一、RabbitMQ 核心架构
1.1 RabbitMQ 基础定位
- RabbitMQ是一款基于AMQP 0-9-1 高级消息队列协议实现的开源消息中间件,由Erlang语言开发,天然支持高并发、高可用
- 核心设计理念:生产者与消费者解耦,通过消息队列做中间件,实现异步通信、流量削峰、分布式任务分发等核心能力
- 核心优势:轻量、稳定、易部署、生态完善,支持多语言客户端(Java/Go/Python/PHP等),是企业级分布式架构中最常用的MQ之一
1.2 整体核心架构(核心角色)
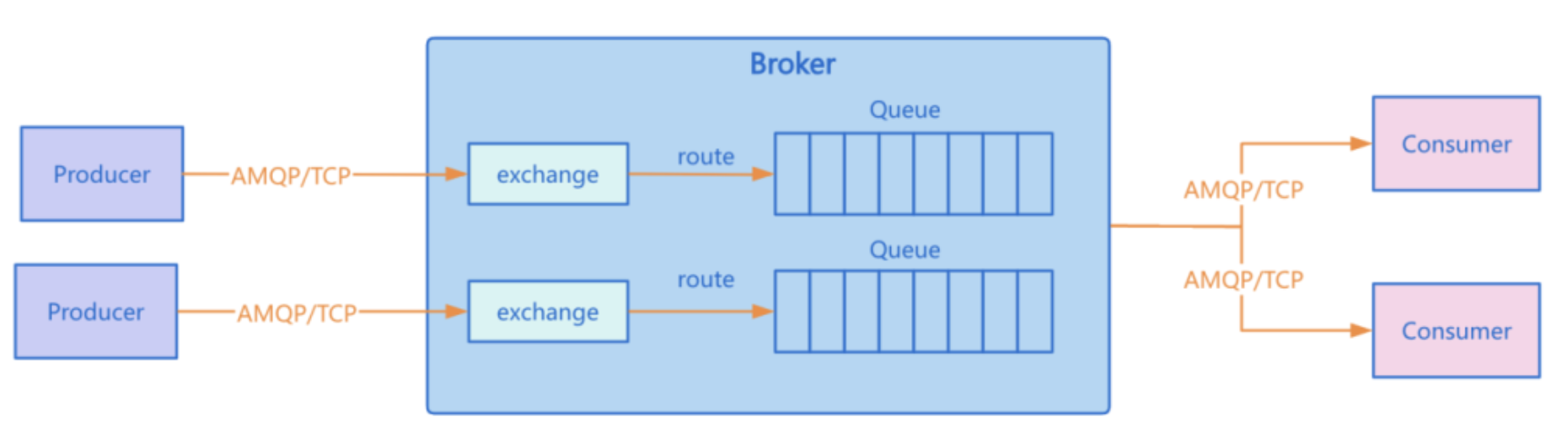
- Producer(生产者):消息的发送方,负责创建并发送消息到RabbitMQ,不直接与队列通信,仅与交换机交互
- Consumer(消费者):消息的接收方,监听队列并消费队列中的消息,消费完成后给出消费确认
- Broker(服务节点):RabbitMQ服务实例本身,一个Broker就是一个RabbitMQ服务节点,多个Broker可组成集群
- Client(客户端):生产者和消费者的统称,通过RabbitMQ提供的SDK与Broker建立连接进行消息交互
1.3 RabbitMQ 集群架构模式(高可用核心)
RabbitMQ的集群架构是保障高可用的核心,所有架构均基于主从、分片、镜像 三大思想设计,无单点故障风险:
- 普通集群(默认):多个节点共享元数据(交换机、队列、绑定关系),队列数据仅存储在一个节点,其他节点只存路由信息;优点是轻量,缺点是队列节点宕机则队列不可用
- 镜像集群(生产首选) :队列数据会镜像同步到集群中多个节点,主节点宕机后,从节点无缝接管队列;优点是高可用、无数据丢失,缺点是集群性能略有损耗,是企业生产核心选型
- 联邦集群:跨地域/跨网络的RabbitMQ集群互联,实现消息的跨集群路由与同步,适合异地多活架构
- 分片集群:将一个大队列拆分为多个分片队列分布在不同节点,解决单队列的性能瓶颈,适合超高频消息场景
二、RabbitMQ 核心概念(基础基石)
2.1 核心消息模型组件(四大金刚,缺一不可)
所有RabbitMQ的消息流转,均基于这四个核心组件完成,是RabbitMQ的核心骨架,必须熟记
-
Exchange(交换机)- 核心作用:接收生产者发送的消息,根据绑定规则将消息路由到对应的队列,交换机不存储消息
- 核心特性:如果交换机没有找到匹配的队列,消息会被丢弃(除非开启死信机制);交换机必须声明后才能使用,支持持久化配置
-
Queue(队列)- 核心作用:RabbitMQ中唯一存储消息的组件,所有消息最终都会落到队列中,消费者只能从队列中消费消息
- 核心特性:队列是RabbitMQ的核心存储单元,支持持久化、排他性、自动删除三大核心属性,是消息可靠性的核心载体
-
Binding(绑定)- 核心作用:将交换机与队列建立关联关系 ,并指定绑定规则(
BindingKey),交换机通过绑定关系完成消息路由 - 核心特性:一个交换机可以绑定多个队列,一个队列也可以绑定多个交换机,多对多的关联关系
- 核心作用:将交换机与队列建立关联关系 ,并指定绑定规则(
-
Message(消息)- 核心作用:生产者与消费者之间传递的数据载体,是业务数据的封装
- 消息组成:
消息体(payload)+消息属性(Properties),消息体是业务数据(JSON/字符串/二进制),消息属性包含路由键、优先级、过期时间、持久化标识等核心配置
2.2 核心标识关键字
RoutingKey(路由键):生产者发送消息时指定的路由规则,交换机通过该值匹配绑定规则,完成消息路由BindingKey(绑定键):交换机与队列绑定时指定的匹配规则,与RoutingKey配合完成消息的精准路由Virtual Host(虚拟主机,VHost):RabbitMQ的资源隔离单元 ,相当于数据库的库,每个VHost拥有独立的交换机、队列、绑定关系、权限配置;默认VHost为/,生产建议按业务划分独立VHost,实现资源隔离
2.3 核心网络通信组件
Connection(连接) :生产者/消费者与RabbitMQ Broker之间建立的TCP长连接,建立TCP连接的开销较大,不建议频繁创建和销毁Channel(信道) :建立在Connection之上的轻量级连接 ,是RabbitMQ的性能优化核心 ;所有的消息发送、接收、声明队列/交换机的操作,均通过Channel完成- 核心优势:一个Connection可以创建多个Channel,复用同一个TCP连接,大幅降低TCP连接的开销,RabbitMQ推荐所有操作基于Channel完成,这是生产调优的基础
2.4 交换机的4种核心类型(路由核心)
RabbitMQ的核心灵活性体现在交换机的路由规则,4种固定类型,无其他类型,所有业务路由场景均基于这4种类型实现,面试必考!
-
direct(直连交换机,默认)- 路由规则:RoutingKey 与 BindingKey 完全精准匹配,才能将消息路由到对应队列
- 核心特点:一对一的精准路由,一个消息只能路由到一个匹配的队列
- 适用场景:单业务精准推送、订单状态通知、用户私信等一对一的业务场景
-
fanout(扇出交换机/广播交换机)- 路由规则:无视RoutingKey和BindingKey ,只要队列绑定了该交换机,消息会广播到所有绑定的队列
- 核心特点:广播模式,消息无差别分发,性能最高,无路由匹配开销
- 适用场景:消息广播、日志收集、数据同步、多服务订阅同一消息的场景
-
topic(主题交换机/通配符交换机)- 路由规则:支持通配符模糊匹配 ,是最灵活的路由方式;BindingKey支持两个通配符:
*匹配一个单词 ,#匹配零个或多个单词 (单词以.分隔) - 示例:RoutingKey为
order.pay.success,可以匹配BindingKey为order.*.success/order.#的队列 - 适用场景:多业务模糊匹配、按业务模块分发消息、日志分级推送等绝大多数业务场景,生产中使用最多的类型
- 路由规则:支持通配符模糊匹配 ,是最灵活的路由方式;BindingKey支持两个通配符:
-
headers(头交换机)- 路由规则:无视RoutingKey,通过消息的header属性 匹配绑定规则,匹配成功则路由到对应队列
- 核心特点:匹配规则灵活,但性能较低,路由开销大
- 适用场景:极少使用,仅在需要通过消息头做复杂匹配的特殊场景使用,一般被topic替代
三、RabbitMQ 核心工作机制(核心原理)
3.1 消息生产→投递→存储 完整流程(生产者侧)
这是RabbitMQ最核心的工作流程,所有消息的流转均遵循此规则,无任何例外:
- 生产者与RabbitMQ Broker建立
TCP Connection连接,基于连接创建Channel信道 - 生产者通过Channel声明交换机 、声明队列 、建立交换机与队列的Binding绑定关系(可提前在控制台配置,无需代码声明)
- 生产者封装业务数据为Message,指定
Exchange、RoutingKey和消息属性,通过Channel发送消息 - Broker接收消息后,交由指定的交换机处理,交换机根据自身类型+RoutingKey+BindingKey匹配对应的队列
- 匹配成功:消息被投递到匹配的队列中,队列根据自身配置(持久化/内存)完成消息存储
- 匹配失败:无任何队列匹配时,消息被直接丢弃(若配置了死信交换机,则会投递到死信队列)
3.2 消息存储机制
RabbitMQ的消息存储分为内存存储 和磁盘存储,队列的配置决定存储方式,是消息可靠性的核心:
- 内存队列:消息仅存储在内存中,读写性能极高,但Broker宕机后消息全部丢失,适合非核心的临时消息
- 持久化队列 :消息会同时写入内存和磁盘 ,内存做缓存提升读写效率,磁盘做持久化保障数据不丢失;Broker宕机重启后,消息可从磁盘恢复,生产核心业务必须配置持久化队列
- 存储规则:RabbitMQ会对内存中的消息做异步刷盘,同时支持内存阈值触发刷盘,保证内存不会溢出
3.3 消息拉取→消费→确认 完整流程(消费者侧)
消费者的消费逻辑是保障消息不重复、不丢失的核心,所有消费规则均由消费者控制,核心流程:
- 消费者与Broker建立
TCP Connection连接,基于连接创建Channel信道 - 消费者通过Channel监听指定的队列,并配置消费相关参数(预取值、手动/自动确认)
- Broker检测到队列中有消息,根据消费者的预取值,将消息推送给消费者(推模式),消费者也可主动拉取消息(拉模式)
- 消费者接收到消息后,执行业务处理逻辑(如更新数据库、调用接口、处理业务数据)
- 消费完成后,消费者向Broker发送消费确认(ACK),Broker收到ACK后,将该消息从队列中删除
- 消费失败:消费者可发送拒绝确认(NACK),Broker会根据配置决定是否重新投递消息到队列,或投递到死信队列
3.4 核心消息确认机制(RabbitMQ的灵魂,可靠性核心)
RabbitMQ提供三层完整的确认机制 ,从生产到消费全链路保障消息的可靠性,杜绝消息丢失,这是RabbitMQ的核心优势,生产必须全部启用
3.4.1 生产者确认机制(Publisher Confirm)
保障:生产者发送的消息,能被Broker成功接收并存储,杜绝生产者发送消息后丢失的问题
- 核心规则:生产者开启确认机制后,每发送一条消息,Broker都会返回一个确认回执,告知生产者消息是否投递成功
- 两种模式:普通确认(单条消息单确认)、批量确认(多条消息批量确认),批量确认性能更高,生产推荐使用
3.4.2 生产者退回机制(Publisher Return)
保障:生产者发送的消息被交换机接收,但无匹配队列时,能被生产者感知,避免消息无声丢弃
- 核心规则:开启退回机制后,无匹配队列的消息会被Broker退回给生产者,生产者可对退回的消息做重试/存储/告警处理
3.4.3 消费者确认机制(Consumer ACK)
保障:消费者只有成功处理完消息后,才会告知Broker删除消息,杜绝消费过程中消息丢失的问题,分为两种模式,生产严禁使用自动确认
- 自动确认(autoAck=true) :消费者接收到消息后,立即向Broker发送ACK,Broker直接删除消息;若消费者处理消息时宕机,消息永久丢失,仅适合非核心消息
- 手动确认(autoAck=false) :消费者处理完消息后,手动调用API发送ACK;处理失败则发送NACK,生产核心业务必须使用手动确认,这是保障消息不丢失的核心配置
四、RabbitMQ 核心特性(核心能力+优势)
4.1 核心可靠性保障特性(重中之重)
4.1.1 全链路持久化机制
RabbitMQ的持久化是消息不丢失的基础 ,需要三层持久化配置缺一不可,否则持久化失效:
- 交换机持久化:声明交换机时指定
durable=true,Broker宕机后交换机元数据不丢失 - 队列持久化:声明队列时指定
durable=true,Broker宕机后队列元数据和消息数据不丢失 - 消息持久化:发送消息时指定
deliveryMode=2,消息会被写入磁盘,内存宕机后消息可恢复
4.1.2 死信队列(DLX,Dead Letter Exchange)
死信队列 是RabbitMQ的核心容错机制,用于存储处理失败、过期、被拒绝的异常消息,是生产中排查问题、保障业务稳定的必备能力
- 死信触发条件(满足其一即可):
- 消息被消费者拒绝(NACK) 且不重新投递(requeue=false)
- 消息到达过期时间(TTL) 仍未被消费
- 队列达到最大长度,新消息入队时挤掉旧消息
- 核心价值:异常消息不会阻塞正常消息消费,可对死信消息做单独的重试、人工排查、归档处理,保障主业务不受影响
4.1.3 延迟队列
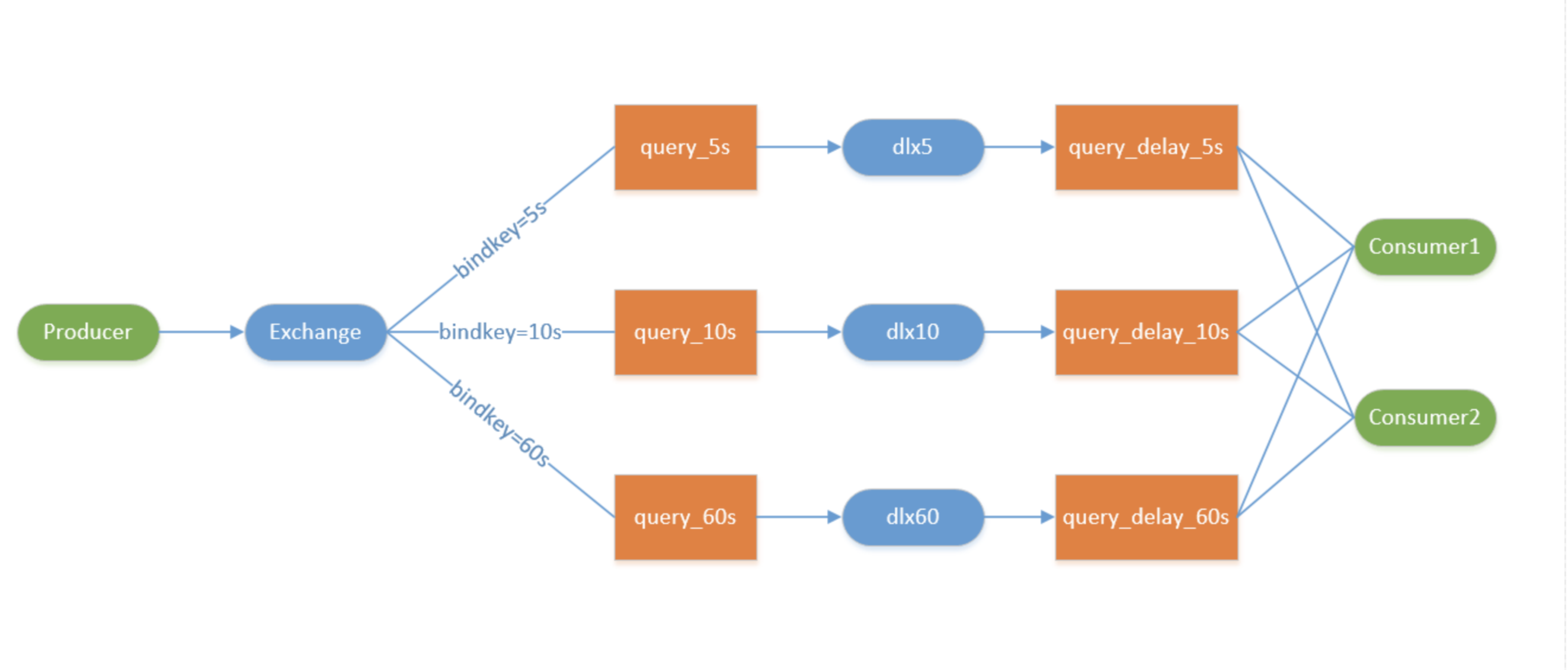
RabbitMQ本身没有原生的延迟队列,但可通过死信队列+消息TTL 实现延迟队列功能,是业务中实现延迟任务的核心方案
- 实现原理:消息发送到一个无消费者的队列,给消息配置过期时间(TTL),队列绑定死信交换机;消息过期后被投递到死信队列,消费者监听死信队列完成延迟消费
- 适用场景:订单超时关闭、支付超时提醒、物流状态延迟推送、定时任务触发等
4.2 核心性能与灵活配置特性
- 消息优先级:支持为消息设置优先级(0-255),优先级高的消息会被优先消费,适合核心业务消息插队的场景(如VIP订单优先处理)
- 消费限流 :通过配置
prefetchCount(预取值),控制Broker每次推送给消费者的消息数量,防止消费者被海量消息压垮,是削峰的核心配置 - 惰性队列:消息优先存储在磁盘,内存中只保留少量消息,适合消息堆积量大的场景,大幅降低内存占用
- 消息重试机制:消费失败的消息可配置自动重试,重试次数达到阈值后投递到死信队列,避免消息无限重试阻塞业务
- 事务机制 :RabbitMQ支持事务,生产者发送消息时开启事务,消息投递失败则回滚,成功则提交;但事务会大幅降低性能,生产中一般用生产者确认机制替代事务
4.3 核心高可用特性
- 镜像队列:队列数据同步到集群多个节点,主节点宕机后从节点无缝接管,无数据丢失、无服务中断
- 队列镜像策略:支持按队列配置镜像节点数量,可灵活配置核心队列多镜像、非核心队列少镜像,平衡性能与高可用
- 故障自动转移:集群中节点宕机后,其他节点自动接管宕机节点的队列和交换机,无需人工干预
- 持久化存储:所有核心数据均支持磁盘持久化,Broker重启后可快速恢复服务和数据
五、RabbitMQ 关键运维与配置要点
5.1 核心配置优化(生产必改,性能+稳定性双提升)
所有配置均在RabbitMQ的核心配置文件rabbitmq.conf中修改,是运维调优的核心,优先级最高的几个配置:
- 内存阈值配置 :
vm_memory_high_watermark.relative = 0.7,内存占用达到70%时触发流控,拒绝新消息写入,防止内存溢出 - 磁盘阈值配置 :
disk_free_limit.absolute = 500MB,磁盘剩余空间低于500MB时触发流控,保障磁盘有足够空间做持久化 - 连接池配置 :
tcp_listeners = 5672,调整TCP监听端口的连接数,支持更多客户端连接 - 信道复用 :生产中必须复用Channel,一个Connection创建多个Channel,杜绝频繁创建TCP连接
- 预取值配置 :消费者设置
prefetchCount=10(根据业务调整),控制每次推送的消息数,防止消费者过载
5.2 核心运维命令
RabbitMQ提供rabbitmqctl命令行工具,所有运维操作均可通过命令完成,核心高频命令:
- 启动/停止RabbitMQ服务:
rabbitmq-server start/rabbitmqctl stop - 查看队列状态:
rabbitmqctl list_queues name messages_ready messages_unacknowledged - 查看交换机状态:
rabbitmqctl list_exchanges name type - 查看连接状态:
rabbitmqctl list_connections name port state - 查看消费者状态:
rabbitmqctl list_consumers queue name - 清除队列消息:
rabbitmqctl purge_queue 队列名 - 开启管理控制台:
rabbitmq-plugins enable rabbitmq_management(浏览器访问http://ip:15672,默认账号guest/guest)
5.3 生产高频运维问题与解决方案
5.3.1 消息堆积问题(最常见)
- 问题现象:队列中的消息数持续增长,消费速度远低于生产速度,队列堆积严重
- 核心原因:消费者宕机、消费速度慢、生产速度过高、消费逻辑阻塞
- 解决方案:
- 扩容消费者节点,增加消费能力
- 优化消费逻辑,提升单消费者处理速度(如异步处理、减少数据库操作)
- 配置队列限流,控制生产速度
- 使用分片队列,拆分大队列到多个节点
- 堆积严重时,临时将消息转存到其他存储,消费完后再恢复
5.3.2 消息重复消费问题
- 问题现象:同一条消息被消费者多次消费,导致业务数据重复(如重复下单、重复扣款)
- 核心原因:消费者发送ACK后,Broker未收到回执就宕机,重启后重新推送消息;网络抖动导致ACK丢失
- 解决方案:消费端实现幂等性(核心),通过业务唯一标识(订单号、消息ID)判断消息是否已处理,已处理则直接返回成功,不执行业务逻辑
5.3.3 消息丢失问题
- 问题现象:消息发送后,队列中无消息,或消费后业务未处理成功但消息已被删除
- 核心原因:未开启持久化、未开启生产者确认、使用自动ACK、Broker宕机、队列配置错误
- 解决方案:开启三层持久化 +生产者确认机制 +消费者手动ACK,全链路配置可靠性保障,这是根治消息丢失的唯一方案
5.3.4 集群节点宕机
- 问题现象:集群中某个节点宕机,部分队列不可用
- 解决方案:配置镜像队列,核心队列必须镜像到至少2个节点;宕机后手动重启节点,RabbitMQ会自动同步数据并恢复服务
5.4 权限与安全配置
- 生产环境禁用guest账号,创建独立的业务账号,并分配对应VHost的读写权限
- 限制IP访问,只允许业务服务器的IP连接RabbitMQ,防止非法访问
- 开启SSL加密,对TCP连接做加密处理,防止消息被窃听
- 定期清理无效连接和信道,释放服务器资源
六、RabbitMQ 核心使用场景
RabbitMQ的核心价值是解耦、异步、削峰 ,所有业务场景均围绕这三个核心价值展开,以下是生产中最常用的核心场景,覆盖99%的业务需求,按场景选型即可,无需纠结技术选型
6.1 异步通信场景(最核心,使用最多)
- 业务场景:用户注册后发送验证码、下单后发送短信通知、支付完成后推送物流信息、业务操作后记录日志
- 核心价值:将同步的业务操作改为异步,主业务流程无需等待通知/日志操作完成,大幅提升接口响应速度,降低服务耦合度
- 典型案例:电商用户注册,注册成功后发送短信验证码,通过RabbitMQ异步发送,主接口直接返回注册成功,无需等待短信发送结果
6.2 服务解耦场景
- 业务场景:电商下单后,订单服务需要通知库存服务扣减库存、支付服务创建支付单、物流服务创建物流单、风控服务做风险校验
- 核心价值:各服务之间通过RabbitMQ通信,无需直接调用对方接口,服务之间完全解耦;某个服务宕机,不会影响其他服务的正常运行,服务扩容/下线无需修改其他服务代码
- 核心优势:提升系统的扩展性和可维护性,是分布式架构的核心设计思想
6.3 流量削峰填谷场景(高并发核心)
- 业务场景:电商秒杀、双十一抢购、直播间下单、节日促销等短时间内产生海量请求的场景
- 核心价值:海量请求会被先投递到RabbitMQ队列中,消费者按自身处理能力匀速消费,避免直接压垮数据库/业务服务,实现削峰填谷,保障系统稳定运行
- 核心特点:队列做缓冲,请求峰值被平摊,系统不会因突发流量宕机,这是高并发架构的必备能力
6.4 任务分发与并行处理场景
- 业务场景:大数据批量处理、报表生成、文件解析、视频转码、分布式计算等耗时任务
- 核心价值:将一个大任务拆分为多个小任务,通过RabbitMQ分发到多个消费者节点并行处理,大幅提升任务处理效率,缩短处理时间
- 典型案例:上传一个大文件后,拆分为多个分片,通过RabbitMQ分发到多个服务节点解析,解析完成后合并结果
6.5 消息广播与多服务订阅场景
- 业务场景:系统配置更新、数据同步、日志收集、状态通知等需要多个服务同时接收同一消息的场景
- 核心价值:通过
fanout交换机实现消息广播,所有订阅的服务均可接收消息,无需单独推送,简化业务逻辑 - 典型案例:后台修改系统配置后,广播消息到所有服务节点,各节点实时更新本地配置,无需重启服务
6.6 跨服务数据同步场景
- 业务场景:微服务架构中,各服务的数据库独立,需要同步核心数据(如用户信息、商品信息)到其他服务
- 核心价值:通过RabbitMQ监听数据变更,实时推送变更消息到其他服务,实现数据的最终一致性,避免分布式数据不一致问题
七、RabbitMQ 常见问题
1 基础概念类
-
问题 :RabbitMQ 的核心组件有哪些?各自的作用是什么?
答案:核心组件包含4个,缺一不可:Exchange(交换机) :接收生产者发送的消息,根据RoutingKey和绑定规则路由到队列,不存储消息;Queue(队列):RabbitMQ中唯一存储消息的组件,消费者只能从队列消费消息;Binding(绑定) :建立交换机与队列的关联关系,指定BindingKey匹配规则;Message(消息):业务数据载体,包含消息体和属性(路由键、优先级、持久化标识等)。
-
问题 :RabbitMQ 交换机有哪几种类型?各自的路由规则是什么?
答案:共4种核心类型,路由规则不同:direct(直连交换机) :RoutingKey与BindingKey完全精准匹配,一对一路由;fanout(扇出交换机) :无视RoutingKey和BindingKey,广播消息到所有绑定队列;topic(主题交换机) :支持通配符匹配,*匹配一个单词,#匹配零个或多个单词,是生产最常用类型;headers(头交换机) :通过消息头属性匹配,不依赖RoutingKey,性能低,极少使用。
-
问题 :为什么 RabbitMQ 要使用
Channel而不是直接使用Connection?
答案 :核心是降低TCP连接开销:Connection是生产者/消费者与Broker的TCP长连接,创建和销毁开销大;Channel是基于Connection的轻量级连接,一个Connection可创建多个Channel,所有消息操作都通过Channel完成;- 优势:复用TCP连接,减少资源占用,提升并发性能。
-
问题 :什么是
Virtual Host(VHost)?作用是什么?
答案 :VHost是RabbitMQ的资源隔离单元 ,相当于数据库的"库";每个VHost拥有独立的交换机、队列、绑定关系和权限配置;生产中建议按业务模块划分VHost,实现资源隔离,避免不同业务互相干扰。
2 原理机制类
-
问题 :RabbitMQ 消息从生产到消费的完整流程是什么?
答案:分6步走:- 生产者与Broker建立
Connection,创建Channel; - 生产者通过
Channel声明交换机、队列,并建立绑定关系; - 生产者发送消息,指定交换机和
RoutingKey; - 交换机根据
RoutingKey和绑定规则,将消息路由到对应队列; - 消费者通过
Channel监听队列,Broker推送消息给消费者; - 消费者处理消息后手动发送
ACK,Broker收到后删除队列中的消息。
- 生产者与Broker建立
-
问题 :RabbitMQ 如何保障消息不丢失?(全链路可靠性方案)
答案 :需配置三层保障机制,缺一不可:- 生产者侧 :开启生产者确认(Publisher Confirm) ,确保Broker接收消息;开启生产者退回(Publisher Return),处理无匹配队列的消息;
- Broker侧 :配置三层持久化 ------交换机持久化(
durable=true)、队列持久化(durable=true)、消息持久化(deliveryMode=2),确保Broker宕机后消息不丢失; - 消费者侧 :使用手动ACK确认机制 ,处理完业务再发送
ACK,杜绝消费中宕机导致消息丢失。
-
问题 :RabbitMQ 消息重复消费的原因是什么?如何解决?
答案:- 原因 :① 消费者发送
ACK后,Broker未收到回执就宕机,重启后重新推送;② 网络抖动导致ACK丢失;③ 消息重试机制重复投递; - 解决方案 :消费端实现幂等性处理(核心方案),通过业务唯一标识(如订单号、消息ID)判断消息是否已处理,已处理则直接返回成功,不执行业务逻辑;常见幂等方案:数据库唯一索引、Redis分布式锁、本地缓存标记。
- 原因 :① 消费者发送
-
问题 :死信队列(DLX)的触发条件有哪些?作用是什么?
答案:- 触发条件 (满足其一即可):① 消息被消费者拒绝(
NACK)且不重新投递(requeue=false);② 消息达到过期时间(TTL)未被消费;③ 队列达到最大长度,新消息挤掉旧消息; - 作用:存储异常消息,避免阻塞正常消息消费;可对死信消息单独重试、人工排查、归档处理,保障主业务稳定。
- 触发条件 (满足其一即可):① 消息被消费者拒绝(
-
问题 :RabbitMQ 如何实现延迟队列?
答案 :RabbitMQ无原生延迟队列,通过死信队列+消息TTL 间接实现:- 创建一个无消费者的普通队列,绑定死信交换机,并设置队列/消息的TTL(过期时间);
- 生产者发送消息到该普通队列,消息因无消费者而滞留;
- 消息过期后,被自动投递到绑定的死信队列;
- 消费者监听死信队列,完成延迟消费;
- 适用场景:订单超时关闭、支付超时提醒、定时任务触发。
-
问题 :什么是消费限流?如何配置?
答案:- 消费限流 :通过配置
prefetchCount(预取值),控制Broker每次推送给消费者的消息数量,防止消费者被海量消息压垮; - 配置方式 :消费者监听队列时,设置
channel.basicQos(prefetchCount),例如prefetchCount=10表示消费者最多同时处理10条消息,处理完一条再接收下一条; - 核心价值:实现消费端的"削峰填谷",保障消费者稳定运行。
- 消费限流 :通过配置
3 高可用与运维类
-
问题 :RabbitMQ 集群有哪些模式?生产中首选哪种?为什么?
答案:共3种核心集群模式:- 普通集群:共享元数据,队列数据仅存一个节点,节点宕机队列不可用,适合测试环境;
- 镜像集群 :队列数据镜像同步到多个节点,主节点宕机后从节点无缝接管,无数据丢失,生产首选;
- 联邦集群:跨地域集群互联,适合异地多活架构;
- 生产首选镜像集群原因:兼顾高可用与数据可靠性,核心业务零中断,是企业级场景的最优解。
-
问题 :RabbitMQ 消息堆积的原因有哪些?如何解决?
答案:- 原因:① 消费速度远低于生产速度;② 消费者宕机或消费逻辑阻塞;③ 生产侧突发海量消息;
- 解决方案 :
- 扩容消费者节点,增加消费能力;
- 优化消费逻辑,提升单消费者处理速度(如异步处理、减少数据库操作);
- 配置消费限流,控制生产速度;
- 使用分片队列,拆分大队列到多个节点;
- 堆积严重时,临时将消息转存到其他存储,消费完后再恢复。
-
问题 :RabbitMQ 持久化机制的原理是什么?配置时需要注意什么?
答案:- 原理:持久化是将交换机、队列的元数据,以及消息数据写入磁盘;Broker重启时,从磁盘加载数据恢复状态;内存中保留缓存,提升读写效率;
- 注意事项:① 必须同时配置交换机、队列、消息三层持久化,否则持久化失效;② 持久化会增加磁盘IO开销,性能略低于内存队列;③ 核心业务必须开启持久化,非核心临时消息可关闭。
-
问题 :RabbitMQ 自动ACK和手动ACK的区别?生产中用哪种?
答案:- 自动ACK :消费者接收到消息后立即发送
ACK,Broker直接删除消息;若消费者处理时宕机,消息永久丢失;仅适合非核心消息; - 手动ACK :消费者处理完业务后,手动调用API发送
ACK;处理失败可发送NACK;生产核心业务必须使用手动ACK,这是保障消息不丢失的核心配置。
- 自动ACK :消费者接收到消息后立即发送
4 选型对比类
-
问题 :RabbitMQ 和 Kafka 的核心区别是什么?各自适用场景是什么?
答案 :核心区别在于设计定位和架构特性:特性维度 RabbitMQ Kafka 设计定位 企业级业务消息中间件 大数据流式处理平台 核心协议 AMQP 0-9-1 自定义TCP协议 吞吐量 中低吞吐量,万级/秒 超高吞吐量,十万级/秒 可靠性 支持全链路持久化,可靠性高 依赖副本机制,可靠性中等 路由灵活性 支持4种交换机,路由规则灵活 仅支持主题分区路由,灵活性低 适用场景 业务解耦、异步通信、流量削峰、延迟任务 日志收集、大数据分析、流式计算、海量消息存储 - 选型建议:业务系统用RabbitMQ,大数据场景用Kafka。
-
问题 :RabbitMQ 的优缺点是什么?
答案:- 优点:① 轻量易部署,生态完善,支持多语言客户端;② 路由规则灵活,支持复杂业务场景;③ 可靠性高,支持全链路持久化和确认机制;④ 运维成本低,提供可视化管理控制台;
- 缺点:① 吞吐量低于Kafka,不适合超海量消息场景;② 基于Erlang语言开发,二次开发难度大;③ 镜像集群模式下,性能会因数据同步略有损耗。