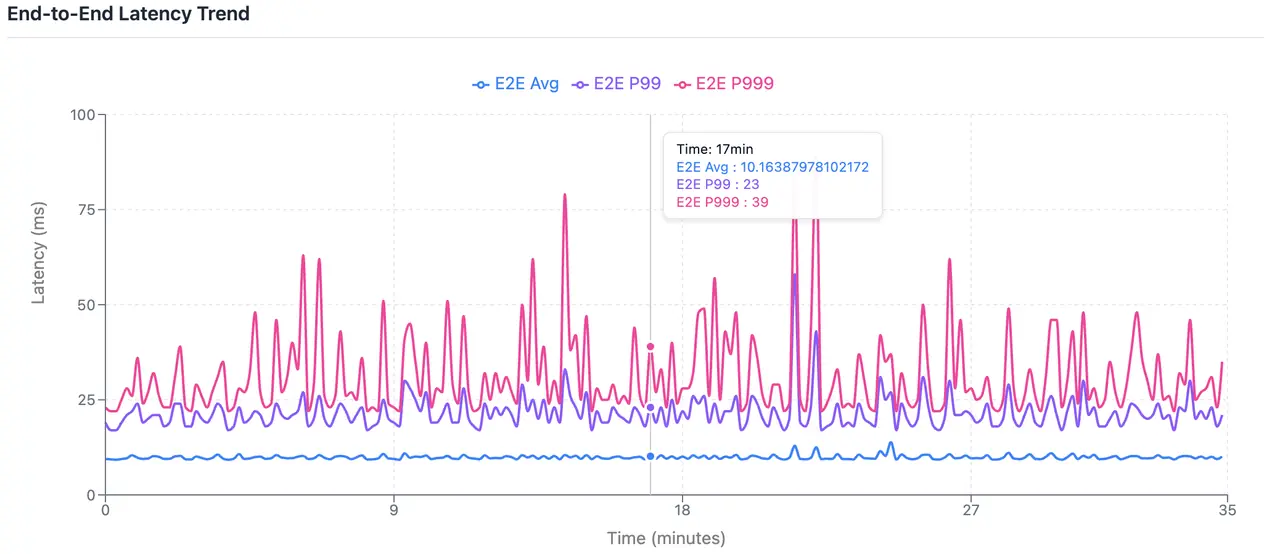

增加了linger.ms=3 会带来额外的客户端延迟,但能带来更加稳定的攒批结果,能更好的应对业务流量峰谷,集群扩缩容 Producer 数目变化对延迟的影响,能够提供更加稳定的延迟表现,在实际生产中更具有参考意义。
此外,测试用例是按照集群满负载的情况运行,对 P99、P999 的更具有挑战。AutoMQ 内部经过大量优化,以确保文件系统耗时更加稳定。
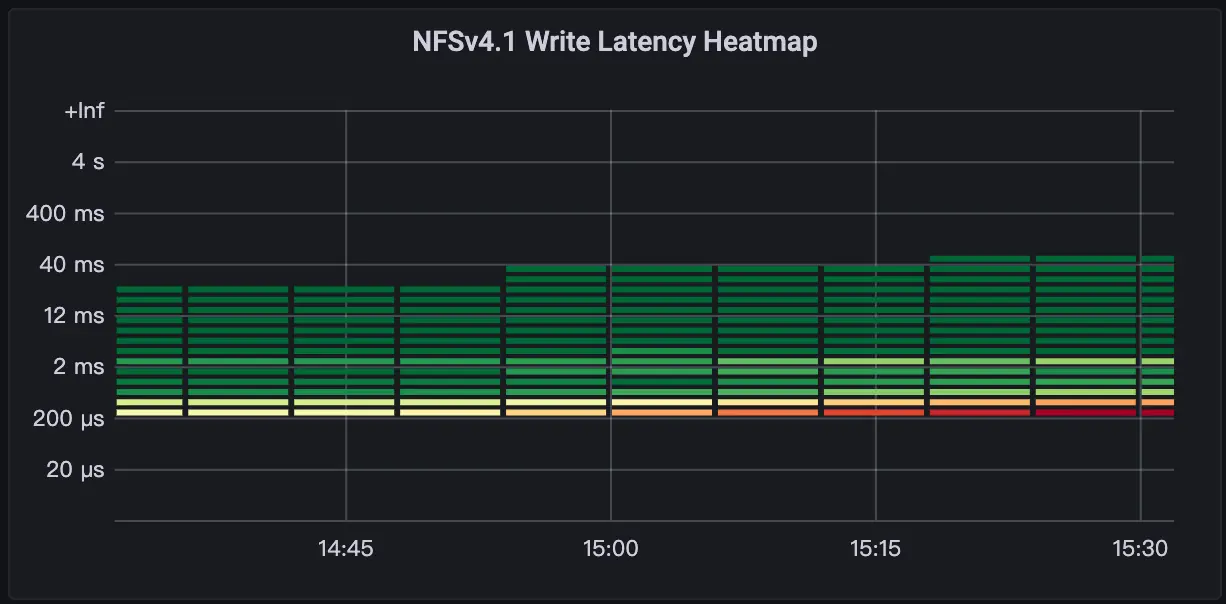
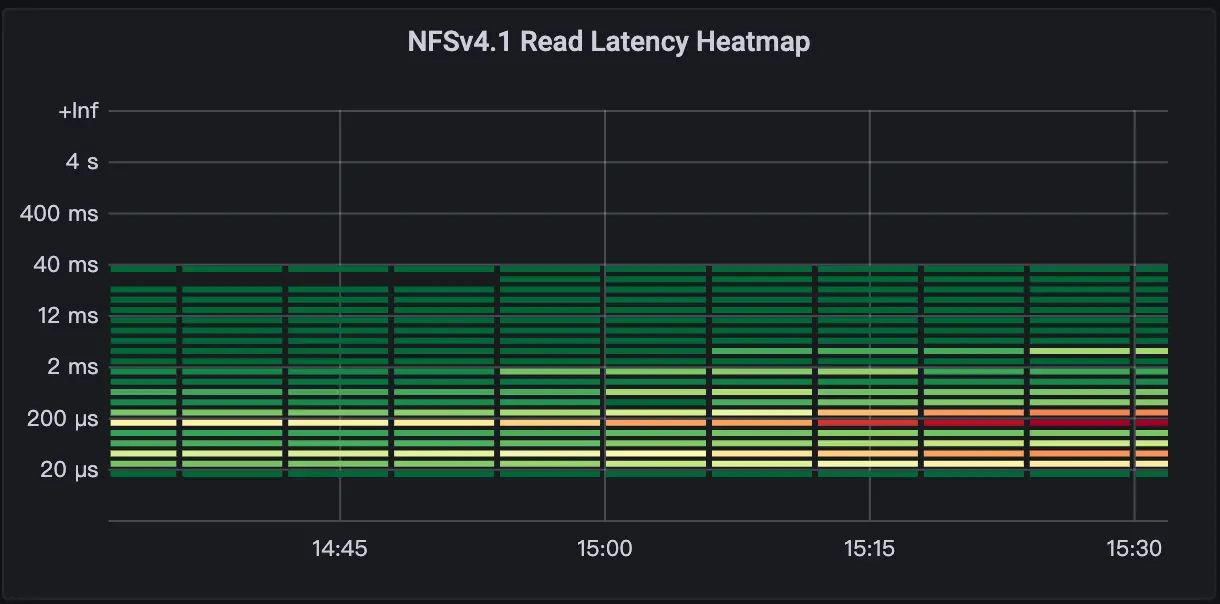
从文件系统写入延迟热力图看 90%的写入响应都在 1ms 以下,同时 91%的读取都在 1ms 以下。
关于成本
看到这里,你可能会产生疑问:既然性能实现了如此惊人的飞跃,成本是否也会随之"水涨船高"?
事实恰恰相反。在 AutoMQ 的集成架构中,FSxN 并非用于海量数据的长期堆积,而是仅作为"高速缓冲站"运行。它只负责承载极少量的最新预写日志(WAL),而海量的业务数据依然存储在价格极低的 S3 中。
为什么成本依然极低:
- 按需占用,规模固定: 由于数据会迅速沉降到 S3 存储桶,FSxN 仅需占用极小且固定的资源容量,不会随业务数据量的增长而产生高额费用。
- 省下巨额流量费: 虽然集成 FSxN 会带来少量的资源开销,但它彻底消除了传统 Kafka 最昂贵的"跨 AZ 复制流量费"。
- 99% 的存储在 S3: 绝大部分数据都存储在成本极低的 S3 上。
这意味着即使集成了 FSxN 提升性能,AutoMQ 的整体拥有成本(TCO)依然比传统 Kafka 节省近 90%。
详细可以查看:👉 AutoMQ x FSx: 10ms Latency Diskless Kafka on AWS
总结
通过引入 FSxN 作为 WAL,AutoMQ 在保持跨 AZ 容灾与 S3 存算分离优势的同时,将平均写入延迟从数百毫秒大幅降至 10ms 以内,性能表现媲美本地磁盘。这一突破彻底补齐了 Diskless 架构的性能短板,使其能够以极具竞争力的成本和高稳定性,完美支撑微服务、风控及交易撮合等延迟敏感型核心业务。