前言
Dinky 是一个开箱即用、易扩展,以 Apache Flink 为基础,连接 OLAP 和数据湖等众多框架的一站式实时计算平台,致力于流批一体和湖仓一体的探索与实践。 致力于简化Flink任务开发,提升Flink任务运维能力,降低Flink入门成本,提供一站式的Flink任务开发、运维、监控、报警、调度、数据管理等功能。
今天想给大家说一说,如何通过dinky数据开发平台提供的CDCSOURCE 整库同步方案将Mysql同步到mysql数据库中。
实现步骤
- 搭建好Flink appliction部署环境
- 定义dinky全局变量(数据库配置信息)
- 定义CDCSOURCE整库同步的脚本
步骤1.搭建好Flink appliction部署环境
参考之前的文章。
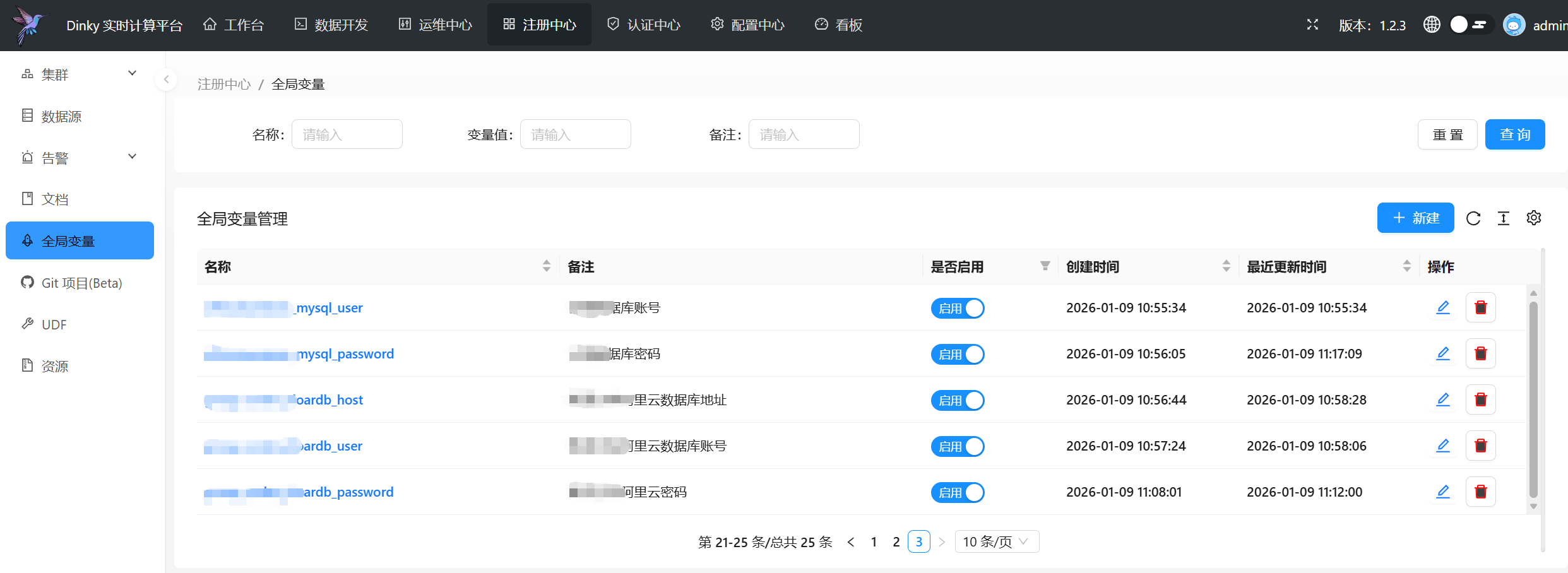
步骤2.定义Dinky全局变量
定义Dinky中的全局变量
mysql1_host
mysql1_user
mysql1_password
...
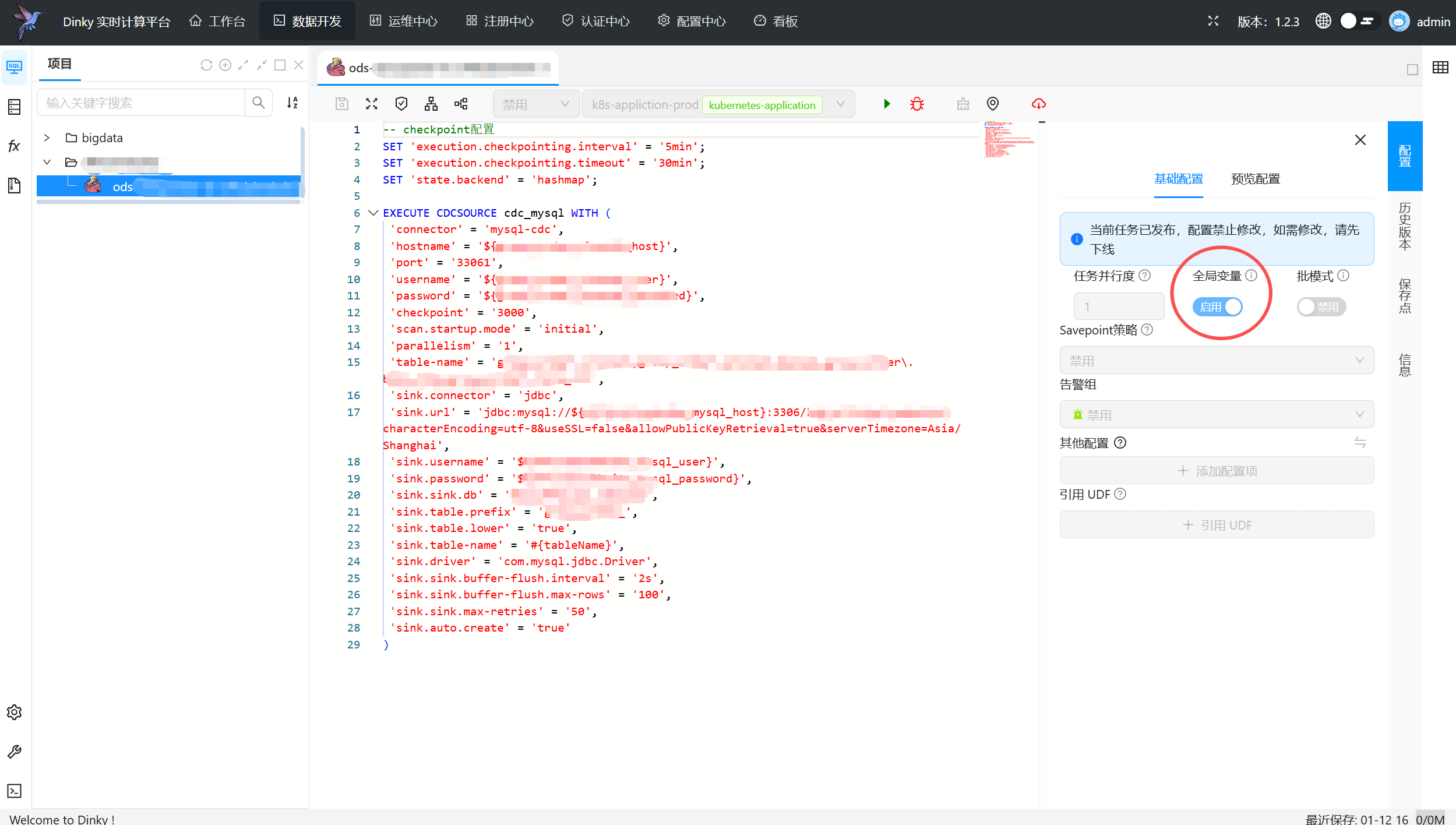
步骤3.定义CDCSOURCE整库同步的脚本
创建作业ods-mysql-to-mysql,选择flink集群为k8s-appliction-test
使用步骤2的全局变量
${mysql1_host}
${mysql1_user}
${mysql1_password}
...
-- checkpoint配置
SET 'execution.checkpointing.interval' = '5min';
SET 'execution.checkpointing.timeout' = '30min';
EXECUTE CDCSOURCE cdc_mysql WITH (
'connector' = 'mysql-cdc',
'hostname' = '${mysql1_host}',
'port' = '3306',
'username' = '${mysql1_user}',
'password' = '${mysql1_password}',
'checkpoint' = '3000',
'scan.startup.mode' = 'initial',
'parallelism' = '1',
'table-name' = 'db1\.tb1,db1\.tb2',
'sink.connector' = 'jdbc',
'sink.url' = 'jdbc:mysql://${mysql2_host}:3306/db2?characterEncoding=utf-8&useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai',
'sink.username' = '${mysql2_user}',
'sink.password' = '${mysql2_password}',
'sink.sink.db' = 'db2',
'sink.table.prefix' = 'prefix_',
'sink.table.lower' = 'true',
'sink.table-name' = '#{tableName}',
'sink.driver' = 'com.mysql.jdbc.Driver',
'sink.sink.buffer-flush.interval' = '2s',
'sink.sink.buffer-flush.max-rows' = '100',
'sink.sink.max-retries' = '50',
'sink.auto.create' = 'true'
)
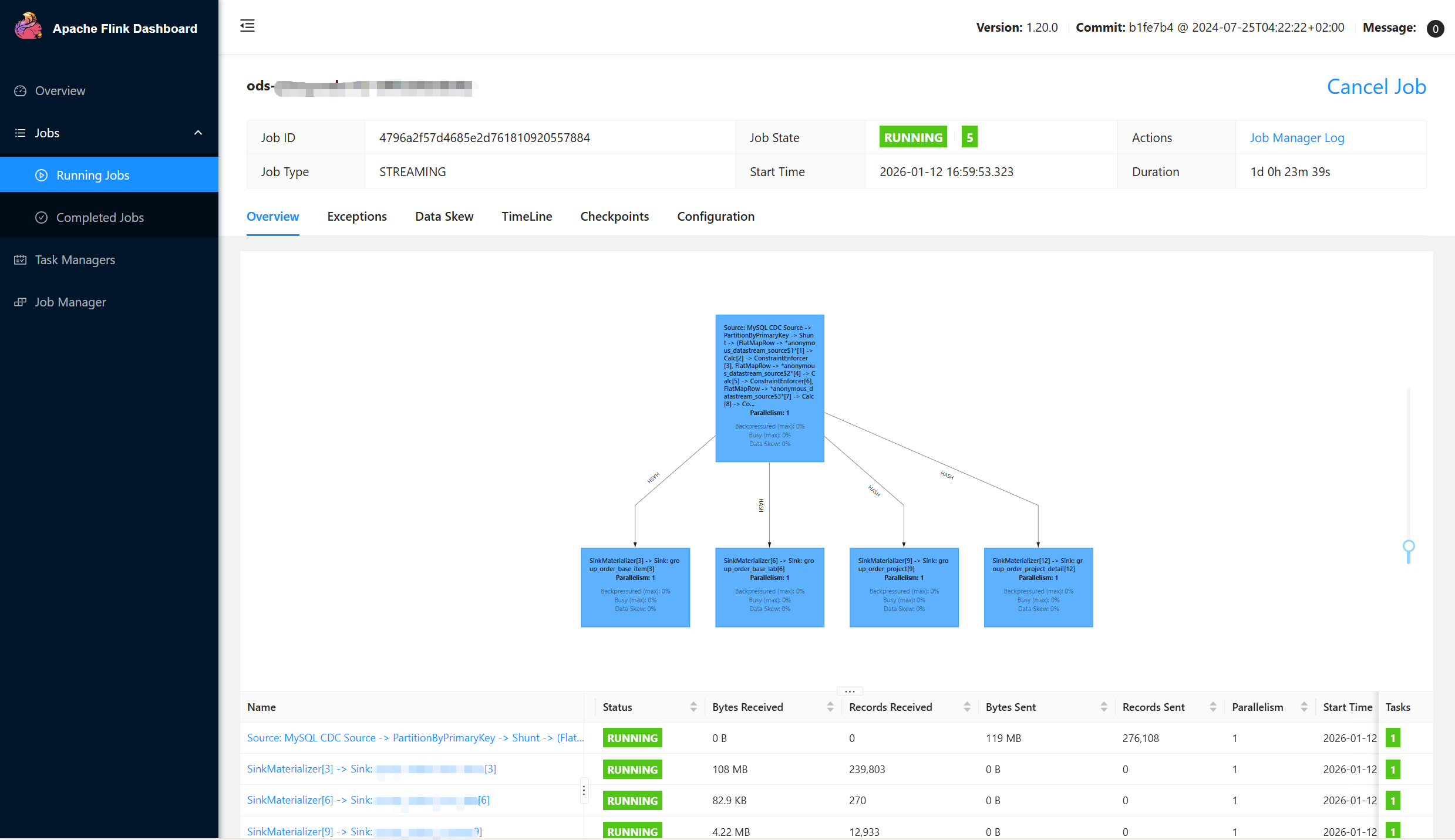
Flink作业运行如下
总结
- Dinky 定义了 CDCSOURCE 整库同步的语法,该语法和 CDAS 作用相似,可以直接自动构建一个整库入仓入湖的实时任务,并且对 source 进行了合并,不会产生额外的 Mysql 及网络压力,支持对任意 sink 的同步,如 kafka、doris、hudi、jdbc 等等
- Dinky中的作业开启前,如果使用了全局变量,务必启用全局变量配置的开关,否则提交作业会报错。
- 解决了单个Flink作业造成的大量的 DDL 和编写大量的 INSERT INTO,更为严重的是会占用大量的数据库连接,对 Mysql 和网络造成压力。